资料:《新一代视频压缩编码标准H.264/AVC》 毕厚杰
有一些超出 音视频encode decode scope 的content,会过滤阅读,本次学习过程更偏向基础概念的理解,terms学习
第一章 绪论
1.3视频压缩的目标和方法
1.3.1 视频压缩的目标
有损压缩图像数据,节省带宽和存储空间
评判视频压缩的两个标准
- 主观质量,从人类的视觉上判定
- 客观质量,用信噪比S/N计算。S代表无噪音的信号值,N代表机器本身的噪声。 信噪比越高越好,代表杂波越少
1.3.2 视频压缩的可能性
- 预测编码:由于当前帧和下一帧,图像的像素信息变化不会特别大,因此可以用当前帧预测下一帧的数据。这种压缩方式称为 帧内预测编码。 具体怎么预测值,待了解
- 变换编码:通过数学变化,只传递直流,低频,高频的成分,有一些频率相当低的就可以不传。 这种方式,我理解就是像个筛子,过滤掉一些频率过低的成分,以实现压缩的目标
1.4 视频压缩编码技术综述
1.4.1基本结构
视频编码的方法与 信源模型有关
- “一张图片由像素组成“的概念,这时信源模型的参数就是每个像素的亮度和色度。称为基于波形的编码
- 利用像素间的相关性,采用预测编码和变换编码技术,实现压缩编码
- 基于波形的编码,采用预测编码和变换编码组合起来的,基于块的混合编码方法,将图像分割成固定大小的块
- ”一个分量由几个物体组成“的概念,这时信源模型的参数就是各个物体的形状、纹理和运动。称为基于内容的编码
1.4.4 立体(三维)视频编码
基于平面信息,增加深度信息
第二章 数字视频
视频压缩编码技术就是对数字视频信号进行压缩和解压缩的技术
2.1数字电视的基本概念
2.1.1 数字电视相对模拟彩电的优势
- 失真小、噪音低、视频质量高
- 易处理、易校正
- 容量大、节目多
2.2.2 色彩空间
黑白图像的每个像素,只需要亮度信息即可,而彩色图像的每个像素至少需要三个值,用来表示 亮度和色度。所谓色度空间,就是表示彩色图像亮度与色度的方法
- RGB,任何颜色都可以由红绿蓝组成,即三基色原理
- YCbCr(YUV)。人类视觉系统,对亮度的敏感程度比色彩高。因此从彩色信息中分离出亮度信息,并使之有更高的清晰度。压缩带宽,但对于人眼来说感受没有太大差异。RGB和YUV之间,有转换公式
第三章
3.1 预测编码
3.1.1 预测编码的基本概念
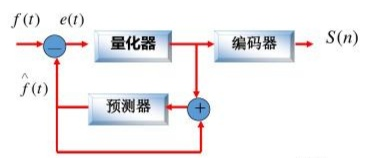
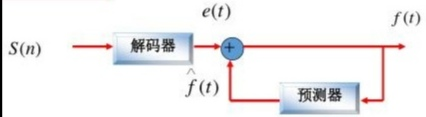
预测编码框图如上,也成为差分脉冲编码(DPCM,Differential Pulse code modulation),主要的误差产生在 “量化” 过程
3.1.2 帧内预测编码
以一维预测举例(即以横方向上的所有左边的pixel值作为预测值
最后的误差应该为 e ( x ) = f ( x ) − f ′ ( x ) = f ( x ) − ∑ 1 k f ( x − k ) [ k < = x − 1 ] e(x) = f(x)-f'(x)=f(x)-\sum_1^k f(x-k) [k<=x-1] e(x)=f(x)−f′(x)=f(x)−∑1kf(x−k)[k<=x−1]
应使e(x)的均方差最小,此时编码效率最高???
预测编码的优化也就是在 量化过程,对数据进行了压缩。图像中平坦部分比突变区域多。实验表明亮度突变的部分,量化误差可以大;平坦部分,量化误差得小
3.1.3 帧间预测编码
- 单向预测
- 双向预测
- 重叠块运动
比较复杂,暂时不看
3.2 变换编码
基本概念:直流和低频区域(平坦或内容缓慢变化区域)占大部分,高频区域(突变区域)占小部分
常见算法:FFT(快速傅里叶变化)等
3.3 预测编码和变换编码的比较
变换编码算法实现比预测编码要复杂,但误差小。预测编码的误差会扩散,以一行为例,越后面的误差越大,因为要累计前面参考像素的误差值。实际现实中,采用混合编码
3.4 熵编码
利用信源统计特性进行编码的方式,叫熵编码,也叫统计编码。在视频编码中,常用的有变长编码(哈夫曼编码)和算术编码
- 哈夫曼编码,老熟悉了,贪心嘛
- 算数编码,利用某种算法,将字符串哈希成0~1的小数,再反序列化
第五章 H.264/AVC编码器原理
5.3 H.264/AVC 的结构
5.3.1 名词解释
场和帧
- 场编码:最早模拟视频,都是隔行扫描,以奇数行和偶数行为根据分开扫描
- 帧编码:现在采用数字视频后,都是帧编码。场编码的存在只是为了和老技术兼容
宏块和片