视频压缩基本介绍与标准
视频压缩又称视频编码,所谓视频编码方式就是指通过特定的压缩技术,将某个视频格式的文件转换成另一种视频格式文件的方式。
一般的通用数据压缩方案如下图:

压缩就是一个传播的过程,所以在压缩与解压缩之间,没有信号的丢失则称这种压缩就是无损的,相反的就是有损的,都有各自的算法,下面介绍。
无损压缩算法
一 游长编码(Run-Length Coding, RLC)
产生年代:未知。
主要人物:未知。
基本思想:如果我们压缩的信息源中的符号具有这样的连续的性质,即同一个符号常常形成连续的片段出现,那么我们可以对这个符号片段长度进行这样的的编码。
例子:输入:5555557777733322221111111
游长编码为:(5,6)(7,5)(3,3)(2,4)(l,7)
二 变长编码:
1 香农-凡诺算法
产生年代:未知
主要人物:Shannon 和 Robert Fano
基本思想:对于每个符号出现的频率对符号进行排序,递归的将这些符号分成两部分,每一部分有相近的频率,知道只有一个符号未止。
说明:过程用一颗二叉树完成,它是一种自顶向下的过程,对于此输入5个字符则自然的分成2,3左右两子树,接着就是递归的过程。因为分法不唯一,所以下列输出是一种情况。
例子:输入:HELLO
输出:10 110 0 0 111(左子树标0)
2赫夫曼编码
产生年代:1952年
主演人物:David A.Huffman
基本思想:与香农-凡诺算法的区别在于,赫夫曼编码采用的是一种自下而上的描述方式,先从符号的频率中选取最小的两个符号,合成一个新的结点,进行等效的代替,然后也是个递归过程。
说明:赫夫曼编码具有唯一的前缀性质和最优性。
例子:对于输入:HELLO 建立的一刻赫夫曼树

扩展:
扩展的赫夫曼编码,这是相对于数据中某个符号的概率较大(接近1.0)时,将几个符号组成组,然后为整个组赋予一个码字。
自适应的赫夫曼编码,这是一个边接收边编码的过程,完全的体现了适应的过程,需要对二叉树进行改变,由接收到的数据去添加进二叉树中,自动生成新的“赫夫曼树”。
三 基于字典的编码(Lempel-Ziv-Welch, LZW)
产生年代:1977年 1978年改进一,1984年改进二
主要人物:Jacob Ziv, Abraham Lempel, Terry Welch
基本思想:该算法利用了一种自适应的基于字典的压缩技术,字典就是给给不同的符号组合进行编码,生成一个个“单词”,自适应就是,单词是接收数据的时候,一个个生成的,字典会慢慢的边长。
例子:先从一个简单的字典开始 原字典单词 新生成的字典单词
我们输入: ABABBABCABABBA
输出:1 2 4 5 2 3 4 6 1
说明:只要待编码的符号序列是字符、字符串、字符、
字符串、字符、等等,编码器就会产生一个新的编码
来表示字符+字符串+字符,并且在解码器还没来得及
产生这个编码的时候马上将其投入使用。
四 算术编码
产生年代:追溯到1948年 20世纪七八十年代发展成熟
主要人物:Shannon Abramson Peter Elias
基本思想:把整个消息看成一个单元。然后经过数字处理,计算出每个符号的频率范围,再由上限及下限产生码字……
( 我没看懂……)
有损压缩算法
一 变换编码
1 离散余弦变换(DCT)
DCT 是一种广泛应用的变换编码方式,它能以数据无光的方式解除输入信号之间的相关性。例如对于JPEG和类似的图像压缩算法来说,压缩的第一步需要将图像分割为小块,同时将每个小块进行变换,使之由空域信号变换成为时域信号。这时候就会采用DCT,CT变换能够完整的保留所有8x8像素块的信息,因此反向离散余弦变换(IDCT)也就能够从8x8频域信号矩阵中完整的恢复原始8x8像素矩阵。
扩展:2D DCT, 2D IDCT。
2 Karhunen-Loeve 变换(KLT)
KLT变换是一种可逆的线性变换,它应用了向量表述的统计学原理。KLT变换主要的特征就是能够很好的解除输入的相关性。
二 小波编码
这是一种信号的分解方法。它采用一组成为小波的基函数来表示信号,可以在时域和频域都得到很好的分辨率。小波变换有两种:连续小波变换(CWT)和离散小波变换(DWT)。
扩展: 二维Haar变换
三 小波包
紧接上文,解决小波变换值进行编码,怎样形成流。将采取一种叫做嵌入零树的数据结构。
嵌入式零树小波(EWZ)算法 层次树集合划分(SPIHT)算法 优化截断嵌入式编码(EBCOT)算法。
具体内容复杂,在这里不做介绍了。
JPEG图像
下面介绍JPEG图像的简单步骤:
1 把RGB转换为YIQ 或 YUV, 并且二次采样。
2 对图像块进行DCT变换。(块是图像压缩的一个单位,能使DCT变换加快)。
3 进行量化。量化的目标是减少图像压缩所需要的位数。量化的过程就是将每个DCT系数向诺干预设值进行舍入得过程。这种对系数的编码方法可以通过两步来实现:首先通过量化过程舍去次要的视频信息,然后利用统计学的方法尽可能少的对剩余的重要信息进行比特编码。
4进行Z编序和游长编码。在编码过程中,AC分量进行游长编码, DC分量采用(DPCM)差分脉冲编码调制。
5进行熵编码。熵编码(entropy encoding)是一类利用数据的统计信息进行压缩的无语义数据流的无损编码。JPEG编码允许赫夫曼编码和算术编码。
看到了基本的有损,无损算法在JPEG标准的应用。
再起视频压缩
视频是由一系列的时间上有序的图像(我们叫做帧)所组成的。解决视频压缩的一个简单的方案就是基于前面的帧的帧预测编码。视频的压缩不是对图像本身进行相减,而是按照时间顺序进行相减,并将残差进行编码。就是所说的时间冗余,而相对的图像处理主要面对的是空间冗余。
这里有两个很重要的压缩策略,形象的描述是:在足球比赛中,进行视频处理,在下一帧中寻找足球运动员的位置的策略叫做运动估计(ME),来回移动帧的位置为了最大程度上将球员从图像中减去,叫做运动补偿(MC)。
基于运动补偿的视频压缩
前面说的视频中时间冗余比较显著,可以利用这个特征,不必将每帧视频图像都作为一幅新的图像进行编码,而是用当前的帧和其他的帧的差值进行编码。一个简单的想法就是将一张图像的按照像素点值减去另一张图像,但不能达到很好的压缩率。由于帧图像的主要差别是由摄像头或者物体运动造成的,所以可以用“补偿”的概念来测量差值。这就是我们所说的视频压缩基于运动补偿的压缩算法。
该算法可以分为三个步骤:
1)运动估计(运动向量查找)。
2)基于运动补偿的预测。
3)预测误差的生成——差值。
我们知道,为提高效率,就把每张图像分为一个个宏块,运动补偿就是在图像的宏块级别起作用。把当前帧称为目标帧,很容易就知道,我们是要在目标帧中的宏块和参考帧(下面会说)中的最相似的宏块间寻找匹配。这种情况下,目标宏块由参考宏块预测生成。
参考宏块到目标宏块的位移称作运动向量(MV),两个宏块之间的差值叫做预测误差。
所以我们只要对运动向量和差值宏块进行编码。
搜索运动向量
我们应该知道运动向量的搜索就是一个匹配的问题,也就是相关性的问题。方便的原因,我们规定原点,目标帧, 参考帧的像素,用平均绝对误差(MAD)来测量宏块的大小。搜索的目的是寻找一个向量使得MAD取得最小值。
一 顺序搜索
寻找运动向量的最简单的方法就是顺序搜索参考帧中整个大小的窗口(也叫全搜索)。然后将窗口的每一个宏块逐个像素和目标帧中的宏块进行比较。
特点:代价高,实现编码困难。
二 2D对数搜索
2D对数搜索的方法搜索运动向量的过程中需要进行多次迭代,类似折半查找过程。
特点:相对于顺序搜索的算法,明显得到改善。
三 分层搜索
运用该方法,初始的运动向量估计是从显著降低分辨率后的图像中获得的。因为图像的分辨率太低,缺少图像的细节内容,所以初始的运动向量估计值是比较粗糙的,要进行一层层的修正。
特点:速度再一次得到优化。
下面具体介绍视频压缩(编码)标准。
H.261
产生年代:1988年
提出者:国际电报电话咨询委员会(CCITT)
应用于:早期的数字电视压缩
支持的视频格式:QCIR, CIF。
H.261帧序列:有两种的类型的图像帧, I帧, P帧。
I帧: 被视为独立的图像,基本上每一个I帧内应用和JPEG相似的变换编码方式。
P帧:不是对立的。它采用的是向前预测的编码方式,该方法中的当前的宏块(目标帧),是通过先前的I帧或者前面P帧(参考帧)中的相似的宏块预测出来的,并对宏块间的差进行编码。
图像帧编码:
I帧编码:采用4:2:0的色彩二次采样,对于8x8子块进行离散余弦变换,同JPEG算法,后对DCT系数进行量化,最后通过Z字扫描并进行熵编码。
P帧预测编码:对目标帧的每一个宏块俩说,我们用前面所说的3种方法中的一种进行运动向量的分配,再用差值宏块测量预测误差,同样对于8x8的子块进行离散余弦变换、量化、Z字扫描和尚编码。
H.261的量化
标准中的量化,是对一个宏块中所有的DCT系数均采用一个常数,称为步长。
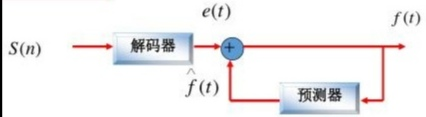
H.261编码器和解码器
在编码器中
当前帧为I帧,观察点从I帧中接收宏块,每个I经过离散余弦变换、量化、熵编码,将结果放入输出缓冲区中,准备发送。同时I量化后的DCT系数被送到模块中进行量化逆变换和逆离散余弦变换,把这里得到的数据(I1)和从目标帧中输入的数据相加,另外在保留一份在帧内存中,用于下一帧P1的运动估计和基于运动补偿的预测。
接下来当前帧P1到达观察点,立即调用运动估计过程,在帧I1中位P1中的每一个块寻找最匹配的宏块,求得运动向量。这个运动向量的估计值被同时送到运动补偿的预测器和可变长度编码器。基于运动补偿的预测器给出P1中最匹配的宏块用P2表示。然后得到预测误差其值为D=P1-P2,接着D1进行DCT,量化,熵编码将结果输入到缓冲区中和前面的I一样得到D1然后D又与P2相加得P21,并放在下一帧的运动估计和基于运动补偿的预测。
在解码器中
输入码经过熵编码、量化逆变换和逆离散余弦变换。对于I帧,解码后的数据出现在观察点,然后同样的得到I1,I1被当做第一个输出帧,并且同时送到帧内存中进行保存。
接下来,P1作为输入码进行解码,在观察点得到预测误差D1,同样的得到P21,作为解码后的帧输出,同时存放在帧内存中。
H.261视频位流语法概述
这就是一个分层的结构,共四层,图像层、块组层、宏块层和块层。
H.263
产生年代:1995年
提出者:国际电联ITU-T
应用于:公交电话交换网络上的视频会议或其他可视化服务传输。
支持的视频格式:QCIR, CIF, sub-QCIF, 16CIF, 16CIF格式的视频
H.263的运动补偿
H.263中的运动补偿过程和H.261中的运动补偿过程相似。但是运动向(MV)
不只是从当前块产生的。在H.263中并不是对MV进行编码,而是对误差向量进行编码。为了改善运动补偿的效果,减少预测的误差,H.263支持半像素精度的预测,二H.261支持完整的像素预测。
H.263的可选编码模式
除了核心的算法外H.263在附件中指定了许多可选的编码模式,以下四种常用:
1)无限制的运动向量模式
2)基于语法的算术编码模式
3)高级预测模式
4)PB帧模式
介绍B帧:B帧,他是同时由先前帧和后一帧双向预测而得到的,可以改善预测的质量,可以让我们在不牺牲画质的条件下提供压缩率。
另外,还有H.263+和H.263++标准。
MPEG-4 Part10/H.264
产生年代:2003年
提出者:国际电联ITU-T ISO/IEC的MPEG专家组 共同指定
应用于:可视电话(固定或移动)、实时视频会议系统、视频监控系统、因特网视频传输以及多媒体信息存储等
H.264的特点
H.264在编码框架上还是沿用以往的MC-DCT结构,即运动补偿加变换编码的混合(hybrid)结构,因此它保留了一些先前标准的特点。然而,以下介绍的技术使得H.264比之前的视频编码标准在性能上有了很大的提高。应当指出的是,这个提高不是单靠某一项技术实现的,而是由各种不同技术带来的小的性能改进而共同产生的。
1. 帧内预测
对I帧的编码是通过利用空间相关性而非时间相关性实现的。以前的标准只利用了一个宏块内部的相关性,而忽视了宏块之间的相关性,所以一般编码后的数据量较大。为了能进一步利用空间相关性,H.264引入了帧内预测以提高压缩效率。简单地说,帧内预测编码就是用周围邻近的像素值来预测当前的像素值,然后对预测误差进行编码。
2. 帧间预测
与以往的标准一样,H.264使用运动估计和运动补偿来消除时间冗余,但是它具有以下四个不同的特点:
(1)预测时所用块的大小可变
由于基于块的运动模型假设块内的所有像素都做了相同的平移,在运动比较剧烈或者运动物体的边缘处这一假设会与实际出入较大,从而导致较大的预测误差,这时减小块的大小可以使假设在小的块中依然成立。另外小的块所造成的块效应相对也小,所以一般来说小的块可以提高预测的效果。
(2)更精细的预测精度
在H.264中,Luma分量的运动矢量(MV)使用1/4像素精度。Chroma分量的MV由luma MV导出,由于chroma分辨率是luma的一半(对4:2:0),所以其MV精度将为1/8,这也就是说1个单位的chroma MV所代表的位移仅为chroma分量取样点间距离的1/8。如此精细的预测精度较之整数精度可以使码率节省超过20%。
(3)多参考帧
H.264支持多参考帧预测,即可以有多于一个(最多5个)的在当前帧之前解码的帧可以作为参考帧产生对当前帧的预测。这适用于视频序列中含有周期性运动的情况。采用这一技术,可以改善运动估计(ME)的性能,提高H.264解码器的错误恢复能力,但同时也增加了缓存的容量以及编解码器的复杂性。不过,H.264的提出是基于半导体技术的飞速发展,因此这两个负担在不久的将来会变得微不足道。较之只使用一个参考帧,使用5个参考帧可以节省码率5~10%。
(4)抗块效应滤波器
抗块效应滤波器,它的作用是消除经反量化和反变换后重建图像中由于预测误差产生的块效应,即块边缘处的像素值跳变,从而一来改善图像的主观质量,二来减少预测误差。需要注意的是,对于帧内预测,使用的是未经过滤波的重建图像。
3.整数变换
H.264对帧内或帧间预测的残差进行DCT变换编码。新标准对DCT的定义做了修改,使得变换仅用整数加减法和移位操作即可实现,这样在不考虑量化影响的情况下,解码端的输出可以准确地恢复编码端的输入。当然这样做的代价是压缩性能的略微下降。此外,该变换是针对4×4块进行的,这也有助于减少块效应。
4.熵编码
如果是Slice层预测残差,H.264有两种熵编码的方式:基于上下文的自适应变长码(CAVLC)和基于上下文的自适应二进制算术编码(CABAC);如果不是预测残差,H.264采用Exp-Golomb码或CABAC编码,视编码器的设置而定。
(1)CAVLC
VLC的基本思想就是对出现频率大的符号使用较短的码字,而出现频率小的符号采用较长的码字。这样可以使得平均码长最小。
在CAVLC中,H.264采用若干VLC码表,不同的码表对应不同的概率模型。编码器能够根据上下文,如周围块的非零系数或系数的绝对值大小,在这些码表中自动地选择,最大可能地与当前数据的概率模型匹配,从而实现了上下文自适应的功能。
(2)CABAC
算术编码是一种高效的熵编码方案,其每个符号所对应的码长被认为是分数。由于对每一个符号的编码都与以前编码的结果有关,所以它考虑的是信源符号序列整体的概率特性,而不是单个符号的概率特性,因而它能够更大程度地逼近信源的极限熵 ,降低码率。 在CABAC中,每编码一个二进制符号,编码器就会自动调整对信源概率模型(用一个“状态”来表示)的估计,随后的二进制符号就在这个更新了的概率模型基础上进行编码。这样的编码器不需要信源统计特性的先验知识,而是在编码过程中自适应地估计。显然,与CAVLC编码中预先设定好若干概率模型的方法比较起来,CABAC有更大的灵活性,可以获得更好的编码性能——大约10%码率的降低。
5. SP Slice
SP Slice的主要目的是用于不同码流的切换(switch),此外也可用于码流的随机访问、快进快退和错误恢复。
6.灵活的宏块排序
灵活的宏块排序(flexible macroblock ordering,FMO),是指将一幅图像中的宏块分成几个组,分别独立编码,某一个组中的宏块不一定是在常规的扫描顺序下前后连续,而可能是随机地分散在图像中的各个不同位置。这样在传输时如果发生错误,某个组中的某些宏块不能正确解码时,解码器仍然可以根据图像的空间相关性依靠其周围正确译码的像素对其进行恢复。
总结
视频压缩的目的是在保证质量的情况下,用更少的数据去存储,传播视频。视频压缩的一般方法中,少不了离散余弦变换、量化、熵编码,这是因为视频的压缩更多的是处理时间冗余。很重要的思想是预测,向前预测,向后预测,还有就是相关性,也就是让跟周围的关系联系起来,让自己复原的更彻底。视频可以看成是一幅幅图像以某个速度进行传播,而在压缩中跟多的是可看成把一部分看成一个图像的演化过程,然后下一部分又是一个新的演化。