INTERSPEECH 2023 论文预讲会是由CCF语音对话与听觉专委会、语音之家主办,旨在为学者们提供更多的交流机会,更方便、快捷地了解领域前沿。活动将邀请 INTERSPEECH 2023 录用论文的作者进行报告交流。
INTERSPEECH 2023 论文预讲会第一期邀请到清华大学和新疆大学进行联合专场分享,欢迎大家预约观看。

第一期
清华大学 & 新疆大学【专场】
时间:6月8日(周四) 18:30-21:00
形式:线上
议程:每位嘉宾分享30分钟(含5分钟QA)
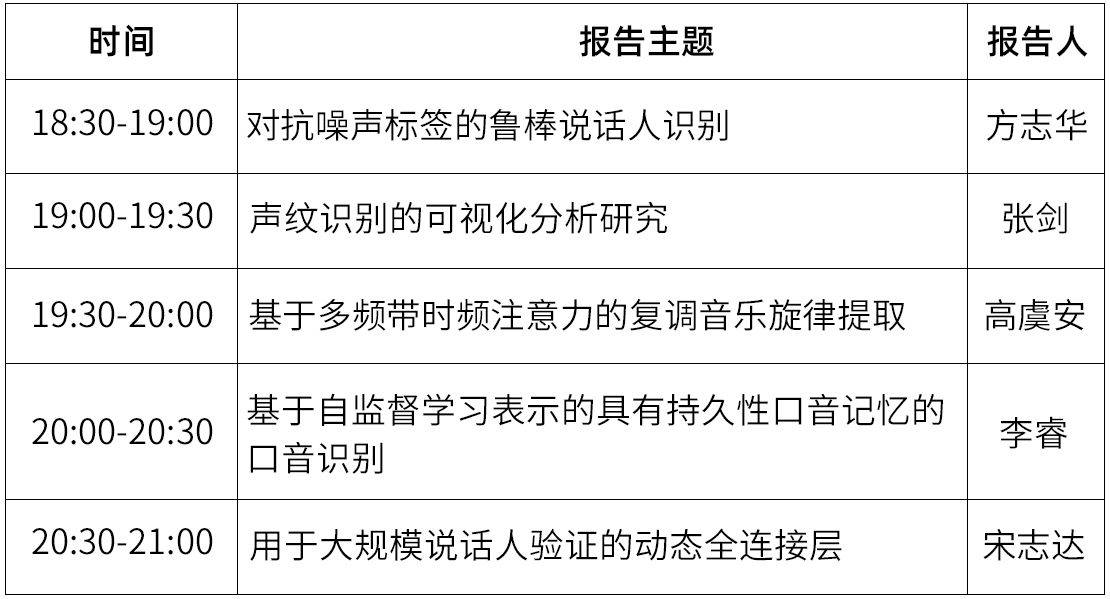
嘉宾&主题

嘉宾简介:方志华,新疆大学计算机科学与技术专业硕士二年级在读,主要研究方向是带噪声标签的说话人识别方法研究。
分享主题:对抗噪声标签的鲁棒说话人识别
摘要:带噪声标签学习一直是研究的热点之一,但在说话人识别方面的研究还不够成熟。已有的研究聚焦于鲁棒的损失函数和鲁棒正则化,目前在样本选择方面还没有相关研究。因此我们提出一种两阶段的方法进行训练,既实现了优异的性能,又能准确过滤噪声数据并尽可能挑选出干净数据。该方法不仅适用于说话人识别,也适用于人脸识别等其他领域。

嘉宾简介:张剑,新疆大学信息与通信工程专业硕士二年级在读,主要研究方向是声纹特征的可视化研究。
分享主题:声纹识别的可视化分析研究
摘要:利用5种归因算法和2种方式在ECAPA-TDNN上实现声纹特征的可视化,以及对可视化结果做出分析。

嘉宾简介:高虞安,新疆大学硕士研究生二年级在读,新疆大学信号检测与处理重点实验室,主修音乐信息检索
分享主题:基于多频带时频注意力的复调音乐旋律提取
摘要:音乐旋律提取是音乐信息检索(MIR)领域中一项具有挑战性的任务,其目的是从复调音乐中生成与歌唱旋律音高对应的频率值序列。在本文中,我们提出了一种多频带时频注意力网络Multi-band Time-frequency Attention Network (MTANet)用于复调音乐旋律提取。针对高共振声音容易导致高次谐波的振幅大于基频,从而导致八度误差问题,我们提出了一种频带划分策略,旨在利用频谱中基频和非基频成分的位置分布来表征基频分量和非基频分量。同时,频带划分能够有效规避高次谐波及高频噪声对基频定位的影响。为了进一步融合多频带特征,我们提出一种基于时频注意力的特征融合模块以获得能更有效表征主旋律的显著表示。可视化与实验结果表明,MTANet能够降低八度和旋律检测误差且在保持较少网络参数的基础上取得了良好的性能。

嘉宾简介:李睿,新疆大学多语种信息技术重点实验室硕士生,研究方向为多语种识别。
分享主题:基于自监督学习表示的具有持久性口音记忆的口音识别
摘要:由于缺乏训练数据以及口音与说话人和区域特征纠缠在一起,口音识别 (AR) 具有挑战性。本文旨在从两个角度提高 AR 性能。首先,为了缓解数据不足的问题,我们使用从预训练模型中提取的自我监督学习表示 (SSLR) 来构建 AR 模型。在 SSLRs 的帮助下,与传统的声学特征相比,它获得了显着的性能提升。其次,我们提出了一种持久性口音记忆(PAM)作为上下文知识来偏置 AR 模型。AR 模型的编码器从所有训练数据中提取的重音嵌入被聚类以形成重音码本,即 PAM。此外,我们提出了多种注意机制来研究 PAM 的最佳利用。我们观察到,通过选择最相关的重音嵌入可以获得最佳性能。

嘉宾简介:宋志达,新疆大学信息科学与工程学院二年级硕士生,研究方向为声纹识别和语音识别。
分享主题:用于大规模说话人验证的动态全连接层
摘要:主流的说话人验证系统在训练阶段通常使用one-hot编码的全连接(FC)层进行分类。假设使用一个大规模数据集(包含百万甚至更多说话人)进行训练,FC层参数的优化将占用大量内存和时间。本文中,我们提出使用动态全连接(Dynamic FC)层替换FC层。Dynamic FC层使用一个动态类队列存储说话人伪身份中心的一个子集。该层的内存占用仅取决于动态类队列的大小,不会随着训练数据集中说话人的数量增加而增加。此外,我们采用了一种基于身份的数据加载机制使得训练时间进一步节省。在VoxCeleb数据集上的实验结果表明,Dynamic FC层使用较少的参数数目就可以获得不错的性能。
参与方式
直播将通过CSDN进行直播,手机端、PC端可同步观看
👇👇👇
https://live.csdn.net/room/weixin_48827824/cmMINpYu
论文征集
INTERSPEECH 2023 论文预讲会面向全球线上招募,结合定向邀请与自选投稿的方式,来选择预讲会的嘉宾。
投稿邮箱:jack@speechhome.com