分析网页

可以看见网站搜索框这里运用了异步JavaScript渲染来报证不刷新整个页面的情况下来刷新数据,这样我们就可直接打开浏览器开发工具找到Ajax请求,也就是图中我点击的位置,然后可以看到请求体里面有params数,这个参数一般是用于url拼接的,我们还可以找到请求方式是post请求,这样就有了请求url和params参数

返回数据是以json数据返回的,也就是嵌套字典的形式,我们可以看到我们想要的信息都在这里面,然后我们选一个搜索结果点进去

点进来以后发现这个页面也是用Ajax请求来获取刷新后的数据,也就是我上面说的异步javascrapy渲染,
我们发现可以对搜索到的股票信息进行分类和时间筛选,我这里选了年报,半年报和日常经营这三个分类,你们也可以换成别的,这里的请求体数据类型变成了data,请求方式也是post请求,在这里我们可以看见data参数里面有一个stock键,它对应的值601012,9900022338,然后我们在返回上面一张图片一看,唉,这不就是code和orgId参数吗所以从上次Ajax请求返回的数据里面我们就可以得到stock这个参数了,然后我们再往下看,tabName,pageSize,pageNum是固定参数不用管,来到column这里开始参数就会有变化了,categories就是类别的意思,三个参数分别对应我之前点击的分类类型年报,半年报,日常经营,seDate我们可以看见一个时间段这是什么呢?我们看下面这张图
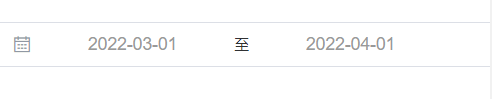
唉!这不就对应我选的日期间隔吗?看来我们又得到了一个参数,然后就是plate和column了,在这里我们还不知这是什么意思,我们返回首页去不同的股市板块分别选几个不同的股票对比一下看看,

从左往右分别是深市,沪市,北交所的股票信息,可以看见plate分别是sz,sh,bj,这不就是深圳,上海,北京的配音缩写吗?这样就可以得到深市:column=szse,plate=sz, 沪市:column=sse,plate=sh, 北交所:column=bj,plate=bj;third,
这样我们就得了股票分类筛选请求的所有请求体参数
接下来就是下载pdf了,

我们可以从返回的数据里面得到一个pdf的url,但是这并不是完整的url我们还得去找到完整的url

我们点进一个pdf页面可以再文档这里找到后缀为pdf的文件,点进去发现请求链接域名后面就是我们之前得到的pdf下载地址,我们点击一下试试,发现就是我们要找的下载地址
这样我们就得到了所有想要的参数
可以开始动手写代码了
完整功能代码
import requests
import os
import aiohttp
import asyncio
import aiofiles
# 设置请求头
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Krow, like Gecko) Chrome/99.0.4844.51 Safari/537.36'
}
# 创建一个目录用来存储pdf文件
path = 'D:/股票信息/'
if not os.path.exists(path):os.mkdir(path)print('文件夹创建成功')
def search():"""搜索函数:return: 返回搜索结果并筛选信息"""# 输入搜索关键字while True:key = input('请输入关键字: ')# 设置params参数params = {'keyWord': key,'maxNum': 10}url = 'http://www.cninfo.com.cn/new/information/topSearch/query'# 发送post请求resp = requests.post(url, headers=headers, params=params)if resp.json() == []:print('该股票不存在请重新输入: ')continueelse:break# 过滤A股search_list = []for r in resp.json():if r['category'] == 'A股':search_list.append(r)# 将每只股票写上对应序号search_dict = {'0': '再次按下enter键返回到搜索框'}num = 1for row in search_list:search_dict[str(num)] = rowprint('[序号:{}]名称:{}'.format(num, row['zwjc']))num += 1# 选择想要下载的股票序号while True:numbers = input('请输入你要选择的股票序号:')if search_dict.get(numbers) == None:print('你输入的股票序号不存在,请重新输入:')elif numbers == '0':print(search_dict[numbers])continueelse:return search_dict[numbers]def category(code,orgId):"""分类函数对搜索到的股票信息进行分类筛选:param code: 股票代码:param orgId: 股票id:return: 返回股票报告pdf下载地址"""# 定义分类字典category_dict = {'1': 'category_ndbg_szsh','2': 'category_bndbg_szsh','3': 'category_rcjy_szsh'}while True:number = input('请选择你要下载的股票信息分类(1年报 2半年报 3日常经营): ')if number == '1':category_search = 'category_ndbg_szsh'elif number == '2':category_search = 'category_bndbg_szsh'elif number == '3':category_search = 'category_rcjy_szsh'elif category_dict.get(number) == None:print('没有你选择的类别,请重新输入')continuebreak# 深市股票:column : szse plate : sz# 沪市股票: column : sse plate : sh# 通过股票代码启示字符来判断该股票是深市还是沪市if str(code).startswith('0') or str(code).startswith('3'):column = 'szse'plate = 'sz'elif str(code).startswith('6'):column = 'sse'plate = 'sh'category_url = 'http://www.cninfo.com.cn/new/hisAnnouncement/query'# 选择时间段startime = input('请输入开始时间(例如:2017-01-01): ')endtime = input('请输入结束时间(例如:2019-01-01): ')# 搜索结果列表result_list = []# 搜索页码page_num = 1while True:# 设置data参数data = {'stock': '{},{}'.format(code, orgId),'tabName': 'fulltext','pageSize': '30','pageNum': '{}'.format(page_num),'column': column,'category': category_search,'plate': plate,'seDate':'{}~{}'.format(startime, endtime),'searchkey':'','secid':'','sortName':'','sortType':'','isHLtitle': 'true',}resp = requests.post(category_url, data=data, headers=headers)if resp.json()['announcements'] == None:print('该时间段里没有相关股票信息,请重新输入时间段: ')# 选择时间段startime = input('请输入开始时间(例如:2017-01-01): ')endtime = input('请输入结束时间(例如:2019-01-01): ')continuefor row in resp.json()['announcements']:result_list.append([row['announcementTitle'], row['adjunctUrl']])# 同返回json数据里的hasMore参数来判断是否需要翻页if resp.json()['hasMore'] == 'true':page_num += 1continue# 已经获取所有的数据了结束循环breakreturn result_listasync def download(name, url):"""文件下载函数:param name: 文件名:param url: 文件下载地址:return:"""download_url = 'http://static.cninfo.com.cn/{}'.format(url)async with aiohttp.ClientSession() as session:async with session.get(download_url) as resp:file = await resp.content.read()async with aiofiles.open('{}{}.pdf'.format(path, name), 'wb')as f:await f.write(file)print('文件下载成功')async def main():"""主函数,调用其他函数来完成相关操作:return:"""# 调用搜索函数,获取搜索结果列表search_result = search()# 股票代码和股票IDcode, Id = search_result['code'], search_result['orgId']# 调用分类函数获取处理过后的结果列表detail_list = category(code, Id)# 将下载函数封装成task对象tasks = [asyncio.create_task(download(name=item[0], url=item[1])) for item in detail_list]# 协程对象进入事件循环await asyncio.wait(tasks)if __name__ == '__main__':asyncio.run(main())print('所有文件下载完成!')
这里面我用到了异步爬虫的知识,异步知识如果你不是很懂的话可以先去了解下再回来看我的代码就能理解了