python中用于请求http接口的有自带的urllib和第三方库requests,但 urllib 写法稍微有点繁琐,所以在进行接口自动化测试过程中,一般使用更为简洁且功能强大的 requests 库。下面我们使用 requests 库发送get请求。
requests库
简介
requests 库中提供对用的方法用于常用的HTTP请求,对应如下:
requests.get() # 用于GET请求
requests.post() # 用于POST请求
requests.put() # 用于PUT请求
requests.delete() # 用于DELETE请求当然还有更多的方法,这里只列举常用的。
安装
安装命令:pip install requests
发送get请求
get请求参数格式说明
requests 中的 get 方法源码如下:
defget(url, params=None, **kwargs):r"""Sends a GET request.:param url: URL for the new :class:`Request` object.:param params: (optional) Dictionary, list of tuples or bytes to sendin the query string for the :class:`Request`.:param \*\*kwargs: Optional arguments that ``request`` takes.:return: :class:`Response <Response>` object:rtype: requests.Response"""kwargs.setdefault('allow_redirects', True)return request('get', url, params=params, **kwargs)参数说明:
url,即接口地址
params,接口参数,可选(即可填可不填)
**kwargs,可以添加其他请求参数,如设置请求头headers、超时时间timeout、cookies等
不带参数请求
import requestsres = requests.get(url="https://www.cnblogs.com/lfr0123/")
# 请求得到的res是一个Response对象,如果想要看到返回的文本内容,需要使用.textprint(res.text)带参数请求
import requestsurl = "http://www.baidu.com/s"
params = {"wd": "给你一页白纸-博客园", "ie": "utf-8"}
res = requests.get(url=url, params=params)
print(res.text)加入请求头headers
有些接口限制只能被浏览器访问,这时按照上面的代码去请求就会被禁止,我们可以在代码中加入 headers 参数伪装成浏览器进行接口请求,示例如下:
import requestsurl = "http://www.baidu.com/s"
params = {"wd": "给你一页白纸-博客园", "ie": "utf-8"}# User-Agent的值为浏览器类型
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36"}res = requests.get(url=url, params=params, headers=headers)
print(res.text)部分结果如下:
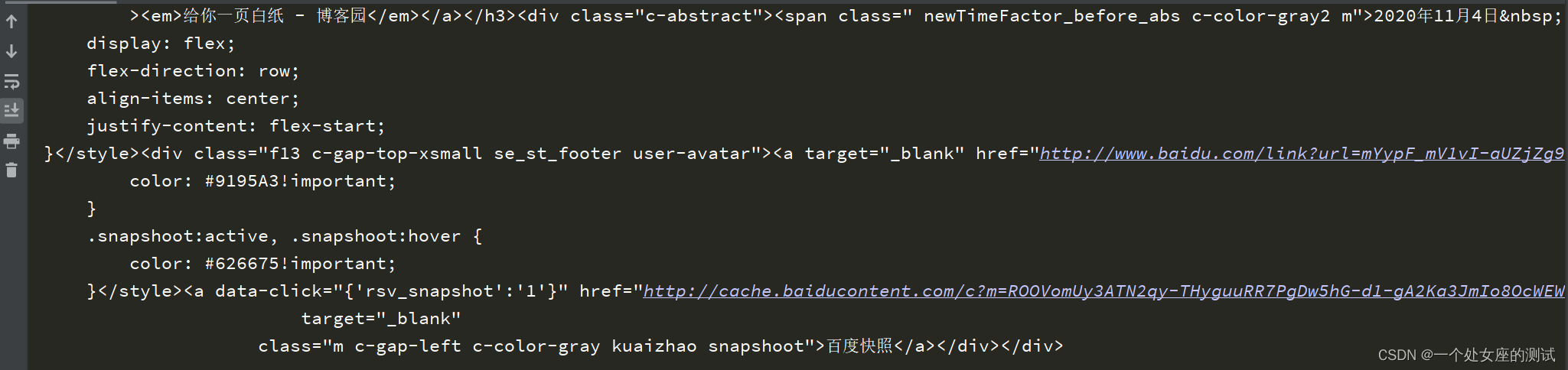
这里的响应体其实就是在百度中搜索给你一页白纸-博客园的结果页面。
除此之外,还可以加入timeout、cookies等,写法如下:
# timeout只限制请求的超时时间,单位为s,若超时则报错
res = requests.get(url=url, params=params, headers=headers, timeout=20, cookies=cookies)响应内容
发送请求后会获取到接口响应的内容,如上面示例中res.text,其他响应内容获取方式如下:
res.status_code # 响应状态码
res.headers # 响应头
res.encoding # 响应体编码格式
res.text # 响应体,字符串形式的文本信息
res.content # 响应体,二进制形式的文本信息,会自动解码
res.cookies # 响应的cookie
res.json() # 响应体格式为json,则需要通过json()进行解码这里需要注意,res.text与res.content的使用,具体使用哪种方式获取响应体内容,需要根据编码方式进行选择,最笨的方法就是一种不行换另一种试试。
示例如下:
import requestsurl = "http://www.baidu.com/s"
params = {"wd": "给你一页白纸-博客园", "ie": "utf-8"}
# User-Agent的值为浏览器类型
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36"}res = requests.get(url=url, params=params, headers=headers)
print(res.text)
print(res.status_code)
print(res.headers)
print(res.encoding)
print(res.cookies)结果如下:
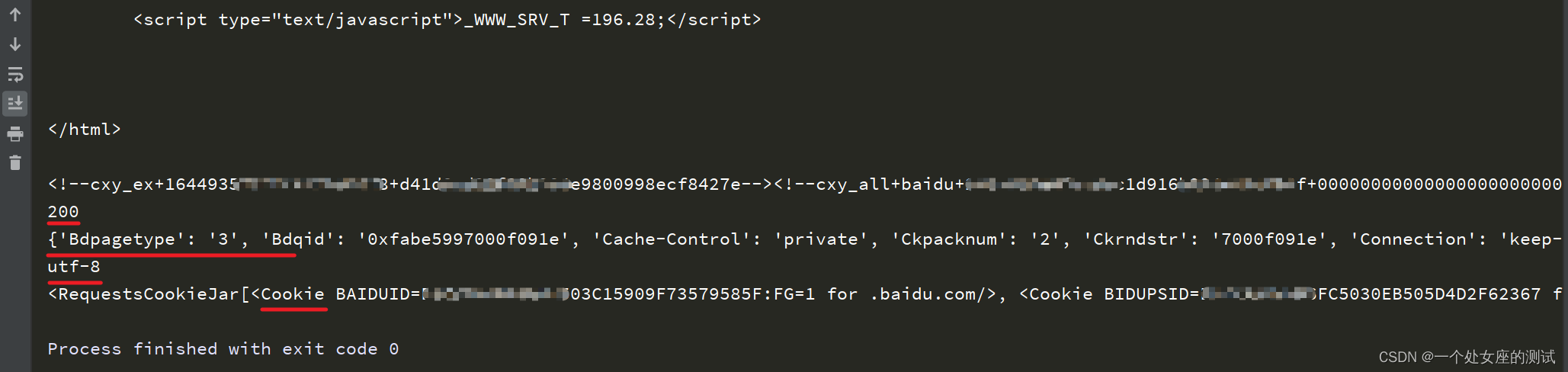
结果中由上而下依次对应代码中print的响应内容。
实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
电商项目实战
web测试项目
web+App+h5+小程序 测试项目
接口自动化测试实战项目
Linux实战项目

面试资料
我们进阶学习自动化测试必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

以上资料,对于想要测试进阶的朋友们来说应该会很有帮助,需要的小伙伴可以后台私信找我免费领取。
总结
我见过很多leader在面试的时候,遇到处于迷茫期的大龄程序员,比面试官年龄都大。这些人有一些共同特征:可能工作了好几年,更夸张的是7、8年工作内容的重复性比较高,没有什么技术含量的工作。
凡事要趁早,特别是技术行业,一定要提升技术功底,丰富自动化项目实战经验,这对于你未来几年职业规划,以及测试技术掌握的深度非常有帮助。
如果对你有帮助的话,点个赞收个藏,给作者一个鼓励。也方便你下次能够快速查找。
如有不懂还要咨询下方小卡片,博主也希望和志同道合的测试人员一起学习进步
在适当的年龄,选择适当的岗位,尽量去发挥好自己的优势。
我的自动化测试开发之路,一路走来都离不每个阶段的计划,因为自己喜欢规划和总结,
测试开发视频教程、学习笔记领取传送门!!!