1、企业级调优
1.1 计算资源配置
到此学习的计算环境为HIve on MR。计算资源的调整主要包括Yarn和MR。
1.1.1 Yarn资源配置
1、Yarn配置说明
需要调整的Yarn的参数均与CPU、内存等资源有关,核心配置参数如下:
(1)yarn.nodemanager.resource.memory-mb
该参数的含义是,一个NodeManager节点分配给Container使用的内存。该参数的配置,取决于NodeManager所在节点的总内存容量和该节点运行的其他服务的数量。
(2)yarn.nodemanager.resource.cpu-vcores
该参数的含义是,一个NodeManager节点分配给Container使用的CPU核数。该参数的配置,同样取决于NodeManager所在节点的总CPU核数和该节点运行的其他服务。
(3)yarn.scheduler.maximum-allocation-mb
该参数的含义是,单个Container能够使用的最大内存。
(4)yarn.scheduler.minimum-allocation-mb
该参数的含义是,单个Container能够使用的最小内存。
1.1.2 MapReduce资源配置
MapReduce资源配置主要包括Map Task的内存和CPU核数,以及Reduce Task的内存和CPU核数。核心配置参数如下:
1、mapreduce.map.memory.mb
该参数的含义是,单个Map Task申请的container容器内存大小,其默认值为1024。该值不能超出yarn.scheduler.maximum-allocation-mb和yarn.scheduler.minimum-allocation-mb规定的范围。
2、mapreduce.map.cpu.vcores
该参数的含义是,单个Map Task申请的container容器cpu核数,其默认值为1。该值一般无需调整。
3、mapreduce.reduce.memory.mb
该参数的含义是,单个Reduce Task申请的container容器内存大小,其默认值为1024。该值同样不能超出yarn.scheduler.maximum-allocation-mb和yarn.scheduler.minimum-allocation-mb规定的范围。
4、mapreduce.reduce.cpu.vcores
该参数的含义是,单个Reduce Task申请的container容器cpu核数,其默认值为1。该值一般无需调整。
1.2 Explain查看执行计划
1.2.1 Explain执行计划概述
Explain呈现的执行计划,由一系列Stage组成,这一系列Stage具有依赖关系,每个Stage对应一个MapReduce Job,或者一个文件系统操作。
若某个Satge对应的一个MapReduce Job,其Map段和Reduce端的计算逻辑分别由Map Operator Tree 和Reduce Operator Tree进行描述,Operator Tree 由一系列的Operator组成,应该Operator代表在Map或Reduce阶段的一个单一的逻辑操作,例如TableScan Operator,Select Operator,Join Operator等。
下图是由一个执行计划绘制而成:
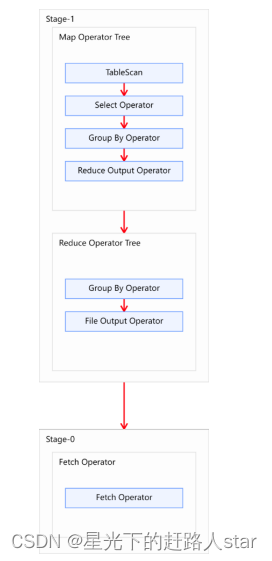
常见的Operator及作用如下:
TableScan:表扫描操作,通常map段第一个操作肯定是表扫描操作
Select Operator:选取操作
Group by Operator:分组聚合操作
Reduce Output Operator:输出到reduce操作
Filter Operator:过滤操作
Join Operator:join操作
File Output Operator:文件输出操作
Fetch Operator:客户端获取数据操作
1.2.2 基本语法
Explain [Formatted | Extended | Dependency] query-sql
注:Formatted、Extended、Dependency关键字为可选项,各自作用如下。
FORMATTED:将执行计划以JSON字符串的形式输出
EXTENDED:输出执行计划中的额外信息,通常是读写的文件名等信息
DEPENDENCY:输出执行计划读取的表及分区
1.2.3 案例实操
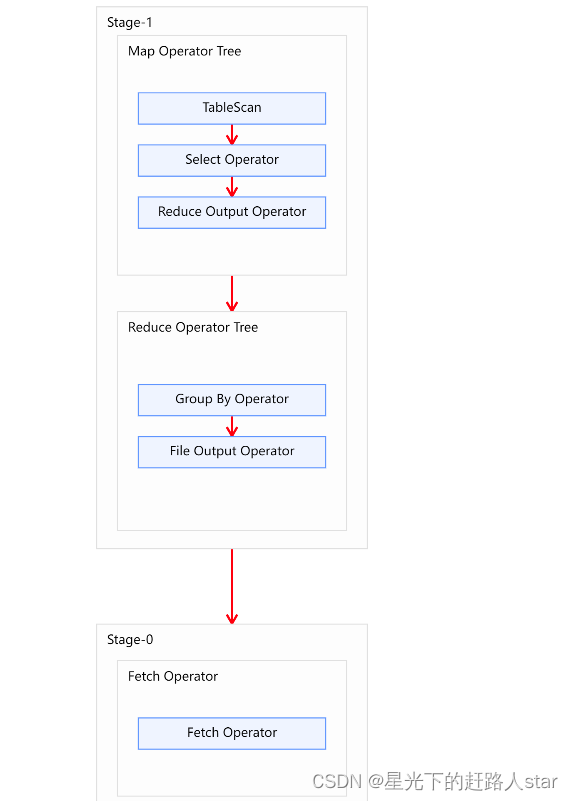
1、查看下面这条语句的执行
explain formatted
selectsku_id,count(*)
from order_detail
group by sku_id;
2、执行计划如下图

1.3 HQL语法优化之分组聚合优化
1.3.1 优化说明
Hive中未经优化的分组聚合是通过一个MapReduce Job实现的。Map端负责读取数据,并按照分组字段分区,通过Shuffle,将数据发往Reduce端,各组数据在Reduce端完成最终的聚合运算。
Hive对分组聚合的优化主要是围绕着减少Shuffle数据量进行,具体做法是map-side聚合。所谓map-side聚合,就是在map端维护一个hash table,利用其完成部分的聚合,然后将部分聚合的结果,按照分组字段分区,发送至reduce端,完成最终的聚合。map-side聚合能有效减少Shuffle的数据量,提高分组聚合运算的效率。
map-side聚合相关的参数如下:
--启动map-side聚合
set hive.map.aggr=true;--用于检测源表数据是否适合进行map-side聚合。检测的方法是:先对若干条数据进行map-side聚合,若聚合后的条数和聚合前的条数比值小于该值,则认为该表适合进行map-side聚合;否则,认为该表数据不适合进行map-side聚合,后续数据便不再进行map-side聚合。
set hive.map.aggr.hash.min.reduction=0.5;--用于检查源表是否适合map-side聚合的条数
set hive.groupby.mapaggr.checkinterval=100000;
1.3.1 优化案例
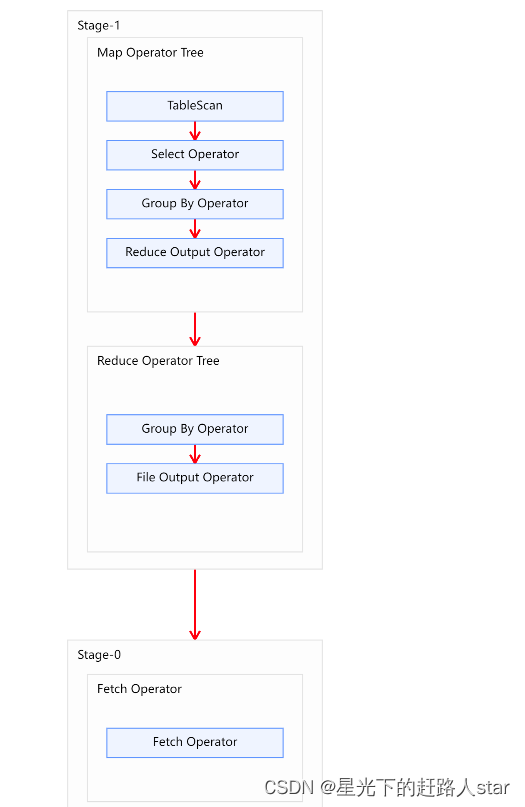
1、实例SQL
selectproduct_id,count(*)
from order_detail
group by product_id;
2、优化前
3、优化思路
可以考虑开启map-side聚合,配置以下参数
--启用map-side聚合,默认是true
set hive.map.aggr=true;--用于检测源表数据是否适合进行map-side聚合。检测的方法是:先对若干条数据进行map-side聚合,若聚合后的条数和聚合前的条数比值小于该值,则认为该表适合进行map-side聚合;否则,认为该表数据不适合进行map-side聚合,后续数据便不再进行map-side聚合。
set hive.map.aggr.hash.min.reduction=0.5;--用于检测源表是否适合map-side聚合的条数。
set hive.groupby.mapaggr.checkinterval=100000;--map-side聚合所用的hash table,占用map task堆内存的最大比例,若超出该值,则会对hash table进行一次flush。
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;
1.4 HQL语法优化之Join优化
1.4.1 Join算法概述
Hive拥有多种Join算法,包括Common Join,Map Join,Bucket Map Join,Sort Merge Bucket Map Join等,下面对每种Join算法做简要说明:
1、Common Join
Common Join算法是Hive中最稳定的算法,其通过一个MapReduce Job完成一个Join操作。Map端负责读取Join操作所需表的数据,并按照关联字段进行分区,通过Shuffle,将其发送到Reduce端,相同Key的数据在Reduce端完成最终的Join操作。如下图所示:
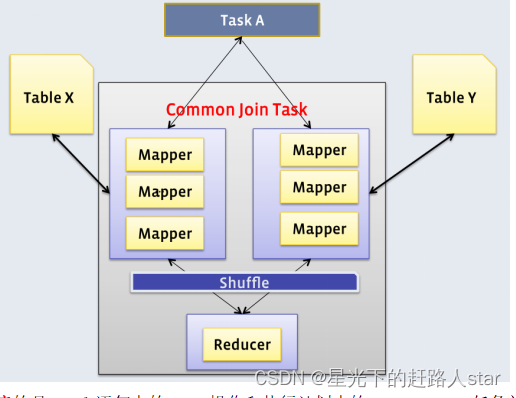
需要注意的是,sql语句中的join操作和执行计划中的Common Join任务并非一对一的关系,一个sql语句中的相邻的且关联字段相同的多个join操作可以合并为一个Common Join任务。
例如:
hive (default)>
select a.val, b.val, c.val
from a
join b on (a.key = b.key1)
join c on (c.key = b.key1)
上述sql语句中两个join操作的关联字段均为b表的key1字段,则该语句中的两个join操作可由一个Common Join任务实现,也就是可通过一个Map Reduce任务实现。
select a.val, b.val, c.val
from a
join b on (a.key = b.key1)
join c on (c.key = b.key2)
上述sql语句中的两个join操作关联字段各不相同,则该语句的两个join操作需要各自通过一个Common Join任务实现,也就是通过两个Map Reduce任务实现。
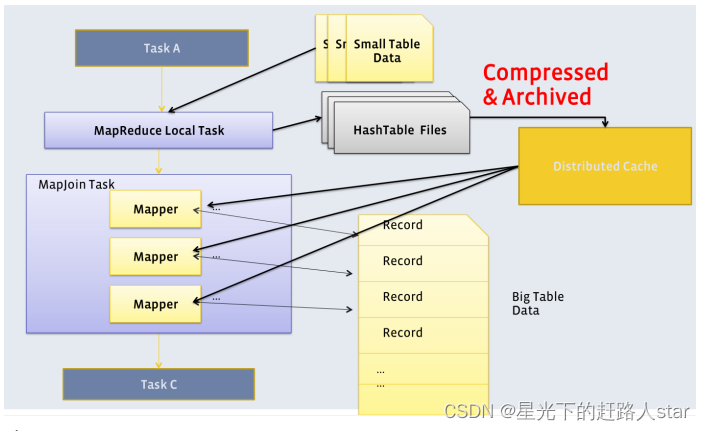
2、Map Join
Map Join算法可以通过两个只有map阶段的Job完成一个join操作。其适用场景为大表join小表。若某join操作满足操作要求,则第一个job会读取小表的数据,将其制作为hashtable,并上传到hadoop分布式缓存(本质上是上传至HDFS)。第二个Job会先从分布式缓存中读取小表数据,并缓存在Map Task的内存中,然后扫描大表数据,这样在map端即可完成关联操作。如下图所示:
3、Bucket Map Join
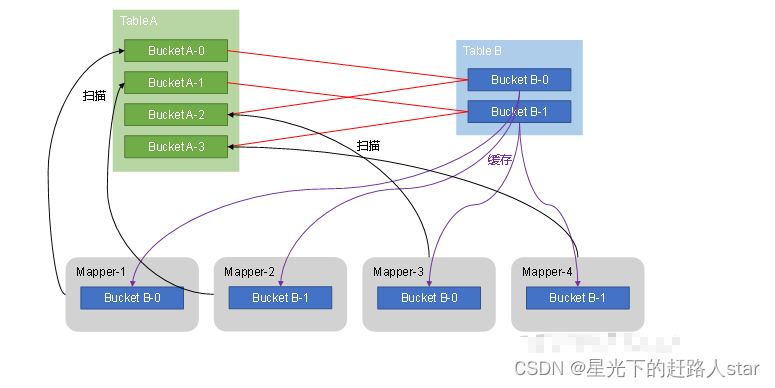
Bucket Map Join 是对Map Join算法的改进,其打破了Map Join只适用于大表join小表的限制,可用于大表join大表的场景。
Bucket Map Join 的核心思想是:若能保证参与Join的表均为分桶表,且关联字段为分桶字段,且其中一张表的分桶数量是另外一张分桶表数量的整数倍,就能保证参与Join的两张表的分桶之间具有明确的关联关系,所以就可以在两表的分桶间进行Map Join操作了。这样一来,第二个Job的Map端就无需再缓存小表的全表数据了,而只需缓存其所需要的分桶即可。其原理如图所示:
4、Sort Merge Bucket Map Join
Sort Merge Bucket Map Join(简称SMB Map Join)基于Bucket Map Join。SMB Map Join要求,参与join的表均为分桶表,且需保证分桶内的数据是有序的,且分桶字段、排序字段和关联字段为相同字段,且其中一张表的分桶数量是另外一张表分桶数量的整数倍。
SMB Map Join同Bucket Join一样,同样是利用两表各分桶之间的关联关系,在分桶之间进行join操作,不同的是,分桶之间的join操作的实现原理。Bucket Map Join,两个分桶之间的join实现原理为Hash Join算法;而SMB Map Join,两个分桶之间的join实现原理为Sort Merge Join算法。
Hash Join和Sort Merge Join均为关系型数据库中常见的Join实现算法。Hash Join的原理相对简单,就是对参与join的一张表构建hash table,然后扫描另外一张表,然后进行逐行匹配。Sort Merge Join需要在两张按照关联字段排好序的表中进行,其原理如图所示:
Hive中的SMB Map Join就是对两个分桶的数据按照上述思路进行Join操作。可以看出,SMB Map Join与Bucket Map Join相比,在进行Join操作时,Map端是无需对整个Bucket构建hash table,也无需在Map端缓存整个Bucket数据的,每个Mapper只需按顺序逐个key读取两个分桶的数据进行join即可。
1.4.2 Map Join
优化说明:
Map Join有两种触发方式,一种是用户在SQL语句中增加hint提示,另一种是Hive优化器根据参与Join表的数据量大小,自动触发。
1、hint提示
用户可以通过如下方式,指定通过map join算法,并且ta将作为map join中的小表。这种方式已经过时,不推荐使用。
select /*+ mapjoin(ta) */ta.id,tb.id
from table_a ta
join table_b tb
on ta.id=tb.id;
2、自动触发
Hive在编译SQL语句阶段,起初所有的join操作均采用Common Join算法实现。
之后在物理优化阶段,Hive会根据每个Common Join任务所需表的大小判断该Common Join任务是否能够转换为Map Join任务,若满足要求,便将Common Join任务自动转换为Map Join任务。
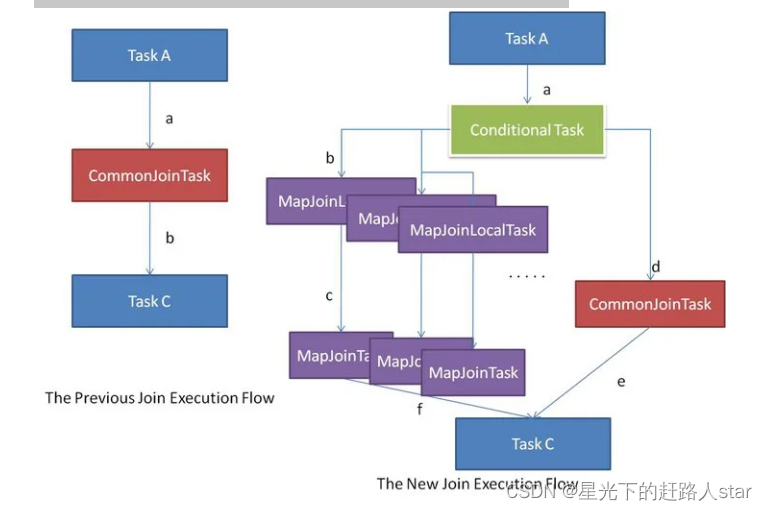
但有些Common Join任务所需的表大小,在SQL的编译阶段是未知的(例如对子查询进行join操作),所以这种Common Join任务是否能转换成Map Join任务在编译阶是无法确定的。
针对这种情况,Hive会在编译阶段生成一个条件任务(Conditional Task),其下会包含一个计划列表,计划列表中包含转换后的Map Join任务以及原有的Common Join任务。最终具体采用哪个计划,是在运行时决定的。大致思路如下图所示:
Map join自动转换的具体判断逻辑如下图所示:
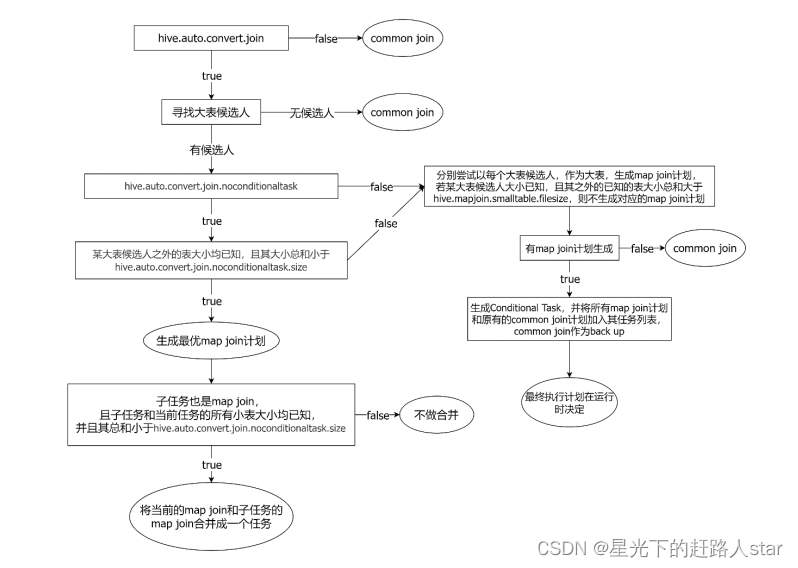
图中涉及的参数如下:
--启动Map Join自动转换
set hive.auto.convert.join=true;--一个Common Join operator转为Map Join operator的判断条件,若该Common Join相关的表中,存在n-1张表的已知大小总和<=该值,则生成一个Map Join计划,此时可能存在多种n-1张表的组合均满足该条件,则hive会为每种满足条件的组合均生成一个Map Join计划,同时还会保留原有的Common Join计划作为后备(back up)计划,实际运行时,优先执行Map Join计划,若不能执行成功,则启动Common Join后备计划。
set hive.mapjoin.smalltable.filesize=250000;--开启无条件转Map Join
set hive.auto.convert.join.noconditionaltask=true;--无条件转Map Join时的小表之和阈值,若一个Common Join operator相关的表中,存在n-1张表的大小总和<=该值,此时hive便不会再为每种n-1张表的组合均生成Map Join计划,同时也不会保留Common Join作为后备计划。而是只生成一个最优的Map Join计划。
set hive.auto.convert.join.noconditionaltask.size=10000000;
1.4.3 Bucket Map Join
优化说明:Bucket Map Join不支持自动转换,发须通过用户在SQL语句中提供如下Hint提示,并配置如下相关参数,方可使用。
1、hint提示
select /*+ mapjoin(ta) */ta.id,tb.id
from table_a ta
join table_b tb on ta.id=tb.id;
2、相关参数
--关闭cbo优化,cbo会导致hint信息被忽略
set hive.cbo.enable=false;
--map join hint默认会被忽略(因为已经过时),需将如下参数设置为false
set hive.ignore.mapjoin.hint=false;
--启用bucket map join优化功能
set hive.optimize.bucketmapjoin = true;
1.4.4 Sort Merge Bucket Map Join
优化说明:Sort Merge Bucket Map Join有两种触发方式,包括Hint提示和自动转换。Hint提示已过时,不推荐使用。下面是自动转换的相关参数:
--启动Sort Merge Bucket Map Join优化
set hive.optimize.bucketmapjoin.sortedmerge=true;
--使用自动转换SMB Join
set hive.auto.convert.sortmerge.join=true;
1.5 HQL语法优化之数据倾斜
1.5.1 数据倾斜概述
数据倾斜问题,通常是指参与计算的数据分布不均,即某个key或者某些key的数据量远超其他key,导致在shuffle阶段,大量相同key的数据被发往同一个Reduce,进而导致该Reduce所需的时间远超其他Reduce,成为整个任务的瓶颈。
Hive中的数据倾斜常出现在分组聚合和join操作的场景中,下面分别介绍在上述两种场景下的优化思路。
1.5.2 分组聚合导致的数据倾斜
优化说明:
Hive中未经优化的分组聚合,是通过一个MapReduce Job实现的。Map端负责读取数据,并按照分组字段分区,通过Shuffle,将数据发往Reduce端,各组数据在Reduce端完成最终的聚合运算。
如果group by分组字段的值分布不均,就可能导致大量相同的key进入同一Reduce,从而导致数据倾斜问题。
由分组聚合导致的数据倾斜问题,有以下两种解决思路:
1、Map-side聚合
开启Map-Side聚合后,数据会现在Map端完成部分聚合工作。这样一来即便原始数据是倾斜的,经过Map端的初步聚合后,发往Reduce的数据也就不再倾斜了。最佳状态下,Map-端聚合能完全屏蔽数据倾斜问题。
相关参数如下:
--启用map-side聚合
set hive.map.aggr=true;--用于检测源表数据是否适合进行map-side聚合。检测的方法是:先对若干条数据进行map-side聚合,若聚合后的条数和聚合前的条数比值小于该值,则认为该表适合进行map-side聚合;否则,认为该表数据不适合进行map-side聚合,后续数据便不再进行map-side聚合。
set hive.map.aggr.hash.min.reduction=0.5;--用于检测源表是否适合map-side聚合的条数。
set hive.groupby.mapaggr.checkinterval=100000;--map-side聚合所用的hash table,占用map task堆内存的最大比例,若超出该值,则会对hash table进行一次flush。
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;
2、Skew-GroupBy优化
Skew-GroupBy的原理是启动两个MR任务,第一个MR按照随机数分区,将数据分散发送到Reduce,完成部分聚合,第二个MR按照分组字段分区,完成最终聚合。
相关参数如下:
--启用分组聚合数据倾斜优化
set hive.groupby.skewindata=true;
1.5.3Join导致的数据倾斜
未经优化的join操作,默认是使用common join算法,也就是通过一个MapReduce Job完成计算。Map端负责读取join操作所需表的数据,并按照关联字段进行分区,通过Shuffle,将其发送到Reduce端,相同key的数据在Reduce端完成最终的Join操作。
如果关联字段的值分布不均,就可能导致大量相同的key进入同一Reduce,从而导致数据倾斜问题。
由join导致的数据倾斜问题,有如下三种解决方案:
1、map join
使用map join算法,join操作仅在map端就能完成,没有shuffle操作,没有reduce阶段,自然不会产生reduce端的数据倾斜。该方案适用于大表join小表时发生数据倾斜的场景。
相关参数如下:
--启动Map Join自动转换
set hive.auto.convert.join=true;--一个Common Join operator转为Map Join operator的判断条件,若该Common Join相关的表中,存在n-1张表的大小总和<=该值,则生成一个Map Join计划,此时可能存在多种n-1张表的组合均满足该条件,则hive会为每种满足条件的组合均生成一个Map Join计划,同时还会保留原有的Common Join计划作为后备(back up)计划,实际运行时,优先执行Map Join计划,若不能执行成功,则启动Common Join后备计划。
set hive.mapjoin.smalltable.filesize=250000;--开启无条件转Map Join
set hive.auto.convert.join.noconditionaltask=true;--无条件转Map Join时的小表之和阈值,若一个Common Join operator相关的表中,存在n-1张表的大小总和<=该值,此时hive便不会再为每种n-1张表的组合均生成Map Join计划,同时也不会保留Common Join作为后备计划。而是只生成一个最优的Map Join计划。
set hive.auto.convert.join.noconditionaltask.size=10000000;
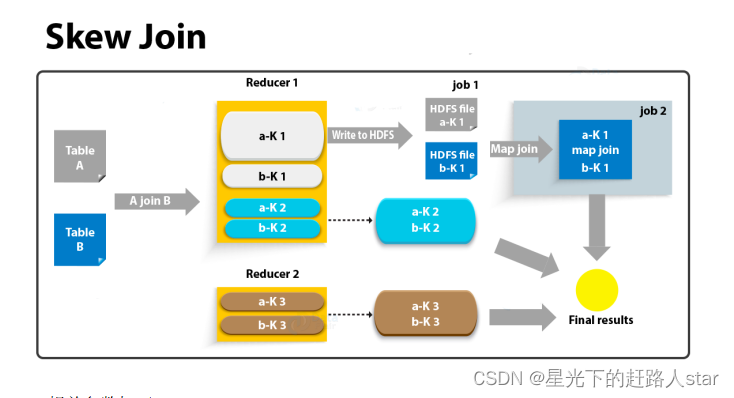
2、Skew join
skew join的原理是,为倾斜的大key单独启动一个map join任务进行计算,其余key进行正常的common join。原理图如下:
相关参数如下:
--启用skew join优化
set hive.optimize.skewjoin=true;
--触发skew join的阈值,若某个key的行数超过该参数值,则触发
set hive.skewjoin.key=100000;
这种方案对参与join的源表大小没有要求,但是对两表中倾斜的key的数据量有要求,要求一张表中的倾斜key的数据量比较小(方便走mapjoin)。
3、调整SQL语句
若参与join的两表均为大表,其中一张表的数据是倾斜的,此时也可通过以下方式对SQL语句进行相应的调整。
假设原始SQL语句如下:A,B两表均为大表,且其中一张表的数据是倾斜的。
select*
from A
join B
on A.id=B.id;
其join过程如下:
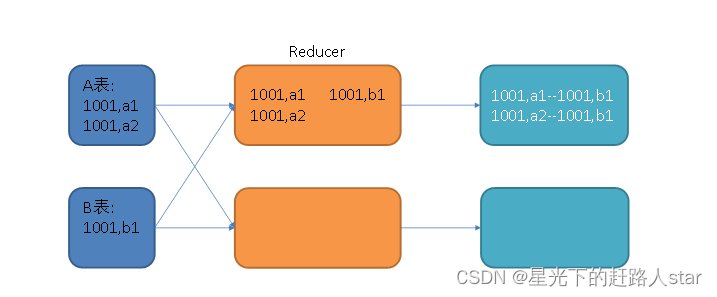
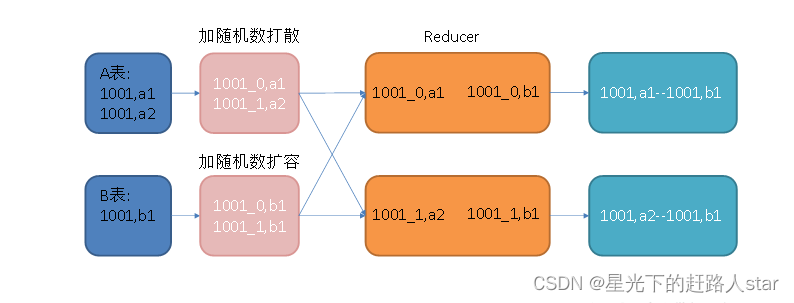
图中1001为倾斜的大key,可以看到,其被发往了同一个Reduce进行处理。
调整SQL语句如下:
select*
from(select --打散操作concat(id,'_',cast(rand()*2 as int)) id,valuefrom A
)ta
join(select --扩容操作concat(id,'_',0) id,valuefrom Bunion allselectconcat(id,'_',1) id,valuefrom B
)tb
on ta.id=tb.id;
调整之后的SQL语句执行计划如下图所示:
1.6 HQL语法优化任务并行度
优化说明:
对于一个分布式的计算任务而言,设置一个合适的并行度十分重要。Hive的计算任务由MapReduce完成,故并行度的调整需要分为Map端和Reduce端。
1.6.1 Map端并行度
Map端的并行度,也就是Map的个数。是由输入文件的切片数决定的。一般情况下,Map端的并行度无需手动调整。
以下特殊情况可考虑调整map端并行度:
1、查询的表中存在大量小文件
按照Hadoop默认的切片策略,一个小文件会单独启动一个map task负责计算。若查询的表中存在大量小文件,则会启动大量map task,造成计算资源的浪费。这种情况下,可以使用Hive提供的CombineHiveInputFormat,多个小文件合并为一个切片,从而控制map task个数。相关参数如下:
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
2、map端有复杂的查询逻辑
若SQL语句中有正则替换、json解析等复杂耗时的查询逻辑时,map端的计算会相对慢一些。若想加快计算速度,在计算资源充足的情况下,可考虑增大map端的并行度,令map task多一些,每个map task计算的数据少一些。相关参数如下:
--一个切片的最大值
set mapreduce.input.fileinputformat.split.maxsize=256000000;
1.6.2 Reduce端并行度
Reduce端的并行度,也就是Reduce个数。相对来说,更需要关注。Reduce端的并行度,可由用户自己指定,也可由Hive自行根据该MR Job输入的文件大小进行估算。
Reduce端的并行度的相关参数如下:
--指定Reduce端并行度,默认值为-1,表示用户未指定
set mapreduce.job.reduces;
--Reduce端并行度最大值
set hive.exec.reducers.max;
--单个Reduce Task计算的数据量,用于估算Reduce并行度
set hive.exec.reducers.bytes.per.reducer;
Reduce端并行度的确定逻辑如下:
若指定参数mapreduce.job.reduces的值为一个非负整数,则Reduce并行度为指定值。否则,Hive自行估算Reduce并行度,估算逻辑如下:
假设Job输入的文件大小为totalInputBytes
参数hive.exec.reducers.bytes.per.reducer的值为bytesPerReducer。
参数hive.exec.reducers.max的值为maxReducers。
则Reduce端的并行度为:
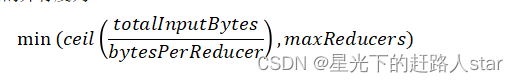
根据上述描述,可以看出,Hive自行估算Reduce并行度时,是以整个MR Job输入的文件大小作为依据的。因此,在某些情况下其估计的并行度很可能并不准确,此时就需要用户根据实际情况来指定Reduce并行度了。
1.7 HQL语法优化之小文件合并
优化说明:小文件合并优化,分为两个方面,分别是Map端输入的小文件合并,和Reduce端输出的小文件合并。
1.7.1 Map端输入文件合并
合并Map端输入的小文件,是指将多个小文件划分到一个切片中,进而由一个Map Task去处理。目的是防止为单个小文件启动一个Map Task,浪费计算资源。
相关参数:
--可将多个小文件切片,合并为一个切片,进而由一个map任务处理
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
1.7.2 Reduce端输出文件合并
合并Reduce端输出的小文件,是指将多个小文件合并成大文件。目的是减少HDFS小文件数量。其原理是根据计算任务输出文件的平均大小进行判断,若符合条件,则单独启动一个额外的任务进行合并。
相关参数:
--开启合并map only任务输出的小文件
set hive.merge.mapfiles=true;--开启合并map reduce任务输出的小文件
set hive.merge.mapredfiles=true;--合并后的文件大小
set hive.merge.size.per.task=256000000;--触发小文件合并任务的阈值,若某计算任务输出的文件平均大小低于该值,则触发合并
set hive.merge.smallfiles.avgsize=16000000;
1.8 HQL 语法优化之小文件合并
优化说明
小文件合并优化,分为两个方面,分别是Map端输入的小文件合并,和Reduce端输出的小文件合并。
1.8.1 Map端输入文件合并
合并Map端输入的小文件,是指将多个小文件划分到一个切片中,进而由一个Map Task去处理。目的是防止为单个小文件启动一个Map Task,浪费计算资源。
相关参数:
--可将多个小文件切片,合并为一个切片,进而由一个map任务处理
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; --底层逻辑是Hadoop的Combiner
1.8.2 Reduce输出文件合并
合并Reduce端输出的小文件,是指将多个小文件合并成大文件。目的是减少HDFS小文件数量。其原理是根据计算任务输出文件的平均大小进行判断,若符合条件,则单独启动一个额外的任务进行合并。
相关参数为:
--开启合并map only任务输出的小文件
set hive.merge.mapfiles=true;--开启合并map reduce任务输出的小文件
set hive.merge.mapredfiles=true;--合并后的文件大小
set hive.merge.size.per.task=256000000;--触发小文件合并任务的阈值,若某计算任务输出的文件平均大小低于该值,则触发合并
set hive.merge.smallfiles.avgsize=16000000;
1.9 其它优化
1.9.1 CBO优化
CBO是指Cost based Optimizer,即基于计算成本的优化。
在Hive中,计算成本模型考虑到了:数据的行数、CPU、本地IO、HDFS IO、网络IO等方面。Hive会计算同一SQL语句的不同执行计划的计算成本,并选出成本最低的执行计划。目前CBO在hive的MR引擎下主要用于join的优化,例如多表join的join顺序。
相关参数为:
--是否启用cbo优化
set hive.cbo.enable=true;
1.9.2 谓词下推
谓词下推(predicate pushdown)是指,尽量将过滤操作前移,以减少后续计算步骤的数据量。
相关参数:
--是否启动谓词下推(predicate pushdown)优化
set hive.optimize.ppd = true;
需要注意的是:
CBO优化也会完成一部分的谓词下推优化工作,因为在执行计划中,谓词越靠前,整个计划的计算成本就会越低。
1.9.3 矢量化查询
Hive的矢量化查询优化,依赖于CPU的矢量化计算,CPU的矢量化计算的基本原理如下图:
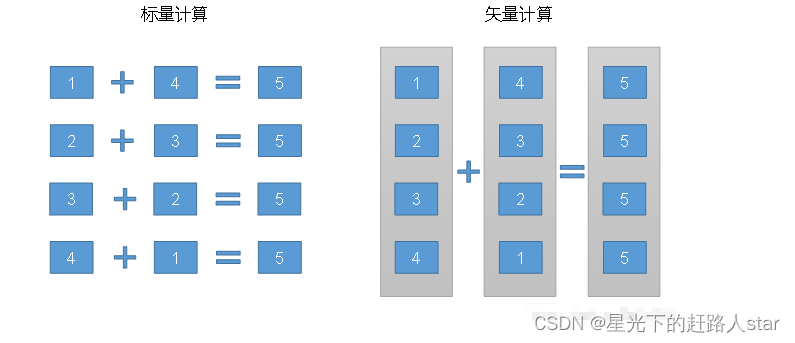
Hive的矢量化查询,可以极大的提高一些典型查询场景(例如scans, filters, aggregates, and joins)下的CPU使用效率。
相关参数如下:
set hive.vectorized.execution.enabled=true;
1.9.4 Fetch抓取
Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算。例如:select * from emp;在这种情况下,Hive可以简单地读取emp对应的存储目录下的文件,然后输出查询结果到控制台。
--是否在特定场景转换为fetch 任务
--设置为none表示不转换
--设置为minimal表示支持select *,分区字段过滤,Limit等
--设置为more表示支持select 任意字段,包括函数,过滤,和limit等
set hive.fetch.task.conversion=more;
1.9.5 本地模式
大多数的Hadoop Job是需要Hadoop提供的完整的可扩展性来处理大数据集的。不过,有时Hive的输入数据量是非常小的。在这种情况下,为查询触发执行任务消耗的时间可能会比实际job的执行时间要多的多。对于大多数这种情况,Hive可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。
相关参数如下:
--开启自动转换为本地模式
set hive.exec.mode.local.auto=true; --设置local MapReduce的最大输入数据量,当输入数据量小于这个值时采用local MapReduce的方式,默认为134217728,即128M
set hive.exec.mode.local.auto.inputbytes.max=50000000;--设置local MapReduce的最大输入文件个数,当输入文件个数小于这个值时采用local MapReduce的方式,默认为4
set hive.exec.mode.local.auto.input.files.max=10;
1.9.6 并行执行
Hive会将一个SQL语句转化成一个或者多个Stage,每个Stage对应一个MR Job。默认情况下,Hive同时只会执行一个Stage。但是某SQL语句可能会包含多个Stage,但这多个Stage可能并非完全互相依赖,也就是说有些Stage是可以并行执行的。此处提到的并行执行就是指这些Stage的并行执行。相关参数如下:
-启用并行执行优化
set hive.exec.parallel=true; --同一个sql允许最大并行度,默认为8
set hive.exec.parallel.thread.number=8;
1.9.7 严格模式
Hive可以通过设置某些参数防止危险操作:
1、分区表不使用分区过滤
将hive.strict.checks.no.partition.filter设置为true时,对于分区表,除非where语句中含有分区字段过滤条件来限制范围,否则不允许执行。换句话说,就是用户不允许扫描所有分区。进行这个限制的原因是,通常分区表都拥有非常大的数据集,而且数据增加迅速。没有进行分区限制的查询可能会消耗令人不可接受的巨大资源来处理这个表。
2、使用order by没有limit过滤
将hive.strict.checks.orderby.no.limit设置为true时,对于使用了order by语句的查询,要求必须使用limit语句。因为order by为了执行排序过程会将所有的结果数据分发到同一个Reduce中进行处理,强制要求用户增加这个limit语句可以防止Reduce额外执行很长一段时间(开启了limit可以在数据进入到Reduce之前就减少一部分数据)。
3、笛卡尔积
将hive.strict.checks.cartesian.product设置为true时,会限制笛卡尔积的查询。对关系型数据库非常了解的用户可能期望在执行JOIN查询的时候不使用ON语句而是使用where语句,这样关系数据库的执行优化器就可以高效地将WHERE语句转化成那个ON语句。不幸的是,Hive并不会执行这种优化,因此,如果表足够大,那么这个查询就会出现不可控的情况。

![[DesktopPicture]桌面图片](https://img2018.cnblogs.com/blog/1530634/201811/1530634-20181121185641097-861047351.jpg)