验证码是根据随机字符生成一幅图片,然后在图片中加入干扰象素,用户必须手动填入,防止有人利用机器人自动批量注册、灌水、发垃圾广告等等 。
验证码的作用是验证用户是真人还是机器人;设计理念是对人友好,对机器难。
![]()
上图是常见的字符验证码,还有一些验证码使用提问的方式。
我们先来看看破解验证码的几种方式:
- 人力打码(基本上,打码任务都是大型网站的验证码,用于自动化注册等等)
- 找到能过验证码的漏洞
- 最后一种是字符识别,这是本帖的关注点
我上网查了查,用Tesseract OCR、OpenCV等等其它方法都需把验证码分割为单个字符,然后识别单个字符。分割验证码可是人的强项,如果字符之间相互重叠,那机器就不容易分割了。
本帖实现的方法不需要分割验证码,而是把验证码做为一个整体进行识别。
相关论文:
- Multi-digit Number Recognition from Street View Imagery using Deep CNN
- CAPTCHA Recognition with Active Deep Learning
- http://matthewearl.github.io/2016/05/06/cnn-anpr/
使用深度学习+训练数据+大量计算力,我们可以在几天内训练一个可以破解验证码的模型,当然前提是获得大量训练数据。
获得训练数据方法:
- 手动(累死人系列)
- 破解验证码生成机制,自动生成无限多的训练数据
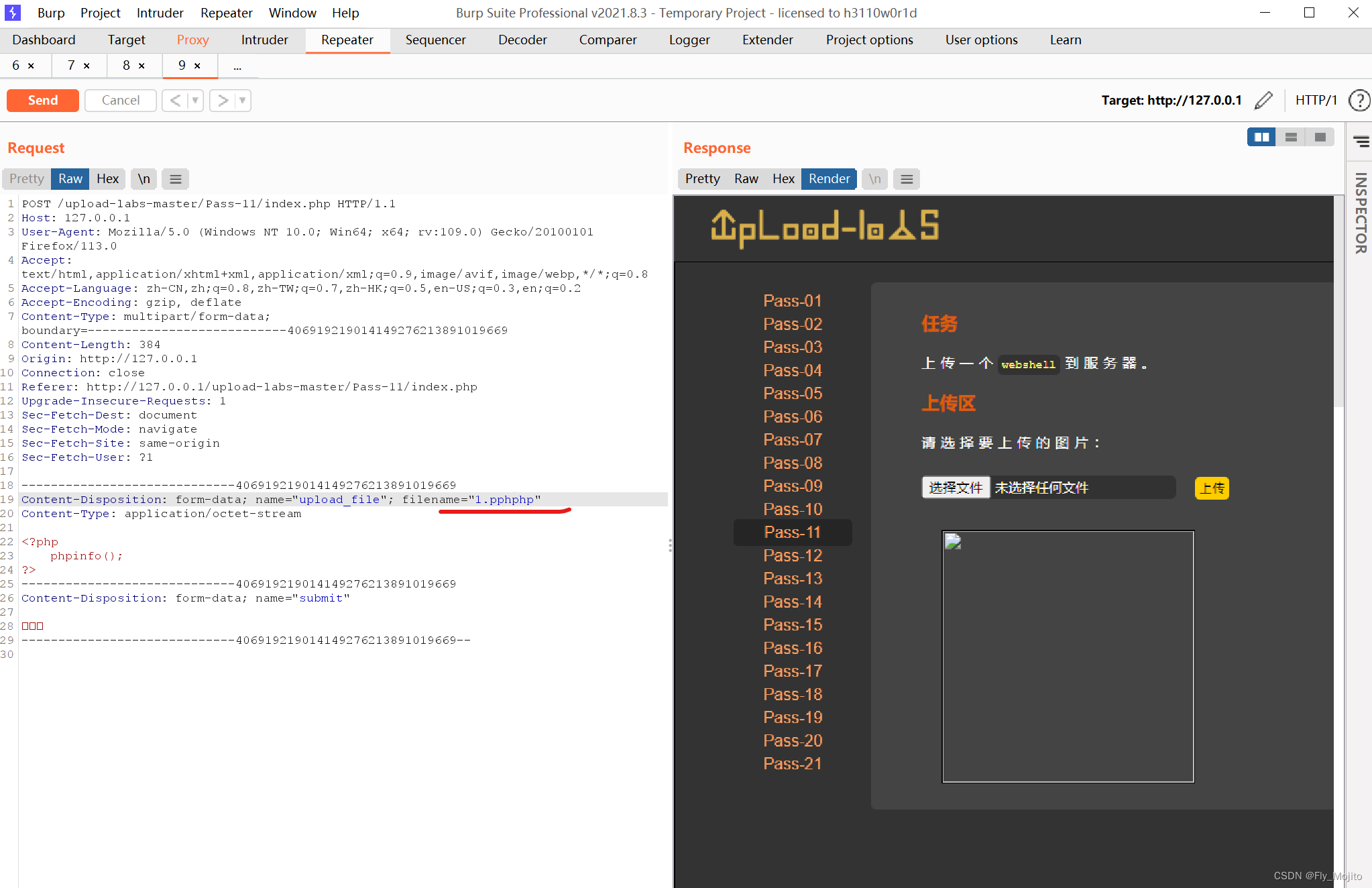
- 打入敌人内部(卧底+不要脸+不要命+多大仇系列)
我自己做一个验证码生成器,然后训练CNN模型破解自己做的验证码生成器。
我觉的验证码机制可以废了,单纯的增加验证码难度只会让人更难识别,使用CNN+RNN,机器的识别准确率不比人差。Google已经意识到了这一点,他们现在使用机器学习技术检测异常流量。
验证码生成器
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | from captcha . image import ImageCaptcha # pip install captcha import numpy as np import matplotlib . pyplot as plt from PIL import Image import random # 验证码中的字符, 就不用汉字了 number = [ '0' , '1' , '2' , '3' , '4' , '5' , '6' , '7' , '8' , '9' ] alphabet = [ 'a' , 'b' , 'c' , 'd' , 'e' , 'f' , 'g' , 'h' , 'i' , 'j' , 'k' , 'l' , 'm' , 'n' , 'o' , 'p' , 'q' , 'r' , 's' , 't' , 'u' , 'v' , 'w' , 'x' , 'y' , 'z' ] ALPHABET = [ 'A' , 'B' , 'C' , 'D' , 'E' , 'F' , 'G' , 'H' , 'I' , 'J' , 'K' , 'L' , 'M' , 'N' , 'O' , 'P' , 'Q' , 'R' , 'S' , 'T' , 'U' , 'V' , 'W' , 'X' , 'Y' , 'Z' ] # 验证码一般都无视大小写;验证码长度4个字符 def random_captcha_text ( char_set = number + alphabet + ALPHABET , captcha_size = 4 ) : captcha_text = [ ] for i in range ( captcha_size ) : c = random . choice ( char_set ) captcha_text . append ( c ) return captcha_text # 生成字符对应的验证码 def gen_captcha_text_and_image ( ) : image = ImageCaptcha ( ) captcha_text = random_captcha_text ( ) captcha_text = '' . join ( captcha_text ) captcha = image . generate ( captcha_text ) #image.write(captcha_text, captcha_text + '.jpg') # 写到文件 captcha_image = Image . open ( captcha ) captcha_image = np . array ( captcha_image ) return captcha_text , captcha_image if __name__ == '__main__' : # 测试 text , image = gen_captcha_text_and_image ( ) f = plt . figure ( ) ax = f . add_subplot ( 111 ) ax . text ( 0.1 , 0.9 , text , ha = 'center' , va = 'center' , transform = ax . transAxes ) plt . imshow ( image ) plt . show ( ) |


训练
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 | from gen_captcha import gen_captcha_text_and_image from gen_captcha import number from gen_captcha import alphabet from gen_captcha import ALPHABET import numpy as np import tensorflow as tf text , image = gen_captcha_text_and_image ( ) print ( "验证码图像channel:" , image . shape ) # (60, 160, 3) # 图像大小 IMAGE_HEIGHT = 60 IMAGE_WIDTH = 160 MAX_CAPTCHA = len ( text ) print ( "验证码文本最长字符数" , MAX_CAPTCHA ) # 验证码最长4字符; 我全部固定为4,可以不固定. 如果验证码长度小于4,用'_'补齐 # 把彩色图像转为灰度图像(色彩对识别验证码没有什么用) def convert2gray ( img ) : if len ( img . shape ) > 2 : gray = np . mean ( img , - 1 ) # 上面的转法较快,正规转法如下 # r, g, b = img[:,:,0], img[:,:,1], img[:,:,2] # gray = 0.2989 * r + 0.5870 * g + 0.1140 * b return gray else : return img """ cnn在图像大小是2的倍数时性能最高, 如果你用的图像大小不是2的倍数,可以在图像边缘补无用像素。 np.pad(image,((2,3),(2,2)), 'constant', constant_values=(255,)) # 在图像上补2行,下补3行,左补2行,右补2行 """ # 文本转向量 char_set = number + alphabet + ALPHABET + [ '_' ] # 如果验证码长度小于4, '_'用来补齐 CHAR_SET_LEN = len ( char_set ) def text2vec ( text ) : text_len = len ( text ) if text_len > MAX_CAPTCHA : raise ValueError ( '验证码最长4个字符' ) vector = np . zeros ( MAX_CAPTCHA * CHAR_SET_LEN ) def char2pos ( c ) : if c == '_' : k = 62 return k k = ord ( c ) - 48 if k > 9 : k = ord ( c ) - 55 if k > 35 : k = ord ( c ) - 61 if k > 61 : raise ValueError ( 'No Map' ) return k for i , c in enumerate ( text ) : idx = i * CHAR_SET_LEN + char2pos ( c ) vector [ idx ] = 1 return vector # 向量转回文本 def vec2text ( vec ) : char_pos = vec . nonzero ( ) [ 0 ] text = [ ] for i , c in enumerate ( char_pos ) : char_at_pos = i #c/63 char_idx = c % CHAR_SET_LEN if char_idx < 10 : char_code = char_idx + ord ( '0' ) elif char_idx < 36 : char_code = char_idx - 10 + ord ( 'A' ) elif char_idx < 62 : char_code = char_idx - 36 + ord ( 'a' ) elif char_idx == 62 : char_code = ord ( '_' ) else : raise ValueError ( 'error' ) text . append ( chr ( char_code ) ) return "" . join ( text ) """ #向量(大小MAX_CAPTCHA*CHAR_SET_LEN)用0,1编码 每63个编码一个字符,这样顺利有,字符也有 vec = text2vec("F5Sd") text = vec2text(vec) print(text) # F5Sd vec = text2vec("SFd5") text = vec2text(vec) print(text) # SFd5 """ # 生成一个训练batch def get_next_batch ( batch_size = 128 ) : batch_x = np . zeros ( [ batch_size , IMAGE_HEIGHT * IMAGE_WIDTH ] ) batch_y = np . zeros ( [ batch_size , MAX_CAPTCHA * CHAR_SET_LEN ] ) # 有时生成图像大小不是(60, 160, 3) def wrap_gen_captcha_text_and_image ( ) : while True : text , image = gen_captcha_text_and_image ( ) if image . shape == ( 60 , 160 , 3 ) : return text , image for i in range ( batch_size ) : text , image = wrap_gen_captcha_text_and_image ( ) image = convert2gray ( image ) batch_x [ i , : ] = image . flatten ( ) / 255 # (image.flatten()-128)/128 mean为0 batch_y [ i , : ] = text2vec ( text ) return batch_x , batch_y #################################################################### X = tf . placeholder ( tf . float32 , [ None , IMAGE_HEIGHT * IMAGE_WIDTH ] ) Y = tf . placeholder ( tf . float32 , [ None , MAX_CAPTCHA * CHAR_SET_LEN ] ) keep_prob = tf . placeholder ( tf . float32 ) # dropout # 定义CNN def crack_captcha_cnn ( w_alpha = 0.01 , b_alpha = 0.1 ) : x = tf . reshape ( X , shape = [ - 1 , IMAGE_HEIGHT , IMAGE_WIDTH , 1 ] ) #w_c1_alpha = np.sqrt(2.0/(IMAGE_HEIGHT*IMAGE_WIDTH)) # #w_c2_alpha = np.sqrt(2.0/(3*3*32)) #w_c3_alpha = np.sqrt(2.0/(3*3*64)) #w_d1_alpha = np.sqrt(2.0/(8*32*64)) #out_alpha = np.sqrt(2.0/1024) # 3 conv layer w_c1 = tf . Variable ( w_alpha * tf . random_normal ( [ 3 , 3 , 1 , 32 ] ) ) b_c1 = tf . Variable ( b_alpha * tf . random_normal ( [ 32 ] ) ) conv1 = tf . nn . relu ( tf . nn . bias_add ( tf . nn . conv2d ( x , w_c1 , strides = [ 1 , 1 , 1 , 1 ] , padding = 'SAME' ) , b_c1 ) ) conv1 = tf . nn . max_pool ( conv1 , ksize = [ 1 , 2 , 2 , 1 ] , strides = [ 1 , 2 , 2 , 1 ] , padding = 'SAME' ) conv1 = tf . nn . dropout ( conv1 , keep_prob ) w_c2 = tf . Variable ( w_alpha * tf . random_normal ( [ 3 , 3 , 32 , 64 ] ) ) b_c2 = tf . Variable ( b_alpha * tf . random_normal ( [ 64 ] ) ) conv2 = tf . nn . relu ( tf . nn . bias_add ( tf . nn . conv2d ( conv1 , w_c2 , strides = [ 1 , 1 , 1 , 1 ] , padding = 'SAME' ) , b_c2 ) ) conv2 = tf . nn . max_pool ( conv2 , ksize = [ 1 , 2 , 2 , 1 ] , strides = [ 1 , 2 , 2 , 1 ] , padding = 'SAME' ) conv2 = tf . nn . dropout ( conv2 , keep_prob ) w_c3 = tf . Variable ( w_alpha * tf . random_normal ( [ 3 , 3 , 64 , 64 ] ) ) b_c3 = tf . Variable ( b_alpha * tf . random_normal ( [ 64 ] ) ) conv3 = tf . nn . relu ( tf . nn . bias_add ( tf . nn . conv2d ( conv2 , w_c3 , strides = [ 1 , 1 , 1 , 1 ] , padding = 'SAME' ) , b_c3 ) ) conv3 = tf . nn . max_pool ( conv3 , ksize = [ 1 , 2 , 2 , 1 ] , strides = [ 1 , 2 , 2 , 1 ] , padding = 'SAME' ) conv3 = tf . nn . dropout ( conv3 , keep_prob ) # Fully connected layer w_d = tf . Variable ( w_alpha * tf . random_normal ( [ 8 * 20 * 64 , 1024 ] ) ) b_d = tf . Variable ( b_alpha * tf . random_normal ( [ 1024 ] ) ) dense = tf . reshape ( conv3 , [ - 1 , w_d . get_shape ( ) . as_list ( ) [ 0 ] ] ) dense = tf . nn . relu ( tf . add ( tf . matmul ( dense , w_d ) , b_d ) ) dense = tf . nn . dropout ( dense , keep_prob ) w_out = tf . Variable ( w_alpha * tf . random_normal ( [ 1024 , MAX_CAPTCHA * CHAR_SET_LEN ] ) ) b_out = tf . Variable ( b_alpha * tf . random_normal ( [ MAX_CAPTCHA * CHAR_SET_LEN ] ) ) out = tf . add ( tf . matmul ( dense , w_out ) , b_out ) #out = tf.nn.softmax(out) return out # 训练 def train_crack_captcha_cnn ( ) : output = crack_captcha_cnn ( ) # loss #loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(output, Y)) loss = tf . reduce_mean ( tf . nn . sigmoid_cross_entropy_with_logits ( logits = output , labels = Y ) ) # 最后一层用来分类的softmax和sigmoid有什么不同? # optimizer 为了加快训练 learning_rate应该开始大,然后慢慢衰 optimizer = tf . train . AdamOptimizer ( learning_rate = 0.001 ) . minimize ( loss ) predict = tf . reshape ( output , [ - 1 , MAX_CAPTCHA , CHAR_SET_LEN ] ) max_idx_p = tf . argmax ( predict , 2 ) max_idx_l = tf . argmax ( tf . reshape ( Y , [ - 1 , MAX_CAPTCHA , CHAR_SET_LEN ] ) , 2 ) correct_pred = tf . equal ( max_idx_p , max_idx_l ) accuracy = tf . reduce_mean ( tf . cast ( correct_pred , tf . float32 ) ) saver = tf . train . Saver ( ) with tf . Session ( ) as sess : sess . run ( tf . global_variables_initializer ( ) ) step = 0 while True : batch_x , batch_y = get_next_batch ( 64 ) _ , loss_ = sess . run ( [ optimizer , loss ] , feed_dict = { X : batch_x , Y : batch_y , keep_prob : 0.75 } ) print ( step , loss_ ) # 每100 step计算一次准确率 if step % 100 == 0 : batch_x_test , batch_y_test = get_next_batch ( 100 ) acc = sess . run ( accuracy , feed_dict = { X : batch_x_test , Y : batch_y_test , keep_prob : 1. } ) print ( step , acc ) # 如果准确率大于50%,保存模型,完成训练 if acc > 0.5 : saver . save ( sess , "crack_capcha.model" , global_step = step ) break step += 1 train_crack_captcha_cnn ( ) |
CNN需要大量的样本进行训练,由于时间和资源有限,测试时我只使用数字做为验证码字符集。如果使用数字+大小写字母CNN网络有4*62个输出,只使用数字CNN网络有4*10个输出。
TensorBoard是个好东西,既能用来调试也能帮助理解Graph。
训练完成时的准确率(超过50%我就不训练了):
![]()
使用训练的模型识别验证码:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | def crack_captcha ( captcha_image ) : output = crack_captcha_cnn ( ) saver = tf . train . Saver ( ) with tf . Session ( ) as sess : saver . restore ( sess , tf . train . latest_checkpoint ( '.' ) ) predict = tf . argmax ( tf . reshape ( output , [ - 1 , MAX_CAPTCHA , CHAR_SET_LEN ] ) , 2 ) text_list = sess . run ( predict , feed_dict = { X : [ captcha_image ] , keep_prob : 1 } ) text = text_list [ 0 ] . tolist ( ) vector = np . zeros ( MAX_CAPTCHA * CHAR_SET_LEN ) i = 0 for n in text : vector [ i * CHAR_SET_LEN + n ] = 1 i += 1 return vec2text ( vector ) text , image = gen_captcha_text_and_image ( ) image = convert2gray ( image ) image = image . flatten ( ) / 255 predict_text = crack_captcha ( image ) print ( "正确: {} 预测: {}" . format ( text , predict_text ) ) |

loss和准确率曲线:


为了成为真正的码农,本熊猫要开始研习TensorFlow源代码了,应该能学到不少玩意。
如要转载,请保持本文完整,并注明作者@斗大的熊猫和本文原始地址: http://blog.topspeedsnail.com/archives/10858