目录
问题描述
问题分析
解决方案
问题描述:
- Web前端在地图上加载空间数据库里存储的地块中心点时因为数据点太多从而导致页面崩溃。
- Mybatis查询大量数据时,耗时时间更长是主要原因。8万多条数据,数据库查询最慢0.6s, Mybatis查询结果需要4s+。
问题分析:
- 数据点太多,超过800个点时页面卡顿,更多点时地图页面卡死。
目前地图加载地块中心点时,添加了作业类型、年份、地区过滤;大大减小了数据量,缩小了数据点范围, 页面可正常加载。
- 数据加载时间过长
地图加载完成后,等待数据展示时间过长。
解决方案:
一、数据抽稀
- 采用聚合算法、地图距离网格化、查询优化、存储过程进行数据点抽稀。
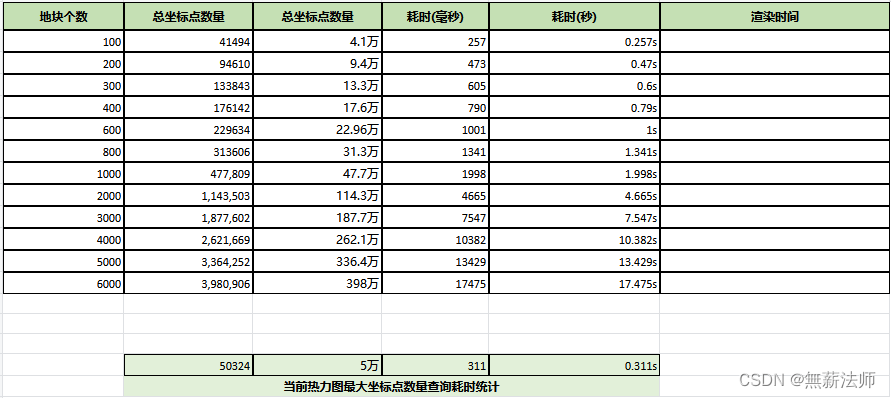
(1) 实现逻辑:根据xmin、ymin、xmax、ymax值限定的最大地理范围进行纵横切分,gridXcount列、gridYcount行。 将每个切分后的小块使用st_makeenvelope() 函数转换成多边形并筛选出在这个多边形内的多个地块中心点所构成的曲面的一个中心点( 这个中心点不是切分后多边形的中心点,也不是某个地块中心点,可以说是新生成的一个曲面中心点),然后筛选距离中心点41米以内的地块中心点1个(这里大约取5个,结果集会没那么稀疏,具体多少个可以按照需求和具体结果)。

(2) 函数参数:
| tab_name | 表名(要操作的表) |
| xmin | 切割范围参数: x轴最小值 |
| ymin | 切割范围参数: y轴最小值 |
| xmax | 切割范围参数: x轴最大值 |
| ymax | 切割范围参数: y轴最大值 |
| gridXcount | 网格划分:用于x轴切分 |
| gridYcount | 网格划分:用于y`轴切分 |
(3) 涉及到的函数:
| 函数名称 | API | |
| ST_distance | 获取两个几何对象间的距离 | http://postgis.net/docs/ST_Distance.html |
| st_collect | 从其他几何对象的集合中返回一个空间ST_Geometry的值 | http://postgis.net/docs/ST_Collect.html |
| st_pointonsurface | 返回曲面上的一个点 | http://postgis.net/docs/ST_PointOnSurface.html |
| st_makeenvelope | 从给定的最小值和最大值构造一个Polygon。输入值必须在给定的SRID的有效范围内。 | http://postgis.net/docs/ST_MakeEnvelope.html |
| st_dwithin | 如果两个几何对象间距离在给定值范围内,则返回TRUE | http://postgis.net/docs/ST_DWithin.html |
- 使用网格将数据进行切分,每次数据请求需要计算时间比较长,但是抽稀后每次地块数据量变化不大, 可以每日定时将抽稀完的中心点存到表里,用于前端页面加载。
数据展示从之前的实时计算需要3s 减少到只需不到1s (网络比较好的情况下)。
-
最终效果图及耗时
| 点数 | 数据查询时间(秒) | |
| 抽稀前: | 170988 | 7.57s+ |
| 抽稀后: | 5341 | 2.67s |
| 提前计算后: | 5341 | <1s |
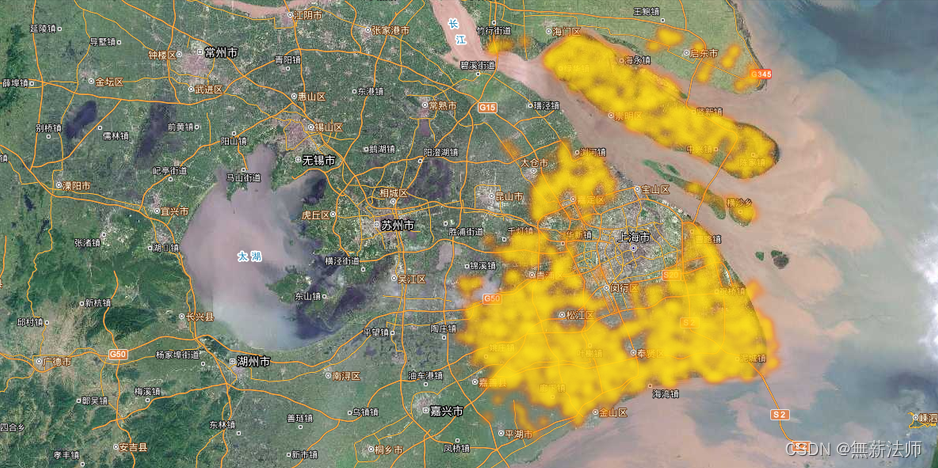
参考:
借鉴抽稀逻辑:https://blog.csdn.net/luojingweikai/article/details/88401201
Postgresql数据库学习手册:http://www.postgres.cn/docs/12/index.html
Postgresl 数据库plgssql语言语法:https://www.postgresql.org/docs/current/plpgsql-overview.html
PostGISx相关学习文档:http://postgis.refractions.net/docs/PostGIS_FAQ.html
二、尝试Node.js解决方案
抽稀的方案没有使用时,仔细研究了下接口代码,发现接口耗时的主要原因是Mybatis查询返回结果耗时时间比较长,讨论过后来尝试使用Node.js解决数据查询问题以及json文件读取耗时。发现Node.js 在查询空间管理数据库读取json文件耗时很短:
最后也没有使用Node.js的方式,因为发现Node.js 访问数据库的代码不能添加到vue项目里。
三、修改接口查询方式:采用jdbc连接查询
这个也是最终解决方案,不再使用Mybatis这个ORM工具、直接jdbc连接查询数据并返回需要的结果集。
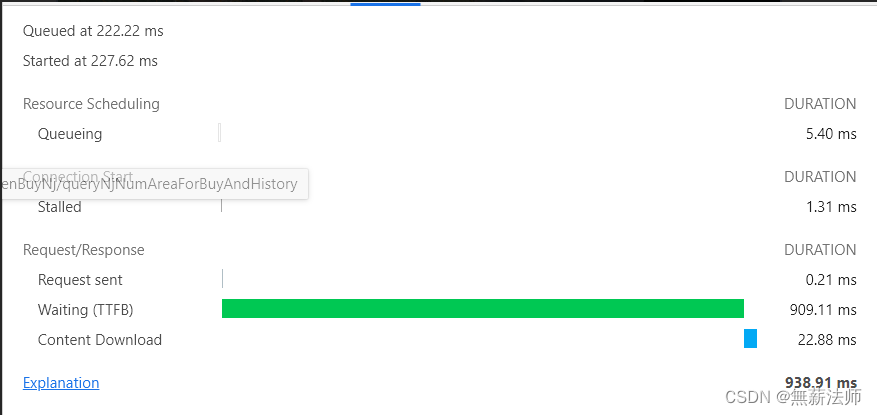
耗时不到900ms, 数据点 8.7万+,数据大小3.45Mb 及效果图: 
其实接口改好后,通过postman获取数据时间是1.6s+, 数据传输时间占了一半( 大约 0.7s ), 项目部署后看到其实浏览器端对传输数据进行了压缩, 从3.6Mb 压缩到了1.6Mb, 节省了不少时间。再者网速也提升了不少,目前可以看到接口查询数据以及返回结果集的耗时很小很理想。