个人学习记录
一、效果展示
这里贴一个还不错的某壁纸网:Wallpaper Abyss - HD Wallpapers, Background Images
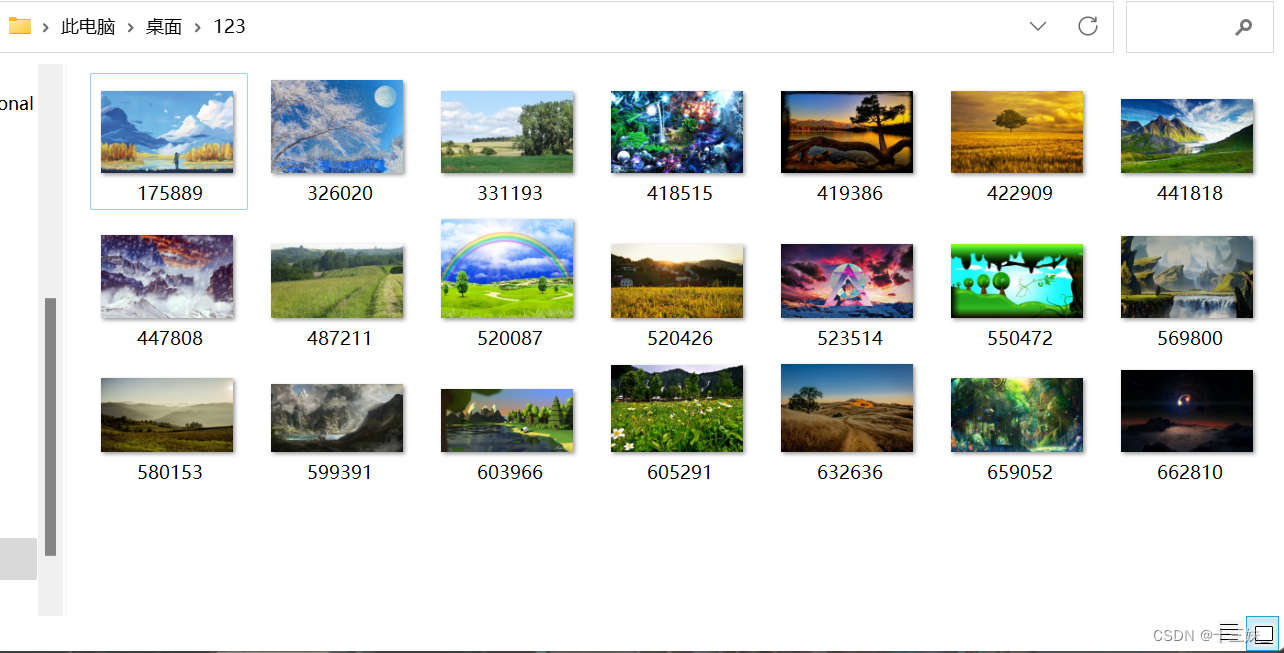
下载的结果展示:
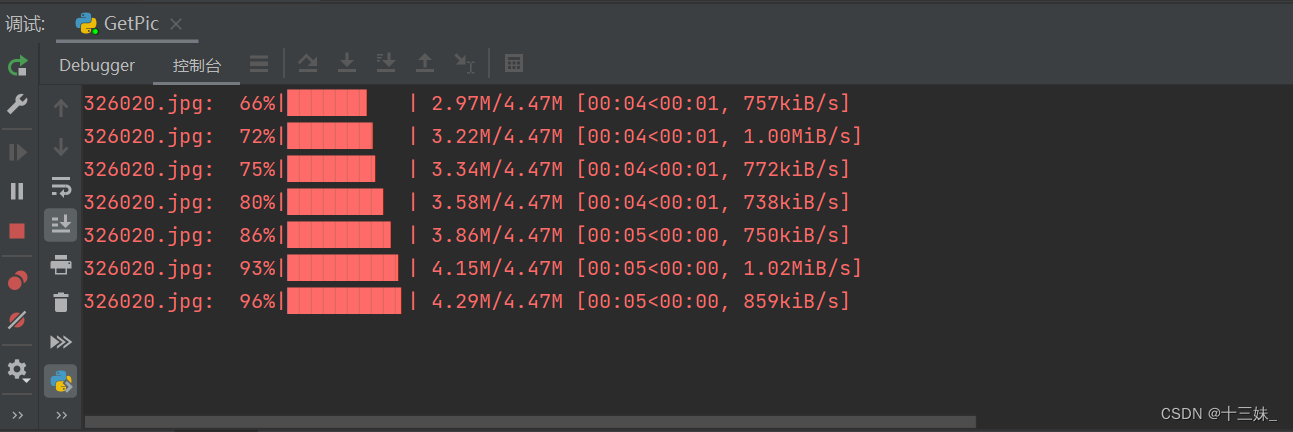
下载进度展示:
二、完整代码
代码中给定了部分注释
import os
import re
import urllib.request
from concurrent.futures import ThreadPoolExecutorimport requests
import tqdm as tqdm
from bs4 import BeautifulSouphead = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36"
}def getPage(url):# 获取通过BeautifulSoup美化过的网页req = urllib.request.Request(url=url, headers=head)html = ""try:response = urllib.request.urlopen(req)html = response.read()page = BeautifulSoup(html, "html.parser")except Exception as result:print(result)return pagedef getFileType(name):# 获取图片的类型,即图片URL图片名的后缀.png .jpg等格式str1 = str(name).split('.', -1)str2 = str1[len(str1) - 1]return str2def getPic(url):pattern = r'<img alt="(.*?)" class="img-responsive big-thumb" height=".*?" loading="lazy" src="(.*?)" width=".*?"/>'# 在正则表达式匹配时里面各参数的顺序按照BeautifulSoup后的page来设置,在原始html中,img 后面并不是alt而是 img class# (.*?)即表示要获取的段,.*?代表任意字符不做匹配imgPage = re.compile(pattern, re.S)page = getPage(url)picname = []# picname存储alt字段,对于一些图片的描述可做图片名,也直接用URL的图片名# 故picname可要可不要picurl = []for item in page.find_all('img'):# 遍历查找当前网页中所有的图片item = str(item)imgurl = re.findall(imgPage, item)if len(imgurl) != 0:if imgurl[0][0] != '':imgname = imgurl[0][0] + '.' + getFileType(imgurl[0][1])picname.append(imgname)picurl.append((imgurl[0][1]).replace('thumbbig-', ''))# 因为该主页中图片被压缩了,删除thumbbig-的URL才是图片原始地址return picname, picurldef main(url):filePath = 'C:/Users/txl/Desktop/123/'# 给定文件存储路径# i = 0for item in (getPic(url)[1]):req = urllib.request.Request(url=item, headers=head)data = urllib.request.urlopen(req).read()# 读取当前图片resp = requests.get(item, stream=True)fileSize = int(resp.headers.get('content-length', 0))# 获取当前图片的总大小imgname = item.split('/')[-1]# 此处以URL中的后缀直接作为图片名(可能是毫无规律的数字,故有时中文网站alt中的中文描述更适合做名字)if not os.path.exists(filePath + imgname):pbar = tqdm.tqdm(total=int(fileSize), unit='iB', unit_scale=True, desc=item.split('/')[-1])# 添加下载进度显示with open(filePath + imgname, 'wb') as file:for chunk in resp.iter_content(chunk_size=1024):if chunk:file.write(chunk)pbar.update(1024)else:continue# i = i + 1if __name__ == "__main__":url1 = 'https://wall.alphacoders.com/search.php?search=landscape&quickload=300&page='for count in range(1, 3):url = url1 + str(count)# pool = ThreadPoolExecutor(max_workers=10)# pool.submit(main(url), count)main(url)exit(0)
内容简介
打开网站随便浏览,我们发现该网页的图片采用下滑加载的方式,不是其他一些点击分页,所以在浏览器上我们并没有发现URL发生变化,这时F12打开network,我们在下滑刷新时产生了一个XHR请求,发现了带有分页标识的URL。
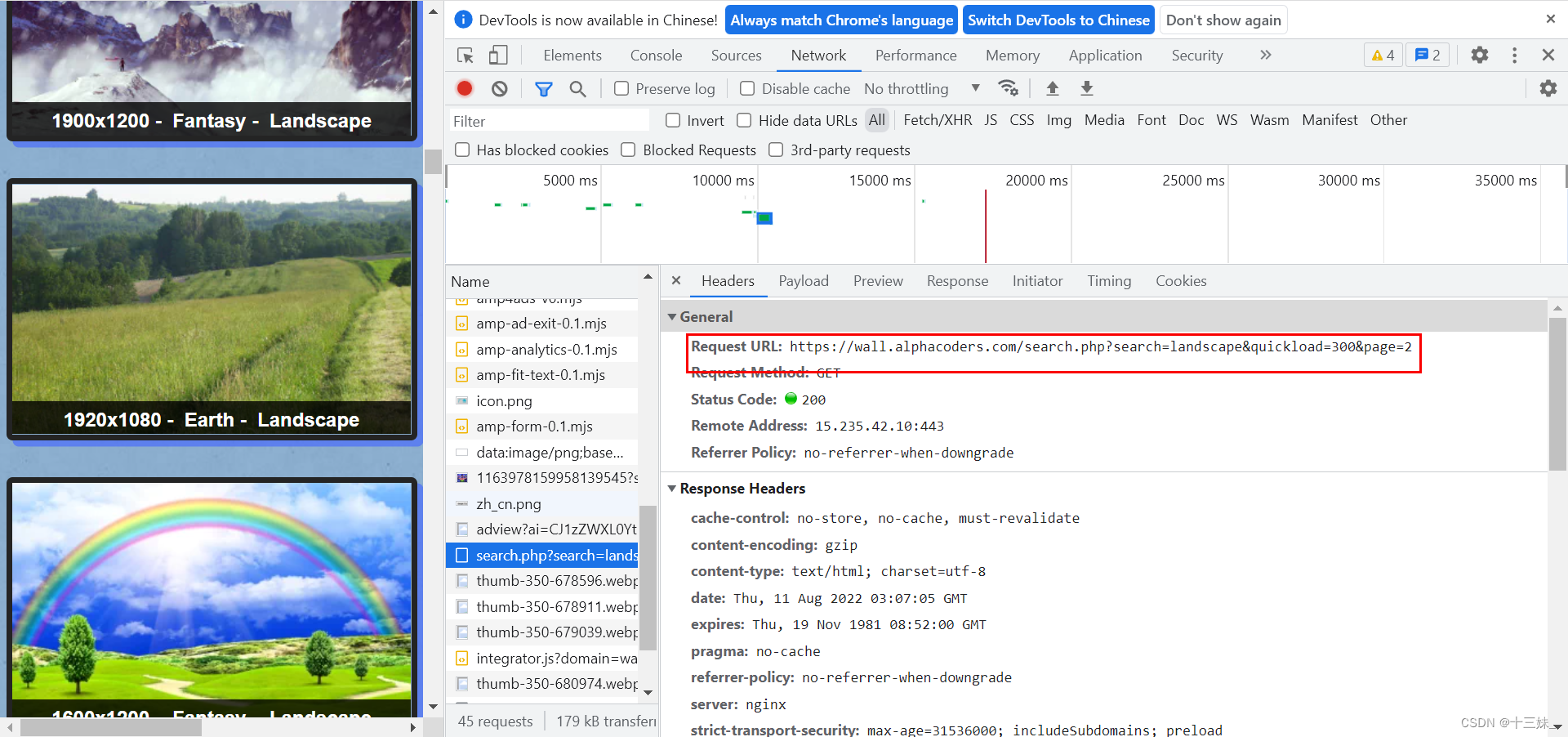
同时,在network中还有代码中需要的请求头header(即本代码中head那一串字符),现在很多网站如果不加请求头http请求是会被网站禁止的。
代码并不复杂,怎么都能看懂 ,掌握之后就可以灵活运用在自己日常图片爬取了(包括但不限于壁纸、小可爱、表情包)。当然其中还有很多可以优化或存在错误的地方,欢迎指正。