结束了上一章内容,我们对数据库的操作有一定的了解,本章内容就是针对表中的数据进行操作的。
针对表中数据的操作绝大部分都是增删改查(CRUD),CRUD也就是四个单词的缩写:
增加(Create)、查询(Retrieve)、更新(Update)、删除(Delete);
这也是数据库存在的主要目的。
CRUD
增加(Create)
增加即向表中插入数据,上一章中已经提到过了,基本语法如下:
insert into 表名 value(值1,值2......);【单行插入】
insert into 表名 values(值1,值2......),(值1,值2......);【多行插入】
例如:
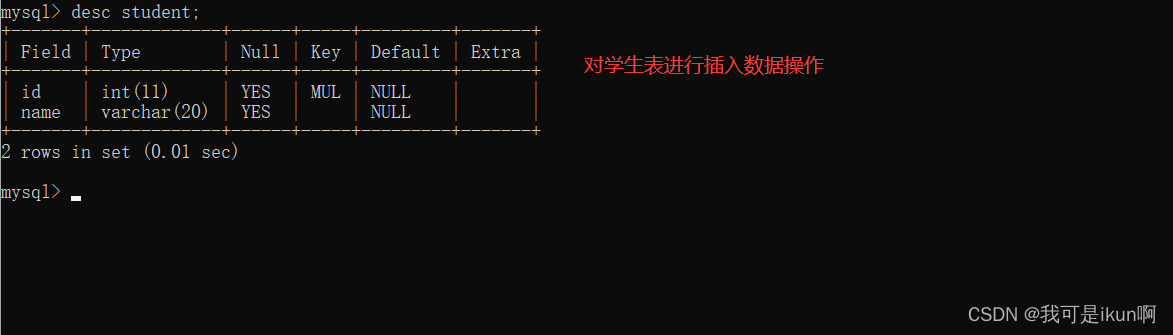
 values 方式插一行,插多行都可以,但是value每次只能插入一行记录。
values 方式插一行,插多行都可以,但是value每次只能插入一行记录。
查询(Retrieve)
全列查询
如上图,我们用的是 * 的方式是全列查询,上一章也提到,对于大数据的查询是非常危险的,带宽会被这一条语句占满,服务器不可能只服务一个用户端。
指定列查询
有时候呢,我们一张表有很多的数据,比如一个人,有年龄,性别,名字,是否已婚,等等....;但是我们有时候又不是需要全部信息,我们只需要取一部分,那么这就需要我们的指定列查询了。
还是拿 student 表来举例:我们拿出所有学生的名字:

否则就会报错:
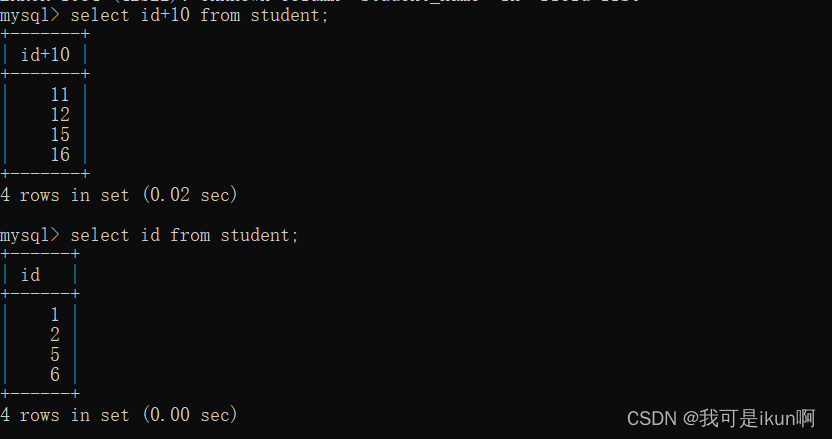
查询字段为表达式
select 表达式 对比结果如下:
别名
为查询结果中的列指定别名,表示返回的结果集中,以别名作为该列的名称,语法:
SELECT column [AS] alias_name [...] FROM table_name;
就是有时候我们不想让列名那么奇怪,或者我们像简单点表示列名,那就需要用到别名。
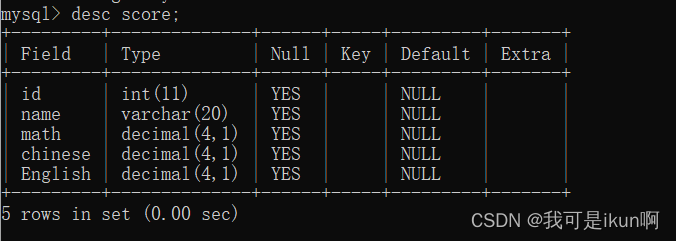
例如,我们设置一个成绩表,并添加数据:

我想查询每个人的总分数:
我们可以怎么写:
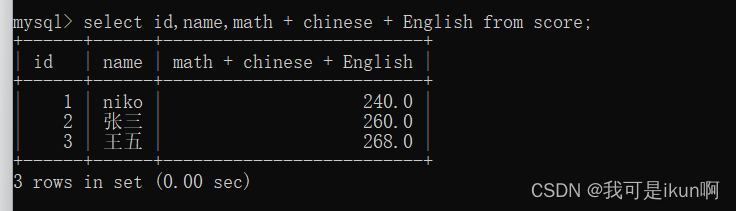 这时候我们看这个总分的列名非常不好,于是可以用到别名:
这时候我们看这个总分的列名非常不好,于是可以用到别名:
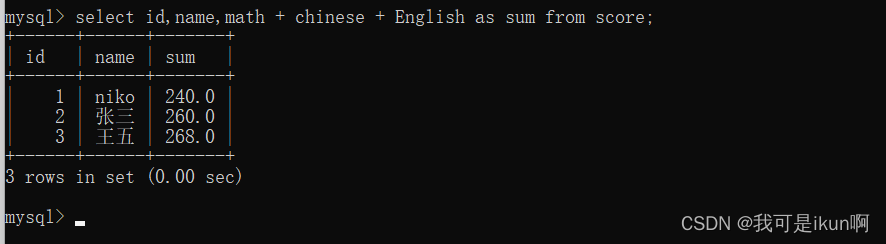
这下舒服多了!
去重:DISTINCT
使用DISTINCT关键字对某列数据进行去重;
就拿上面的分数表来说,我再次添加一个数据:
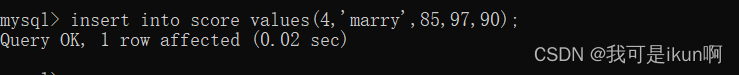
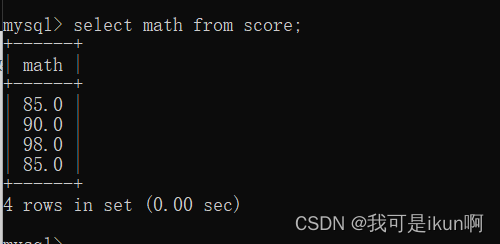
我们现在查询数学成绩看看结果:
去重也就是取出重复数据,我们来试试看:
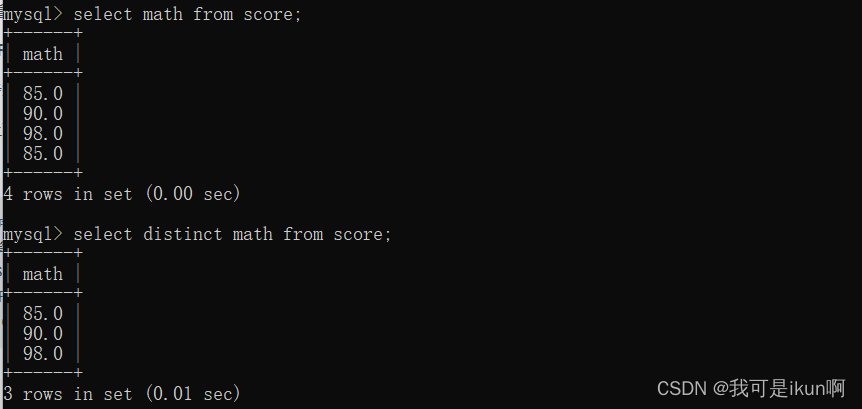
结果的确是将重复数据剔除了。
排序:ORDER BY
上学时期每次考完试,班主任总会对学生的总分进行排序,我们这里也不例外;
我们也可以对上面总成绩进行一个排序;
语法如下:
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
SELECT ... FROM table_name [WHERE ...]
ORDER BY column [ASC|DESC], [...];
结果如下:
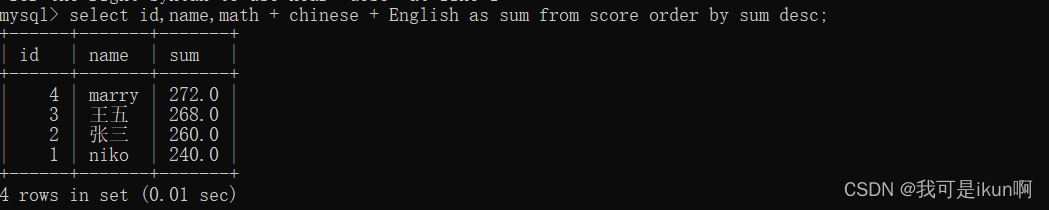
我们也可以升序排序:
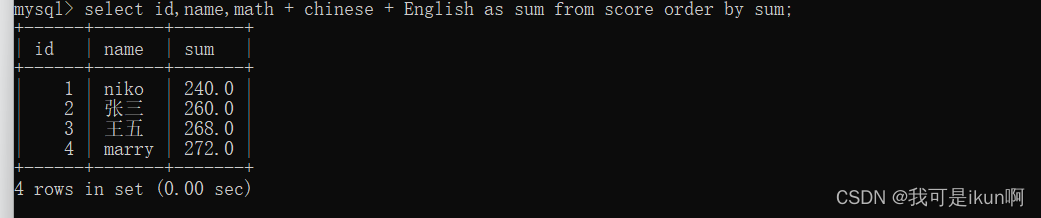
asc 是升序,默认也是升序; desc 的 全拼是 descend(下降)。
条件查询:WHERE
我们在查询的时候会对一些数据进行筛选,并非全部数据都是我们需要的,而 where 条件查询也分很多:
比较运算符:
| 运算符 | 说明 |
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| IN (option, ...) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字 符 |
举个例子:
比如我想查找,总分大于250 分的所有同学,我们可以这么写:

但是我觉得怎么写,sum 总分不好看,我们再换一种写法:

这里我们发现,sum是未定义的,为什么呢?
起别名是在进行排序的时候起的,而排序是在 where 筛选之后才有的,当然找不到sum列了。

我们发现这样的写法也是错误的,那么只能:

除了比较运算符,还有其他的的运算符:
逻辑运算符:
| 运算符 | 说明 |
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
相信大家对逻辑运算符是不陌生的,在Java中不知道写过多少了。
举例:
我要查询数学和语文都大于90 分的全部信息:
我们就可以用and语句来执行:
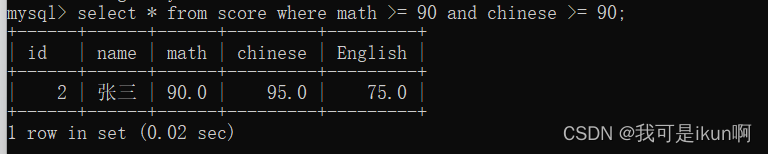
或者,我要查询,语文或数学大于 90 的人:
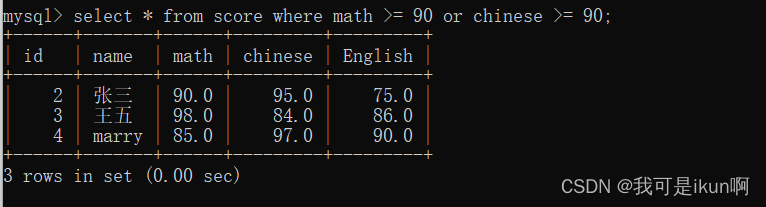
对条件查询做个小结:
1. WHERE条件可以使用表达式,但不能使用别名。
2. AND的优先级高于OR,在同时使用时,需要使用小括号()包裹优先执行的部分
对上面的查询,我就不一一举例了,没事的时候,可以自己动手试一试,光是看无法提升自己的能力,不会的时候可以动手查;反正现在是学习时间,有足够的时间试错!
修改(Update)
在我们添加数据的过程中总会出现添加错误的情况,在这种情况下先删除,再添加显然不是最好的方法,于是就有了修改。
基本语法如下:
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]
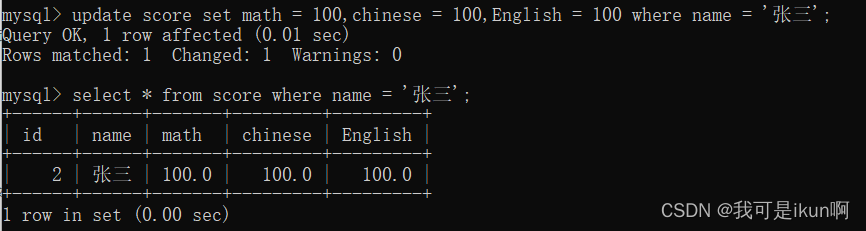
比如:
将张三的语数英都改为100 分:
等等,我就不一一举例了。
删除(Delete)
对于过时的数据,我们就需要执行删除操作:
基本语法如下:
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
比如我们需要删除 jerry 的成绩:
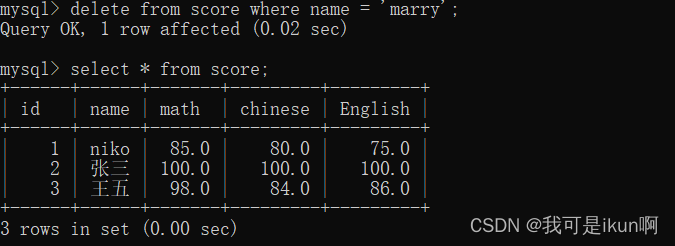
上述都是对表中数据的简单操作,现在进入进阶部分,难度要大于以上内容。
数据库约束
约束的作用:
一般在创建表的时候需要给数据添加各种约束以保证添加到表中的数据是正确的,保证数据的有效性、完整性和正确性;若违反了约束,则无法添加进入表中;若是先添加数据再加约束,若其中有数据违反了约束则约束添加失败。
约束类型:
NOT NULL - 指示某列不能存储 NULL 值。
UNIQUE - 保证某列的每行必须有唯一的值。
DEFAULT - 规定没有给列赋值时的默认值。
PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
CHECK - 保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略CHECK子句
NULL约束
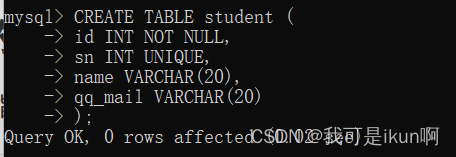
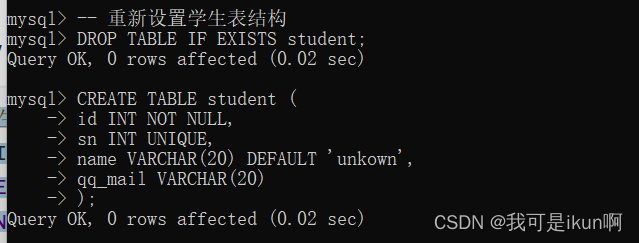
我们重新创建一个学生表 设置id不为空:
UNIQUE:唯一约束
sn列为唯一的、不重复的
DEFAULT:默认值约束
指定插入数据时,name列为空,默认值unkown:
PRIMARY KEY:主键约束
指定id列为主键: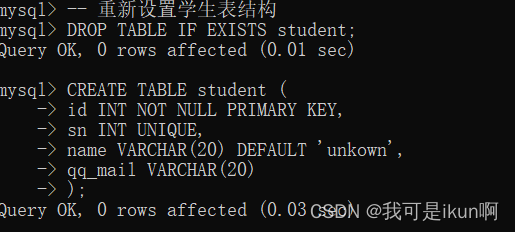
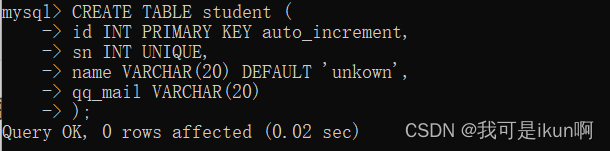
对于整数类型的主键,常配搭自增长auto_increment来使用。插入数据对应字段不给值时,使用最大值+1。
例如:
FOREIGN KEY:外键约束
外键用于关联其他表的主键或唯一键 , 基本语法如下:
foreign key (字段名) references 主表(列)
举例:
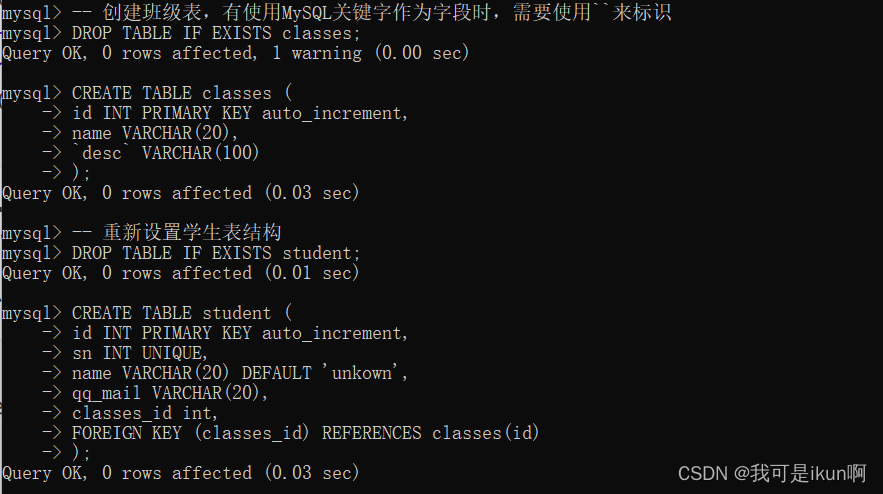
这就把两个表链接起来了。
check约束
了解即可:
MySQL使用时不报错,但忽略该约束:
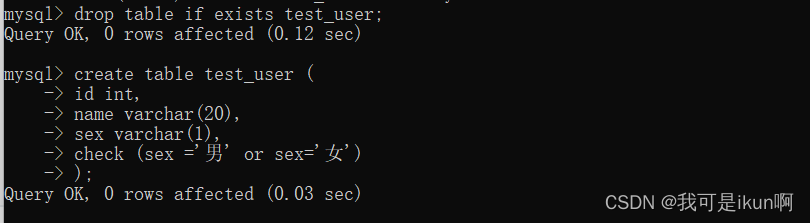
表的设计
本章不涉及表的设计,对于刚刚入职的而言,在这方面压根不会让我们上,这玩意需要一段时间的累积,初学者其实没必要去掌握。等以后技术起来了再来了解。
查询
单表查询
顾名思义,单表查询就是对一个表进行查询。
聚合函数
聚合查询类似于Java中的API,系统给我们写好的函数,我们直接拿来用即可,常用的聚合函数如下:
| 函数 | 说明 |
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
我们拿几个举例:
看看我之前写好的员工表:
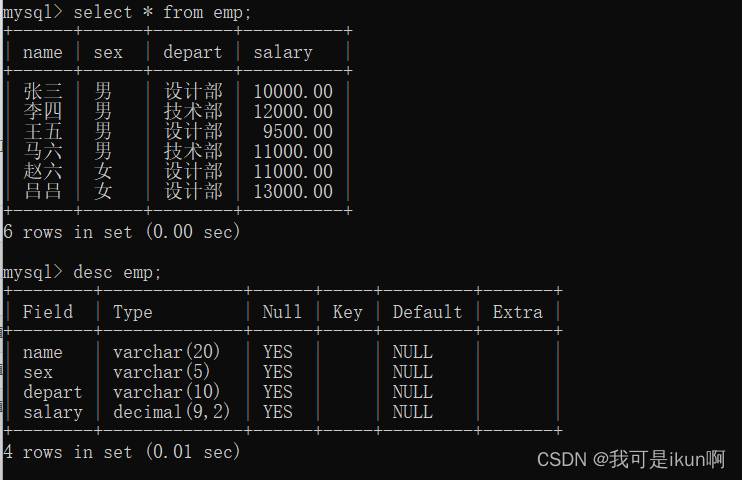
假设我们要计算有多少个员工,就可以用count() 这个函数:
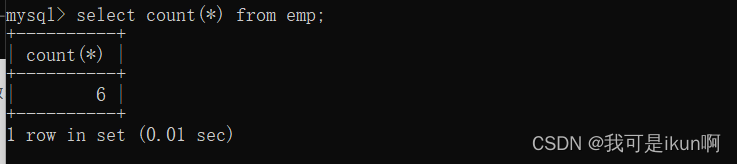
一个count(*)解决问题;
count()里面也可以是其他列名。
再比如,我想知道其中工资最高的男员工:

其他的用法类似,我就不一一举例了,可以自己一个个去试。
GROUP BY子句
SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询。需要满足:使用 GROUP BY 进行分组查询时,SELECT 指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 中则必须包含在聚合函数中;语法如下:
select column1, sum(column2), .. from table group by column1,column3;
就拿上面的例子:
找出每个部门中工资最高的的一个:
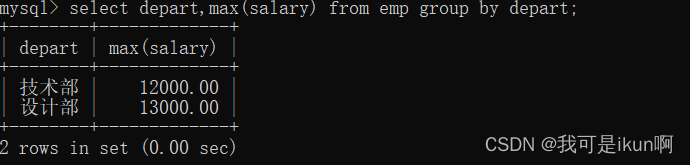
找出每个部门的最高工资,平均工资,最低工资:

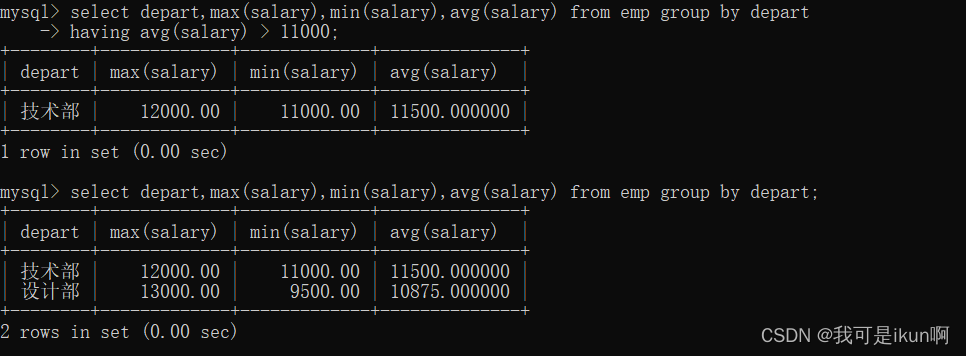
HAVING
having 作用于group by 语句之后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用having。
例如:
找出每个部门的最高工资,平均工资,最低工资;并且平均工资高于11000 的部门情况:
多表查询
在了解多表查询之前我们得了解以下:笛卡尔积
笛卡尔积
简单的说就是两个集合相乘的结果;
我们可以百度查一下,下面是我搜索的:
现在,我们有两个集合A和B。
A = {0,1} B = {2,3,4}
集合 A×B 和 B×A的结果集就可以分别表示为以下这种形式:
A×B = {(0,2),(1,2),(0,3),(1,3),(0,4),(1,4)};
B×A = {(2,0),(2,1),(3,0),(3,1),(4,0),(4,1)};
可以得出A×B和B×A的笛卡尔积,但总体思路为用
以上A×B和B×A的结果就可以叫做两个集合相乘的‘笛卡尔积’。
从以上的数据分析我们可以得出以下两点结论:
1,两个集合相乘,不满足交换率,既 A×B ≠ B×A;
2,A集合和B集合相乘,包含了集合A中元素和集合B中元素相结合的所有的可能性。既两个集合相乘得到的新集合的元素个数是 A集合的元素个数 × B集合的元素个数;
我们举个例子,来看看结果如何?
创建一个学生表和课程表:结果如下:
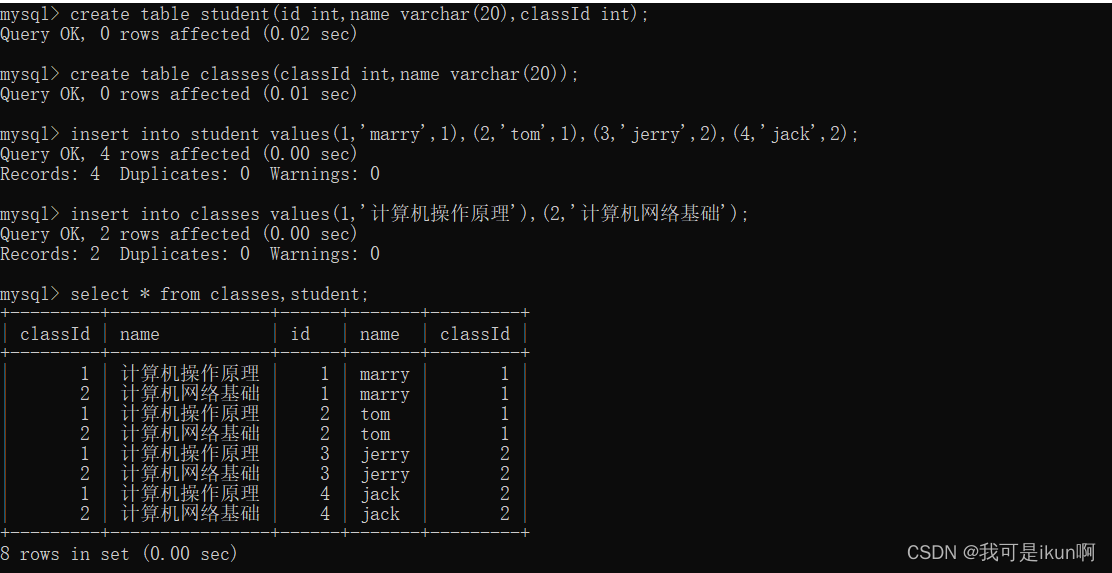
笛卡尔积就是将我们选中的两个表进行一个排列组合;
因此,需要注意的是:我们在进行多表查询的时候(计算笛卡尔积的过程),如果两个表数据很大,就会非常低效,甚至成为危险操作。
所以对其操作要小心!!!
Tip(多表情况):如果是三个表的话,那么就是先将两个表进行笛卡尔积运算,再用这个表与另外一个表进行笛卡尔积操作(以此类推)。
消除笛卡尔积
我们可以通过连接查询来消除笛卡尔积、连接查询分为:
内连接:
语法:
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
比如我想查询每个人的课程:

或者

注意:这里都有相同的记录名(classId),所以这里通过 表名.列名 的方法实现,如果不用则会报错:
![]()
外连接
左连接:左连接显示的结果为tb1中所有的内容,及tb2中满足条件的内容,若tb1中有的内容而tb2中没有,则显示tb2对应的内容时显示为null
select * from tb1 Left Join tb2 where tb1.ID = tb2.ID
右连接:右连接显示的结果为tb2中所有的内容,及tb1中满足条件的内容,若tb2中有的内容而tb1中没有,则显示tb1对应的内容时显示为null
select * from tb2 Right Join tb1 where tb2.ID = tb1.ID
我们再添加一个数据看看结果:

任然 查询每个人的课程

左连接就是以左边的表为准,即使右边的表中不存在某个数据,就为空。
右链接:
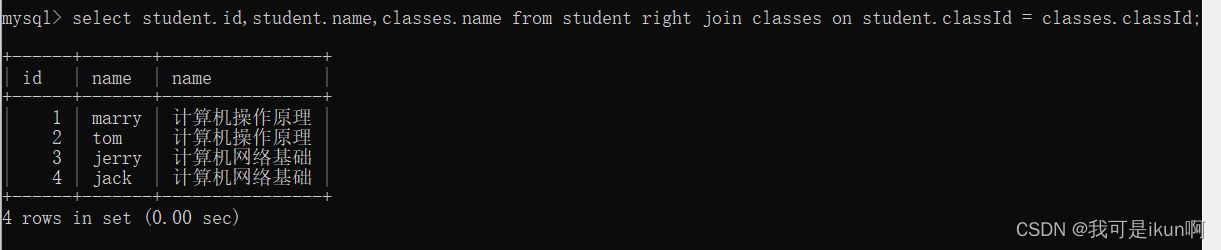
以右边的表为准右边表不存在的数据不出现。
全链接
全连接:MySQL现在不支持全连接,但可以通过union和union all实现,但是两个表的列数必须相同
-- union 可以过滤重复数据
select * from world.city union select * from world.country;
-- union all 不会过滤重复数据
select * from world.city union all select * from world.country;
这章节就到这,其他还有一些不是那么频繁的查询可以在查查资料!!
![Mysql问题:[Err] 1055 - Expression #1 of ORDER BY clause is not in GROUP BY clause](https://img-blog.csdnimg.cn/1066a58e1b5d4b119df843e604651406.png)