分类目录:《深入理解深度学习》总目录
之前我们探讨了机器翻译问题: 通过设计一个基于两个循环神经网络的编码器—解码器架构, 用于序列到序列学习。 具体来说,循环神经网络编码器将长度可变的序列转换为固定形状的上下文变量, 然后循环神经网络解码器根据生成的词元和上下文变量按词元生成输出(目标)序列词元。 然而,即使并非所有输入(源)词元都对解码某个词元都有用, 在每个解码步骤中仍使用编码相同的上下文变量。
在为给定文本序列生成手写的挑战中, Graves设计了一种可微注意力模型, 将文本字符与更长的笔迹对齐, 其中对齐方式仅向一个方向移动。 受学习对齐想法的启发,Bahdanau等人提出了一个没有严格单向对齐限制的可微注意力模型。 在预测词元时,如果不是所有输入词元都相关,模型将仅对齐(或参与)输入序列中与当前预测相关的部分。这是通过将上下文变量视为注意力集中的输出来实现的。
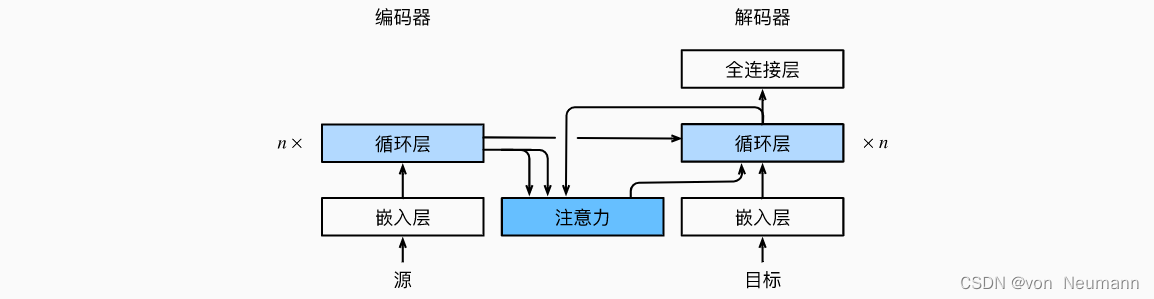
下面描述的Bahdanau注意力模型。假设输入序列中有个词元, 解码时间步的上下文变量是注意力集中的输出:
c t ′ = ∑ t = 1 T α ( s t ′ − 1 , h t ) h t c_{t'}=\sum_{t=1}^T\alpha(s_{t'-1}, h_t)h_t ct′=t=1∑Tα(st′−1,ht)ht
其中,时间步 t ′ − 1 t' - 1 t′−1时的解码器隐状态 s t ′ − 1 s_{t'-1} st′−1是查询, 编码器隐状态 h t h_t ht既是键,也是值, 注意力权重 α \alpha α是使用《深入理解深度学习——注意力机制(Attention Mechanism):注意力评分函数(Attention Scoring Function)》中所定义的加性注意力打分函数计算的。 下图描述了Bahdanau注意力的架构。
参考文献:
[1] Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015
[2] Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola. Dive Into Deep Learning[J]. arXiv preprint arXiv:2106.11342, 2021.




