这两天一直在找直接用python做接口自动化的方法,在网上也搜了一些博客参考,今天自己动手试了一下。
一、整体结构
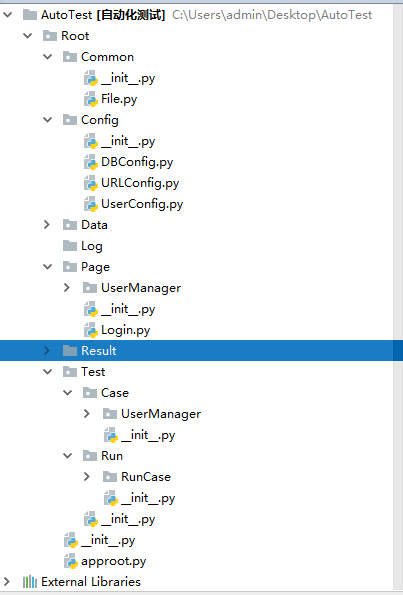
上图是项目的目录结构,下面主要介绍下每个目录的作用。
Common:公共方法:主要放置公共的操作的类,比如数据库sqlhelper、文件操作类等
Config:公共变量:主要放置公共变量,比如ST、UAT、生产环境的url地址、用户名密码、数据库连接
Data:数据层,有点类似三层架构中的DAL,它是数据的来源,根据数据存放的格式再细分json、xml、表单和数据库
Log:日志层:存放日志,便于跟踪调试
Page:页面层:先把整个系统划分若干子系统,每个子系统包含若干页面。这个把用户操作的页面抽象成了page对象,页面的操作抽象成方法,这样测试人员可以传递不同的测试案例进行测试,如果是面向服务的纯接口性质的,没有页面那就没必要再这样划分,这样就把接口测试转换成了python的单元测试。
Result:存放单元测试的执行结果,也可以把每次执行的结果存到数据库打点,然后做测试结果趋势分析,如果后续把项目集成到Jenkins中的话,相当于Jenkins集成python单元测试,这样的话这层也可以不需要。
Case:测试案例层,针对上面Page对应的单个方法利用测试数据和期望数据进行assert判断,这里用到的测试数据和期望数据后续可以放在Excel中,测试人员只需填充测试数据。
Run:这里用来组装成suite然后进行运行案例。
二、测试
1.安装HTMLTestRunner
把它下载下来放到python安装目录的lib目录下
2.业务逻辑层
这里模拟一些业务处理,这里做接口自动化时会使用requests库进行请求。
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import requestsdef Add(name,pwd):session=requests.session()response=session.get('http://www.baidu.com')print(response.status_code)return response.status_code==200def Edit(name,pwd):return {'name':name,'pwd':pwd}def Delete(name,pwd):return {'name':name,'pwd':pwd}def Search(name,pwd):return {'name':name,'pwd':pwd}3.案例层
原本计划增加一个套件suite层,如果是单个接口的不加也可以,如果是多个接口进行流程测试,使用suite时案例的顺序就不会改变。如果是流程的,也可以写成case,只是里面需要多次调用业务逻辑层。‘
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import unittest
from Root.Page import Login
from Root.Page.UserManager import Index
import HTMLTestRunner
import time
class index(unittest.TestCase):def setUp(self):print('setUp')def tearDown(self):print('tearDown')def test_add(self):arr= Login.Login('admin', '123456')flag= Index.Add(arr[0], arr[1])self.assertTrue(flag)flag= Index.Add(arr[0], arr[1])self.assertTrue(flag==False)def test_edit(self):response= Login.Login('admin', '123456')dic= Index.Edit(response[0], response[1])self.assertNotEqual(dic,{'name':'123'})def test_delete(self):response= Login.Login('admin', '123456')dic= Index.Delete(response[0], response[1])self.assertNotEqual(dic,{'name':'123'})’4.运行
这里主要考虑可能整个系统会分成不同的模块进行运行,这样也能维护上也必将方便,可以多执行机执行。这里使用的HTMLTestRunner来生成报告.
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import os
import unittest
from HTMLTestRunner import HTMLTestRunner
from Root.Test.Case.UserManager import Index
import HTMLTestRunner
import time
if __name__ == '__main__':# 1、构造用例集suite = unittest.TestSuite()# 2、执行顺序是安加载顺序:先执行test_sub,再执行test_addsuite.addTest(Index.index("test_add"))suite.addTest(Index.index("test_edit"))suite.addTest(Index.index("test_delete"))suite.addTest(Index.index("test_edit"))suite.addTest(Index.index("test_edit"))filename = "../../../Result/{0}Report.html".format(time.strftime("%Y%m%d%H%M%S", time.localtime()) ) # 定义个报告存放路径,支持相对路径f = file(filename, 'wb') # 结果写入HTML 文件runner = HTMLTestRunner.HTMLTestRunner(stream=f, title='测试报告', description='XXX系统接口自动化测试测试报告',verbosity=2) # 使用HTMLTestRunner配置参数,输出报告路径、报告标题、描述runner.run(suite)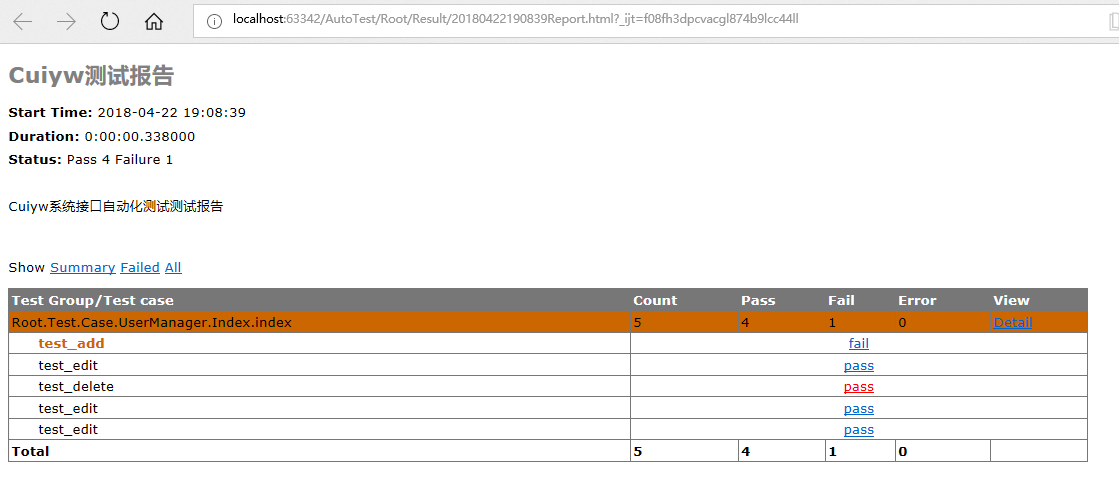
三、测试案例参数化
上面的每个单元测试只能运行一个测试案例的数据,就是如何实现参数化,这样配置一下案例数据就能运行多次单元测试,这样就会方便很多。找了下python自带的单元测试框架不支持,这里使用了nose和parameterized 。
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from nose.tools import assert_equal
from parameterized import parameterized
import HTMLTestRunner
import time
import unittest
import math@parameterized([(2, 2, 4),(2, 3, 8),(1, 9, 1),(0, 9, 0),
])
def test_pow(base, exponent, expected):assert_equal(math.pow(base, exponent), expected)class TestMathUnitTest(unittest.TestCase):@parameterized.expand([("negative", -1.5, -2.0),("integer", 1, 1.0),("large fraction", 1.6, 1),])def test_floor(self, name, input, expected):assert_equal(math.floor(input), expected)
然后cmd跳转到该python文件的目录下,输入命令,它会把该文件中test开头的案例都跑了,然后就可以看到有一个案例运行输出结果的html文件.
nosetests testRuncase.py --with-html --html-report=nose_report2_test.html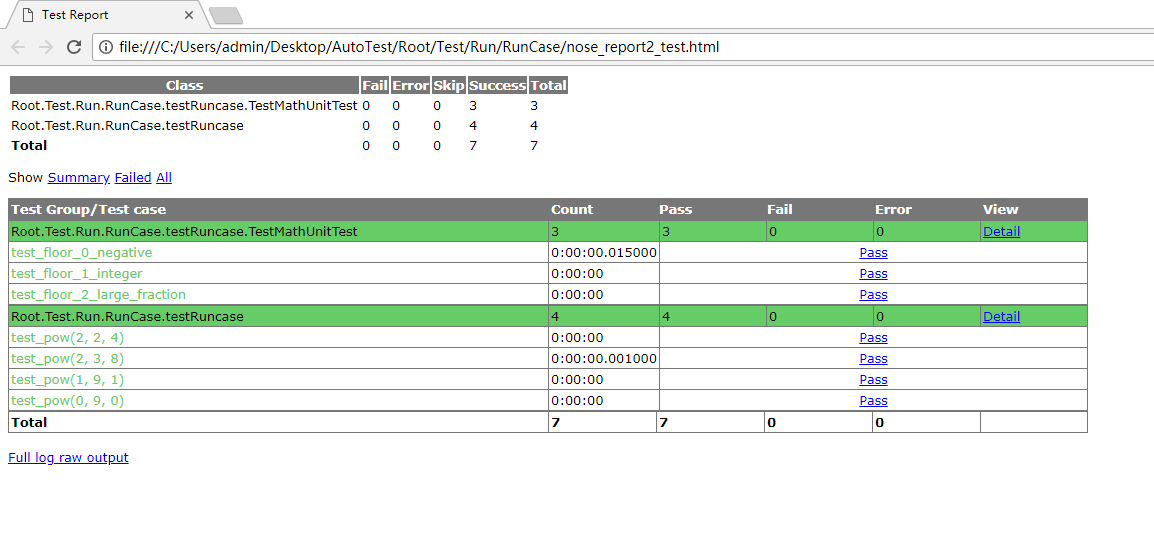
大家也可以看看这个视频学接口自动化测试,只能说超级详细了,
B站讲的最详细的Python接口自动化测试实战教程全集(实战最新版)
![[python入门㊾] - python异常中的断言](https://img-blog.csdnimg.cn/16caf23859fc4edaa7d57b6b747d0432.png)