下面附源码
手游网址:英雄联盟手游官网 - 腾讯游戏
1、点击英雄

2、随机点一个英雄进去
3、按F12进入开发者模式,然后刷新
4、在搜索框里输入 js

找到skins.js点击
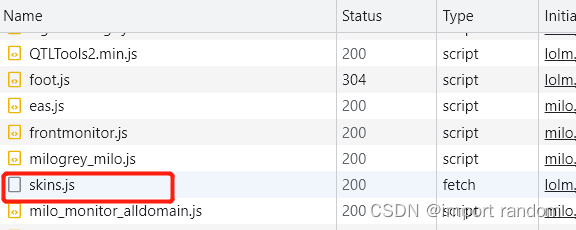
我们可以发现所有现有的英雄皮肤信息都在里面
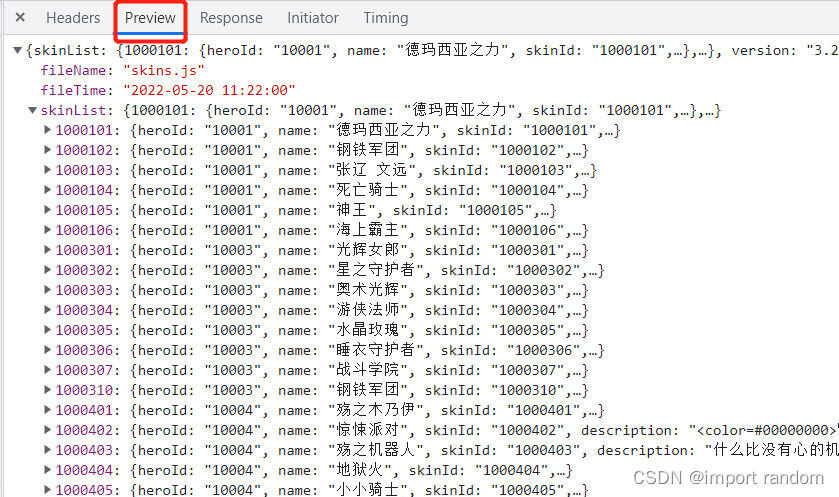
皮肤的图片链接以及对应的皮肤名称在skinList里面的poster下
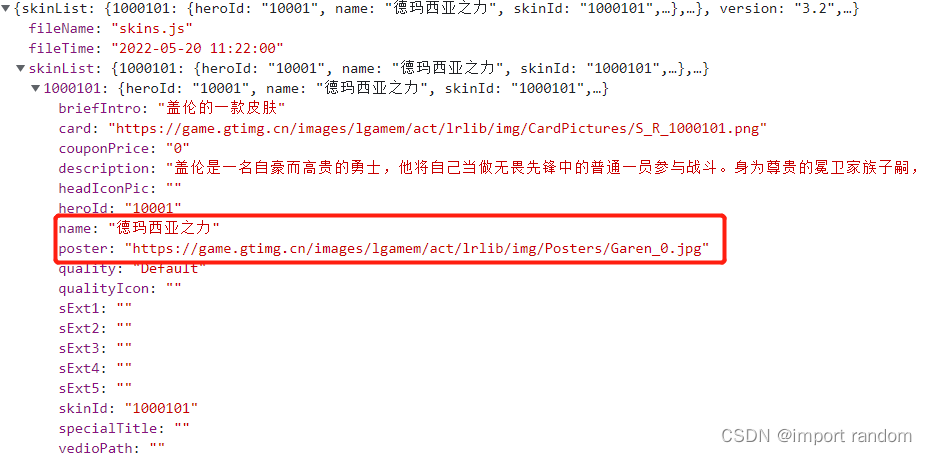
6、提取信息

点击headers就可以发现网页链接 ,用requests库进行爬取,并用json进行解析
#提取并解析网页信息
response = requests.get(url).text
html = json.loads(response)7、 提取图片链接以及名称
#一层一层的把图片信息剥出来
s = html["skinList"]
for i in s:First_name = s[i]["name"]name = First_name.replace("/","")img_url = s[i]["poster"]!!!需要注意的是,这里用replace把/替换乘" ",是因为在将文件写入文件夹中时,/会与文件路径中的\混淆,python不会区分这个东西,所以我们只能去掉
8、将信息写入文件夹中
with open(h+name+".jpg","wb") as f:f.write(img)print(name,"+下载成功")9、源码
import os
import requests
import json
url = "https://game.gtimg.cn/images/lgamem/act/lrlib/js/skins/skins.js"#创建文件夹
h = "F:\\LOL_img\\"
if not os.path.exists(h):os.mkdir(h)#提取并解析网页信息
response = requests.get(url).text
html = json.loads(response)#一层一层的把图片信息剥出来
s = html["skinList"]
for i in s:First_name = s[i]["name"]name = First_name.replace("/","")img_url = s[i]["poster"]img = requests.get(img_url).contentwith open(h+name+".jpg","wb") as f:f.write(img)print(name,"+下载成功")
print("所有图片已经下载完成!")