前言:学了python爬虫,那必须搞点好康的!
先导入需要用到的库
import requests
from bs4 import BeautifulSoup
import time1.针对图片网,先去源代码里面,找它的网址。
我是用的wallhaven网站的网址
然后得到了一个网址:
# 待爬取网址
url = r'https://wallhaven.cc/toplist'在字符串前面加‘r’是用于不与‘/’冲突,毕竟很多制表符都和这个有关,这个‘r’可以规避这个问题
2.用requests去获得网页的源代码
fp= {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.2.2.2.2.2"//用自己的就行
}
resp = requests.get(url,headers=fp)这里的fp是反爬措施。因为我尝试了直接获取源代码,是不行的,网页服务器会拒绝你的请求,所以我们要伪装一下,这个"User-Agent"就是模拟一个真实用户,让服务器以为你是正常浏览网页而不是一个程序。"User-Agent"可以从浏览器右键检查中,网络抓包工具里,预览选项中请求的数据中得到。
3.调用漂亮的汤 BeautifulSoup,去获取一个包
page = BeautifulSoup(resp.text,"html.parser")用的是"html.parser"模式
4.将主页面源代码进行筛选,只获得其中的图片链接,且建立两个列表存放链接
# 缩小范围到<a>标签
jpglist = page.findAll("a",class_="preview")#只用href链接
jpglistbox = []
childjbglistbox = []for i in jpglist: # 在获取的所有链接循环导出至jpg链接列表jpglistbox.append(i.get('href'))5.在的到的所有的图片链接里面循环获取源代码,打开子链接然后从中提取主要的高清大图下载
//用于验证前面的链接是否加载完毕
print(jpglistbox)
for a in jpglistbox:child_resp = requests.get(a,headers=fp)child_resp_text = child_resp.textchild_page = BeautifulSoup(child_resp_text,"html.parser")div = child_page.find("div",class_="scrollbox")img = div.find('img')src = img.get('src')#下载图片img_resp = requests.get(src)img_name = src.split("/")[-1]//建立文件夹with open (img_name,mode = "wb") as f:f.write(img_resp.content)、//提示文本print("ok!",img_name)//间隔一秒,防止网站碰壁time.sleep(1)
print("全部下载完成!")
这里是运行后的结果
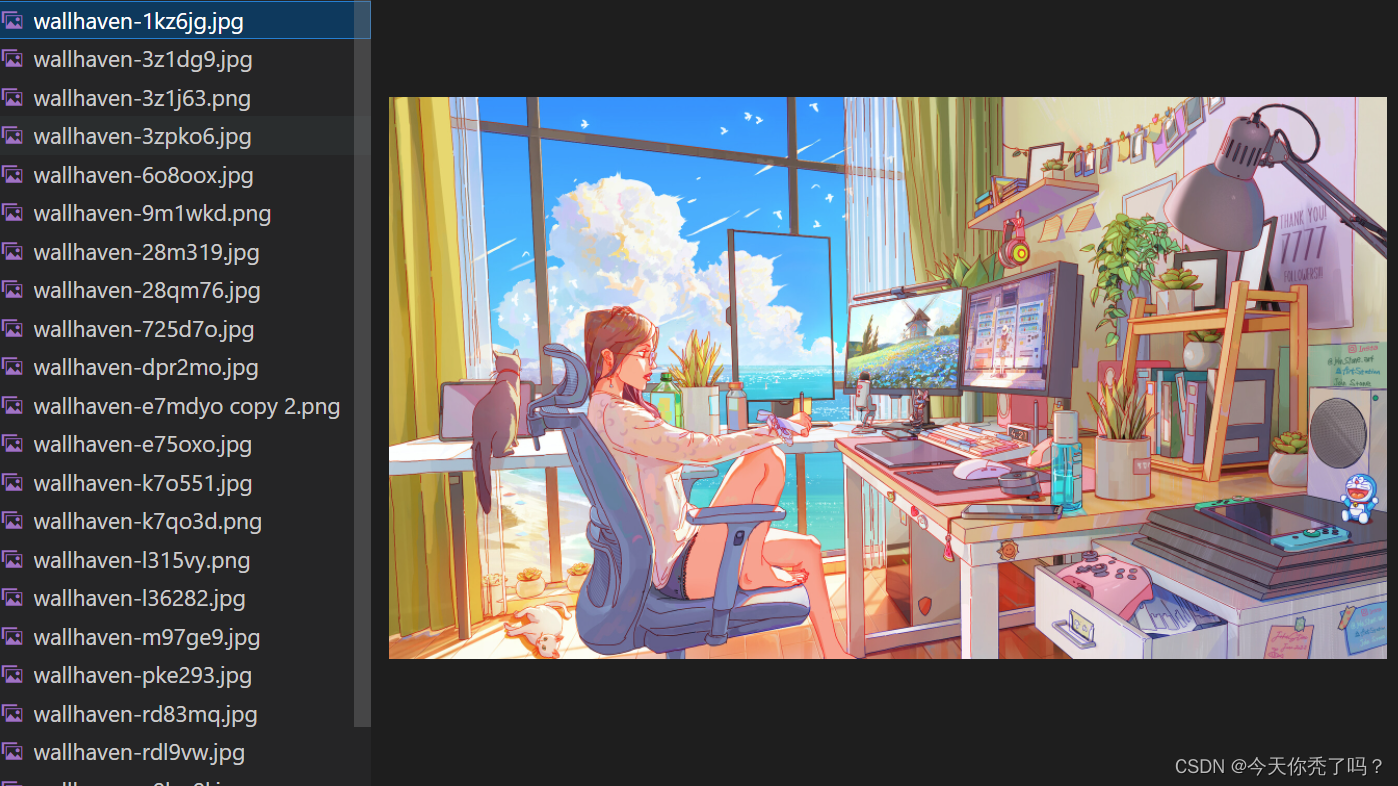
一个非常简单的控制台爬虫程序就做好了!
其实原理很简单,就是去获取网页的源代码,去提取它当前页面的图片超链接,添加到创建的list里,然后再从这个list里面遍历,循环打开超链接获取子页面代码,从子页面代码里面提取高清图的url,然后保存下载。
仅供学习,侵权联系,立马删除