GPT
GPT系列即基于Transformer Decoder实现的预训练语言模型,在各类复杂的NLP任务中都取得了不错的效果,如文章生成、代码生成、机器翻译,Q&A等。
对于一个新的任务,GPT仅仅需要非常少的数据便可以理解该任务,并达到或超过其他工作的效果。
GTP系列的模型结构秉承了不断堆叠transformer的思想,通过不断的提升训练语料的规模的质量,提升网络的参数数量,因此GPT模型的训练需要超大的训练预料,超多的参数和计算资源。

GPT-1:无监督学习
Improving Language Understanding by Generative Pre-Training
github:https://gluebenchmark.com/leaderboard
在GPT-1之前(和ELMo同一年),传统的NLP模型往往使用大量的数据对有监督的模型进行任务相关的模型训练,但是这种有监督学习的任务存在两个缺点
- 需要大量的标注数据,高质量的标注数据往往很难获得,因为在很多任务中,图像的标签并不是唯一的或者实例标签并不存在明确的边界;
- 根据一个任务训练的模型很难泛化到其它任务中,这个模型只能叫做“领域专家”而不是真正的理解了NLP;
根据一个任务训练的模型很难泛化到其它任务中,这个模型只能叫做“领域专家”而不是真正的理解了NLP
GPT-1的思想是先通过在无标签的数据上学习一个生成式的语言模型,然后再根据特定热任务进行微调,处理的有监督任务包括:
- 分类(Classification):判断输入文本类别
- 推理 (Entailment):判断两个句子之间的关系(包含、矛盾、中立)
- 相似度(Semantic Similarity):判断句子语义是否相关
- 问答和常理推理(Question answering and commonsense reasoning):类似多选题,一个文章,多个答案,预测每个答案的正确概率
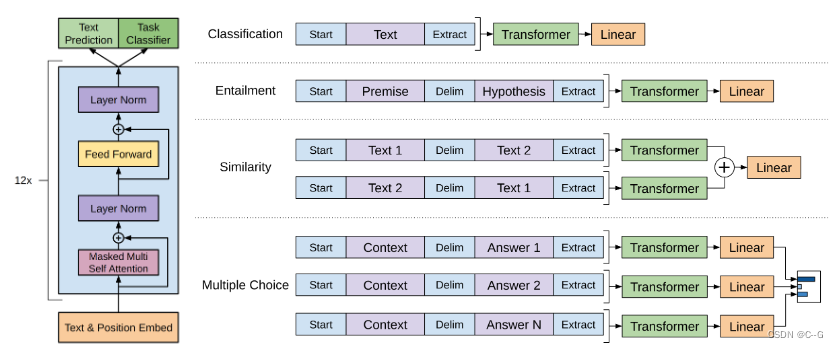
无监督预训练
GPT-1的无监督预训练是基于语言模型进行训练的,给定一个无标签的序列 ,语言模型的优化目标是最大化下面的似然值
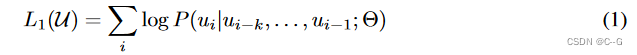
其中 K 是滑动窗口的大小,P 是条件概率, θ\thetaθ 是模型的参数。这些参数使用SGD进行优化。(Transformer Decoder训练方式,当前词只能依据前面的词推断,对后面的词是不知道的)
如上图所示,GPT-1使用了12个Transformer块作为Decoder,每个Transformer块是一个多头自注意力机制,通过全连接得到输出的概率分布。
Decoder流程公式如下:
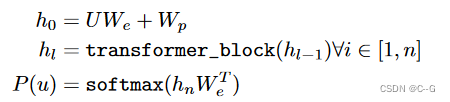
U=(Uk,...,U1)U=(U_k,...,U_1)U=(Uk,...,U1)是当前时间片的上下文token,n是层数,WeW_eWe是词嵌入矩阵,WpW_pWp是位置嵌入矩阵
有监督微调
经过无监督的预训练模型后,将模型直接应用到有监督的任务中。
有标签数据集C,每个实例有m个输入token:{X1,...,XmX^1,...,X^mX1,...,Xm},标签y。将token输入进模型,得到最终的特征向量 hlmh_l^mhlm,最后通过一个全连接层得到预测结果。
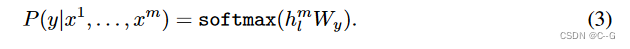
WyW_yWy为全连接层的参数。损失函数为:
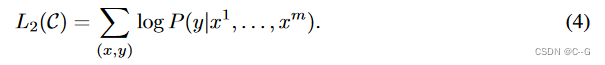
作者将无监督训练和有监督微调的损失结合在一起,通过 λ\lambdaλ 对损失分配权重,λ\lambdaλ 一般为0.5
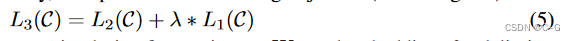
当进行有监督微调的时候,只训练输出层的WyW_yWy和分隔符(delimiter)的嵌入值
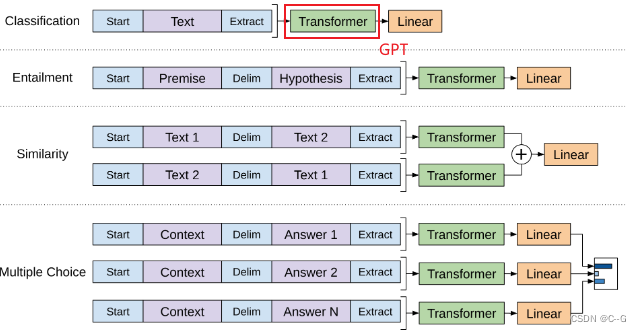
对不同任务的输入进行变换
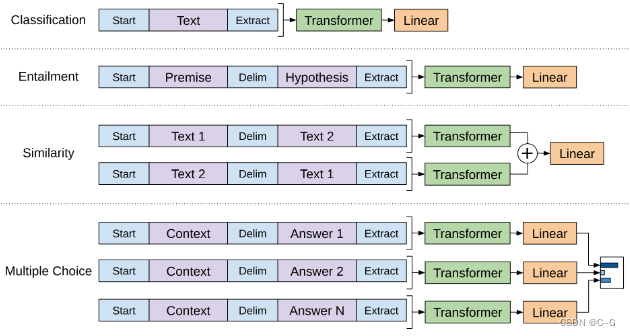
- 分类任务:将起始和终止token加入到原始序列两端,输入transformer中得到特征向量,最后经过一个全连接得到预测的概率分布;
- 自然语言推理:将前提(premise)和假设(hypothesis)通过分隔符(Delimiter)隔开,两端加上起始和终止token。再依次通过transformer和全连接得到预测结果;
- 语义相似度:输入的两个句子,正向和反向各拼接一次,然后分别输入给transformer,得到的特征向量拼接后再送给全连接得到预测结果
- 问答和常识推理:将 n 个选项的问题抽象化为 n 个二分类问题,即每个选项分别和内容进行拼接,然后各送入transformer和全连接中,最后选择置信度最高的作为预测结果。
实验
GPT-1 使用了BooksGorpus数据集,包含了 7,000本没有发布的书籍,该数据集拥有更长的上下文依赖关系,使得模型能学得更长期的依赖关系,并且这些书籍因为没有发布,所以很难在下游数据集上见到,更能验证模型的泛化能力
无监督训练
- 使用字节对编码(byte pair encoding,BPE),共有40,000个字节对
- 词编码的长度为768
- 位置编码也需要学习
- 12层的transformer,每个transformer块有12个头
- 位置编码的长度是 3,072
- Attention,残差,Dropout等机制用来进行正则化,drop的比例为:0.1
- 激活函数为GLEU
- 训练的batchsize为64,学习率为2.5e-4,序列长度为512,序列epoch为100
- 模型参数数量为1.17亿
有监督微调
- 无监督部分的模型也会用来微调
- 训练的epoch为3,学习率为6.25e-5,这表明模型在无监督部分学到了大量有用的特征
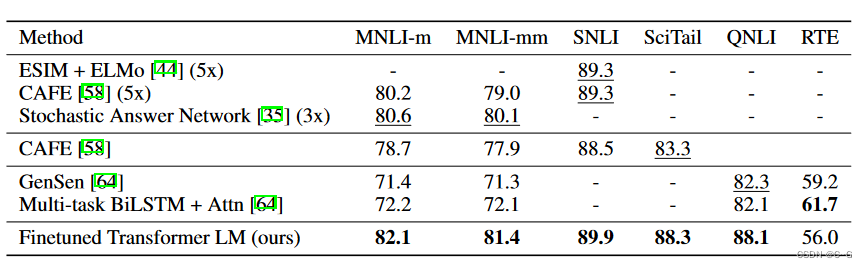
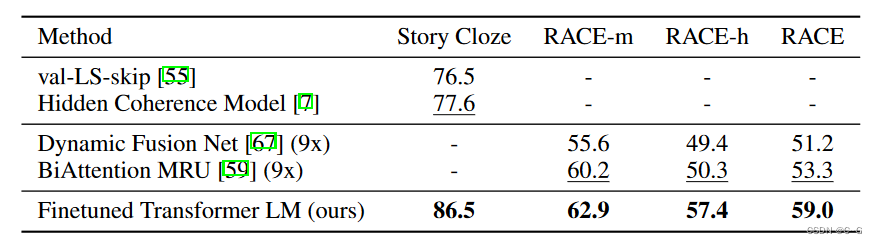
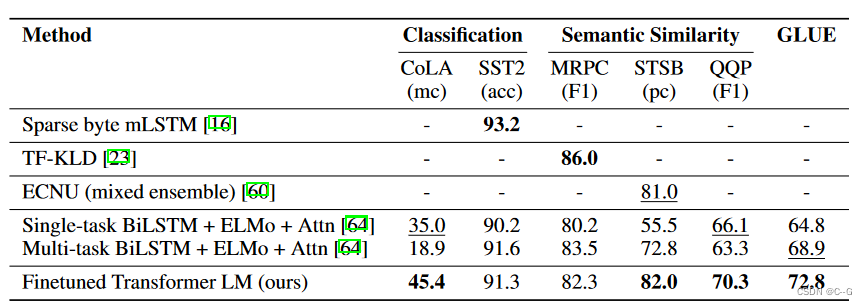
GPT-1在未经微调的任务上虽然也有一定效果,但是其泛化能力远远低于经过微调的有监督任务,说明了GPT-1只是一个简单的领域专家,而非通用的语言学家。
GPT-2:多任务学习
Language Models are Unsupervised Multitask Learners
随着模型层数的叠加,参数量随之增加,这时候对模型进行微调也需要消耗大量资源。GPT-2的目标旨在训练一个泛化能力更强的词向量模型,它并没有对GPT-1的网络进行过多的结构的创新与设计,只是使用了更多的网络参数和更大的数据集
核心思想
GPT-2的学习目标是使用无监督的预训练模型做有监督的任务。因为文本数据的时序性,一个输出序列可以表示为一系列条件概率的乘积
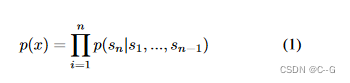
上式也可以表示为p(sn−k,...sn∣s1,s2,...,sn−k−1)p(s_{n-k},...s_n|s_1,s_2,...,s_{n-k-1})p(sn−k,...sn∣s1,s2,...,sn−k−1),实际意义是根据已知的上下文 input={s1,s2,...,sn−k−1}input = \{ s_1,s_2,...,s_{n-k-1} \}input={s1,s2,...,sn−k−1}预测未知的下文 output={sn−k,...,sk}output = \{ s_{n-k},...,s_k\}output={sn−k,...,sk},因此语言模型可以表示为 p(output∣input,task)p(output|input,task)p(output∣input,task)的形式,在decaNLP中,他们提出的MQAN模型可以将机器翻译,自然语言推理,语义分析,关系提取等10类任务统一建模为一个分类任务,而无需再为每一个子任务单独设计一个模型。
基于上面的思想,作者认为,当一个语言模型的容量足够大时,它就足以覆盖所有的有监督任务,也就是说所有的有监督学习都是无监督语言模型的一个子集。例如当模型训练完“Micheal Jordan is the best basketball player in the history”语料的语言模型之后,便也学会了(question:“who is the best basketball player in the history ?”,answer:“Micheal Jordan”)的Q&A任务。
综上,GPT-2的核心思想概括为:任何有监督任务都是语言模型的一个子集,当模型的容量非常大且数据量足够丰富时,仅仅靠训练语言模型的学习便可以完成其他有监督学习的任务。
数据集
GPT-2的文章取自于Reddit上高赞的文章,命名为WebText。数据集共有约800万篇文章,累计体积约40G。为了避免和测试集的冲突,WebText移除了涉及Wikipedia的文章。
实验
- 同样使用了使用字节对编码构建字典,字典的大小为 50,257
- 滑动窗口的大小为 1,024
- batchsize的大小为 512
- Layer Normalization移动到了每一块的输入部分,在每个self-attention之后额外添加了一个Layer Normalization;
- 将残差层的初始化值用 1/N1/\sqrt{N}1/N进行缩放,其中 N 是残差层的个数
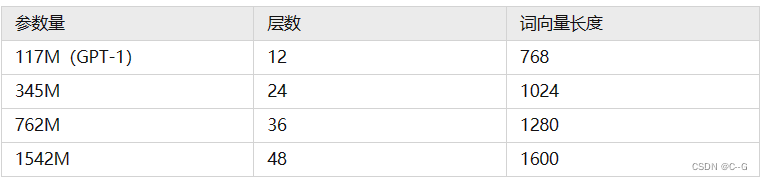
GPT-2训练了4组不同的层数和词向量的长度的模型,具体值见表2。通过这4个模型的实验结果我们可以看出随着模型的增大,模型的效果是不断提升的。
性能
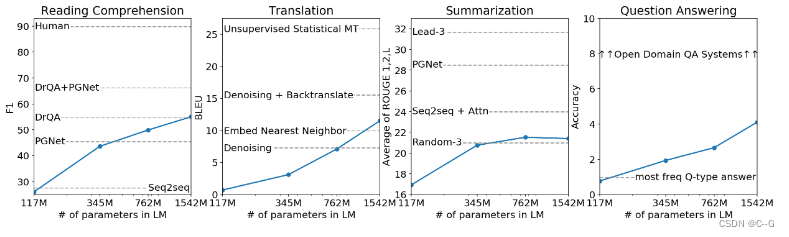
- 在8个语言模型任务中,仅仅通过zero-shot学习,GPT-2就有7个超过了state-of-the-art的方法;
- 在“Children’s Book Test”数据集上的命名实体识别任务中,GPT-2超过了state-of-the-art的方法约7%;
- “LAMBADA”是测试模型捕捉长期依赖的能力的数据集,GPT-2将困惑度从99.8降到了8.6;
- 在阅读理解数据中,GPT-2超过了4个baseline模型中的三个;
- 在法译英任务中,GPT-2在zero-shot学习的基础上,超过了大多数的无监督方法,但是比有监督的state-of-the-art模型要差;
- GPT-2在文本总结的表现不理想,但是它的效果也和有监督的模型非常接近。
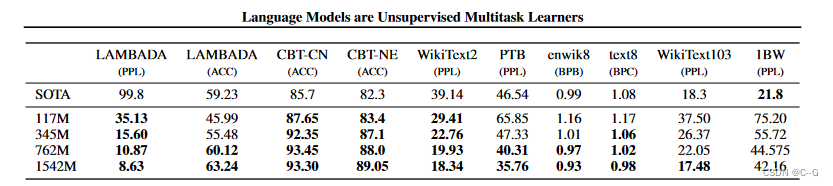
GPT-2的最大贡献是验证了通过海量数据和大量参数训练出来的词向量模型有迁移到其它类别任务中而不需要额外的训练。但是很多实验也表明,GPT-2的无监督学习的能力还有很大的提升空间,甚至在有些任务上的表现不比随机的好。尽管在有些zero-shot的任务上的表现不错,但是仍不清楚GPT-2的这种策略究竟能做成什么样子。GPT-2表明随着模型容量和数据量的增大,其潜能还有进一步开发的空间,基于这个思想,诞生了下面要介绍的GPT-3。
GPT-3:海量参数
Language Models are Few-Shot Learners
GPT-3仅仅需要zero-shot、one-shot或者few-shot,GPT-3就可以在下游任务表现的非常好。除了几个常见的NLP任务,GPT-3还在很多非常困难的任务上也有惊艳的表现,例如撰写人类难以判别的文章,甚至编写SQL查询语句,React或者JavaScript代码等。而这些强大能力的能力则依赖于GPT-3疯狂的 1,750亿的参数量, 45TB的训练数据以及高达 1,200万美元的训练费用
In-context learning
In-context learning是这篇论文中介绍的一个重要概念,要理解in-context learning,需要先理解meta-learning(元学习)。对于一个少样本的任务来说,模型的初始化值非常重要,从一个好的初始化值作为起点,模型能够尽快收敛,使得到的结果非常快的逼近全局最优解。元学习的核心思想在于通过少量的数据寻找一个合适的初始化范围,使得模型能够在有限的数据集上快速拟合,并获得不错的效果。
输入需求+(案例)+问题,模型的Attention机制在Prompt中找上下文信息,给出答案
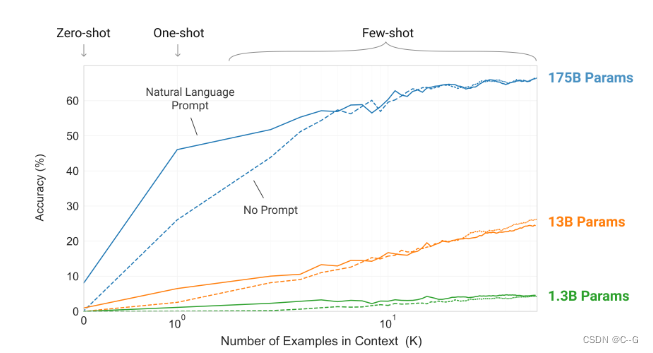
在few-shot learning中,提供若干个(10 - 100个)示例和任务描述供模型学习。one-shot laerning是提供1个示例和任务描述。zero-shot则是不提供示例,只是在测试时提供任务相关的具体描述。作者对这3种学习方式分别进行了实验,实验结果表明,三个学习方式的效果都会随着模型容量的上升而上升,且few shot > one shot > zero show。

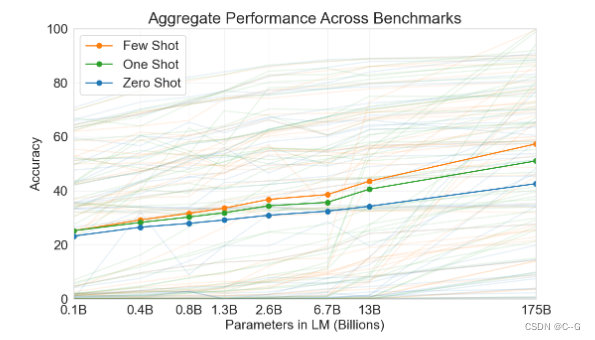
从理论上讲GPT-3也是支持fine-tuning的,但是fine-tuning需要利用海量的标注数据进行训练才能获得比较好的效果,但是这样也会造成对其它未训练过的任务上表现差,所以GPT-3并没有尝试fine-tuning。
实验
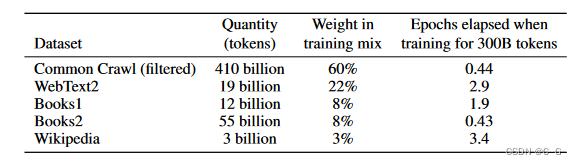
GPT-3共训练了5个不同的语料,分别是低质量的Common Crawl,高质量的WebText2,Books1,Books2和Wikipedia,GPT-3根据数据集的不同的质量赋予了不同的权值,权值越高的在训练的时候越容易抽样到。
模型结构
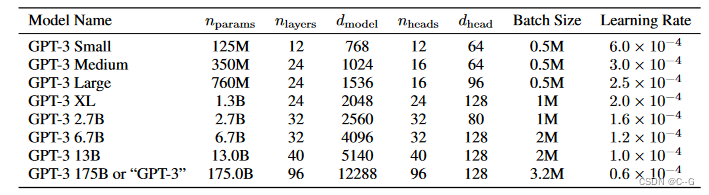
使用了alternating dense和locally banded sparse attention。
仅仅用惊艳很难描述GPT-3的优秀表现。首先,在大量的语言模型数据集中,GPT-3超过了绝大多数的zero-shot或者few-shot的state-of-the-art方法。另外GPT-3在很多复杂的NLP任务中也超过了fine-tune之后的state-of-the-art方法,例如闭卷问答,模式解析,机器翻译等。除了这些传统的NLP任务,GPT-3在一些其他的领域也取得了非常震惊的效果,例如进行数学加法,文章生成,编写代码等。
总结
GPT系列从1到3,通通采用的是transformer架构,可以说模型结构并没有创新性的设计。在微软的资金支持下,这更像是一场赤裸裸的炫富:1750亿的参数,31个分工明确的作者,超强算力的计算机(285,000 个CPU, 10,000个GPU),1200万的训练费用,45TB的训练数据(维基百科的全部数据只相当于其中的 0.6%)。这种规模的模型是一般中小企业无法承受的,而个人花费巨金配置的单卡机器也就只能做做微调或者打打游戏了。甚至在训练GPT-3时出现了一个bug,OpenAI自己也没有资金重新训练了。
读懂了GPT-3的原理,相信我们就能客观的看待媒体上对GPT-3的过分神话了。GPT-3的本质还是通过海量的参数学习海量的数据,然后依赖transformer强大的拟合能力使得模型能够收敛。基于这个原因,GPT-3学到的模型分布也很难摆脱这个数据集的分布情况。得益于庞大的数据集,GPT-3可以完成一些令人感到惊喜的任务,但是GPT-3也不是万能的,对于一些明显不在这个分布或者和这个分布有冲突的任务来说,GPT-3还是无能为力的。例如通过目前的测试来看,GPT-3还有很多缺点的:
- 对于一些命题没有意义的问题,GPT-3不会判断命题有效与否,而是拟合一个没有意义的答案出来;
- 由于40TB海量数据的存在,很难保证GPT-3生成的文章不包含一些非常敏感的内容,例如种族歧视,性别歧视,宗教偏见等;
- 受限于transformer的建模能力,GPT-3并不能保证生成的一篇长文章或者一本书籍的连贯性,存在下文不停重复上文的问题。
参考于:https://zhuanlan.zhihu.com/p/350017443


![python 绘图 —— 绘制从顶部向底部显示的柱形图[ax.bar()]](https://img-blog.csdnimg.cn/3d3c6907642c4d3d9267b9b4987d8aff.png)