手把手+零基础带你玩转大数据流式处理引擎Flink(有状态的流式处理)
- 传统批处理
- 批处理的特点
- 批处理执行原理
- 理想方法
- 流式处理
- 分布式流式处理
- 有状态分布式流式处理
- 有状态分散式流式处理
- 总结分析
传统批处理
传统批处理数据是指一种数据处理方式,它通过将数据分成批次,逐一处理每个批次中的数据,以达到数据处理的目的。传统批处理数据通常使用批处理作业来完成,这些作业由一系列的命令和程序组成,这些命令和程序会按照一定的顺序依次执行,以完成特定的数据处理任务。
传统批处理数据通常适用于处理大量的数据,这些数据需要进行复杂的计算和分析,例如财务数据、人口统计数据等。由于批处理数据可以在非工作时间进行处理,因此可以有效地减少系统负载和运行成本,提高数据处理的效率和精度。
批处理的特点
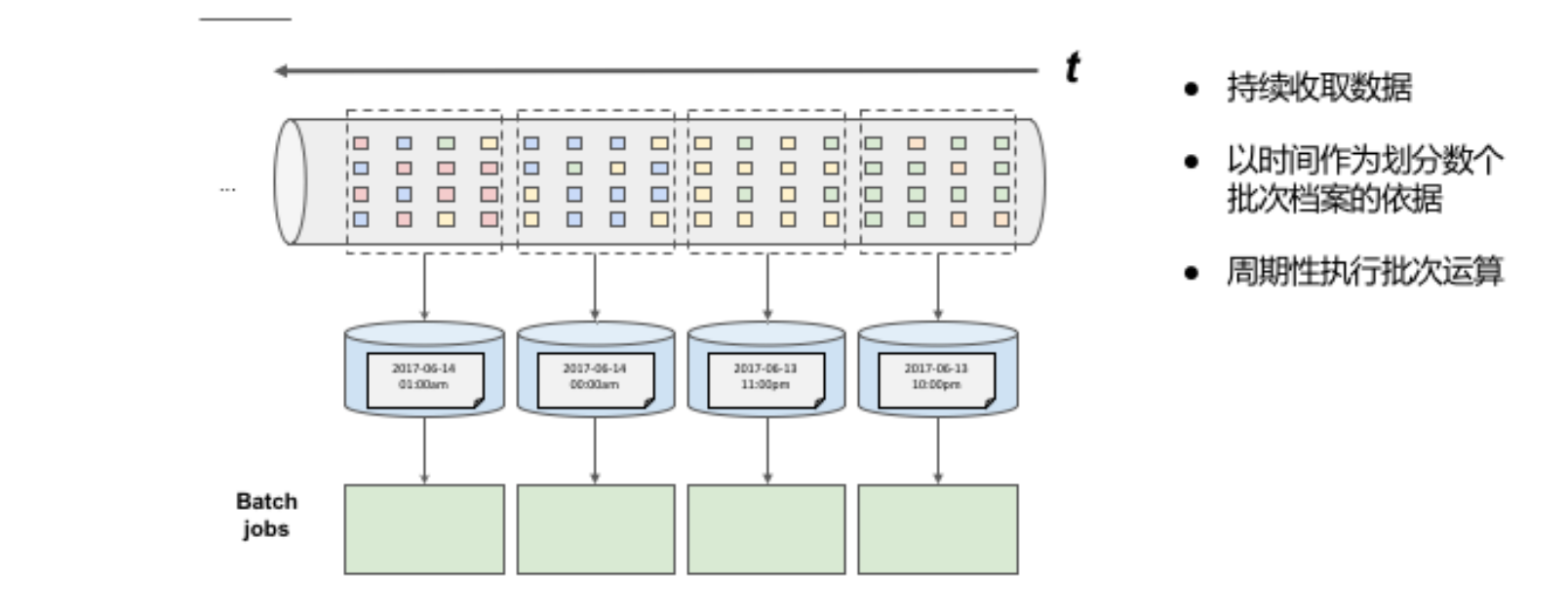
- 持续收集数据
- 根据时间将数据分成若干批次档案
- 定期执行批次运算
批处理执行原理
传统批处理方法是持续收取数据,以时间作为划分多个批次的依据,再周期性地执行批次运算。但假设需要计算每小时出现事件转换的次数,如果事件转换跨越了所定义的时间划分,传统批处理会将中介运算结果带到下一个批次进行计算;除此之外,当出现接收到的事件顺序颠倒情况下,传统批处理仍会将中介状态带到下一批次的运算结果中,这种处理方式也不尽如人意。
理想方法
-
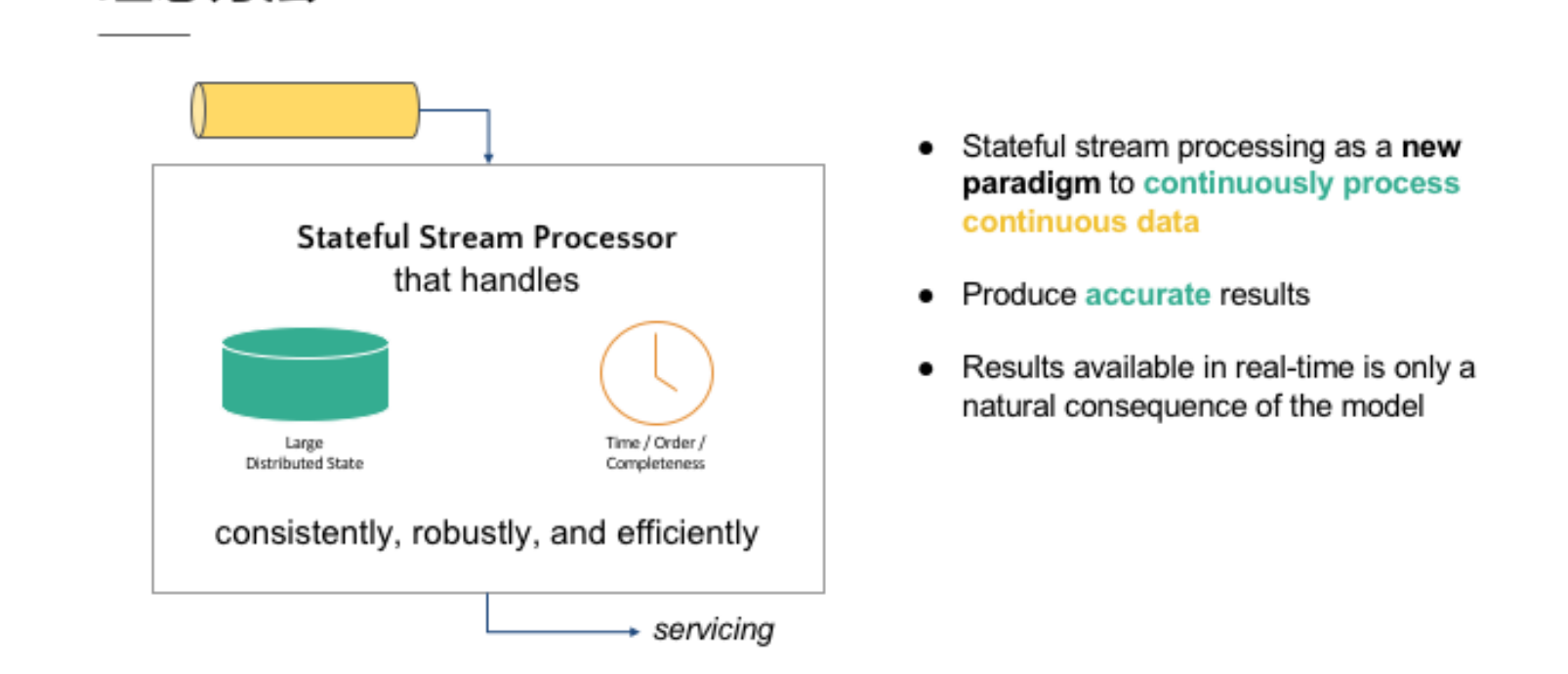
有状态流处理作为一个新的持续处理的范例连续的数据
-
产生准确的结果
-
实时可用的结果只有一个模型的自然结果
-
首先,该方法需要具备状态累积和维护的能力,以便维护过去历史中接收到的所有事件,从而影响输出结果。这可以通过使用流式处理引擎来实现,这种引擎可以在处理过程中维护状态,而不是将状态保存在批处理中。
-
其次,该方法需要具备时间控制机制,以确保数据的完整性。当所有数据都完全接收到后,输出计算结果。这可以通过在流式处理引擎中设置时间窗口来实现,时间窗口可以控制在多长时间内接收数据。
-
最后,该方法需要能够实时产生结果,并采用新的持续性数据处理模型来处理实时数据,以最大程度地符合 continuous data 的特性。这可以通过使用实时流处理引擎来实现,这种引擎可以在处理数据时实时产生结果,而不是等待一段时间再进行批处理。
流式处理
流式处理通常用于需要实时响应数据的应用程序,例如实时监控、实时分析和实时报警等。流式处理通常具有以下特点:
- 连续不断地处理数据流,而不是一次性处理所有数据。
- 以事件驱动的方式进行处理,即在数据到达时立即处理。
- 可以在处理数据时动态调整处理逻辑,例如添加新的规则或过滤器。
- 可以处理无限流数据,即数据源不会停止产生数据。
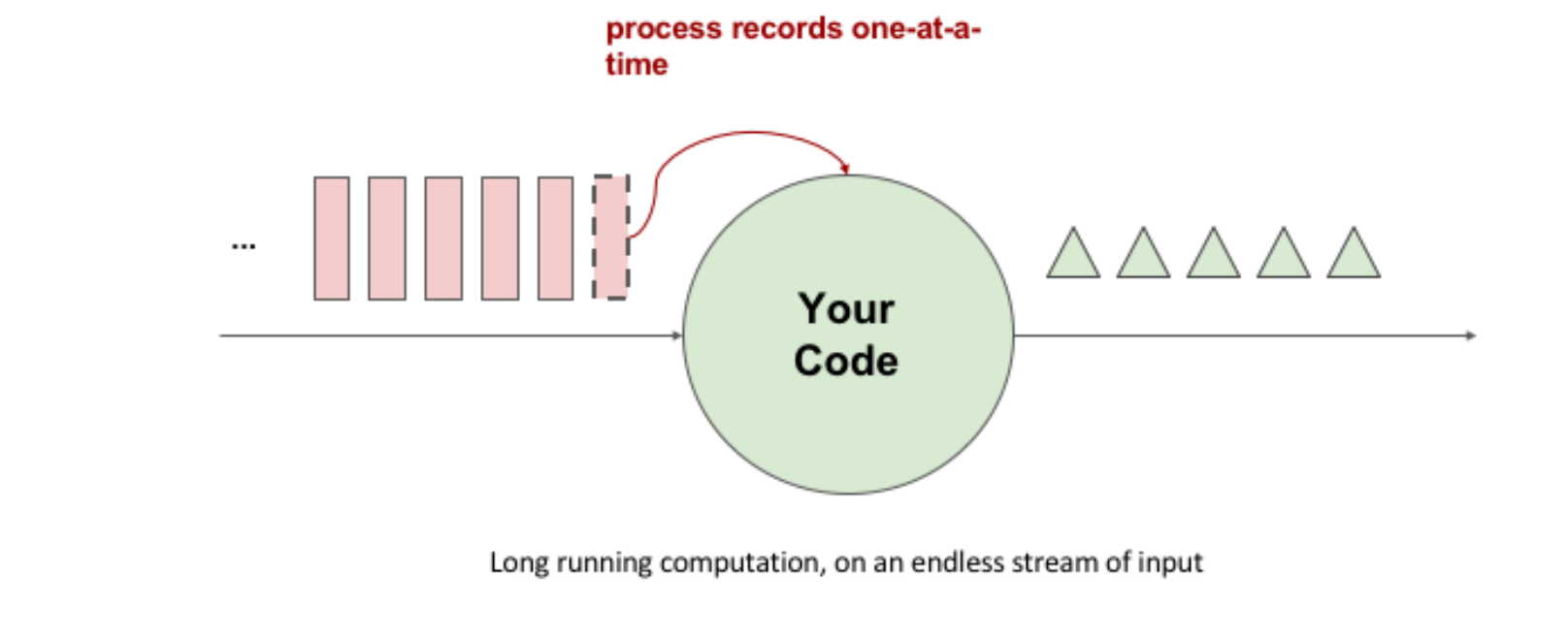
流式处理简单来说是指有一个持续不断的数据源不断地收集数据,数据经过代码处理后即时产生结果,并输出。这种处理方式的基本原理是使用代码作为数据处理的基础逻辑,将数据源中的数据流式地传输到处理引擎中,处理引擎会对数据进行实时处理,并输出结果。与批处理不同,流式处理不需要等待所有数据都被收集完毕后再进行处理,而是可以在数据源不断产生数据的同时进行处理。这种处理方式可以使数据处理更加实时、高效,并且可以应用于需要持续监测和处理数据的场景,如实时监测交通流量、实时监测天气数据等。
分布式流式处理
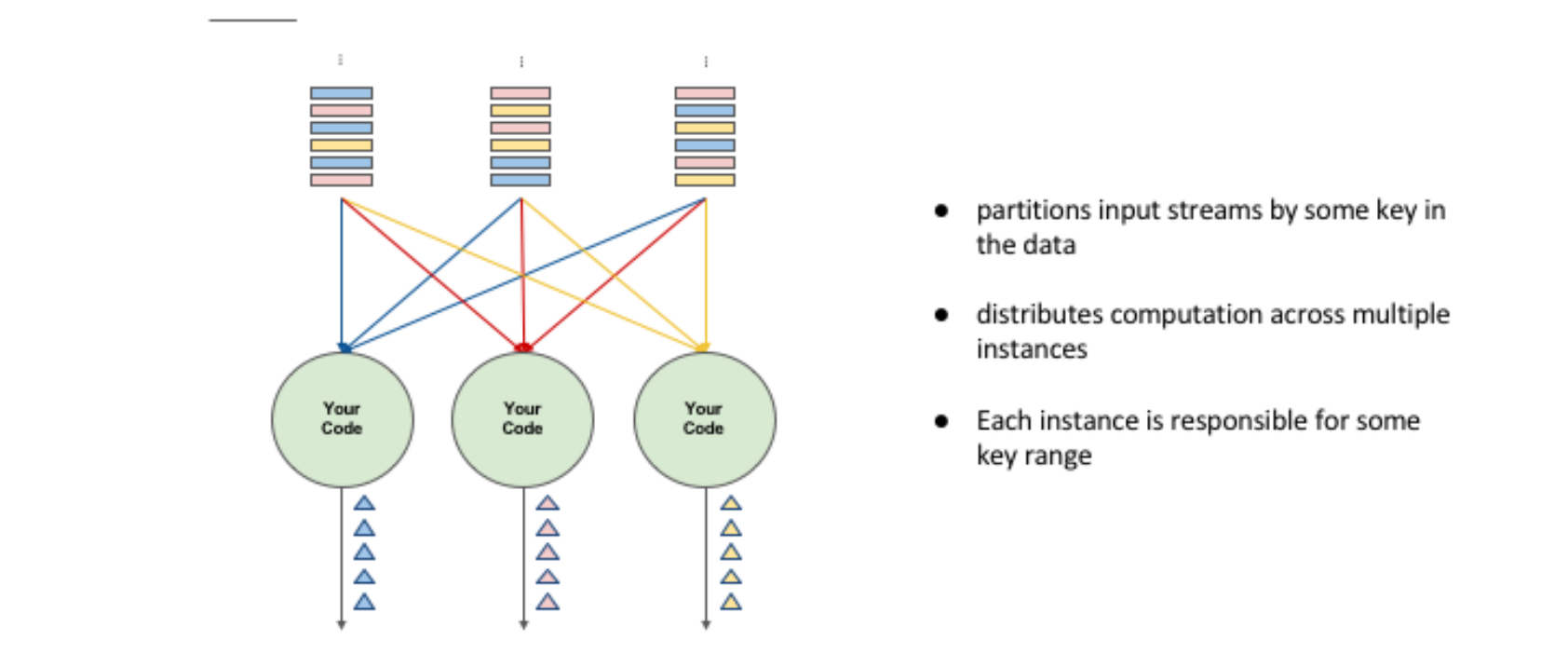
假设有多个使用者使用 Input Streams,每个使用者都有自己的ID。如果我们需要计算每个使用者出现的次数,我们需要将同一使用者的事件流到同一个运算代码中。这个过程类似于批处理中的group by,需要对数据进行分区,并设置相应的键值。然后,将具有相同键值的数据流传输到同一个计算实例中进行相同的运算。这样可以确保每个使用者的数据被正确地处理,并且可以提高处理效率。
有状态分布式流式处理
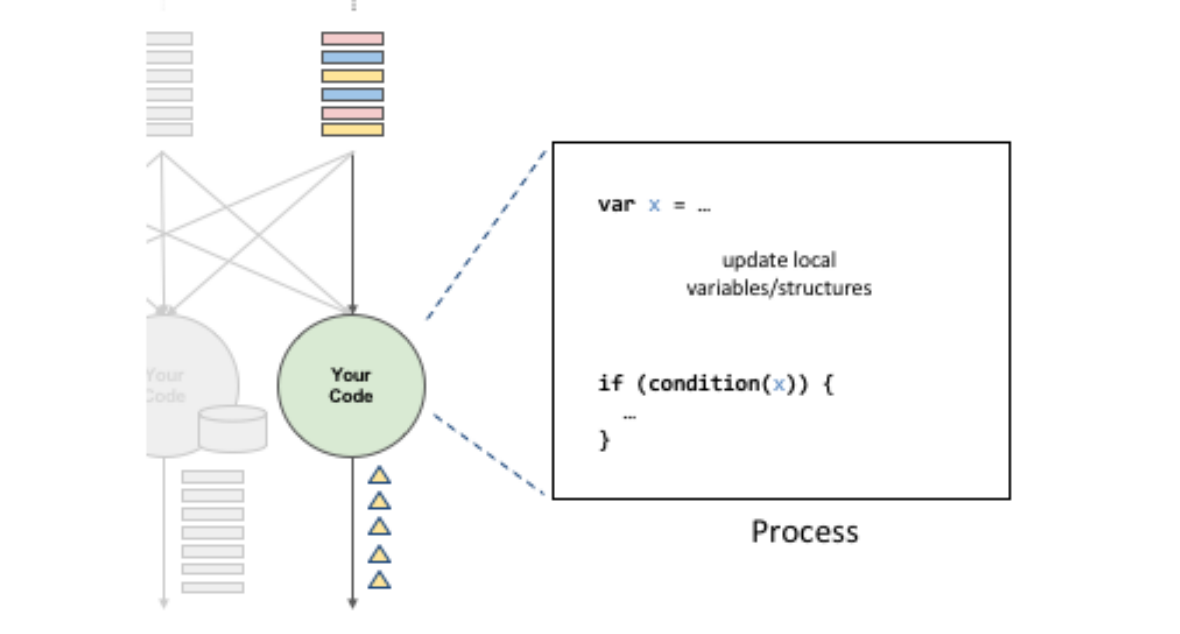
在上述代码中,定义了变量X,X会在数据处理过程中进行读写。在输出结果时,根据变量X的值来决定输出的内容。因此,状态X会影响最终的输出结果。在这个过程中,第一个重点是先进行状态的co-partitioned key by。这样,具有相同键值的数据会流到同一个计算实例中,与使用者出现次数的原理相同。这个状态就是使用者出现的次数,会随着具有相同键值的事件在同一个计算实例中进行累积。
有状态分散式流式处理
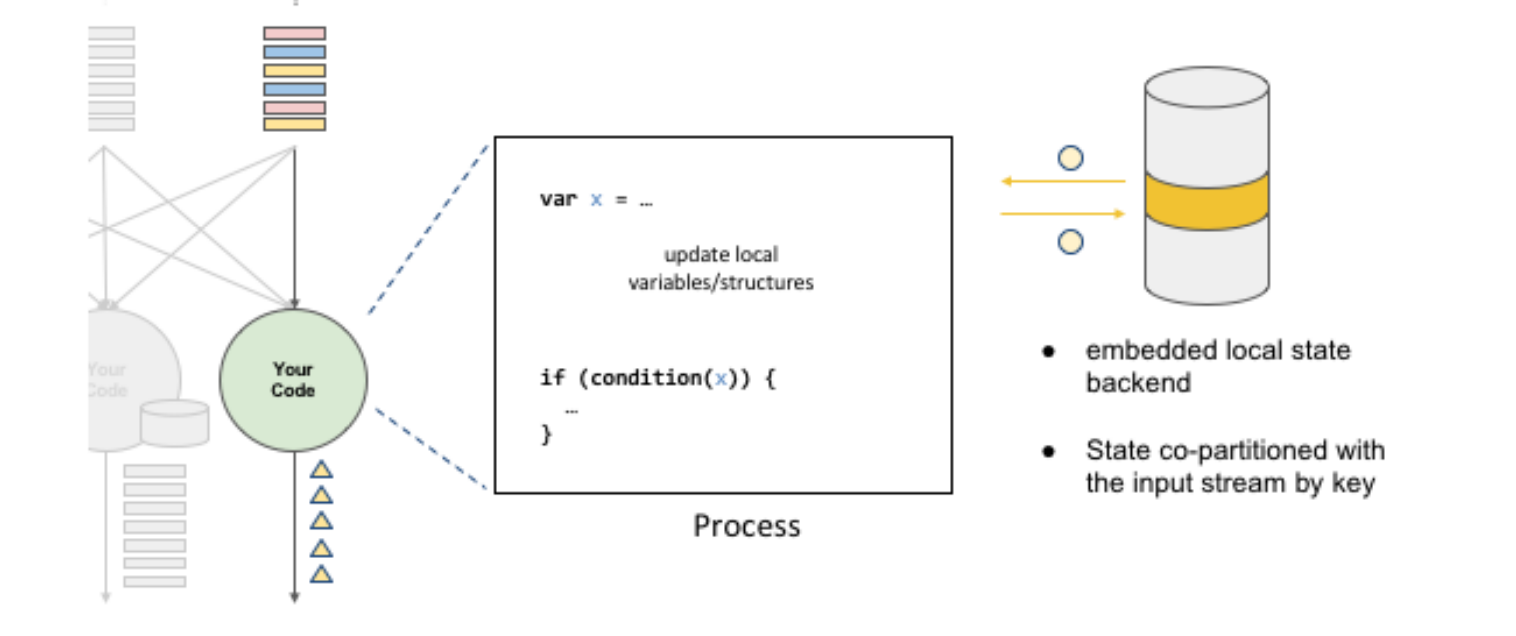
根据输入流的键值重新分区后,状态也会变成co-partition状态,即具有相同键值的状态会被累积到同一个流中。第二个重点是嵌入式本地状态后端。在具有状态的分散式流式处理引擎中,状态可能会累积到非常大,特别是当键值非常多时,状态可能会超出单一节点的内存负荷量。因此,必须有状态后端来维护这些状态。在正常情况下,状态后端可以使用内存来维护这些状态。
总结分析
总之,传统批处理数据是一种基于批处理作业的数据处理方式,它可以有效地处理大量的数据,并且可以在非工作时间进行处理,从而提高数据处理的效率和精度。
流式处理是一种数据处理方式,它能够在数据到达时及时对其进行处理。与批处理不同,流式处理是在数据流中逐个处理数据,而不是将所有数据收集起来一次性处理。





