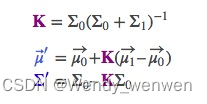--总觉得网上其他博客上写的都不太适合自己理解,百般翻阅书籍理解了一下,供自己日后复习之用。
本文的程序整理可到此处下载:http://download.csdn.net/download/sillykog/10123483
- 用过去的观测值来估计当前或者将来的信号称为预测
- 用当前和过去的观测值来估计当前信号称为滤波
- 用过去的观测值估计过去的信号成为平滑或内插
维纳滤波
1.要求
- 输入过程广义平稳
- 输入过程的统计特性已知
2.效果
- 当信号和干扰以及随机噪声同时输入该滤波器时,在输出端将信号尽可能精确表现出来
- 维纳滤波根据全部过去观测值和当前观测值来估计信号的当前值,解形式是传递函数或单位脉冲响应,说白了就是一个IIR无限单位脉冲滤波器
3.原理
定义误差为观测值减去估计值
e(n)=s(n)−s^(n)目标函数为最小均方误差
min E[e2(n)]=min E[(s(n)−s^(n))2]估计值计算如下
s^(n)=x(n)∗h(n)=∑m=−∞+∞h(m)x(n−m)最小均方误差可表示为
E[e2(n)]=E[(s(n)−s^(n))2]=E[(s(n)−∑m=0+∞h(m)x(n−m))2]对最小均方误差求对冲击响应的偏导并使其为零得到维纳霍夫方程
∂E[e2(n)∂h(m)=2E[(s(n)−∑m=0+∞h(m)x(n−m))x(n−j)],j=0,1,2,...此时求得的 h(m) 为 hopt(m) ,并有
Rxs(j)=E[x(n−j)s(n)]
Rxx(j−m)=E[x(n−m)x(n−j)]维纳霍夫方程方程可化简为
Rxs(j)=∑m=0+∞hopt(m)Rxx(j−m),j=0,1,2,...将方程展开我们可以得到更直观的方程组如下
j=0Rxs(0)=h(0)Rxx(0)+h(1)Rxx(−1)+...+h(N−1)Rxx(1−N)
j=1Rxs(1)=h(0)Rxx(1)+h(1)Rxx(0)+...+h(N−1)Rxx(2−N)
........................................................................
j=N−1Rxs(N−1)=h(0)Rxx(N−1)+h(1)Rxx(N−2)+...+h(N−1)Rxx(0)- 此处假设信号与噪声不相关
Rxs(m)=E[x(n)s(n+m)]=E[s(n)s(n+m)+w(n)s(n+m)]=E[s(n)s(n+m)]=Rss(m)
Rxx(m)=E[x(n)x(n+m)]=E[(s(n)+w(n))(s(n+m)w(n+m))]=Rss(m)+Rww(m) - 则维纳霍夫方程可化简为
Rss(j)=∑m=0+∞hopt(m)Rss(j−m)Rww(j−m),j=0,1,2,...
4.应用
Figure 1. 原始音频序列 Figure 2. 添加噪声序列

Figure 3. 含噪音频序列 Figure 4. 维纳滤波序列
滤波之后得到的结果是基于最小均方误差的,所以也没有办法完全恢复原始序列,但总比含噪的序列效果好一些。该例程程序见文章开头下载连接,本例是直接在时域上进行求解,但时域求解毕竟还是针对较短的序列,数据量一大就无法计算了。
这里要强调的一点是许多网上流传的维纳滤波的程序均是转换到频域上求解,但由于维纳滤波方程t>0的因果性约束,是无法直接频谱相除求解的,必须要用频谱分解法或者伯德-香农的白化法。但以上两种频域解法都是针对特定功率谱函数的,所以需要对系统进行建模,应用起来其实也不方便的,具体内容还是请大家查阅相关资料会清楚一些。
- 由左边序列训练得到维纳滤波的最佳冲击脉冲序列,并对右边序列进行滤波我们可以看到维纳滤波的效果,维纳滤波其实就是一个去相关的过程,对与期望信号不相关的噪声进行最大抑制其实就是维纳滤波器的实际作用,但麻烦就麻烦在维纳滤波器需要一组预训练的期望信号,这在实际当中基本上是做不到的,所以维纳滤波始终不能被广泛应用。

- 另一个方面的话,为什么维纳滤波要求考虑之前所有的观测值呢,这是由于维纳滤波器的一个时效性的问题,由1~N时刻的观测数据计算得到的滤波器直接应用在N+1~2N时刻上,我们发现效果是极差的,因此还是要根据之前所有的观测数值来考虑维纳滤波器的冲击序列h(n)
特别的再提到一点,即便只由部分观测值计算得到的维纳滤波器在时域上表现极差,但在频域上还是差强人意的
关于二维图像的维纳滤波也是非常有意思的,可以参考该篇博文
http://blog.csdn.net/liyuefeilong/article/details/43307197
卡尔曼滤波
1.要求
- 能用卡尔曼滤波的前提是这个系统是可观测的。
- 相比于维纳滤波,卡尔曼滤波可以适用于非平稳随机过程,而且可以递推实现
2.效果
- 卡尔曼滤波是在已知系统和量测的数学模型、量测噪声统计特性及系统状态初值的情况下,利用输出信号的量测数据和系统模型方程,实时获得系统状态变量和输入信号的最优估计值。它是一种线性、无偏、且误差方差最小的随机系统最优估计算法。
3.原理
假设线性离散系统模型如下
状态方程 xk=Φk,k−1xk−1+Γk,k−1ωk−1
测量方程 zk=Hkxk+νk一般情况下我们假定
E[ωk−1]=0,Rωω(k,j)=Qkδkj
E[νk]=0,R(k,j)=Qννδkj
(设 x^k|k−1 为k时刻的估计值, x^k|k 为k时刻的最优估计值(修正值))
- k时刻估计值为
x^k|k−1=Φk,k−1x^k−1|k−1 k时刻观测值
z^k|k−1=Hkx^k|k−1由预测偏差修正状态估计量
x^k|k=x^k|k−1+Kk[zk−z^k|k−1]=x^k|k−1+Kk[zk−Hkx^k|k−1]目标函数为最小误差方差
min E[(xk−x^k|k)(xk−x^k|k)T]由下式
xk−x^k|k=xk−x^k|k−1−Kk[zk−Hkx^k|k−1]=xk−x^k|k−1−Kk[Hkxk+νk−Hkx^k|k−1]=[I−KkHk](xk−1−x^k−1|k−1)−Kkνk误差方差可等价于
Pk|k=E[(xk−x^k|k)(xk−x^k|k)T]=[I−KkHk]Pk|k−1[I−KkHk]T+KkRkKTkK_k的选择是使得 tr(Pk|k) 最小,求 ∂tr(Pk|k)∂Kk=0 得到
Kk=Pk|k−1HTk(HkPkk−1HTk+Rk)−1
Pk|k=[I−KkHk]Pk|k−1
Pk|k−1=Φk,k−1Pk−1|k−1ΦTk,k−1+Γk,k−1Qk−1ΓTk,k−1
4.应用
- 能用卡尔曼滤波的前提是这个系统是可观测的
- 卡尔曼滤波也可以处理观测方程带乘性噪声的系统,不过公式要复杂得多
- 如果系统的噪声统计特性不变(高斯白噪声,均值和方差不变),而且是线性系统,是不用一直迭代着算卡尔曼增益的,直接求卡尔曼增益的稳态值即可
应用中大多数情况下大家其实并不知道建模噪声和观测噪声的统计特性,一般是假定为零均值,方差会去试
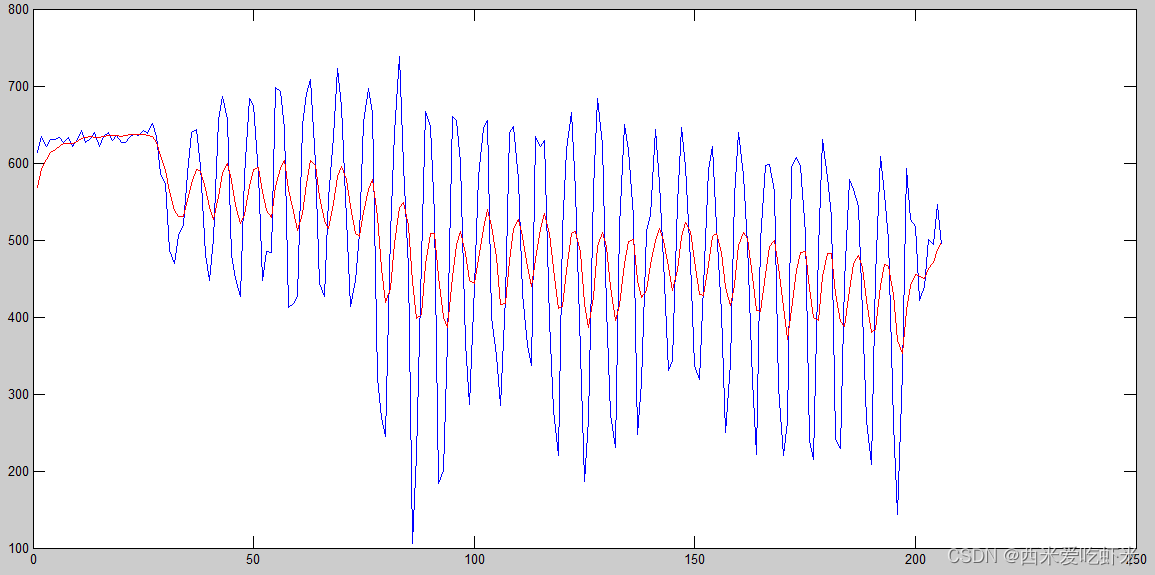
使用卡尔曼滤波对信号进行跟踪,测量误差为高斯噪声。
跟随信号为一次函数时,左图是观测量与噪声数值相近,因此估计值的效果较差,右图是观测量远大于噪声,因此得到了较好的跟踪效果。
- 关于卡尔曼滤波的过程有必要再提一点的是关于卡尔曼增益阵K
- 卡尔曼滤波的修正方程为
xk|k=xk|k−1+Kk[zk−Hkxk|k−1] - 可知是由卡尔曼增益阵K来对观测量和估计量进行折中的。
K=Pk|k−1HTk[HkPk|k−1HTk+Rk]−1 - 特别的当H为单位阵时
K=Pk|k−1[Pk|k−1+Rk]−1
我们可以知道,当P变大时,即上一次的修正值不准确,则R不变情况下,K也随着变大,因此下一次的修正值会增加对观测值的权重。当P变小,即上一次修正值较准确,则R不变情况下,K变小,下一次的修正值会增加对估计值的权重。特别的当误差R变大时,其K变小,也即系统测量噪声太大,修正值会更侧重于估计值。从实际上看,我们发现卡尔曼滤波的思想是既不相信观测值,又不相信估计值,但误差较大的时候,才会相信观测值。
上面的图片是期望信号和滤波信号,下面的图片是观测信号,可以看到由于状态转移方程不能真实对正弦函数进行线性关系建模,因此导致误差非常大,结果滤波信号完全取决于观测值了
总结
- 作为现代控制理论一部分的维纳滤波和卡尔曼滤波一定程度上解决了对含噪信号的最优估计,但维纳滤波在实际适用中受限,即便当其为因果滤波器,要得到半无限时间区间内的全部观测数据也很难满足,同时也不能用于噪声为非平稳的随机过程,对于向量情况应用不方便。基本上还是适用于一维平稳序列的最小均方误差估计。卡尔曼滤波在信号估计上有十分强大的实用性,但页由于状态估计方程的限制,卡尔曼的理论基本局限于线形系统。