目录
- 需求
- 网站分析
- 代码实现
- 进一步
- 通过接口获取
- 定时获取
- 页面展示
- 其他参考资源
需求
老板:微软必应https://cn.bing.com/ 首页的每日一图看着不错,能不能自动获取
我:我试试
网站分析
我们查看网页元素,不难发现背景图就在类名为.img_cont 的标签下
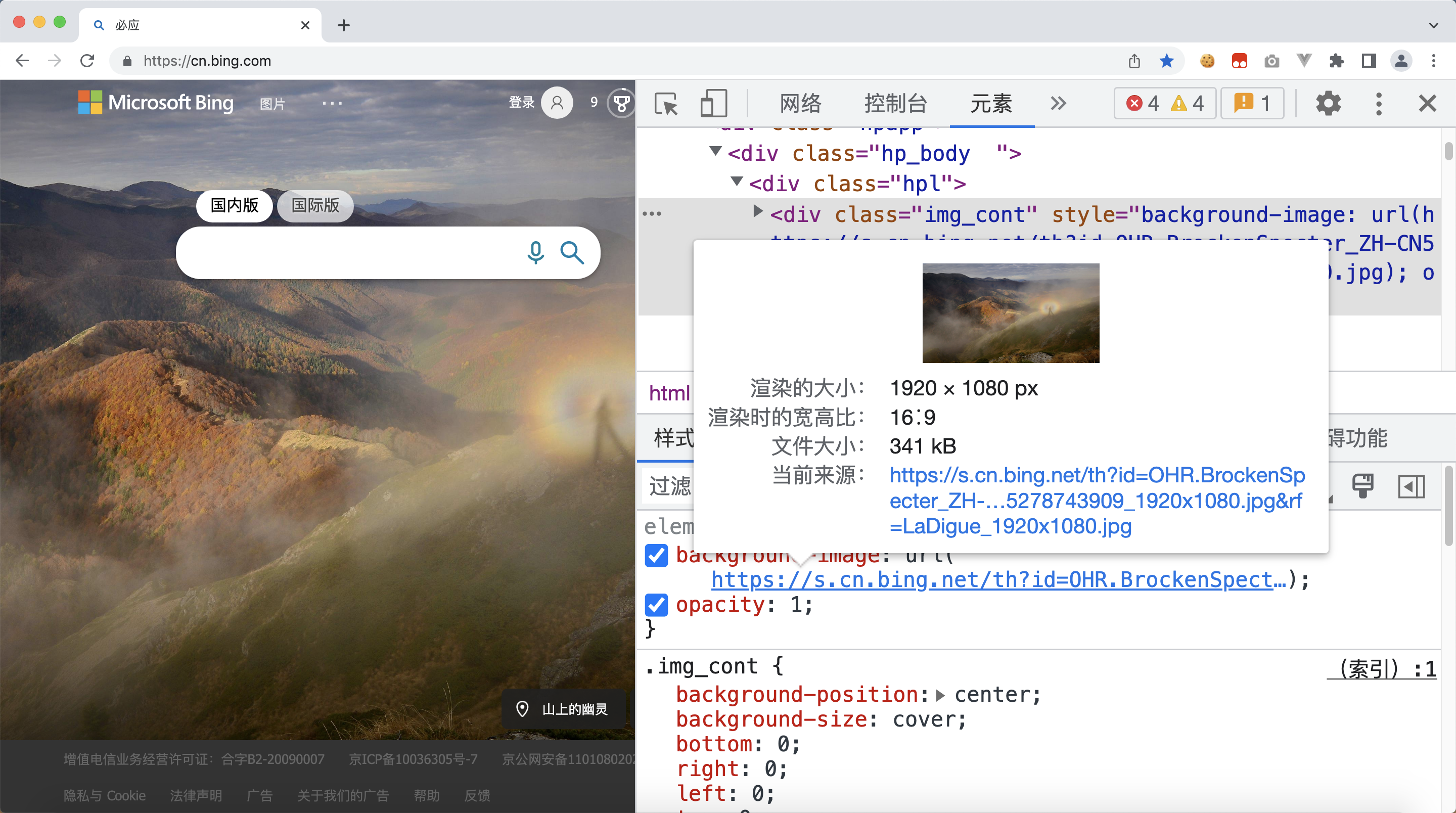
可是搜索源代码 view-source:https://cn.bing.com/
<div class="img_cont" style="background-image: url(https://s.cn.bing.net/th?id=OHR.BrockenSpecter_ZH-CN5278743909_1920x1080.jpg&rf=LaDigue_1920x1080.jpg); opacity: 1;">
发现style属性中的数据不能直接获取,需要使用到正则提取url
换个方法,试试搜索图片地址:
https://s.cn.bing.net/th?id=OHR.BrockenSpecter_ZH-CN5278743909_1920x1080.jpg
发现有三个地方

第一处是在header中
<link rel="preload" href="https://s.cn.bing.net/th?id=OHR.BrockenSpecter_ZH-CN5278743909_1920x1080.jpg&rf=LaDigue_1920x1080.jpg&qlt=50" as="image" id="preloadBg" />
第二处在类名为img_cont 的标签中
<div class="img_cont" style="background-image: url(https://s.cn.bing.net/th?id=OHR.BrockenSpecter_ZH-CN5278743909_1920x1080.jpg&rf=LaDigue_1920x1080.jpg); opacity: 1;">
第三处在js代码中
"Image":{"Url":"https://s.cn.bing.net/th?id=OHR.BrockenSpecter_ZH-CN5278743909_1920x1080.jpg\u0026rf=LaDigue_1920x1080.jpg",
代码实现
通过以上分析,我们可以发现,通过id="preloadBg"的元素获取比较方便
此处需要加一个请求头,避免获取不到正常的网页源代码
安装依赖
$ python --version
Python 3.6.5$ pip install parsel requests
代码示例
# -*- coding: utf-8 -*-
"""
@File : demo.py
@Date : 2022-10-26
@Author : Peng Shiyu
"""import parsel
import requestsdef get_bing_image():url = 'https://cn.bing.com'headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'}res = requests.get(url, headers=headers)res.encoding = res.apparent_encodingsel = parsel.Selector(res.text, base_url=url)return sel.css('#preloadBg::attr(href)').extract_first()if __name__ == '__main__':image_url = get_bing_image()print(image_url)
# https://s.cn.bing.net/th?id=OHR.BrockenSpecter_ZH-CN5278743909_1920x1080.jpg&rf=LaDigue_1920x1080.jpg&qlt=50进一步
我们发现,图片还有一些介绍信息,我们看看能不能拿到
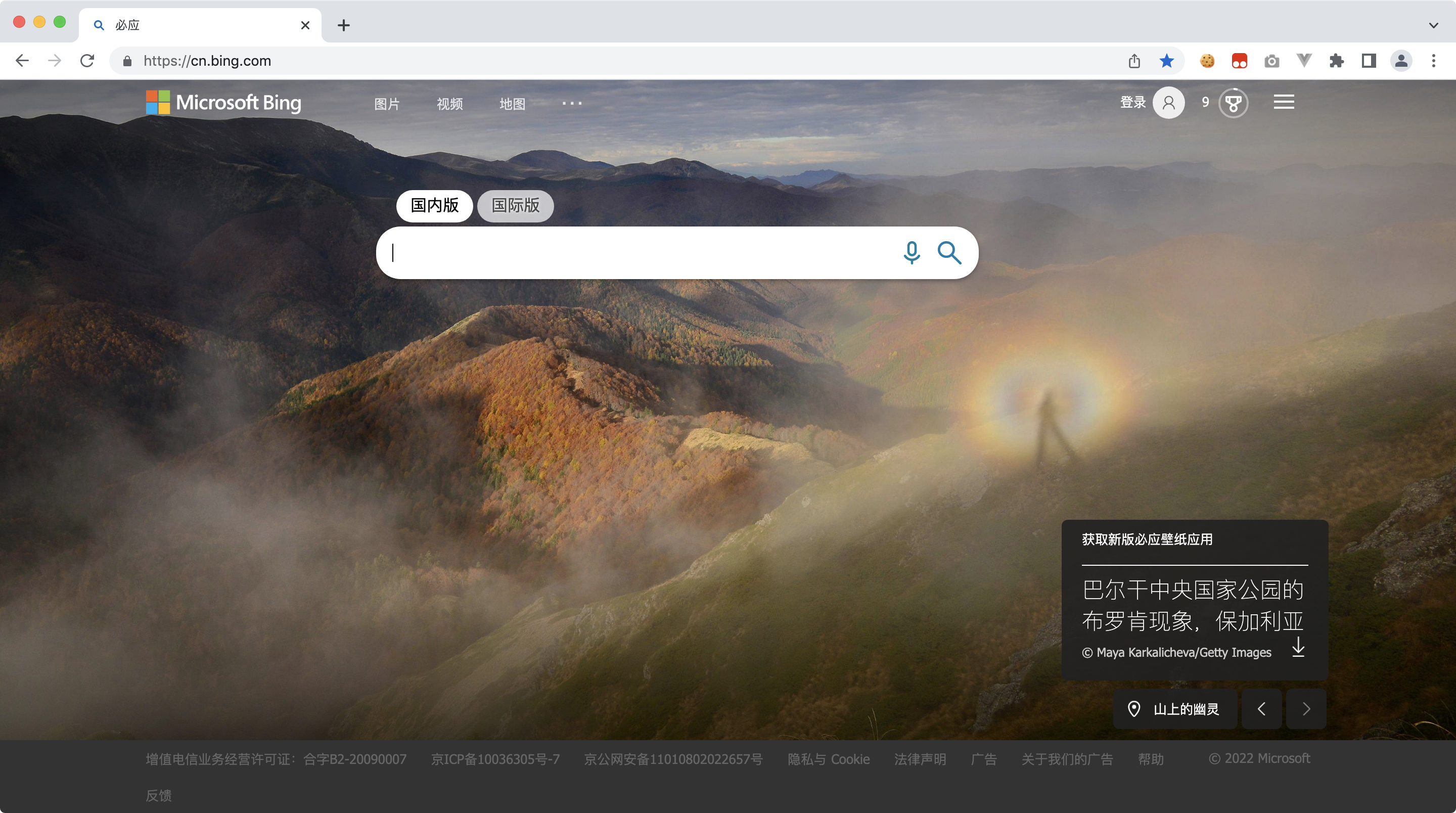
再次查看源码,我们可以发现,网页中有一个js的变量,包含了页面中壁纸的信息
// 截取部分代码
var _model ={"Headline":"山上的幽灵","Title":"巴尔干中央国家公园的布罗肯现象,保加利亚"}
我们可以通过re正则表达式解析这个json字符串,获取更多的数据
# -*- coding: utf-8 -*-
"""
@File : demo.py
@Date : 2022-10-26
@Author : Peng Shiyu
"""
import json
import reimport requestsdef get_bing_image():url = 'https://cn.bing.com'headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'}res = requests.get(url, headers=headers)res.encoding = res.apparent_encodingret = re.search("var _model =(\{.*?\});", res.text)if not ret:returndata = json.loads(ret.group(1))image_content = data['MediaContents'][0]['ImageContent']return {'headline': image_content['Headline'],'title': image_content['Title'],'description': image_content['Description'],'image_url': image_content['Image']['Url'],'main_text': image_content['QuickFact']['MainText']}if __name__ == '__main__':res = get_bing_image()print(json.dumps(res, ensure_ascii=False, indent=2))输出
{"headline": "山上的幽灵","title": "巴尔干中央国家公园的布罗肯现象,保加利亚","description": "万圣节快到了,今天的照片也非常应景,展示了一只“幽灵”,也就是布罗肯现象。尽管看着灵异,但布罗肯现象并非超自然现象。这是一位观察者被投射在阳光对面云层上的阴影。布罗肯现象很少见,但如果你在黎明时分爬上薄雾弥漫的山坡,则有可能幸运地目睹这种现象。只要满足条件,布罗肯现象可以出现在任何地方。在德国哈尔茨山脉的布罗肯峰,当地传说浓雾弥漫的山间有幽灵出没。1780年,约翰·西尔伯施拉格在此观察到了“幽灵”,对其进行了描述记录,并将其命名为“布罗肯现象”。此后,布罗肯现象便常常被记录在有关该地区的文献之中。","image_url": "https://s.cn.bing.net/th?id=OHR.BrockenSpecter_ZH-CN5278743909_1920x1080.jpg&rf=LaDigue_1920x1080.jpg","main_text": "布罗肯现象出现在日出与日落时的高山上,当前面弥漫着雾气时,太阳光将人的背影衍射在雾气上,浮现出彩虹轮廓。"
}
通过接口获取
当然,我们也不必那么麻烦,bing已经贴心的给大家提供了一个接口,可以直接使用。
只不过接口中返回的介绍性文字没有直接从页面上获取的多。
接口地址:
https://cn.bing.com/HPImageArchive.aspx?format=js&idx=0&n=1&mkt=zh-CN
参数
| 参数 | 含义 |
|---|---|
| format | 返回数据形式 js - json xml - xml |
| idx | 截止天数 0-今天 -1 - 截止至明天 1 截止至昨天 |
| n | 返回数量 |
| mkt | 地区 zh-CN - 国区 |
接口来源 Python - 定时自动获取 Bing 首页壁纸
返回数据
{"images": [{"startdate": "20221027","fullstartdate": "202210271600","enddate": "20221028","url": "/th?id=OHR.FrankensteinFriday_ZH-CN5814917673_1920x1080.jpg&rf=LaDigue_1920x1080.jpg&pid=hp","urlbase": "/th?id=OHR.FrankensteinFriday_ZH-CN5814917673","copyright": "洛桑日内瓦湖上空的暴风雨,瑞典 (© Suradech Singhanat/Shutterstock)","copyrightlink": "https://www.bing.com/search?q=%E6%97%A5%E5%86%85%E7%93%A6%E6%B9%96&form=hpcapt&mkt=zh-cn","title": "一个黑暗的暴风雨之夜","quiz": "/search?q=Bing+homepage+quiz&filters=WQOskey:%22HPQuiz_20221027_FrankensteinFriday%22&FORM=HPQUIZ","wp": true,"hsh": "426b0dd10360d364a0fcab233d04a9e3","drk": 1,"top": 1,"bot": 1,"hs": []}],"tooltips": {"loading": "正在加载...","previous": "上一个图像","next": "下一个图像","walle": "此图片不能下载用作壁纸。","walls": "下载今日美图。仅限用作桌面壁纸。"}
}定时获取
我们没有服务器,没有数据库的情况下,怎么才能获取每日最新的图呢?总不能每天自己手动执行吧,肯定不行。
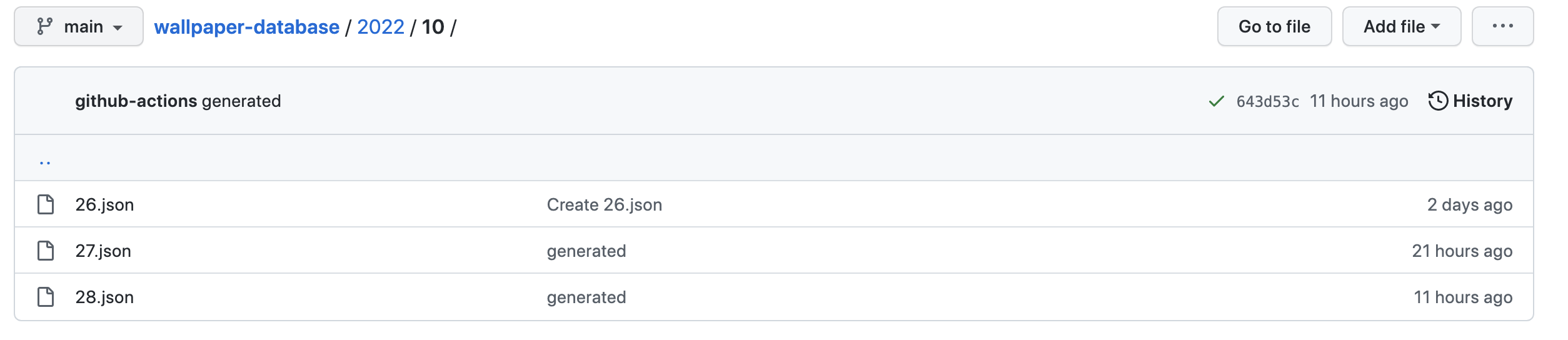
于是。我们可以利用Github Actions 每天执行定时任务,每天定时自动获取数据
数据获取项目地址:https://github.com/mouday/wallpaper-database
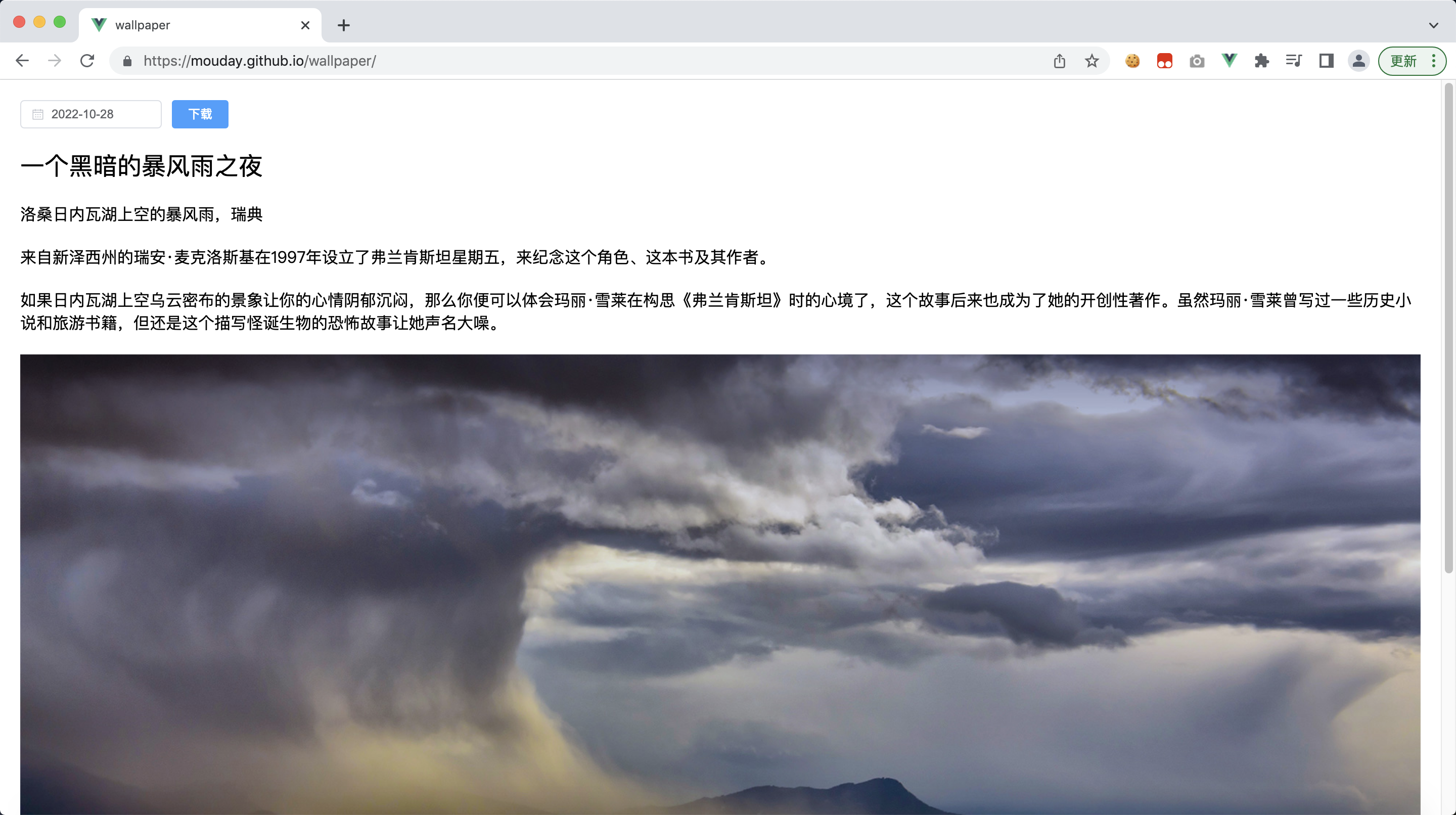
页面展示
不能每次都查看数据,我们需要一个直观的显示地址,所以可以用Vue.js制作一个简单的预览地址,将我们获取的数据展示到浏览器。
数据展示项目地址:https://github.com/mouday/wallpaper
预览地址(仅供学习使用):https://mouday.github.io/wallpaper/
其他参考资源
有小伙伴已经做了必应壁纸图片网站
https://bing.ioliu.cn/
https://www.todaybing.com/
https://www.bingimg.cn/

![[DesktopPicture]桌面图片](https://img2018.cnblogs.com/blog/1530634/201811/1530634-20181121185641097-861047351.jpg)