模型欠拟合:在训练集以及测试集上同时具有较⾼的误差,此时模型的偏差较⼤;
模型过拟合:在训练集上具有较低的误差,在测试集上具有较⾼的误差,此时模型的⽅差较⼤。
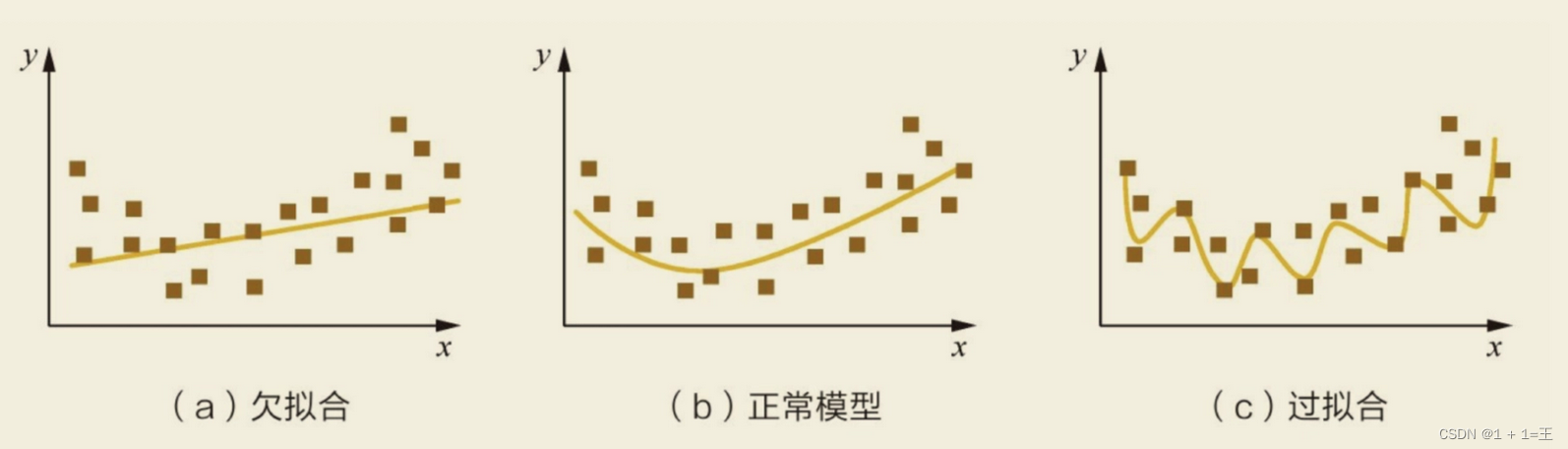
如何解决⽋拟合:
- 添加其他特征项。组合、泛化、相关性、上下⽂特征、平台特征等特征是特征添加的重要⼿段,有时候特征项不够会导致模型⽋拟合。
- 添加多项式特征。例如将线性模型添加⼆次项或三次项使模型泛化能⼒更强。增加了⼆阶多项式,保证了模型⼀定的拟合程度。
- 可以增加模型的复杂程度。
- 减⼩正则化系数。正则化的⽬的是⽤来防⽌过拟合的,但是现在模型出现了⽋拟合,则需要减少正则化参数。
如何解决过拟合:
- 重新清洗数据,数据不纯会导致过拟合,此类情况需要重新清洗数据。
- 增加训练样本数量。
- 降低模型复杂程度。
- 增⼤正则项系数。
- 采⽤dropout⽅法,dropout⽅法,通俗的讲就是在训练的时候让神经元以⼀定的概率不⼯作。
- 减少迭代次数。
- 增⼤学习率。
- 添加噪声数据。
- 树结构中,可以对树进⾏剪枝。
- 减少特征项。
k折交叉验证
- 将含有N个样本的数据集,分成K份,每份含有N/K个样本。选择其中1份作为测试集,另外K-1份作为训练集,测试集就有K种情况。
- 在每种情况中,⽤训练集训练模型,⽤测试集测试模型,计算模型的泛化误差。
- 交叉验证重复K次,每份验证⼀次,平均K次的结果或者使⽤其它结合⽅式,最终得到⼀个单⼀估测,得到模型最终的泛化误差。
- 将K种情况下,模型的泛化误差取均值,得到模型最终的泛化误差。
- ⼀般 。 k折交叉验证的优势在于,同时重复运⽤随机产⽣的⼦样本进⾏训练和验证,每次的结果验证⼀次,10折交叉验证是最常⽤的。
- 训练集中样本数量要⾜够多,⼀般⾄少⼤于总样本数的50%。
- 训练集和测试集必须从完整的数据集中均匀取样。均匀取样的⽬的是希望减少训练集、测试集与原数据集之间的偏差。当样本数量⾜够多时,通过随机取样,便可以实现均匀取样的效果。


![【Spring Cloud Alibaba】000-Spring Cloud Alibaba 问题集锦[持续更新]](/images/no-images.jpg)