目前,本人写的第二个R包pm3包已经正式在CRAN上线,用于3组倾向评分匹配,只能3组不能多也不能少。
可以使用以下代码安装
install.packages("pm3")

什么是倾向性评分匹配?倾向评分匹配(Propensity Score Matching,简称PSM)是一种统计学方法,用于处理观察研究(Observational Study)的数据,在SCI文章中应用非常广泛。在观察研究中,由于种种原因,数据偏差(bias)和混杂变量(confounding variable)较多,倾向评分匹配的方法正是为了减少这些偏差和混杂变量的影响,以便对实验组和对照组进行更合理的比较。
为什么需要做倾向评分匹配?
我们知道RCT的证据力度高,是因为对患者进行了严格的筛选。我们的回顾性研究都是过去的数据,很难像RCT一样进行严格的筛选出两组患者基线相近的基础资料,但我们可以通过倾向评分匹配把回归性的数据进行筛选,把基线资料相近的患者进行匹配,得到近似RCT的效果。
应用场景
1.基线资料不平
2.开展病例对照研究病阳性例数较少,如罕见病研究
3.将众多混杂因素变为一个变量:倾向值
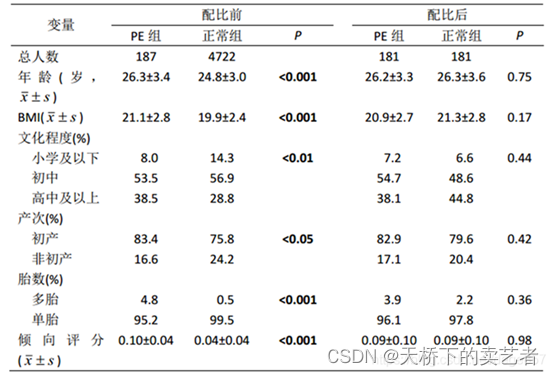
以下为一个实例,没进行匹配前两组患者基线资料相差很大,进行倾向评分匹配后,基线资料近似一致了
目前进行3组倾向评分的R包据我所知,几乎没有,我这个应该也算是开创了把,算法来源于下面两篇参考文献,我既往也写了关于文章《R语言3组患者倾向性评分匹配(PSM)》,想了解做法的可以看看,但是蛮多人看了文章也做不出来,于是我有了写包的想法,这也是在文章末尾答应大家的,也算说到做到了把

感谢付费的朋友们,这也算支持我继续前进的动力吧。感谢原创作者无私提供方法,我只是把方法用代码呈现出来,理论的探讨不要来问我。这里我还要提一句,我对作者的方法进行了一定改进、优化,原作者的方法,协变量的分类变量只能是2分类的,我这里多分类的都可以了。
下面来进行pm3包的用法演示,我们先导入R包和数据,pm3包有我内置的早产数据,我们直接导入就可以了
library(pm3)
bc<-prematurity
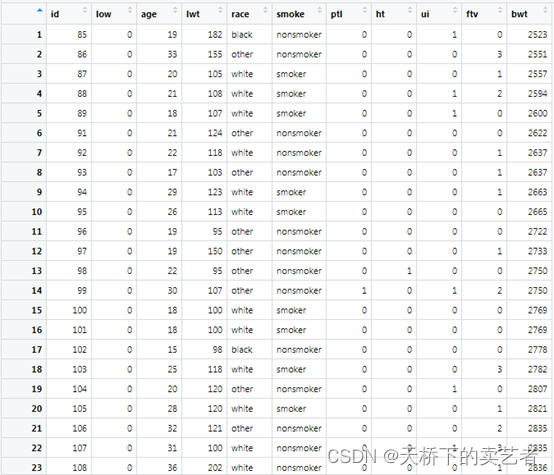
这是一个关于早产低体重儿的数据(公众号回复:早产数据,也可以获得该数据),低于2500g被认为是低体重儿。数据解释如下:low 是否是小于2500g早产低体重儿,age 母亲的年龄,lwt 末次月经体重,race 种族,smoke 孕期抽烟,ptl 早产史(计数),ht 有高血压病史,ui 子宫过敏,ftv 早孕时看医生的次数,bwt 新生儿体重数值。
假设我们研究的是有不同种族(race)对生出低体重儿(low)的影响。需要对3个种族进行基线资料倾向评分匹配
现在我们不需要像既往一样进行一大堆复杂操作,直接一句话代码,就搞定了
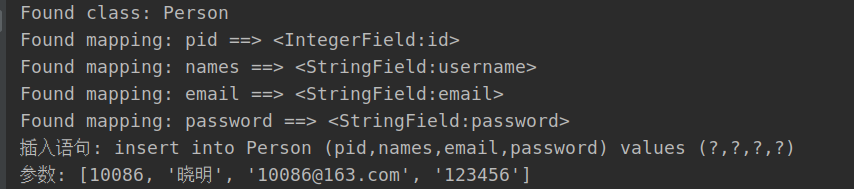
g<-pm3(data=bc,x="race",y="low",covs=c("age","lwt","ptl"),factor=c("ui","low"))
这句代码我来解释一下,因为我们是靠逻辑回归模型生成评分的,所以要定义一个回归模型的变量:data就是你的数据,x就是你要比较的变量,我们这里是race,y是你要比较的结局变量,covs是协变量的意思,填入你模型模型中的协变量,包括连续的和分类的,这里是"age",“lwt”,“ptl”,最后factor是定义你数据中的分类变量,这里有个小问题,factor你要是没有可以不填,填的话最少要填两个,不然会报错,这个问题在后期版本修正。我这里本来只有ui这个分类变量,怕报错我加了low,或者加race也可以,都不影响的.
执行代码后就生成了g

g是一个列表数据文件,我们可以看到生成了3个我们匹配好的数据文件,每个文件26个数据,和文章《R语言3组患者倾向性评分匹配(PSM)》做出来的一模一样。mbc是这是3个匹配好的文件合并后的数据

我们把mbc提取出来
mbc<-g[["mbc"]]

下面我们进行匹配前和匹配后的比较。导入tableone包
library(tableone)
定义全部变量和分类变量
allVars <-c("age", "lwt", "ptl","ht")
fvars<-c("ht")
进行比较
tab2 <- CreateTableOne(vars = allVars, strata = "race" ,
data = bc, factorVars=fvars,addOverall = TRUE )
print(tab2,smd = TRUE)
tab1 <- CreateTableOne(vars = allVars, strata = "race" ,
data = mbc, factorVars=fvars,addOverall = TRUE )
print(tab1,smd = TRUE)

我们可以看到,P值变大了,smd变小了,匹配效果很好,最后想说一句,倾向性匹配也不是万能的,不可能把所有的变量配平。
参考文献:
- 邓强庭, 王宏, 张雷达,等. 无序多分组数据的倾向性评分匹配算法设计及R程序实现[J]. 现代预防医学, 2021, 48(15):5.
- [1]邬顺全, 吴骋, 贺佳. 倾向性评分匹配法在多分类数据中的比较和应用[J]. 中国卫生信息管理杂志, 2013(5):448-451.