 点击上方“LiveVideoStack”关注我们
点击上方“LiveVideoStack”关注我们
 ▲扫描图中二维码或点击阅读原文▲
▲扫描图中二维码或点击阅读原文▲
了解音视频技术大会更多信息
//
编者按:面向人眼感知的质量评价在许多视频图像处理算法和系统中发挥十分重要的作用。近年来学术界已经提出了许多质量评价方法,在已有数据集上取得了很高的性能,但是他们在实际应用中的表现仍然无法让用户满意,以至于无法得到广泛应用。LiveVideoStackCon 2022上海站大会我们邀请到了中国科学院大学副教授 张新峰老师,为我们详细分享了视觉质量评价的背景与问题以及细粒度视觉质量评价方法的发展与挑战。
文/张新峰
整理/LiveVideoStack
大家好,很高兴有机会跟各位同行一起分享我们在质量评价领域的一些想法。我接触视频质量评价领域已经有几年时间,在博士和博士后期间,我主要是做视频编解码,做视频编解码的朋友可能知道我们有一个方向叫Perceptual Coding,也就是面向人眼视觉的编码,希望在相同的码率下得到更高的主观视觉质量。我们想要得到更好的主观质量,就需要有一个很好的质量评价方法。也是基于这个目的,我开始学习和研究一些更好的面向人眼视觉的质量评价方法,进入到视觉质量评价这个领域。
01 回顾:视觉质量评价的背景
本次分享内容主要从以下三个方面展开:首先是回顾,介绍下目前面向视觉信号的质量评价的背景、意义以及目的;然后介绍下视觉质量评价目前存在的一些问题以及我们对该领域问题的一些思考;最后介绍下目前我们的一些工作,对我们提出的细粒度视觉质量评价问题的研究进行些展望。

首先,我们看一下视觉质量评价的目标。视觉质量评价就是希望我们给出图像、视频或者更广义的视觉信息,如光场图像、全息图像等的质量高低的评价。传统使用比较多的是基于信号的评价方法,对于图像来说它的信号就是像素,这种基于像素的质量表示例如PSNR,或者其对应的失真度量就是MSE(均方误差)。它和人眼的感知质量之间是有明显差异的。
这里我放了一个对比的图像,大家也可以很清楚的看到,左上是原始图像,没有任何失真,所以它的MSE是0。我们可以用各种方式对图像进行处理,让它的失真达到相同的均方误差,也就对应相同的PSNR。比如说第一个,可以调节一下对比度,第二个做均衡化。第三个(第2行第1个)进行JPEG压缩,后边两幅可以通过模糊和加噪声,使他们的均方误差可以都接近225。但是人眼看起来,它们的主观质量差异是非常明显的,这个例子充分证明这种基于像素的PSNR的度量是不能准确反映人眼的感知质量的,甚至与人眼的感知差异是非常大的。因此,我们希望在这个领域研究一种比较好的方法,能够跟人眼感知的主观质量更一致,这就是图像视觉质量评价的目标。
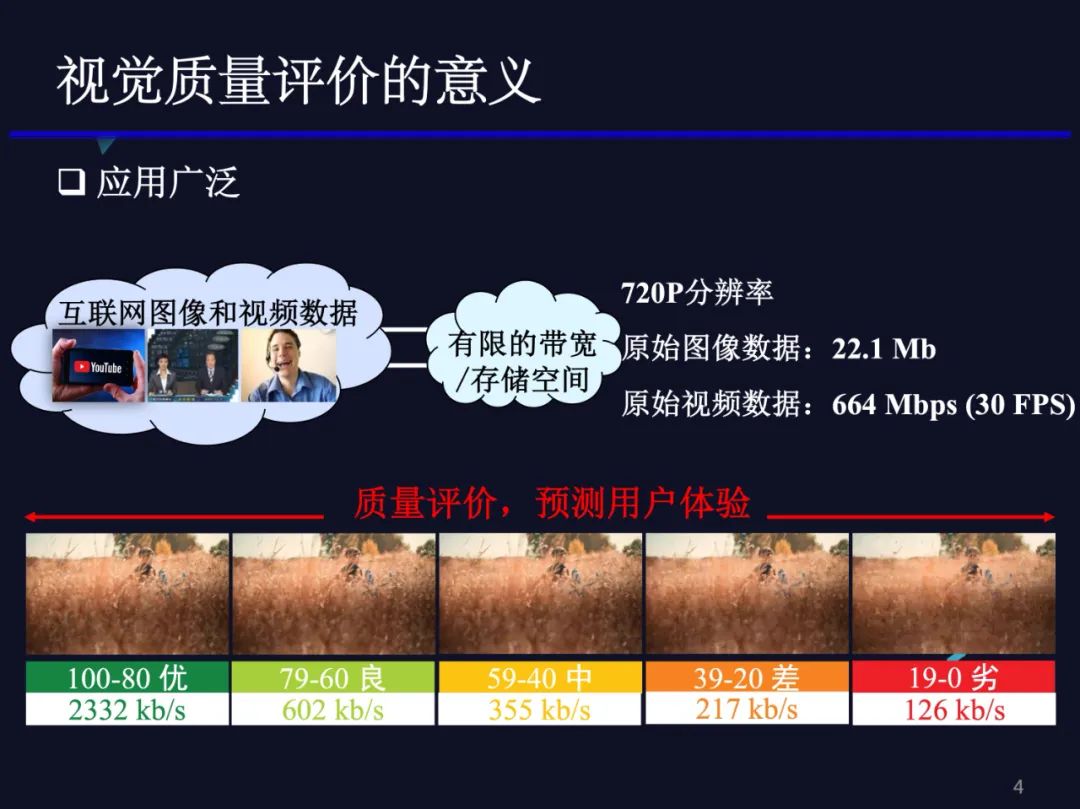
视觉质量评价无论是在流媒体,还是涉及到图像视频的各种算法中都非常重要。众所周知,目前互联网上大量的图像视频要送到用户端必须经过压缩的过程,有损压缩不可避免的要引入失真。我们需要质量评价方法监测图像或者视频,用户端感受的质量是多少,如果质量特别差的话,我们就需要适当提高码率保证良好的用户体验。
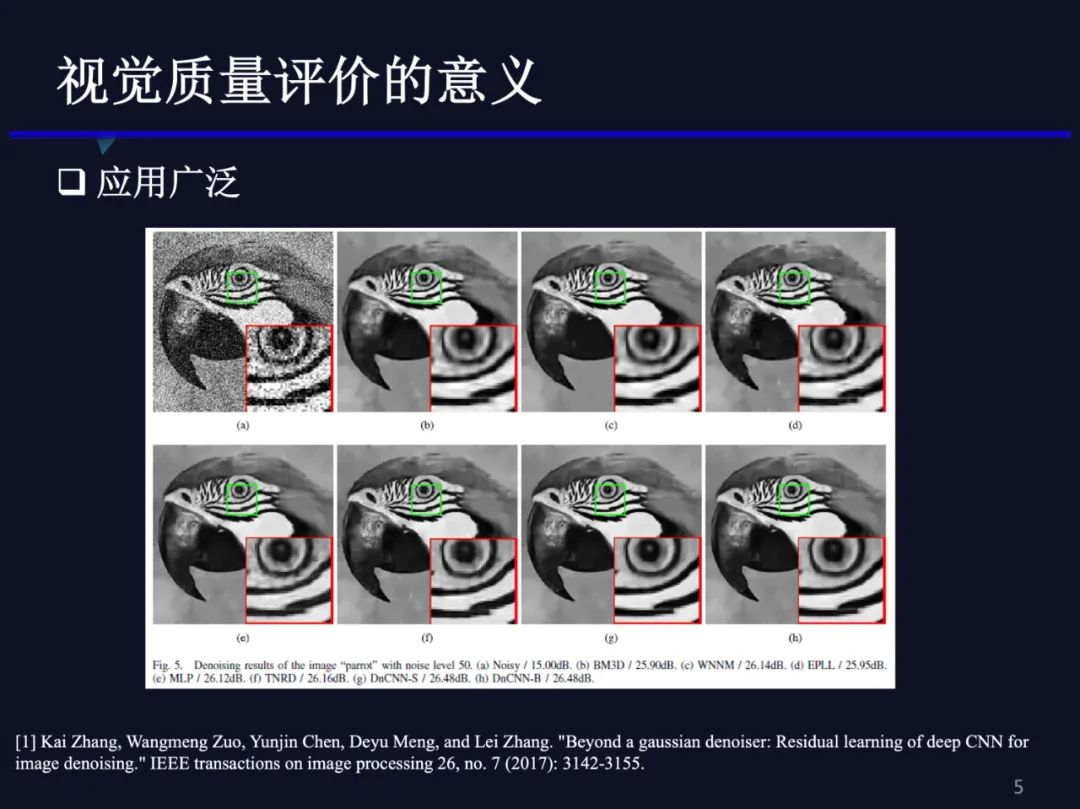
除此之外,我们设计的各种图像或视频处理算法,比如增强,图像复原、去噪,需要有一个质量评价的标准衡量。以图像去噪为例,我们每提出一个新的去噪方法都要展示其性能,需要呈现去噪之后图像的质量,经典的衡量指标就是PSNR,也会借鉴部分质量评价领域的新指标,比如SSIM。但实际上,其它很多质量评价方法很少被用到。由于缺少令人信服的质量评价方法,往往就只能贴出图片来比较。由此可见,无论是在流媒体的传输应用还是图像、视频的算法设计上,我们都急需比较好的、与人眼感知质量更接近的质量评价算法,所以视觉质量评价具有非常重要的价值。

视觉质量评价方法可以分成两类,主观质量评价和客观质量评价,我们通常认为第一类是最准确的一种。国际标准化组织对于主观质量测试方法也给出了很多详细的规定,比如测试过程,观测距离等。这种方式对于评测环境的要求相对苛刻,而且需要很多人给图像打分,人力成本和时间成本都很高。还有最重要的一点是主观质量评价方法不能用于算法优化。所以主观质量评价方法在实际中很难应用。因此,视觉质量评价主要是研究客观质量评价的方法,希望能用数学的方式来建模人眼视觉对图像/视频信号的感知质量。
从是否有参考图像/视频的角度,我们可以将客观质量评价方法分为有参考质量评价方法和无参考质量评价方法。有参考质量评价方法是指在评价质量的时候,有无失真的图像作为参考;无参考质量评价方法是指没有任何参考图像,只有失真的图像/视频,直接预测它质量的高低。
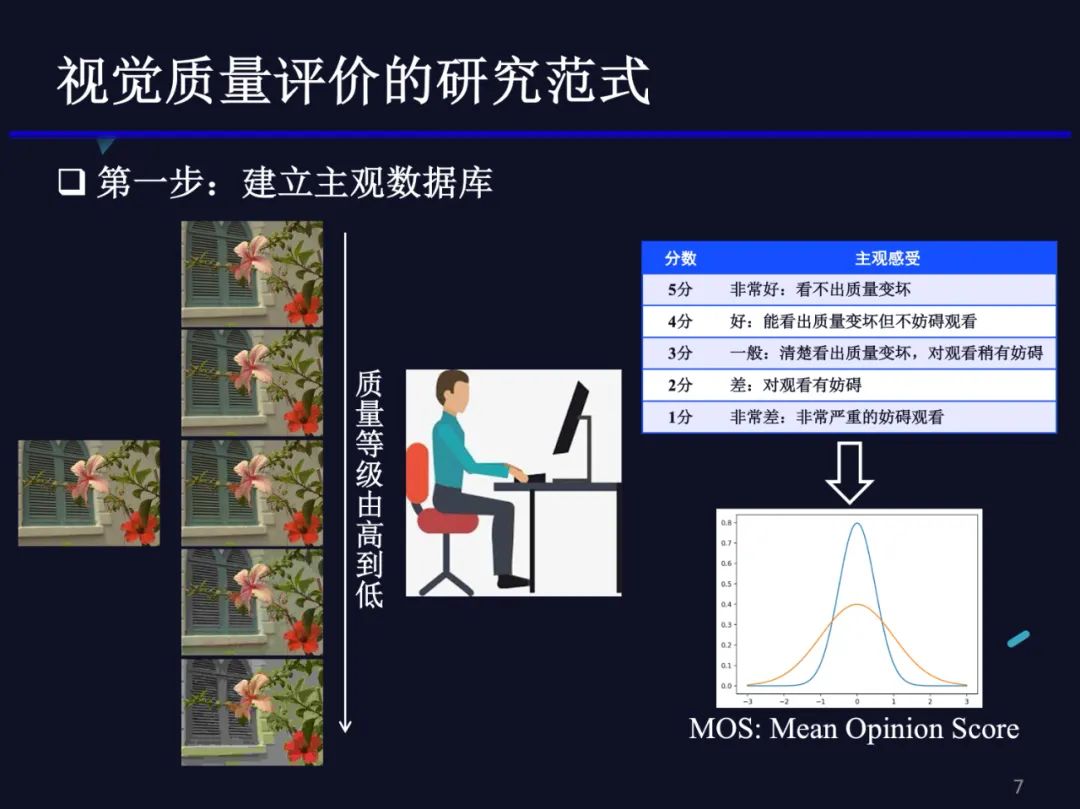
视觉质量评价研究的范式基本上可分为两步:(1)建立一个标注了主观质量的图像数据集。一般数据集的构建需要首先收集高质量无损图像,目前已有的数据集大约选择20~30左右的图像。对每个图像人工设置不同的失真和失真等级。比如对于压缩失真而言,通常使用JPEG编码器将每张图像从最好质量到最差质量压缩为5个等级。然后邀请测试人员对失真图像进行主观打分,通常邀请20~30人左右,将这些失真图像随机地呈现给每位测试人员,要求其给出对应的质量分数,比如采用1-5分的5分制打分法。将每张图像的分数平均得到所谓的主观分数(MOS),将其认为是人眼对该图像的主观感知质量。
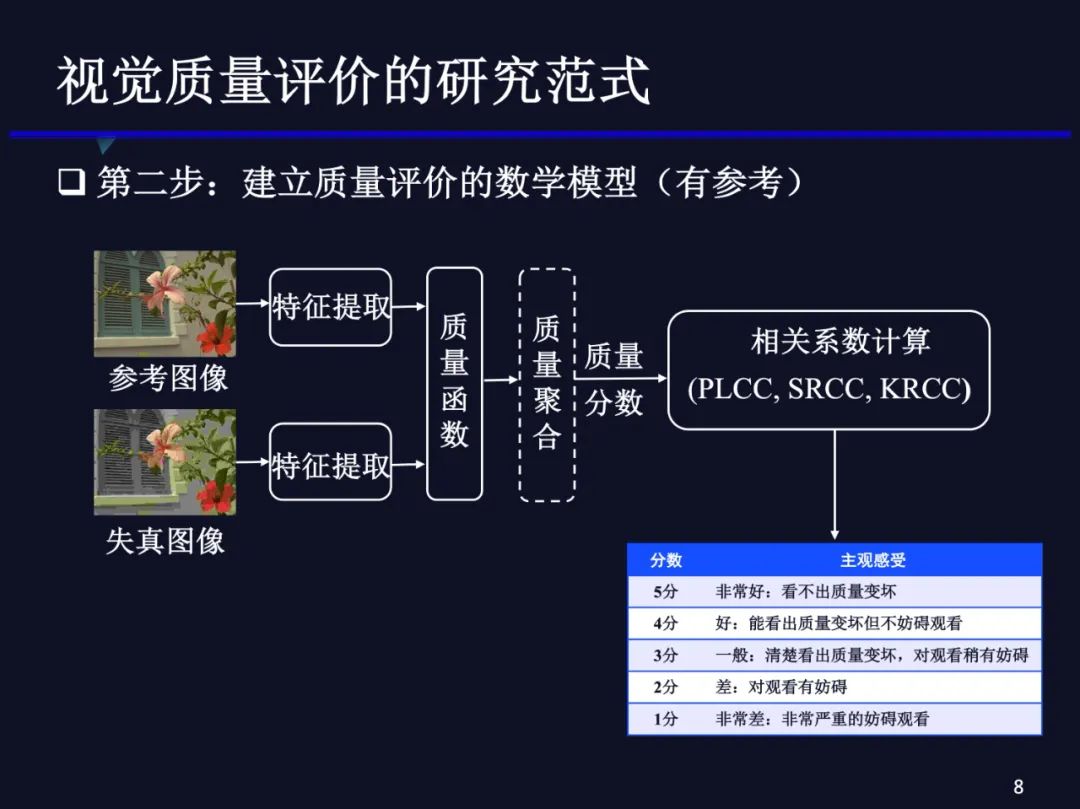
(2)设计图像客观质量评价方法。对于有参考的质量评价方法,我们可以分别提取失真图像和参考图像的特征,建立不同的质量函数模型来计算特征的失真,局部特征的失真可以通过聚合或者回归得到客观质量分数。质量评价方法的性能需要用得到的客观质量分数和主观MOS分数计算相关系数,如果相关系数越接近1,那证明客观质量模型与人眼感知质量越接近,性能越好。
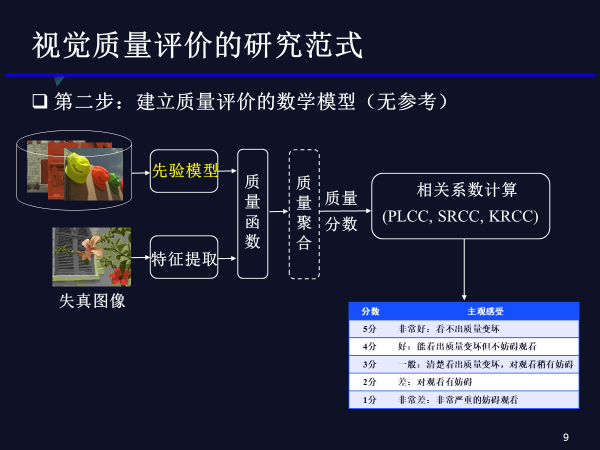
无参考的质量评价方法也和上述方法类似,唯一的区别就是它没有参考图像,需要通过对大量图像进行统计分析得到高质量图像的先验分布特性,利用失真图像的特征与高质量图像特征的先验分布进行比较,得到客观质量分数。大家沿用这种范式做了二、三十年,提出了众多质量评价方法,其性能也越来越好。但是我们在做视频编码的时候,这么多的高效的质量评价方法在实际中依然难以得到满意的结果,这就是我们今天要讨论的一个问题。

看一个具体的例子:以TID2013数据集为例,其中参考图像只有25幅。在压缩失真类型中,每幅图像分了5个失真等级,有125个压缩失真图像的主观分数,记作S,其中Si分别代表第i个质量等级的25个主观分数。
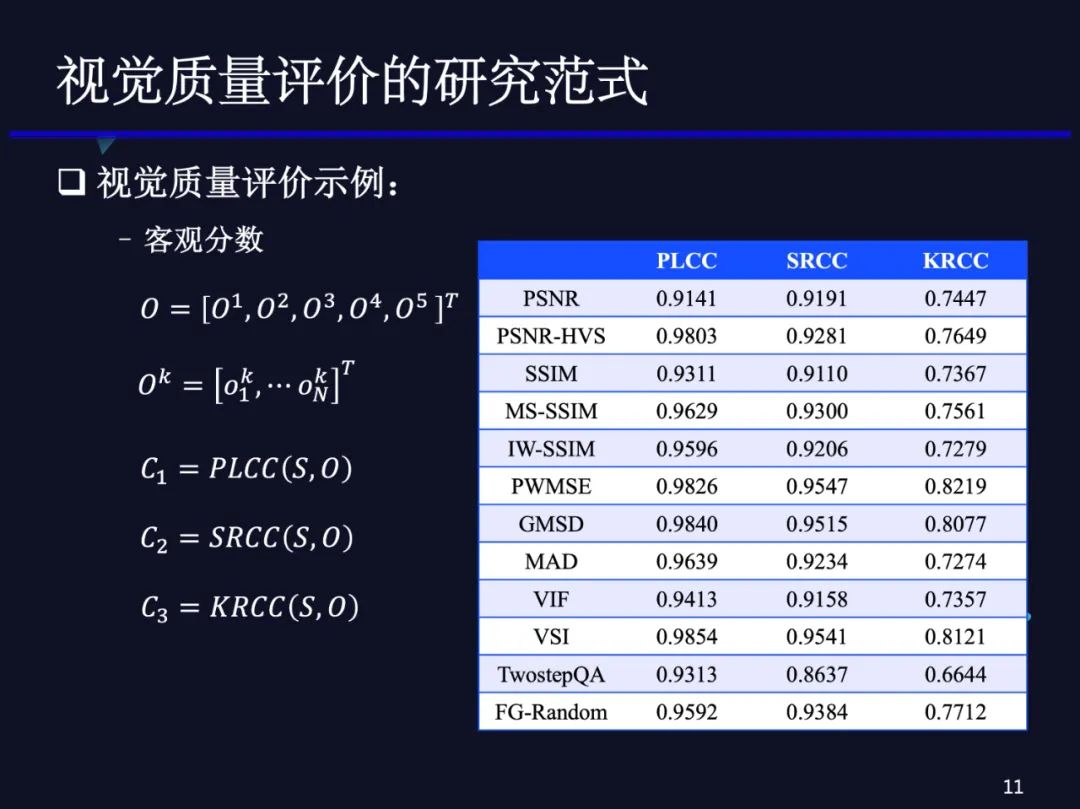
进一步,我们选择多种经典的客观质量评价模型,例如:PSNR、SSIM、MS-SSIM等,对125幅压缩失真图像计算客观分数,记作O,其中Oi表示第一个质量等级中25幅压缩失真图像的质量分数。直接计算PLCC、SRCC、 KRCC得到C1、C2、C3。如表所示,近年来质量评价方法的性能不断在提升,PLCC已经超过了0.98。这么高的相关系数,按道理来讲,质量评价方法应该是可以满足应用需求了。
02 思考:视觉质量评价的问题
但是在实际应用时效果却不尽如人意,到底问题出在了哪里呢?

在视频编码中,国际标准从MPEG-2到VVC依然还是采用PSNR作为质量指标。在图像/视频处理算法中,实际上用的最多的还是基于像素或特征的L2范数。SSIM、MS-SSIM等很少被加入到算法中进去优化,即使加入算法中,其带来主观质量的提升也很小。这些质量评价方法在实际应用中没有发挥出它在质量评价问题上那么显著的性能提升。
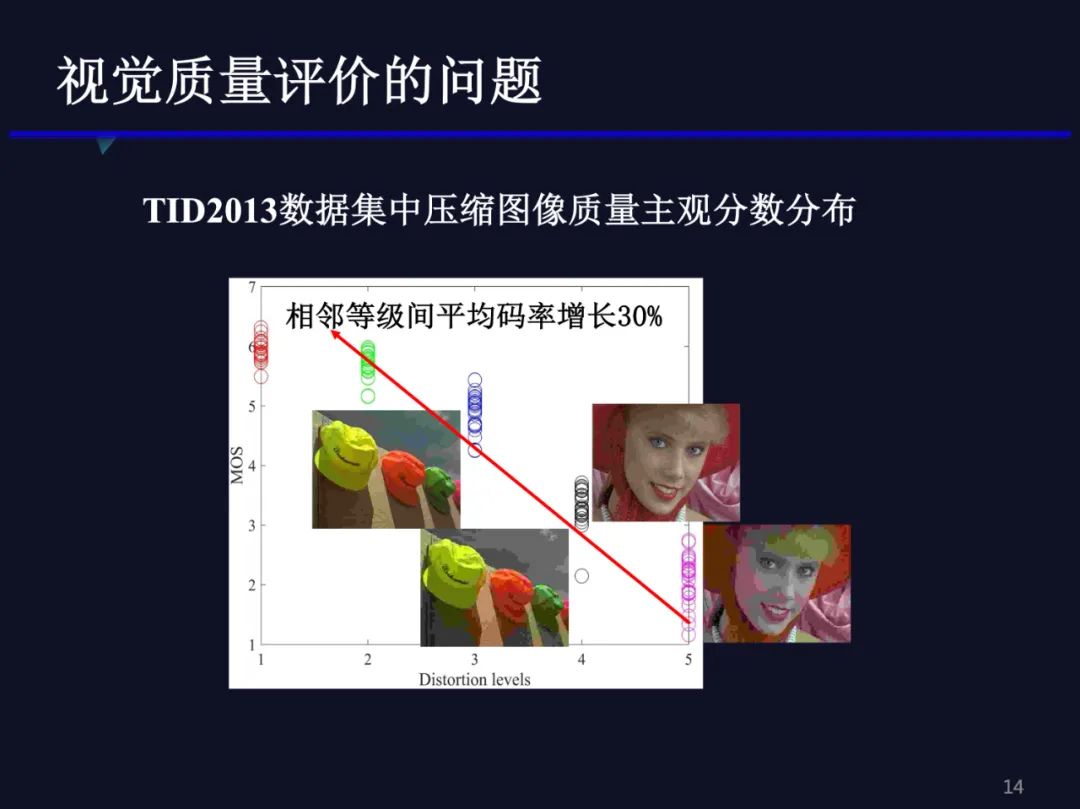
到底哪里出了问题?我们把TID2013压缩图像数据集展开看一下。图中最右侧代表第五个失真等级对应的主观分数的分布,其左边相邻的是第四个失真等级对应的25个主观分数的分布,依次类推。我们可以发现两个问题:
(1)不同失真等级间质量分数差异非常明显,这样大的质量差距应该很简单的质量评价模型就可以判断正确,甚至通过压缩图像中的质量因子,比如JPEG中的QF,可以较为准确地判断出压缩图像的质量。(2)我们又计算了这相邻等级之间压缩图像的码率,大约平均增长30%。在实际中,我们很少需要判断码率在相差30%时两个压缩图像质量的高低。这种情况,PSNR应该也可以比较准确地反映质量排序,一般是码率高的图像质量好,也就是说上述方式设计的这种质量评价数据集与实际需求并不一致。对于压缩问题,实际需要的质量评价数据集是:采用不同的压缩方法,将图像压缩到相同的码率时,判断哪个压缩图像的质量好,这样可以比较符合相同标准的不同编码器的性能;另外的应用是,采用同一个编码器将图像压缩到接近的码率,判断其是否有人眼能感知的质量差异,从而支持流媒体传输应用。实际中,不需要对码率相差30%甚至更大的图像进行质量比较,它们之间的质量差异通常是非常明显的。我们可以先把不同等级间的图像质量的评价看作是粗粒度的质量评价问题,而相同等级内的质量评价问题看作是细粒度的质量评价问题。
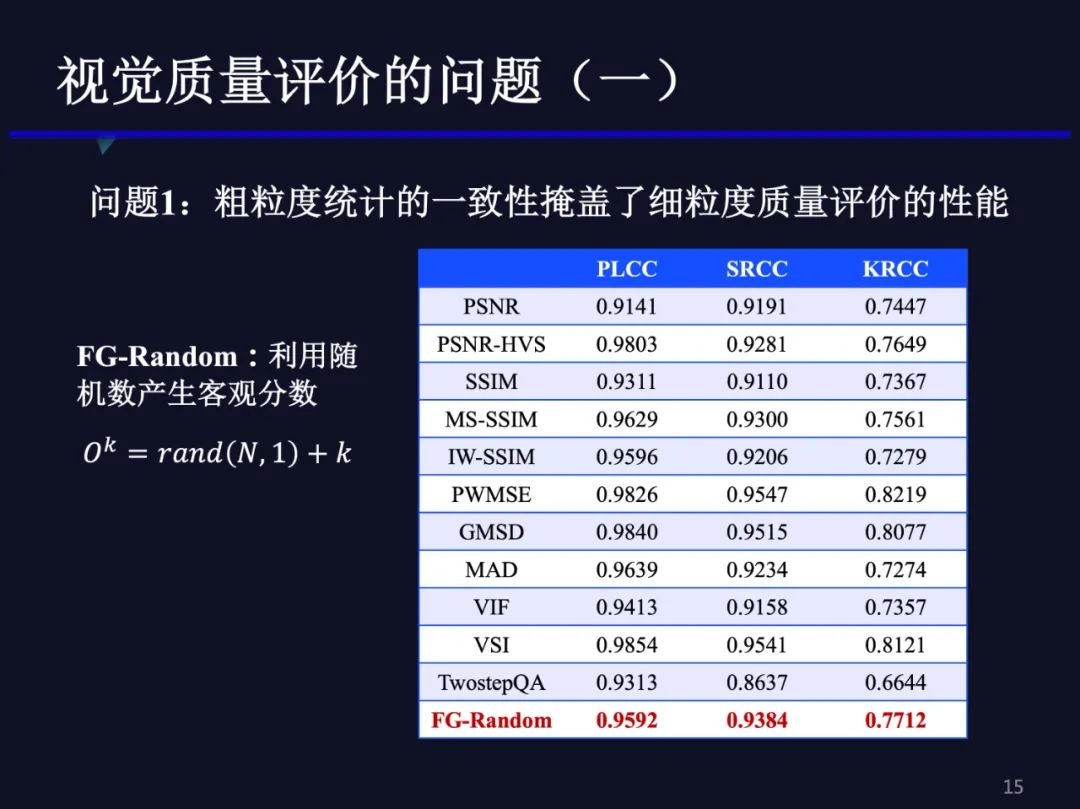
我们发现在已有的质量评价数据集中,粗粒度质量评价的比例是很高的。如果采用现有质量评价的范式,S和O包含了较多的粗粒度质量评价也包含了较少的细粒度的质量评价。如果混合计算会存在第一个问题:粗粒度统计的一致性掩盖细粒度质量评价的性能。也就是说我们评测的时候统计结果,PSNR或SSIM和主观质量的相关系数达到0.91、0.98这么高,其实只是把粗粒度质量排序,即不同等级之间的质量排序评价正确了,掩盖了相同等级内质量评价的错误。为验证上述论断,我们采用了一种随机数产生客观分数的方法,记作FG-Random。该方法得到的客观质量分数在TID2013压缩图像上跟主观分数的相关系数一样可以达到0.96。当然,这个分数并不是纯随机的,这个随机函数是这么写的:生成25个0到1之间的随机数加了一个k,就是质量等级是1时,客观分数就是1-2之间;质量等级是2时,分数就在2-3之间,也就是说不同等级之间分数相差为1。这个结果证明只要把粗粒度的质量level判断对了,质量相关系数就会很高,会超过很多方法,从侧面说明了传统方法可能只是判断出了不同level之间粗粒度质量的排序。
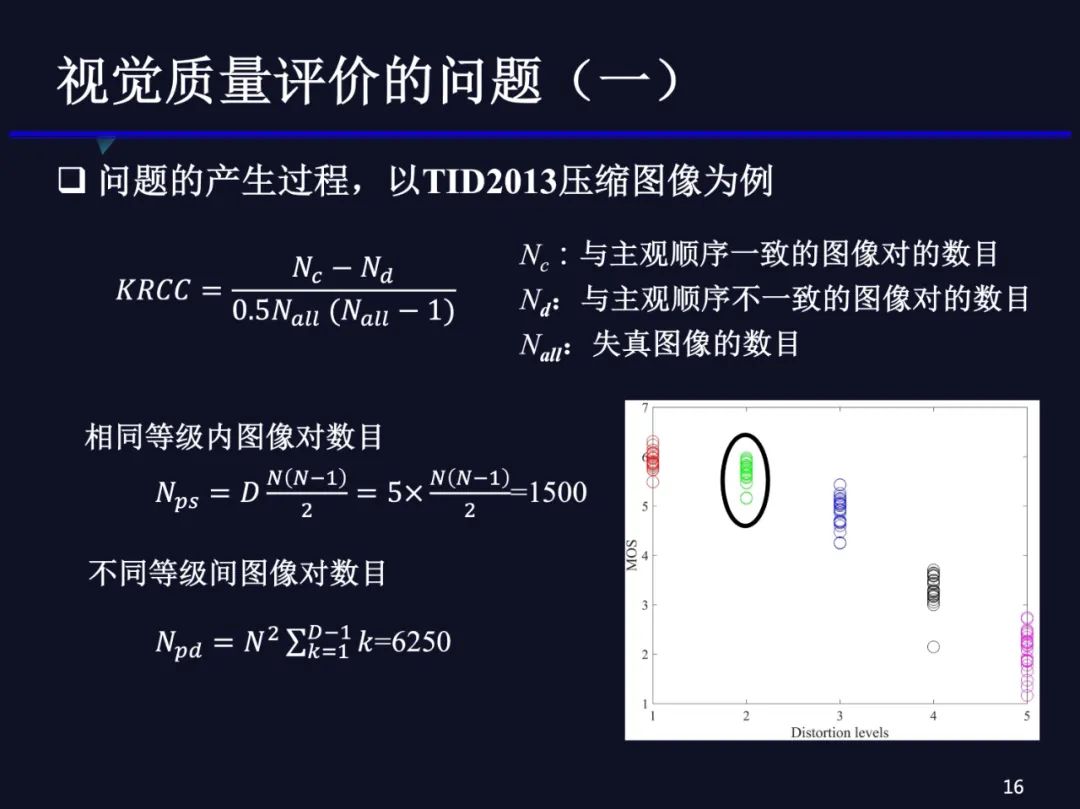
这样可能大家觉得还不够充分,我们做了一个理想化的,从理论上分析下这个事情。KRCC公式里面有三个符号:Nc,Nd,Nall 。Nc 是客观分数与主观分数排序一致的图像对的个数,Nd 是客观分数与主观分数排序不一致的图像对的个数。Nall 是所有失真图像的数目。KRCC的分母是一个组合数,就是所有失真图像两两组合的对数,分子是主客观分数一致图像的对数减去不一致的对数,如果所有图像对数的主客观分数都一致的话,相关系数就是1。
TID2013数据集里,同一个等级内有多少个图像对呢?同一个等级内有25个失真图像,那组合一下,每个等级内有n*(n-1)/2个图像对,有5个失真等级,共计1500对。不同等级之间有多少图像对呢?那就很多了, 大家有兴趣可以算一下,共计有6250对。我们看到,如果用KRCC计算时,相同等级内组成的图像对数要远远小于不同等级之间的图像对数。
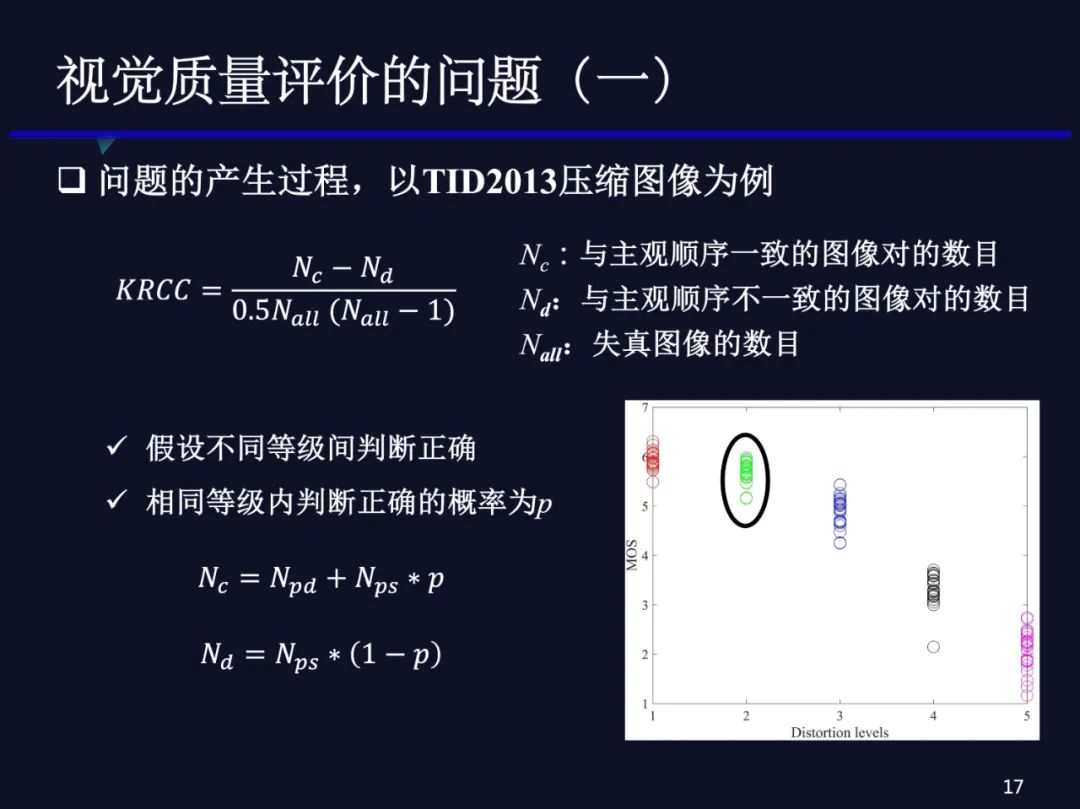
我们进一步做一个假设,假设质量评价算法能够准确判断不同等级的质量排序,相同等级之间判断正确的概率是p,Npd 表示不同等级之间图像对的个数。Nps 表示相同等级内图像对的个数,那么可以直接计算出Nc 、Nd 。
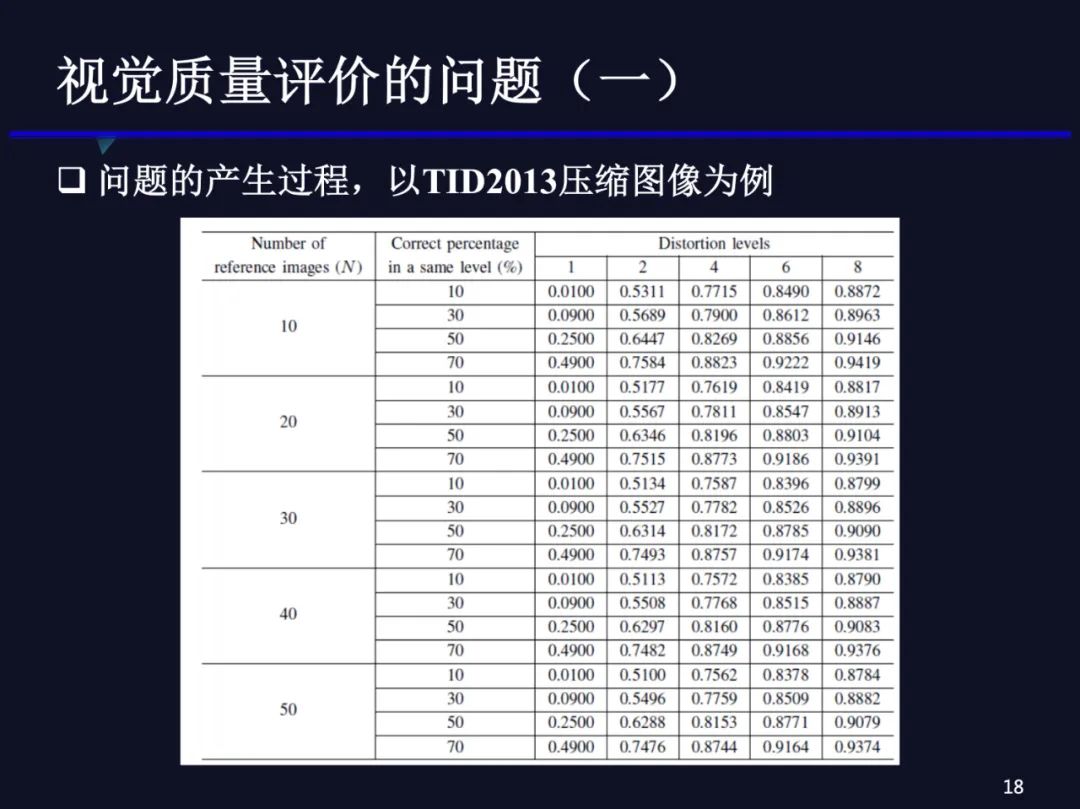
我写了个简单的程序计算不同数量的参考图像、不同失真等级和相同等级内判断正确的图像对的概率为p时,KRCC的值的分布。从上表可以看出,当只有4个失真等级时,相同等级内只有10%的图像对质量顺序判断正确,相关系数就可以达到0.77以上。当然,随着等级内判断正确的数量越多,相关系数越高。我们通常用的数据集是20-30幅参考图像,一般用4-6个失真等级。可以看到,理论上分析,我们只需要把不同等级之间判断正确,KRCC系数就可以达到0.8甚至0.9。然而,那些经典质量评价方法的KRCC系数也只有0.7、0.8左右,所以进一步验证了这些方法只是把不同等级之间的质量排序正确了,内部排序正确的概率可能只有10%左右。

更进一步,我设计了一个等级间判断正确,等级内随机判断的程序,其中O1,…,O5是随机数生成的客观分数,代表不同等级的客观分数,然后把它组成一个向量,S1,…,S2也是随机数生成的主观分数组成一个向量。分别计算两个相关系数,(1)相同等级内部,O1和S1计算相关系数,(2)不同等级组合的向量计算相关系数。我们会发现相同等级内相关系数几乎为0,因为都是随机数。不同等级组合的向量的相关系数超过0.96。也就是说,不同等级之间判断对了,就可以到这么高的相关系数。
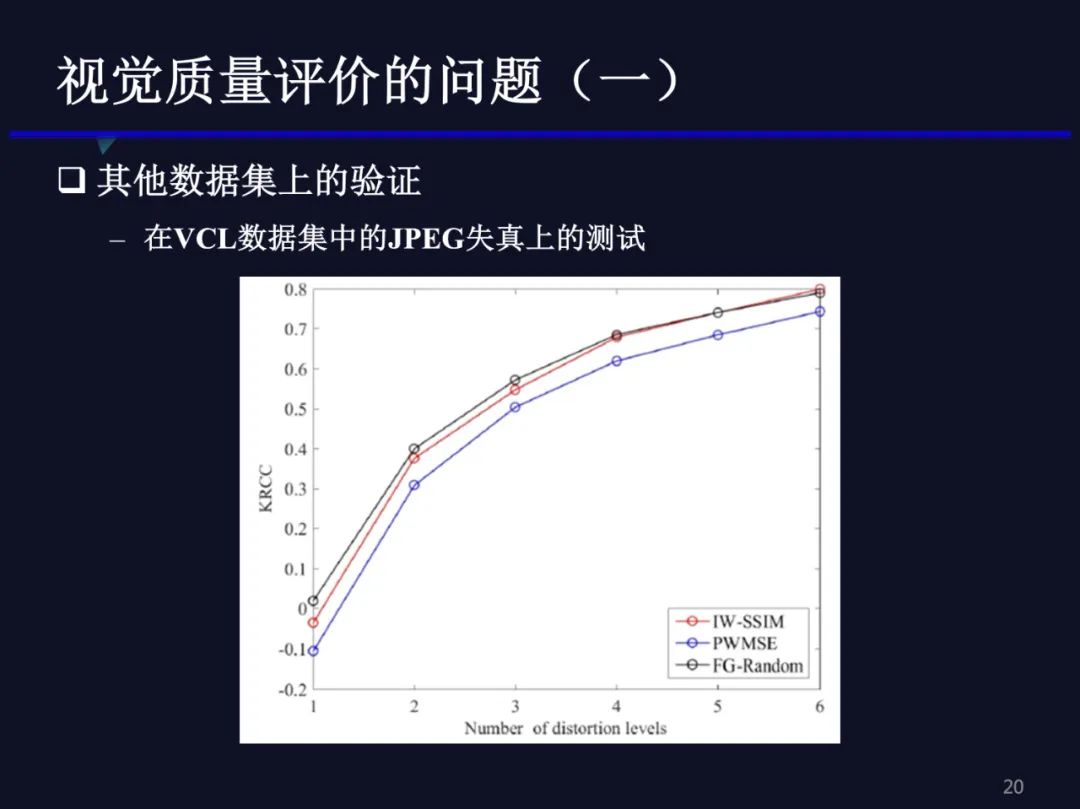
我们在实际的数据集上进一步验证,这个验证是在VCL数据集的JPEG失真图像上进行的。上图横坐标是失真等级的数量,该数据集的JPEG失真图像共有 6个失真等级,我们依次增加失真等级数量,可以看出,在最低质量等级上IW-SSIM或PWMSE这些方法得到的相关系数其实都是在0附近。也就是说,只有一个失真等级时,这些图像的质量差异是很接近的,我们把这种质量差异称为细粒度的质量差异,已有的质量评价方法几乎完全失败。随着我们增加一个失真等级,两个失真等级时KRCC系数迅速提高。随着失真等级数量的增加,相关系数不断提高。该实验更进一步验证了已有的质量评价方法只是能够区分不同粗粒度之间质量的高低,细粒度质量评价上确实没有效果。
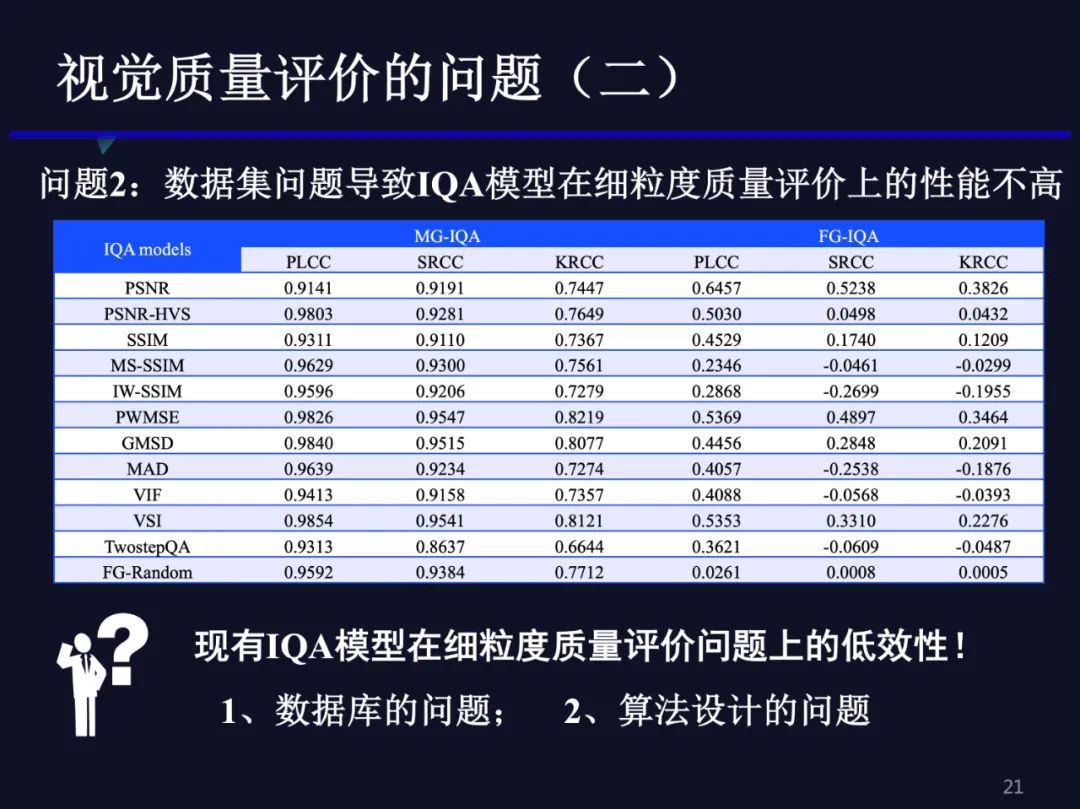
图像/视频质量评价的研究已经持续了二、三十年,大量的方法被提出来,难道真的就没有效果吗?我们又做了一组实验,来探究这个问题。像刚才那样,我在已有数据集TID2013相同等级图像上,计算PLCC,KRCC或SRCC相关系数,然后把不同等级计算得到的相关系数取平均,以此作为细粒度质量评价度量,在上表的FG-IQA部分。我们发现在FG-IQA的测量中PSNR的相关系数反而是最高的,其他方法的相关系数甚至都没有超过0.5。我们用传统的质量评价范式,就是把所有的不同失真等级的客观分数和主观分数一起计算相关系数,在上表的MG-IQA部分,它就可以到0.9、0.8以上。
所以我们想这种细粒度质量评价上性能不高可能的原因有两个:第一个是大家之前设计的时候没有考虑到细粒度差异的特性,可能算法上未来需要去探索;另外一个原因可能是传统的质量评价数据库的设计可能不是很合理。因为传统的质量评价数据库通常是把很多图像随机打乱进行主观打分,这种方式被试人员难以发现细粒度质量的差异。两个失真特别接近图像只有摆在一起,反复对比才可能看出质量差异,传统的质量评价数据库采用随机呈现的方式,使得数据库的主观分数可能不够准确,所以这些方法去做相关系数计算的时候也不可靠。

到底是不是这样一个问题呢?我们重新建了一个质量评价的数据库。我们选择同一种压缩标准JPEG,4种不同优化方法得到的编码器,将每幅图像压缩到相同的码率点附近,在这里,我们选择了100幅参考图像和3个码率点(b1,b2,b3 分别对应低码率、中码率和高码率),由于编码器符合相同标准,在相同码率下图像质量是接近的,由于不同编码器的优化方法不同,相同码率下不同编码器得到的图像质量也存在细微的差异。这个数据集是完全符合实际问题对质量评价方法的需求。为了准确地标识不同图像的质量排序,我们将同一个参考图像压缩成的相同码率下的4幅失真图像进行两两对比的质量排序。
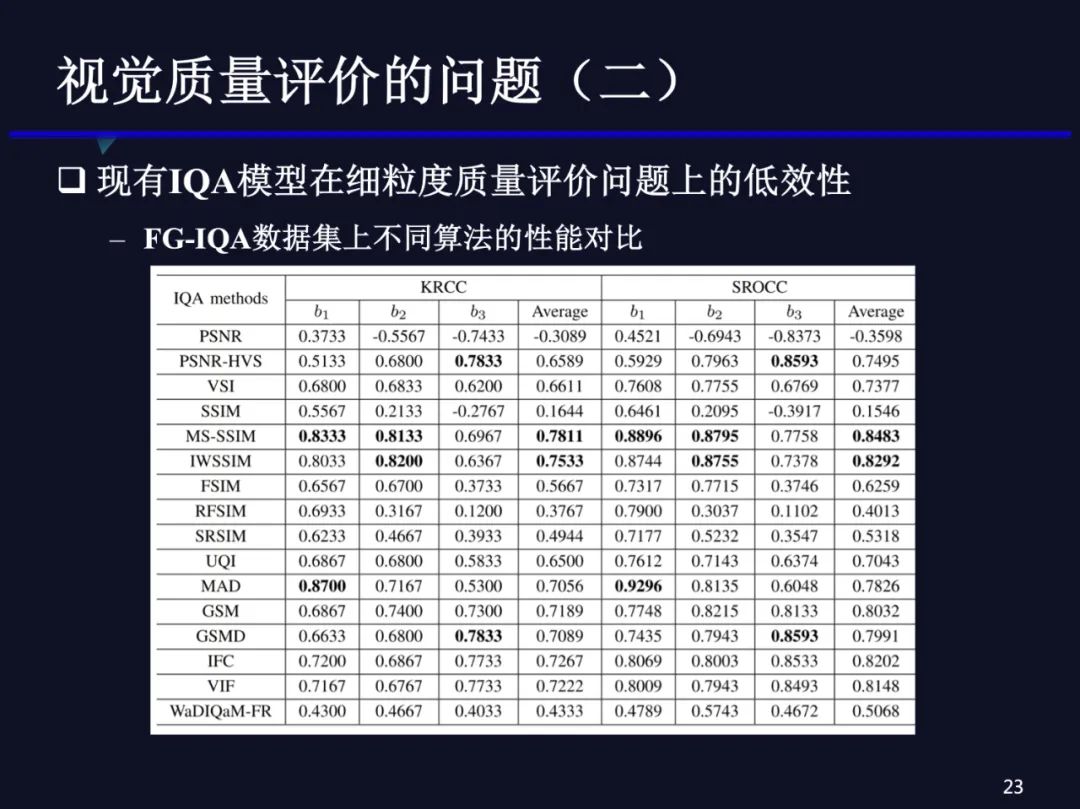
从这个数据集上可以进一步过去二、三十年大家提出的质量评价方法还是有效果的,只是跟传统数据集上的表现可能不太一致。我们发现PSNR确实跟人眼的感觉差异比较大,MS-SSIM、SSIM或IWSSIM比PSNR提升很多,KRCC达到0.8以上,但是这些算法的表现和传统数据集上的就不一致了,比如有的方法在传统数据集上可能会比MS-SSIM好,但是在细粒度的数据集上,我们发现MS-SSIM还是很好的。我们还看到一个现象:在低码率b1下,不同算法的相关系数都很高,码率增加后相关系数会降低,这说明高码率图像的质量评价更难。
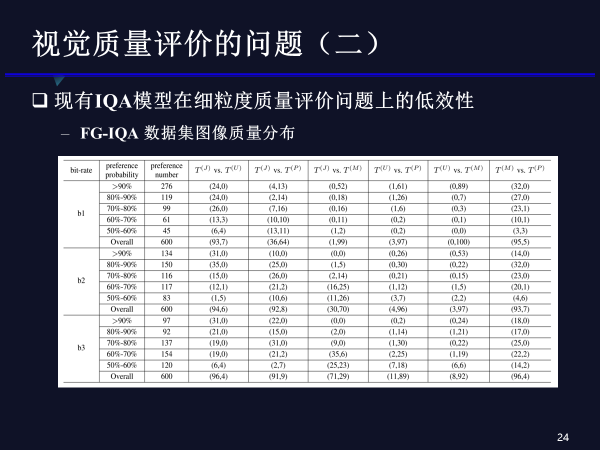
我们想知道是为什么,所以进一步对数据集进行分析。因为同一幅图像在相同码率下对应4幅失真图像,可以组合成6个图像对,因此该数据库中,每个码率点下共计有600个图像对。只要有超过50%的人认为图像A比图像B质量好,就标记为图像A质量好于图像B。那么我们进一步将被试人员判断的比例进行分类,记作preference probability,其中>90%的部分表示,有超过90%的被试人员认为图像A比图像B质量好;80%-90%表示有80%到90%的被试人员认为图像A比图像B质量好;从上述表格中可以看出,在低码率时,人眼也可以比较容易地判断出细粒度图像质量高低,而在高码率时,图像质量差异进一步缩小,人眼也难以判断;所以我们认为质量评价方法不仅仅要能够体现图像细粒度质量高低的准确性,还应该体现图像质量差异判断的难易程度。因为我们不该苛责算法在人眼无法判断的质量差异的情况下,依然做出精准判断。
03 展望:细粒度视觉质量评价
考虑到上述这些问题,我们更多的是思考未来图像/视频质量评价问题该如何进行?我们认为未来的图像/视频质量评价应该更细致,重点研究细粒度质量评价问题。

在细粒度质量评价方向上,有一类问题一直在被大家所研究,就是恰可察觉失真(Just-Noticeable Difference, JND),就是人眼有50%的机会可以察觉到的失真的最小阈值。一个无损图像用QP=8或者10来压缩,虽然信号上有失真,但是人眼是感知不到这么小的失真的。甚至对于一些图像用QP=30来压缩,如图所示,很多人也看不出质量差异。我们认为JND反应的就是细粒度的质量差异。
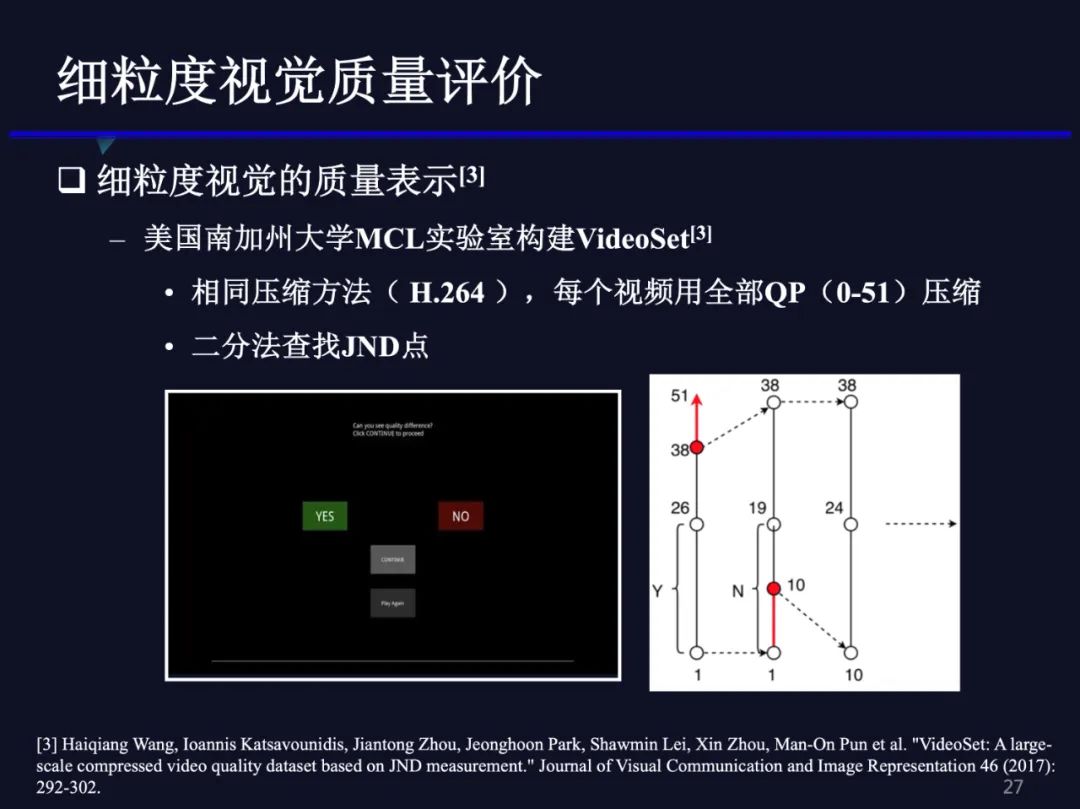
美国南加大多媒体通讯实验室构建了一个视频细粒度质量评价数据集,他们是用相同的压缩方法H.264, 对不同分辨率的视频用QP从0到51依次压缩,然后用二分法查找压缩视频的JND点。
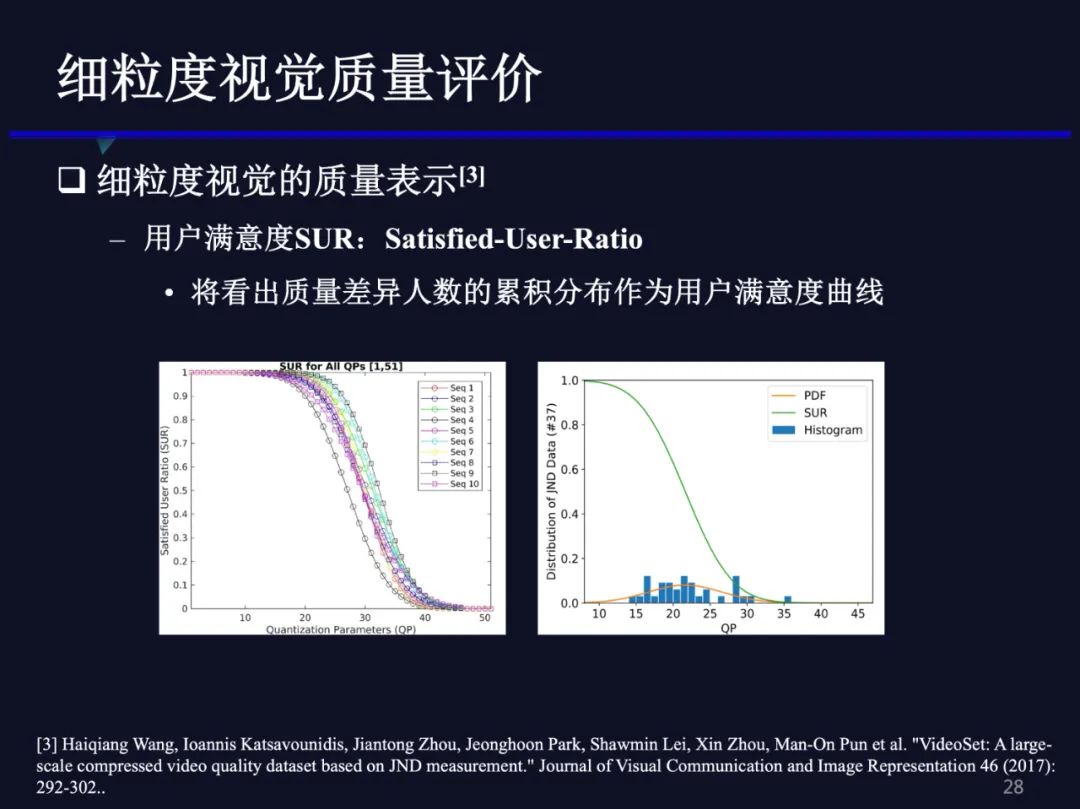
因为不同人眼的感知敏感程度不同,JND点就形成一个分布。如果用户没有看出质量差异,我们认为用户对当前视频是满意的,如果用户恰好看出了质量差异,我们认为用户对该视频质量表现出不满意。因此,将用户JND点的累计分布作为用户对视频质量的满意度的曲线,来表征视频质量,不仅包含了质量表示,也反映了用户的感知分布。
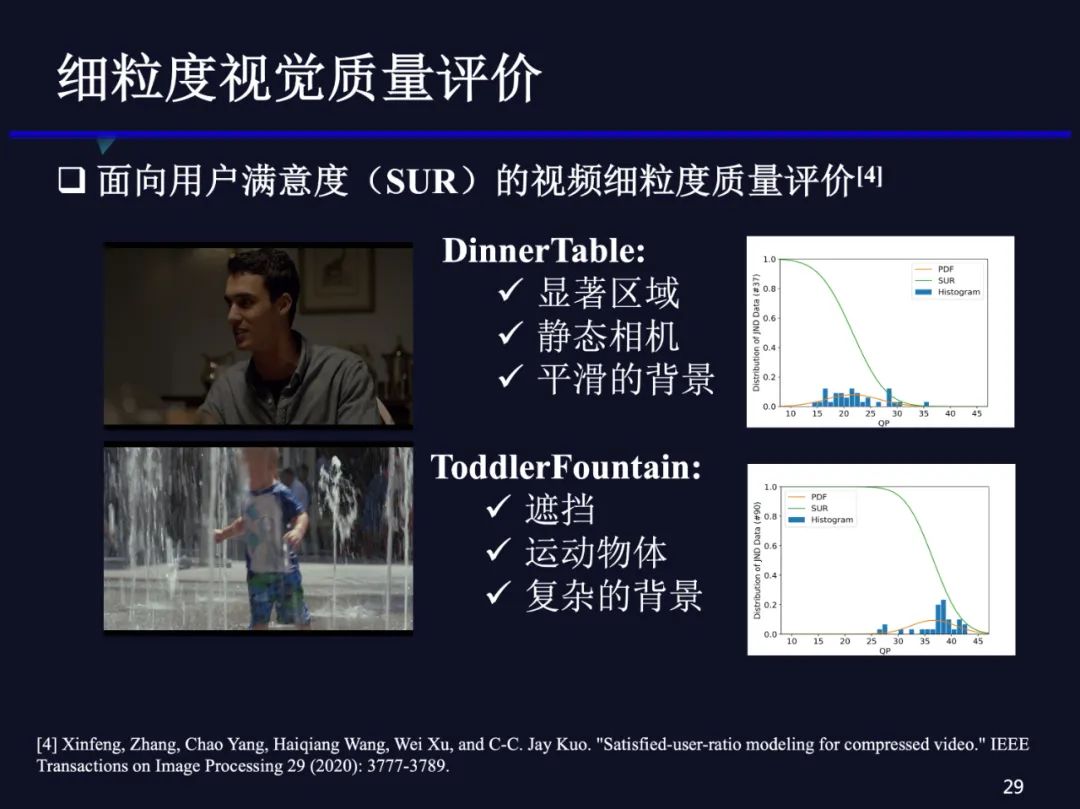
我们在数据集中发现,不同的视频用户满意度的分布差异还是很大的,例如视频会议的视频有比较明显的显著区域——人或者人脸,这时较小的失真用户就会感知到,所以这类视频的JND点的位置都比较靠近小QP位置。对于运动比较复杂的,比如水波纹或者小孩快速运动等,即使有较多失真,人眼也很难看出来,它们的JND点就比较靠后。
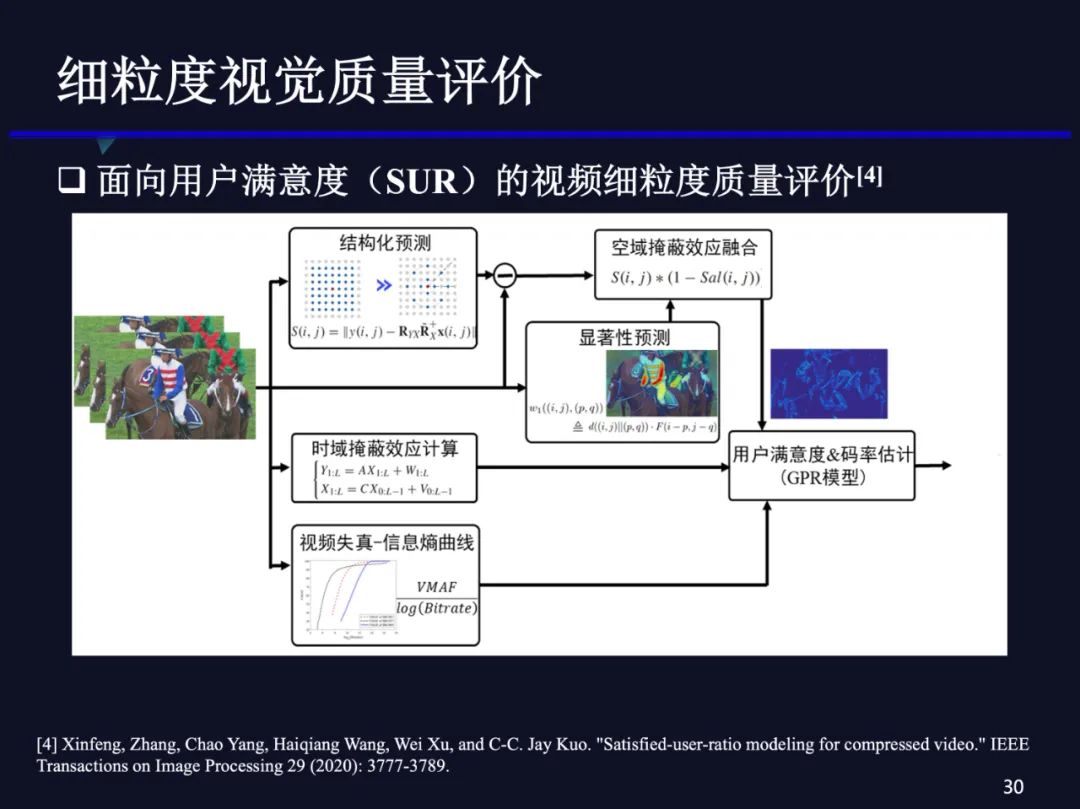
基于此我们做了一个预测模型:引入空域的掩蔽效应和人眼视觉显著性,以及时域运动的掩蔽效应。同时,我们引入VMAF的度量,把它作为一个参考,因为它可以和失真、码率建立起联系,然后将上述特征进行用户满意度的回归。
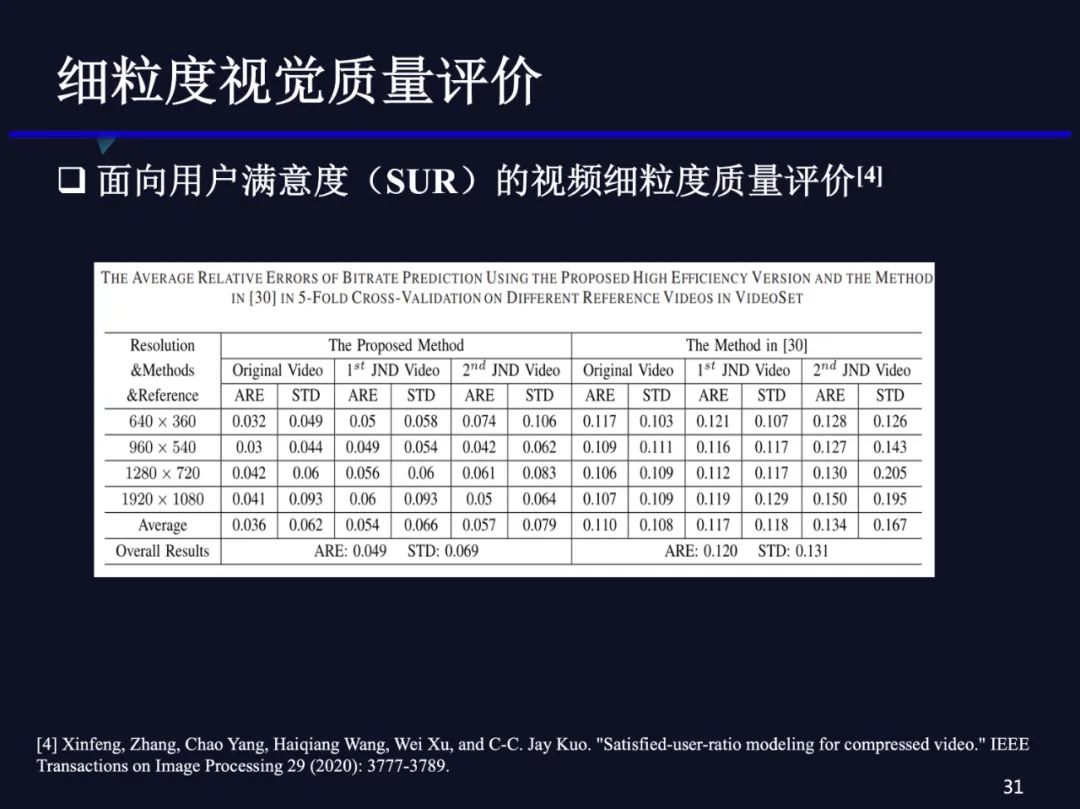
这个是我们算法准确度的一个结果,分别以原始视频、第一个JND点视频、第二个JND点视频为参考时,用户JND点码率的相对误差。
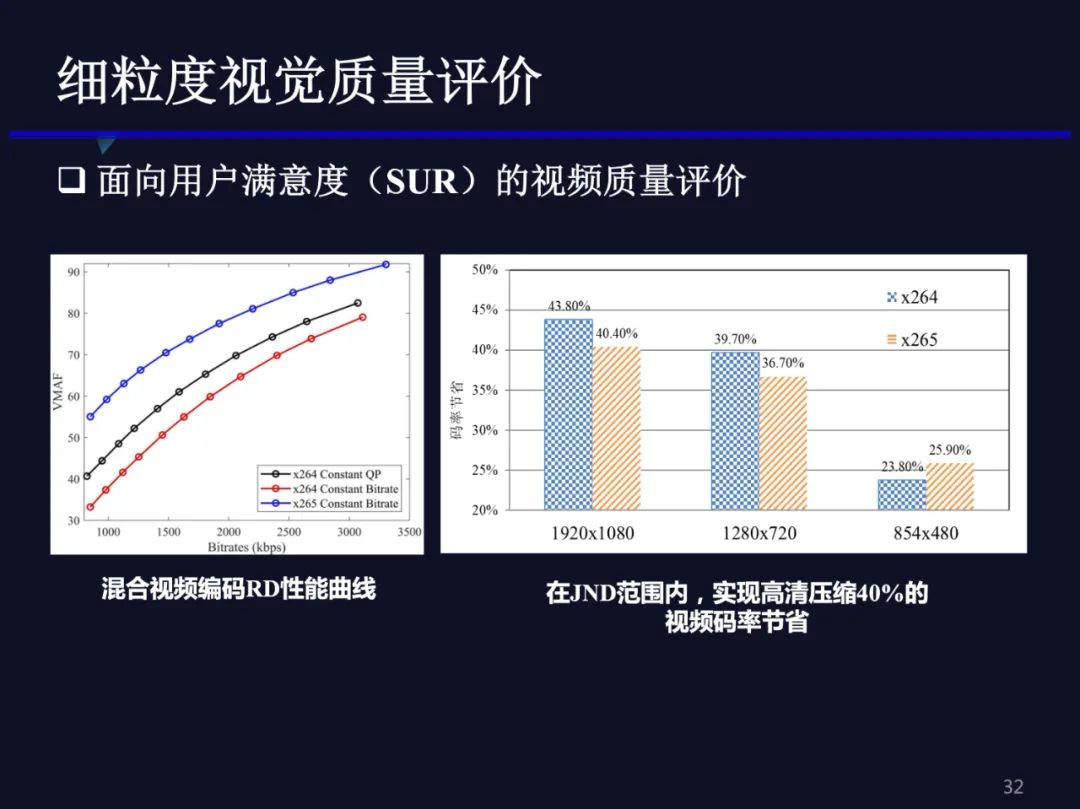
因为算法是基于H.264视频构建的,我们希望把它往H.265视频上迁移,因此,我们利用VMAF和码率之间的关系计算了一个迁移系数。通过实验发现,算法还是在264上得到的码率节省更多一些,H.265上会弱一些,但整体还是可以得到比较多的码率节省。

前面这些就是我们在细粒度质量评价上的一些初步探索。在这里,我们简单展望一下后续的一些研究方向。(1)涉及到不同内容、不同分辨率视频时,用户满意度模型效果还存在明显不足,不同图像或者视频处理任务上的细粒度质量评价研究,比如去噪问题,retargeting问题等。(2)人眼在细粒度质量差异感知上的特性,目前研究还不充分;(3)细粒度质量评价数据集的构建需要更多的人力和时间,难度要比传统的数据集构建更大;
此外,还有一个问题就是我们要在实际场景中应用质量评价方法,需要这种方法简单可导,可导才可以优化,所以在这个方向上,一些简单有效的质量评价方法可能是更为重要的。
最后,计算机视觉这几年研究进展很快,使得机器也成为了视频和图像重要的接收者,分析视频图像失真到什么程度,机器感知会发生变化,这种细粒度的分析可能也是未来的一个方向。

前面介绍到的相关工作有一些参考论文,大家有兴趣可以参考。
以上就是我本次分享的全部内容,谢谢大家!
▼识别二维码或猛戳下图订阅课程▼

喜欢我们的内容就点个“在看”吧!