- 慢查询排查优化
- 排查
slow_query_log设置为on,就会记录慢查询sql;long_query_time可以设置慢查询sql的阈值时间;slow_query_log_file表示记录慢查询sql的日志路径。即我们可以通过打开记录慢查询的开关,设置慢查询的时间阈值,查看日志就能看到慢查询的执行sql。然后使用explain查看sql的执行计划,主要看type字段判断是否走索引了。 - 优化
- 子查询优化,使用join代替in,子查询的话mysql会建立临时表,再把临时表销毁,效率会很低
- 字段优化,尽量使用整形,不要设置太长,避免between、like、<、>范围查询导致的全表查询
- 经常使用的字段创建索引
- 事先准备好报表,避免查询时计算数据导致的性能下降
- 分库分表
- 历史数据迁移
- 使用redis缓存数据,减少查询次数
- 排查
- 聚集索引和非聚集索引
- 聚集索引
聚集索引指的就是主键索引,索引和数据是存放在一起的,故名聚集。mysql的数据在磁盘上是以页的形式进行存储的,每页中的数据按主键的值从小到大进行排列,因此可以通过目录页对数据查询进行维护,每个目录都记录了数据的页数以及该页的最小键值。在查询时根据先可以目录项定位要查询的数据所在的页数,再到数据页中按主键值通过二分法进行查询。 - 非聚集索引
非聚集索引的数据结构与聚集索引类似,不过在数据项中存储的是主键,查询的时候先通过非聚集索引查询得到主键,再通过主键回表查询具体的数据。 - 区别
主键索引叶子节点存储的是具体的数据,而非聚集索引叶子节点存储的主键。聚集索引每张表只能有一个,非聚集索引每张表可以有多个。聚集索引在内存上是线性的,而非聚集索引在内存上不是线性的,逻辑上是线性的。
- 聚集索引
- limit查询变慢的原因
limit语句会先扫描offset+n行,然后再丢弃掉前offset行,返回后n行数据。当limit后面跟的值比较大,mysql查询时扫描的行数变多,导致查询的时间变长。因此limit的第一个参数不要设置的太大,可以通过主键id找到要查询的位置再进行limit。 - mysql事务隔离级别
读未提交;读已提交;可重复读;序列化。可重复读底层是通过mvcc实现的。 - mysql的char和varchar的区别
- varchar 类型的长度是可变的,而 char 类型的长度是固定的
- char 长度最大为 255 个字符,varchar 长度最大为 65535 个字符
- varchar 类型的查找效率比较低,而 char 类型的查找效率比较高
- DATETIME 和 TIMESTAMP 的区别
- DATETIME比TIMESTAMP的范围要广
- TIMESTAMP占4个字节,DATETIME占用8个字节
- TIMESTAMP会时间在当前时间和UTC之间进行转化,DATETIME直接保存和返回
- 什么情况下会创建索引
- 字段的值是唯一
- 表的数据量比较大并且频繁作为where的查询条件
- 索引失效的情况
- 不遵循最左前缀原则
- 索引上有通配符
- 索引的类型和匹配类型不一致
- 索引上存在内置函数
- or连接了非索引字段
- 范围查询时数据量过大
- 索引优化
- 避免回表
- 索引最好设置为not null
- explain调试sql
mysql数据库常见面试题
news/2024/11/24 22:00:39/
相关文章

sql-labs-Less1
靶场搭建好了,访问题目路径
http://127.0.0.1/sqli-labs-master/Less-1/ 我最开始在做sql-labs靶场的时候很迷茫,不知道最后到底要得到些什么,而现在我很清楚,sql注入可以获取数据库中的信息,而获取信息就是我们的目标…

电脑系统崩溃怎么修复教程
系统崩溃了怎么办? 如今的软件是越来越复杂、越来越庞大。由系统本身造成的崩溃即使是最简单的操作,比如关闭系统或者是对BIOS进行升级都可能会对PC合操作系统造成一定的影响。下面一起来看看电脑系统崩溃修复方法步骤。
工具/原料:
系统版本…
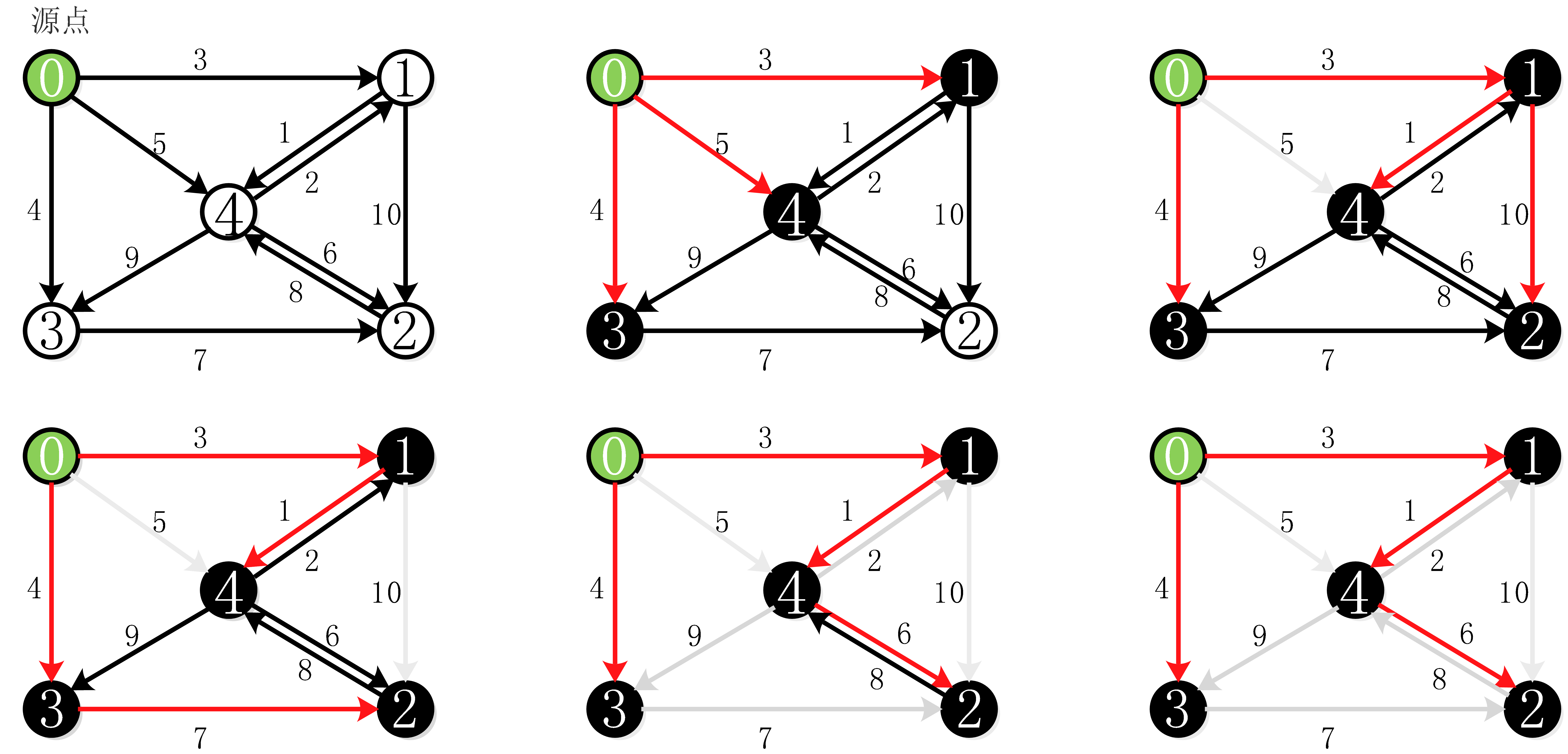
数据结构与算法(六):图结构
图是一种比线性表和树更复杂的数据结构,在图中,结点之间的关系是任意的,任意两个数据元素之间都可能相关。图是一种多对多的数据结构。
一、基本概念
图(Graph)是由顶点的有穷非空集合和顶点之间边的集合组成&#x…
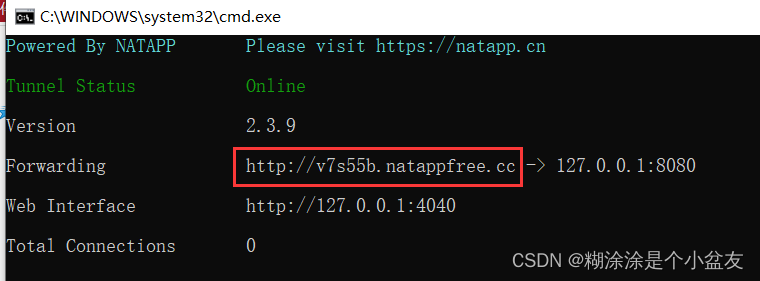
Java-Springboot整合支付宝接口
文章目录一、创建支付宝沙箱二、使用内网穿透 nat app三、编写java程序四、访问一、创建支付宝沙箱
跳转 : 支付宝沙箱平台
1、进入控制台 2、创建小程序,编写名称和绑定商家即可 3、返回第一个页面,往下滑进入沙箱 4、进行相关的配置&a…
【Linux】零成本在家搭建自己的私人服务器解决方案
我这个人自小时候以来就特喜欢永久且免费的东西,也因此被骗过(花巨款买了永久超级会员最后就十几天)。 长大后骨子里也是喜欢永久且免费的东西,所以我不买服务器,用GitHubPage或者GiteePage搭建自己的静态私人博客&…

动态网页的核心——JSP
文章目录1,JSP 概述2,JSP 小案例2.1 搭建环境2.2 导入 JSP 依赖2.3 创建 jsp 页面2.4 编写代码2.5 测试3,JSP 原理4,JSP 总结4.1 JSP的 缺点4.2技术的发展历程4.3JSP的必要性最后说一句1,JSP 概述 JSP(全称…
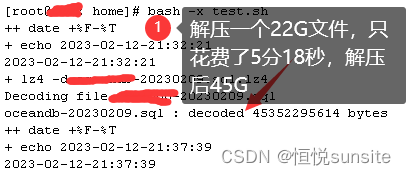
Linux命令之lz4命令
一、lz4命令简介 LZ4是一种压缩格式,特点是压缩/解压缩速度超快(压缩率不如gzip),如果你特别在意压缩速度,或者当前环境的CPU资源紧缺,可以考虑这种格式。lz4是一种非常快速的无损压缩算法,基于字节对齐LZ77系列压缩方…

while与do并行这的for
“while”当……的时候;与……同时;
“do”做;干;行动;
“for”给;对;为了;
从意思上不难理解,这是可以循环的代码英译,
特性:
while、需要的…