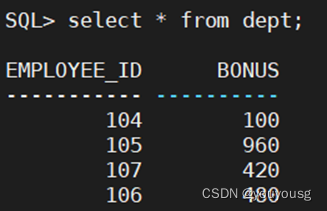
什么是UTXO
在比特币钱包当中,我们通常能够看到账户余额,然而在中本聪设计的比特币系统中,并没有余额这个概念。“比特币余额”是由比特币钱包应用派生出来的产物。中本聪发明了UTXO交易模型,并将其应用到比特币当中。
UTXO(Unspent Transaction Outputs)是未花费的交易输出,它是比特币交易生成及验证的一个核心概念。交易构成了一组链式结构,所有合法的比特币交易都可以追溯到前向一个或多个交易的输出,这些链条的源头都是挖矿奖励,末尾则是当前未花费的交易输出。
基于账户的交易
我们先看下传统的交易是如何进行的:我们设计一个支付系统,给张三一个账户,里面有余额100 元,李四有一个账户,里面有余额50元。当张三要付给李四20元时,做以下操作:
1. 检查张三账户余额是否充足,如果不足20元就终止交易,向张三报“余额不足”
2. 在张三账户里减去20元(假设零手续费)
3. 在李四账户里增加20元
现在的银行也好、信用卡也好、证券交易系统也好,互联网第三方支付系统也好,其核心都是基于账户(account based)的设计,由关系数据库支撑。
基于UTXO的交易
要理解UTXO,最简单的办法就是把一枚比特币从诞生到在商海中沉浮的经历描述一下。我们假设一个这样的场景:张三挖到12.5 枚比特币。过了几天,他把其中 2.5 枚支付给李四。又过了几天,他和李四各出资 2.5 比特币凑成 5 比特币付给王五。
比特币的区块链账本里记录的是一笔又一笔的交易。
每笔交易都有若干交易输入,也就是资金来源,也都有若干笔交易输出,也就是资金去向。一般来说,每一笔交易都要花费(spend)一笔输入,产生一笔输出,而其所产生的输出,就是“未花费过的交易输出”,也就是 UTXO。
比特币交易遵守几个规则:
第一,除了 coinbase交易之外,所有的资金来源都必须来自前面某一个或者几个交易的 UTXO,就像接水管一样,一个接一个,此出彼入,此入彼出,生生不息,钱就在交易之间流动起来了。
第二,任何一笔交易的交易输入总量必须等于交易输出总量,等式两边必须配平。
上图第一个交易#1001 号交易是 coinbase 交易。比特币是矿工挖出来的。当一个矿机费尽九牛二虎之力找到一个合格的区块之后,它就获得一个特权,能够创造一个 coinbase 交易,在其中放入一笔新钱,并且在交易输出的收款人地址一栏,堂堂正正的写上自己的地址。假设这笔比特币的数额为12.5 枚,这个coinbase 交易随着张三挖出来的区块被各个节点接受,经过六个确认以后永远的烙印在历史中。
过了几天,张三打算付 2.5 个比特币给李四,张三就发起#2001号交易,这个交易的资金来源项写着“#1001(1)”,也就是 #1001 号交易——张三挖出矿的那个 coinbase 交易——的第一项 UTXO。然后在本交易的交易输出 UTXO 项中,把2.5个比特币的收款人地址设为李四的地址。
请注意,这一笔交易必须将前面产生那一项 12.5 个比特币的输出项全部消耗,而由于张三只打算付给李四 2.5 个比特币,为了要消耗剩下的10比特币,他只好把剩余的那 10 个比特币支付给自己,这样才能符合输入与输出配平的规则。
再过几天,张三和李四打算AA制合起来给王五付 5 枚比特币。那么张三或李四发起 #3001 号交易,在交易输入部分,有两个资金来源,分别是#2001(1) 和 #2001(2),代表第 #2001 号交易的第 (1) 和第 (2) 项 UTXO。然后在这个交易的输出部分里如法炮制,给王五5比特币,把张三剩下的 7.5 比特币发还给自己。以后王五若要再花他这5比特币,就必须在他的交易里注明资金的来源是 #3001(1)。
所以,其实并没有什么比特币,只有UTXO。当我们说张三拥有 10 枚比特币的时候,我实际上是说,当前区块链账本中,有若干笔交易的 UTXO 项收款人写的是张三的地址,而这些 UTXO 项的数额总和是 10。而我们在比特币钱包中所看到的账户余额,实际上是钱包通过扫描区块链并聚合所有属于该用户的UTXO计算得来的。
两种交易方式对比
1.UTXO只需要看最后一次交易,而账户系统要看历史全数据后所有的增减操作全部加起来才能获得正确的余额,两者效率差异随着时间推移会越来越大;
2.UTXO未来可以裁剪历史老数据,而账户系统则不能丢弃老数据,前者区块链可以控制住整体大小,而后者只能持续膨胀。
一点思考
比特币规定每一笔新的交易的输入必须是某笔交易未花费的输出,每一笔输入同时也需要上一笔输出所对应的私钥进行签名,并且每个比特币的节点都会存储当前整个区块链上的UTXO,整个网络上的节点通过UTXO及签名算法来验证新交易。
转自:
作者:悦诗LY
链接:https://www.jianshu.com/p/02fd289e8853