A Robustly Optimized BMRC for Aspect Sentiment Triplet Extraction用于方面情感三重提取的稳健优化BMRC

中南大学 NAACL 2022
论文地址: https://aclanthology.org/2022.naacl-main.20.pdf
代码地址: https://github.com/ITKaven/RoBMRC
这边文章是基于BMRC论文优化而来的
BMRC论文地址: https://arxiv.org/pdf/2103.07665.pdf
1. 介绍
1.1 任务描述&建模
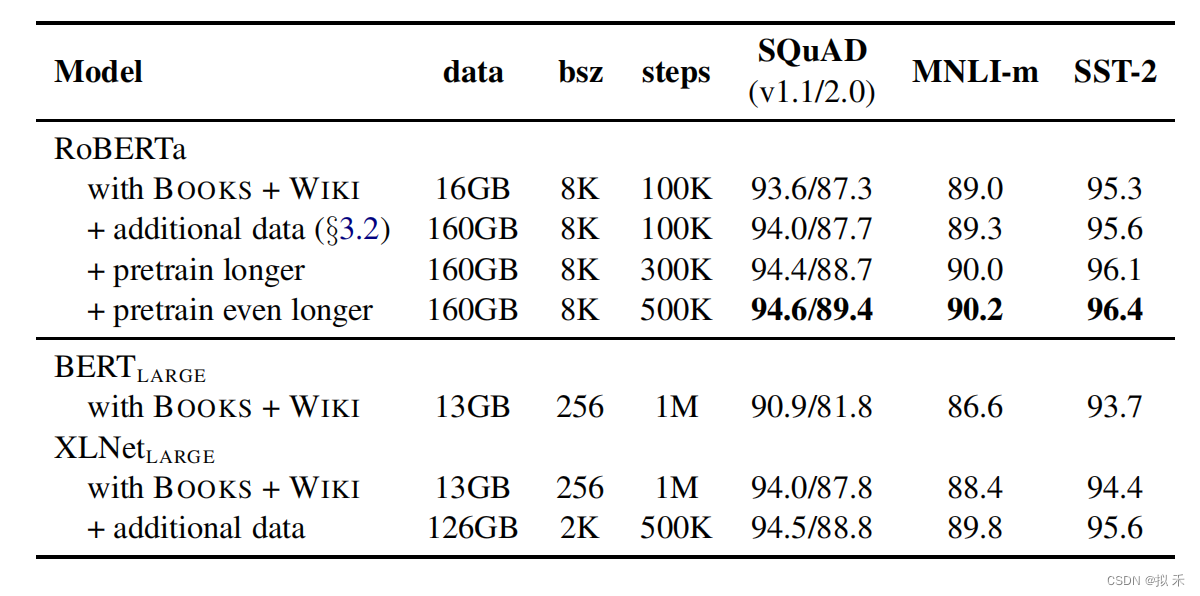
方面情感三重提取 (ASTE) 旨在从评论句子中识别方面及其相应的观点表达和情感(at, op, sp)。
本文将 ASTE 任务转换为多轮机器阅读理解 (MTMRC) 任务,并提出了一个Bidrectional-MRC (BMRC) 框架来应对这一挑战。设计了三种类型的查询,包括非限制性提取查询(第一轮查询)、限制性提取查询(第二轮查询可以理解为给定方面/意见术语查询另一个术语)和情感分类查询(第三轮查询),以建立不同子任务之间的关联。
1.2 前两轮查询时分为双向的
目的是为了抽取(at, op)对
正向:
第一轮抽取方面术语Aspect Term,第二轮根据方面术语抽取意见术语Opinion Term
反向:
第一轮抽取意见术语Opinion Term, 第二轮根据意见术语抽取方面术语Aspect Term
1.3 第三轮
通过得到的前两轮得到(at, op)对进行情感分类得到情感极性Sentiment Polarity,以获得(at, op, sp)三元组
1.4 任务案例

2. 模型架构
3. 改进(贡献)
基于之前的BMRC框架,本文提出了一种鲁棒优化的BMRC方法。主要针对以下四点。
1.为了方便语义学习,采用了分词方法。
2.独立分类器的设计是为了避免不同查询之间的干扰。
3.提出了一个跨度匹配规则来选择更好地代表模型期望的方面和意见。
4.并引入概率生成策略,获得方面、观点和方面-观点对的预测概率。
3.1 Word Segmentation (分词)
WordPiece的标记器将单词分割成子词,学习更多的语义信息 。例如: 当“walked”、“walker”或“walks”等类似的单词出现时,如果不进行分词,它们将被视为完全不同的单词。 然而,如果将它们细分为“walk##ing”、“walk##ed”、“walk##er”它们的子词“walk”包含了训练中相当常见的相同语义。
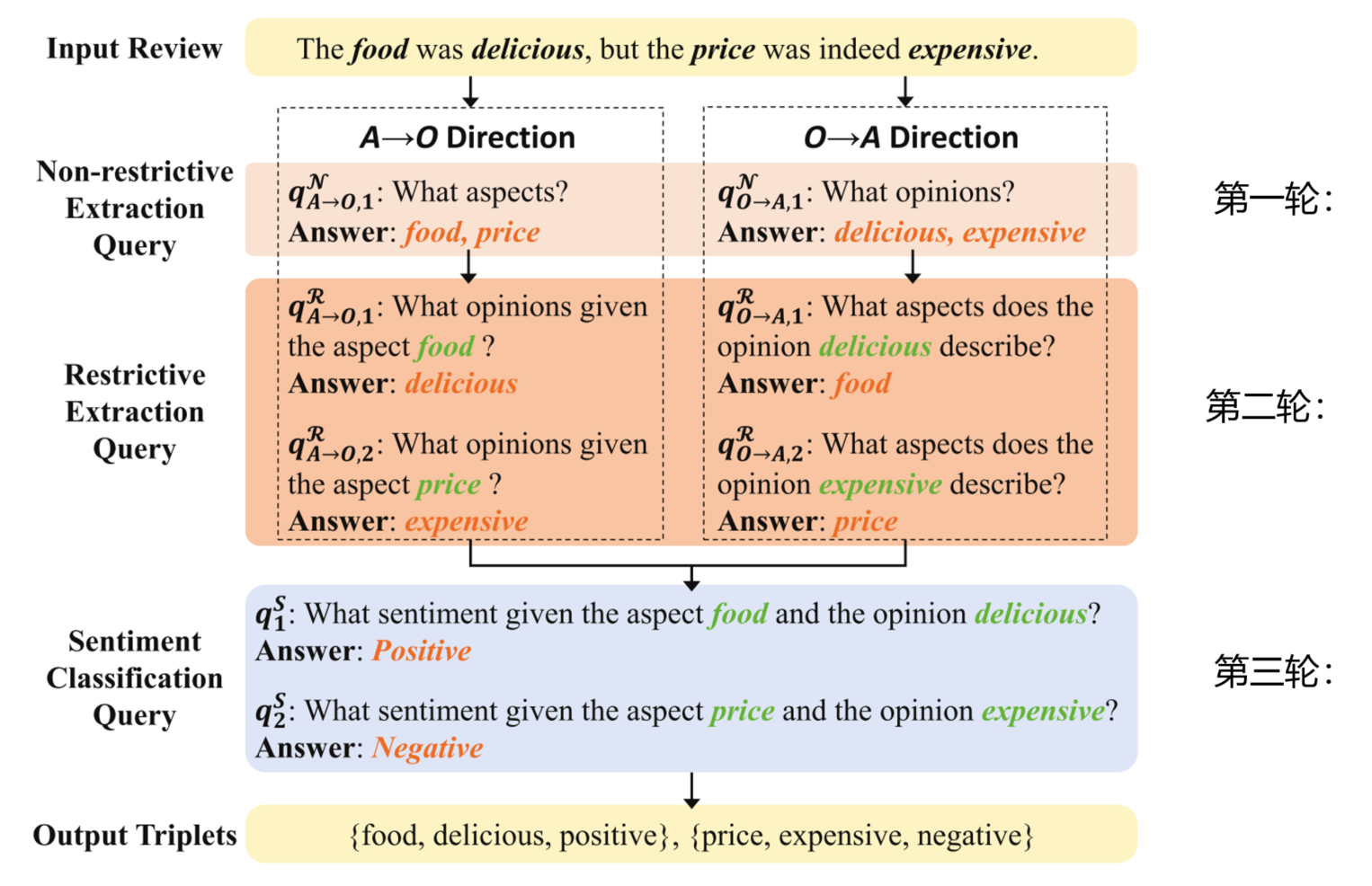
3.2 Exclusive Classifiers (独立的分类器) 之前是共享一个分类器
在最初的BMRC中,所有查询共享一个分类器。 然而,如果不同类型的查询使用相同的分类器,它不能很好地服务于任何部分。 这些不同类型的查询会相互干扰,导致查询冲突。 通过添加独占分类器,每种不同类型的查询都可以使用唯一的分类器,如图3所示,可以有效避免查询冲突问题,大大提高模型的性能。
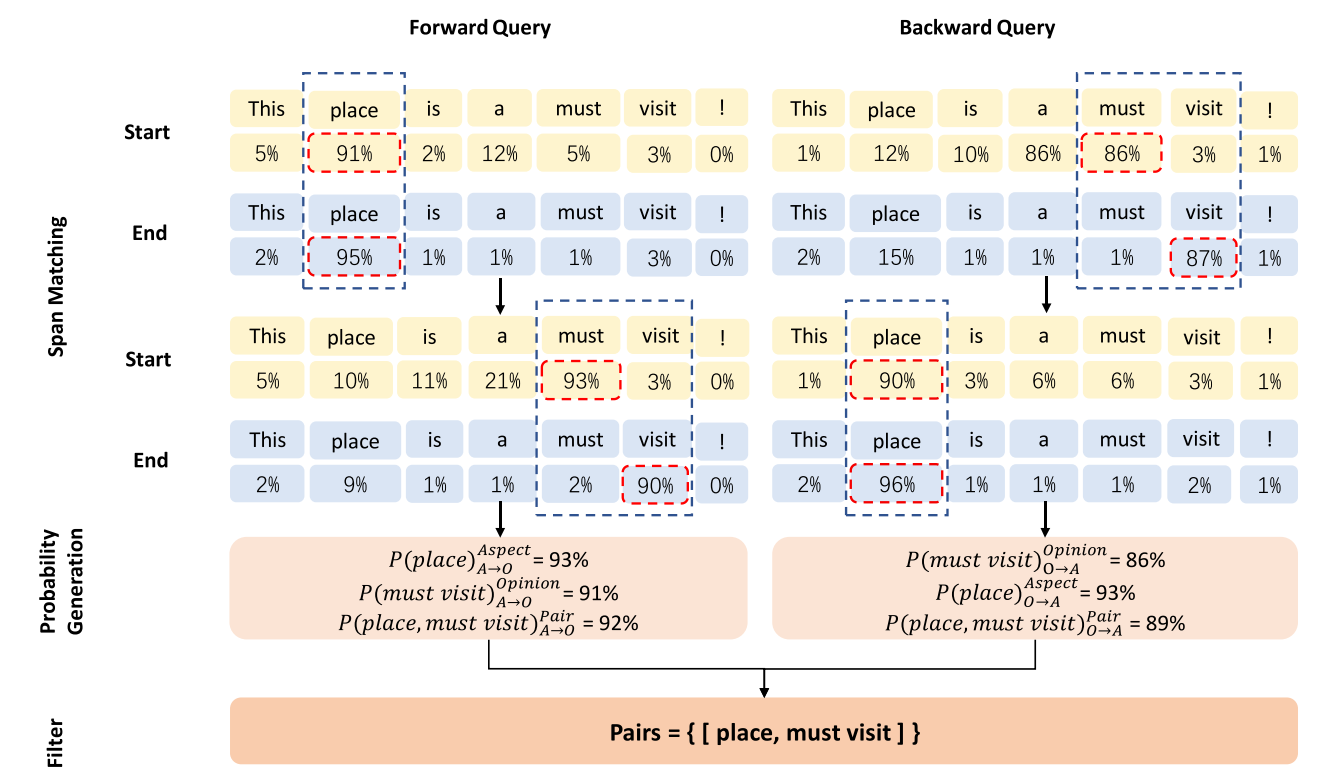
3.3 Span Matching (跨度匹配)
跨度匹配规则的概述是: 使每个结束位置在上一个结束位置之后以最高概率匹配开始位置。如果存在具有相同概率的起始位置,则选择其位置最接近终止位置的位置。
3.4 Probability Generation (概率生成)
在BMRC中,将开始位置和结束位置的概率乘积作为跨度的概率,而成对的概率是方面和观点的概率乘积。这样,配对的概率单边下降,不能很好地表示模型对配对的预测。
例如,pair的四个位置的概率是0.9,而pair的概率是0.9^4= 0.6561,这似乎不是那么合理。运算如等式1和2所示,我们平衡了跨度和成对的概率,使它们的概率在两个相关概率的区间内。那么pair的概率都是0.9了。
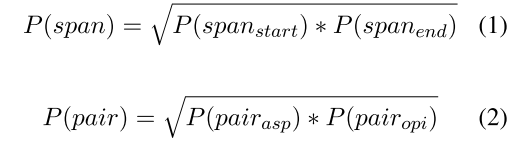
优化之后的模型规则
4. 实验结果
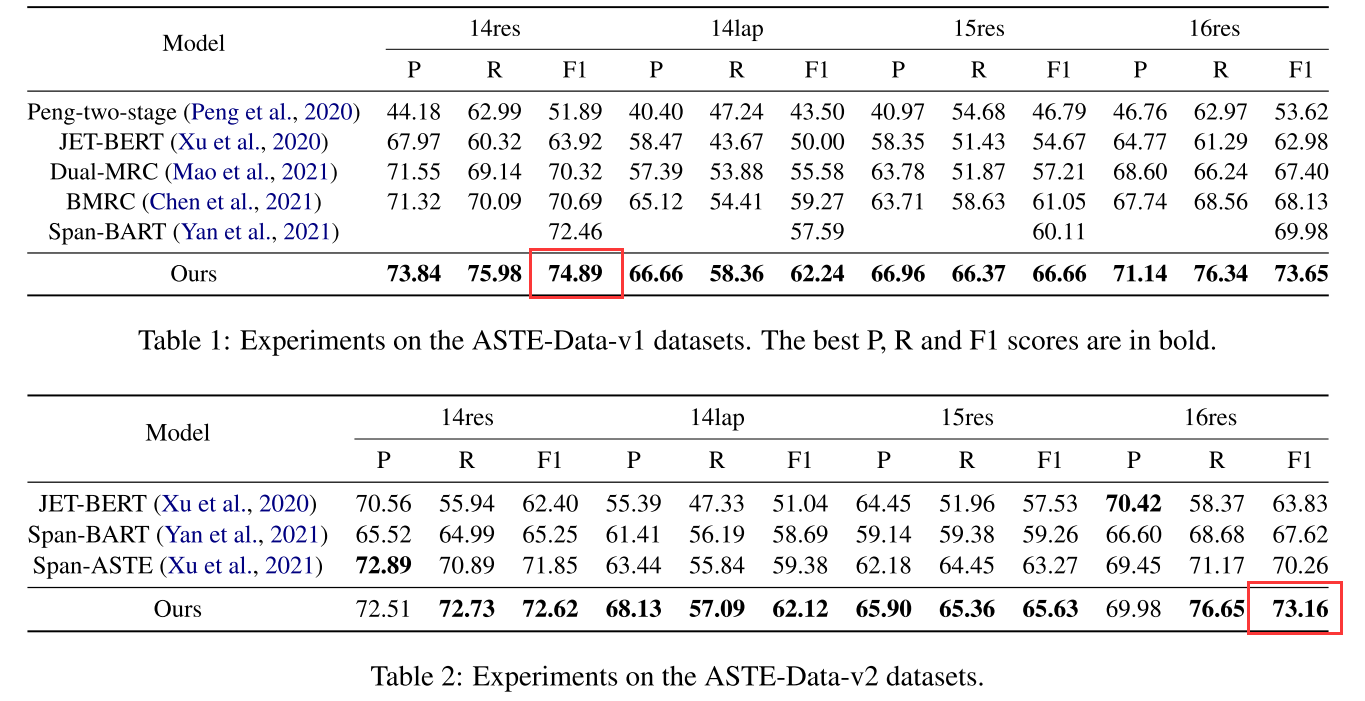
4.1 ASTE实验结果
4.2 消融实验
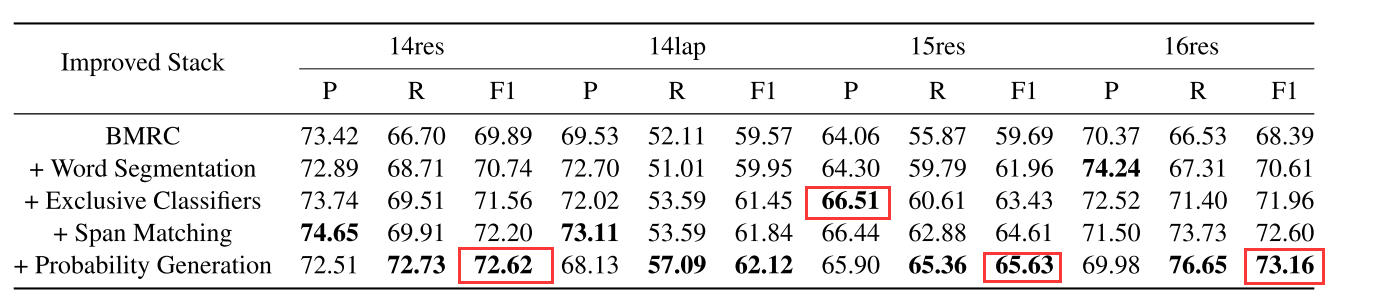
从消融实验中可以看出概率生成的影响最大