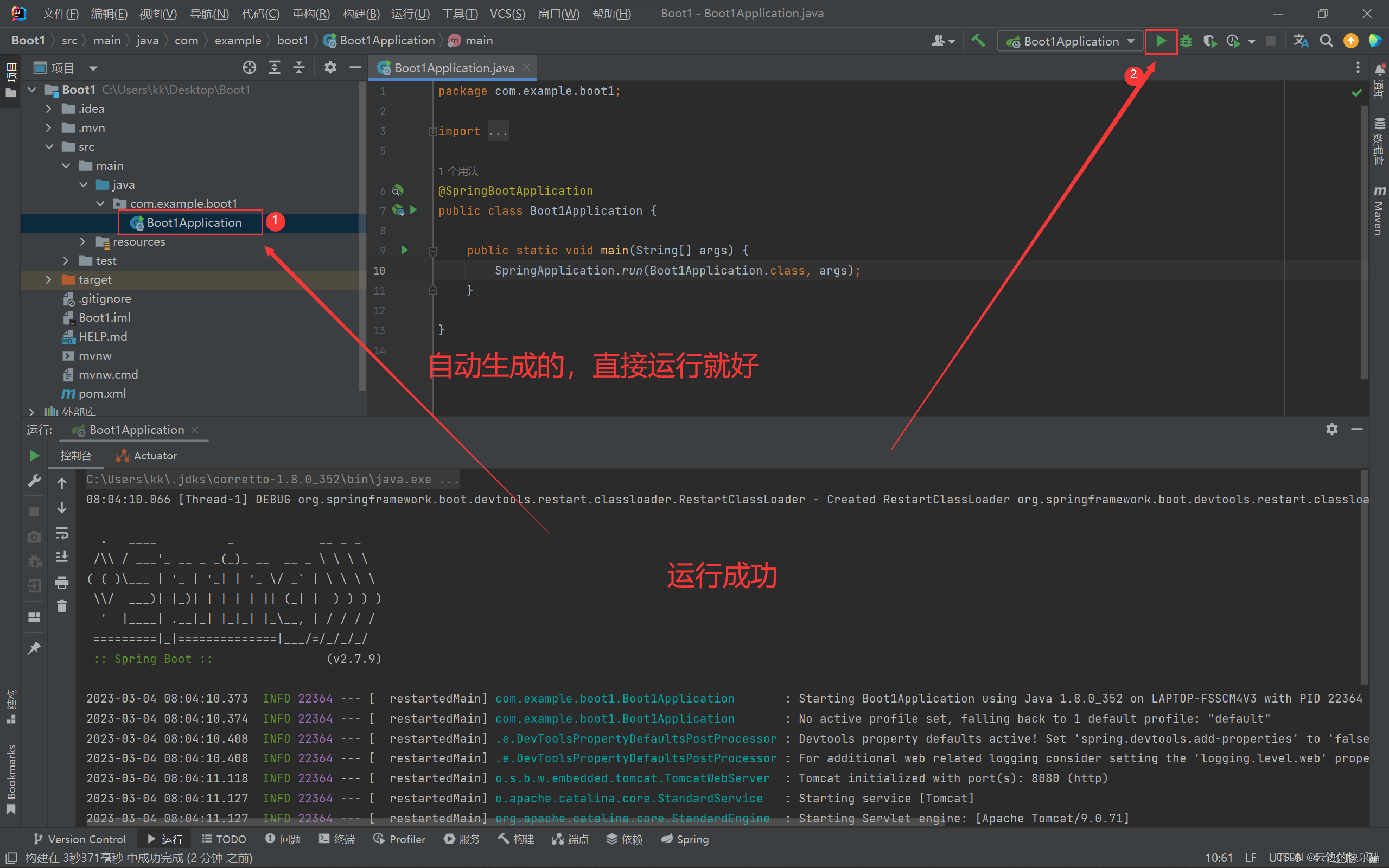
容器云提交spark job任务
容器云提交Kind=Job类型的spark任务,首先需要申请具有Job任务提交权限的rbac,然后编写对应的yaml文件,通过spark内置的spark-submit命令,提交用户程序(jar包)到集群执行。
1、创建任务job提交权限rbac
创建rbac账户,并分配资源权限,Pod服务账户创建参考,kubernetes api查询命令(kubectl api-resources);
cat > ecc-recommend-rbac.yaml << EOF
---
apiVersion: v1
kind: Namespace
metadata:name: item-dev-recommendlabels:name: item-dev-recommend
---
#基于namespace创建服务账户spark-cdp
apiVersion: v1
kind: ServiceAccount
metadata:name: spark-cdpnamespace: item-dev-recommend---
#创建角色资源权限
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:name: spark-cdpnamespace: item-dev-recommend
rules:- apiGroups:- ""resources:- podsverbs:- '*'- apiGroups:- ""resources:- configmapsverbs:- '*'- apiGroups:- ""resources:- services- secretsverbs:- create- get- delete- apiGroups:- extensionsresources:- ingressesverbs:- create- get- delete- apiGroups:- ""resources:- nodesverbs:- get- apiGroups:- ""resources:- resourcequotasverbs:- get- list- watch- apiGroups:- ""resources:- eventsverbs:- create- update- patch- apiGroups:- apiextensions.k8s.ioresources:- customresourcedefinitionsverbs:- create- get- update- delete- apiGroups:- admissionregistration.k8s.ioresources:- mutatingwebhookconfigurations- validatingwebhookconfigurationsverbs:- create- get- update- delete- apiGroups:- sparkoperator.k8s.ioresources:- sparkapplications- scheduledsparkapplications- sparkapplications/status- scheduledsparkapplications/statusverbs:- '*'- apiGroups:- scheduling.volcano.shresources:- podgroups- queues- queues/statusverbs:- get- list- watch- create- delete- update- apiGroups:- batchresources:- cronjobs- jobsverbs:- '*' ---
#服务账户spark-cdp绑定角色
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:name: spark-cdpnamespace: item-dev-recommend
roleRef:apiGroup: rbac.authorization.k8s.iokind: Rolename: spark-cdp
subjects:- kind: ServiceAccountname: spark-cdpEOF
2、spark pv,pvc
- 构建pv
挂载NFS,定义pv访问模式(accessModes)和存储容量(capacity);
cat >ecc-recommend-pv.yaml <<EOF
apiVersion: v1
kind: PersistentVolume
metadata:name: dev-cdp-pv01namespace: item-dev-recommend
spec:capacity:storage: 10GiaccessModes:#访问三种模式:ReadWriteOnce,ReadOnlyMany,ReadWriteMany- ReadWriteOncenfs:path: /data/nfsserver: 192.168.0.135EOF
- 构建pvc
cat >ecc-recommend-pvc.yaml <<EOF
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: dev-cdp-pvc01namespace: item-dev-recommend
spec:accessModes:#匹配模式- ReadWriteOnceresources:requests:storage: 10GiEOF
3、spark-submit任务提交
将java/scala程序包开发完成后,通过spark-submit命令提交jar包到集群执行。
cat >ecc-recommend-sparksubmit.yaml <<EOF
---
apiVersion: batch/v1
kind: Job
metadata:name: item-recommend-jobnamespace: item-dev-recommendlabels:k8s-app: item-recommend-job
spec:template:metadata:labels:k8s-app: item-recommend-jobspec:containers:name: item-recommend-job- args:- /opt/spark/bin/spark-submit- --class- com.www.ecc.com.recommend.ItemRecommender- --master- k8s://https:/$(KUBERNETES_SERVICE_HOST):$(KUBERNETES_SERVICE_PORT)- --name- item-recommend-job- --jars- /opt/spark/jars/spark-cassandra-connector_2.11-2.3.4.jar- --conf- spark.kubernetes.authenticate.caCertFile=/var/run/secrets/kubernetes.io/serviceaccount/ca.crt- --conf- spark.kubernetes.authenticate.oauthTokenFile=/var/run/secrets/kubernetes.io/serviceaccount/token- --conf- spark.kubernetes.driver.limit.cores=3- --conf- spark.kubernetes.executor.limit.cores=8- --conf- spark.kubernetes.driver.limit.memory=5g- --conf- spark.kubernetes.executor.limit.memory=32g- --conf- spark.executor.instances=8- --conf- spark.sql.crossJoin.enable=true- --conf- spark.executor.cores=6- --conf- spark.executor.memory=32g- --conf- spark.driver.cores=3- --conf- spark.dirver.memory=5g- --conf- spark.sql.autoBroadcastJoinThreshold=-1- --conf- spark.kubernetes.namespace=item-dev-recommend- --conf- spark.driver.port=45970- --conf- spark.blockManager.port=45980- --conf- spark.kubernetes.container.image=acpimagehub.ecc.cn/spark:3.11- --conf- spark.executor.extraJavaOptions="-Duser.timezone=GMT+08:00"- --conf- spark.driver.extraJavaOptions="-Duser.timezone=GMT+08:00"- --conf- spark.default.parallelism=500- /odsdata/item-recommender-1.0.0-SNAPSHOT.jar- env:- name: SPARK_SHUFFLE_PARTITIONSvalue: "100"- name: CASSANDR_HOSTvalue: "192.168.0.1,192.168.0.2,192.168.0.3"- name: CASSANDRA_PORTvalue: "9042"- name: AUTH_USERNAMEvalue: "user"- name: AUTH_PASSWORDvalue: "123456"image: acpimagehub.ecc.cn/spark:3.11imagePullPolicy: IfNotPresentports:- containerPort: 9000name: 9000tcp2protocol: TCPresources:limits:cpu: "3"memory: 2Girequests:cpu: "3"memory: 2GivolumeMounts:- mountPath: /odsdataname: item-spark-pvcvolumes:- name: item-spark-pvcpersistentVolumeClaim:claimName: dev-cdp-pvc01dnsPolicy: ClusterFirstrestartPolicy: Neverhostname: item-recommend-jobsecurityContext: {}serviceAccountName: spark-cdp
---
apiVersion: v1
kind: Service
metadata:name: item-recommend-jobnamespace: item-dev-recommend
spec:type: NodePortports:- name: sparkjob-tcp4040port: 4040protocol: TCPtargetPort: 4040#spark driver port- name: sparkjob-tcp-45970port: 45970protocol: TCPtargetPort: 45970#spark ui- name: sparkjob-tcp-48080port: 48080protocol: TCPtargetPort: 48080#spark executor port- name: sparkjob-tcp-45980port: 45980protocol: TCPtargetPort: 45980selector:k8s-app: item-recommend-jobEOF
4、打包插件小记
<build><resources><resource><directory>src/main/resources</directory><includes><include>*.properties</include></includes><filtering>false</filtering></resource></resources><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-surefire-plugin</artifactId><configuration><skipTests>true</skipTests></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.6.1</version><configuration><source>${java.version}</source><target>${java.version}</target><encoding>${project.build.sourceEncoding}</encoding></configuration><executions><execution><phase>compile</phase><goals><goal>compile</goal></goals></execution></executions></plugin><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.2.2</version><executions><execution><id>scala-compile-first</id><phase>process-resources</phase><goals><goal>add-source</goal><goal>compile</goal><goal>testCompile</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.2.1</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals></execution></executions></plugin></plugins></build>