Apply Transformer in the backbone
1、要把注意力结构代码放到common.py文件中
2、手把手带你Yolov5 (v6.1)添加注意力机制(一)(并附上30多种顶会Attention原理图)
3、手把手带你Yolov5 (v6.1)添加注意力机制(二)(在C3模块中加入注意力机制)
4、YOLOv5添加注意力机制
1、 put it as the last part of the backbone instead of a C3 block.
class TransformerLayer(nn.Module):# Transformer layer https://arxiv.org/abs/2010.11929 (LayerNorm layers removed for better performance)def __init__(self, c, num_heads):super().__init__()self.q = nn.Linear(c, c, bias=False)self.k = nn.Linear(c, c, bias=False)self.v = nn.Linear(c, c, bias=False)self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads)self.fc1 = nn.Linear(c, c, bias=False)self.fc2 = nn.Linear(c, c, bias=False)def forward(self, x):x = self.ma(self.q(x), self.k(x), self.v(x))[0] + xx = self.fc2(self.fc1(x)) + xreturn xclass TransformerBlock(nn.Module):# Vision Transformer https://arxiv.org/abs/2010.11929def __init__(self, c1, c2, num_heads, num_layers):super().__init__()self.conv = Noneif c1 != c2:self.conv = Conv(c1, c2)self.linear = nn.Linear(c2, c2) # learnable position embeddingself.tr = nn.Sequential(*(TransformerLayer(c2, num_heads) for _ in range(num_layers)))self.c2 = c2def forward(self, x):if self.conv is not None:x = self.conv(x)b, _, w, h = x.shapep = x.flatten(2).permute(2, 0, 1)return self.tr(p + self.linear(p)).permute(1, 2, 0).reshape(b, self.c2, w, h)class C3TR(C3):# C3 module with TransformerBlock()def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):super().__init__(c1, c2, n, shortcut, g, e)c_ = int(c2 * e)self.m = TransformerBlock(c_, c_, 4, n)
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3TR, [1024]], # 9 <--- C3TR() Transformer module[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)class SE(nn.Module):def __init__(self, c1, c2, ratio=16):super(SE, self).__init__()#c*1*1self.avgpool = nn.AdaptiveAvgPool2d(1)self.l1 = nn.Linear(c1, c1 // ratio, bias=False)self.relu = nn.ReLU(inplace=True)self.l2 = nn.Linear(c1 // ratio, c1, bias=False)self.sig = nn.Sigmoid()def forward(self, x):b, c, _, _ = x.size()y = self.avgpool(x).view(b, c)y = self.l1(y)y = self.relu(y)y = self.l2(y)y = self.sig(y)y = y.view(b, c, 1, 1)return x * y.expand_as(x)2、第二步;找到yolo.py文件里的parse_model函数,将类名加入进去
def parse_model(d, ch): # model_dict, input_channels(3)LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchorsno = na * (nc + 5) # number of outputs = anchors * (classes + 5)layers, save, c2 = [], [], ch[-1] # layers, savelist, ch outfor i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, argsm = eval(m) if isinstance(m, str) else m # eval stringsfor j, a in enumerate(args):try:args[j] = eval(a) if isinstance(a, str) else a # eval stringsexcept NameError:passn = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain#此处添加了C3TRif m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,BottleneckCSP, C3, C3TR, C3SPP, C3Ghost]:c1, c2 = ch[f], args[0]if c2 != no: # if not outputc2 = make_divisible(c2 * gw, 8)args = [c1, c2, *args[1:]]#此处添加了C3TRif m in [BottleneckCSP, C3, C3TR, C3Ghost]:args.insert(2, n) # number of repeatsn = 1elif m is nn.BatchNorm2d:args = [ch[f]]elif m is Concat:c2 = sum(ch[x] for x in f)elif m is Detect:args.append([ch[x] for x in f])if isinstance(args[1], int): # number of anchorsargs[1] = [list(range(args[1] * 2))] * len(f)elif m is Contract:c2 = ch[f] * args[0] ** 2elif m is Expand:c2 = ch[f] // args[0] ** 2else:c2 = ch[f]m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # modulet = str(m)[8:-2].replace('__main__.', '') # module typenp = sum(x.numel() for x in m_.parameters()) # number paramsm_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number paramsLOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # printsave.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelistlayers.append(m_)if i == 0:ch = []ch.append(c2)return nn.Sequential(*layers), sorted(save)
3、第三步;修改配置文件(我这里拿yolov5s.yaml举例子),将注意力层加到你想加入的位置;常用的一般是添加到backbone的最后一层,或者C3里面,这里是加在了最后一层
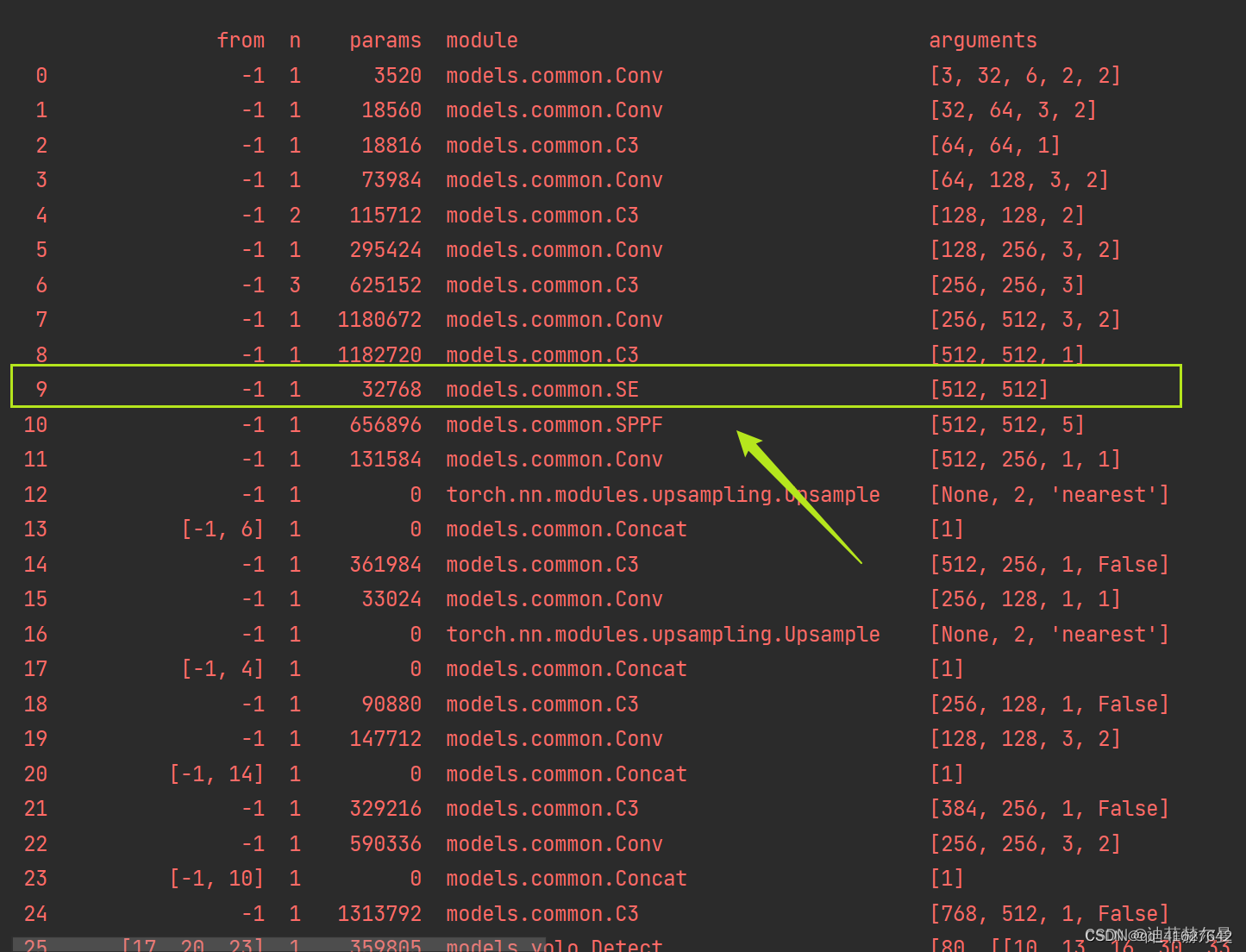
4、当在网络中添加了新的层之后,那么该层网络后续的层的编号都会发生改变,进行对应位置修改
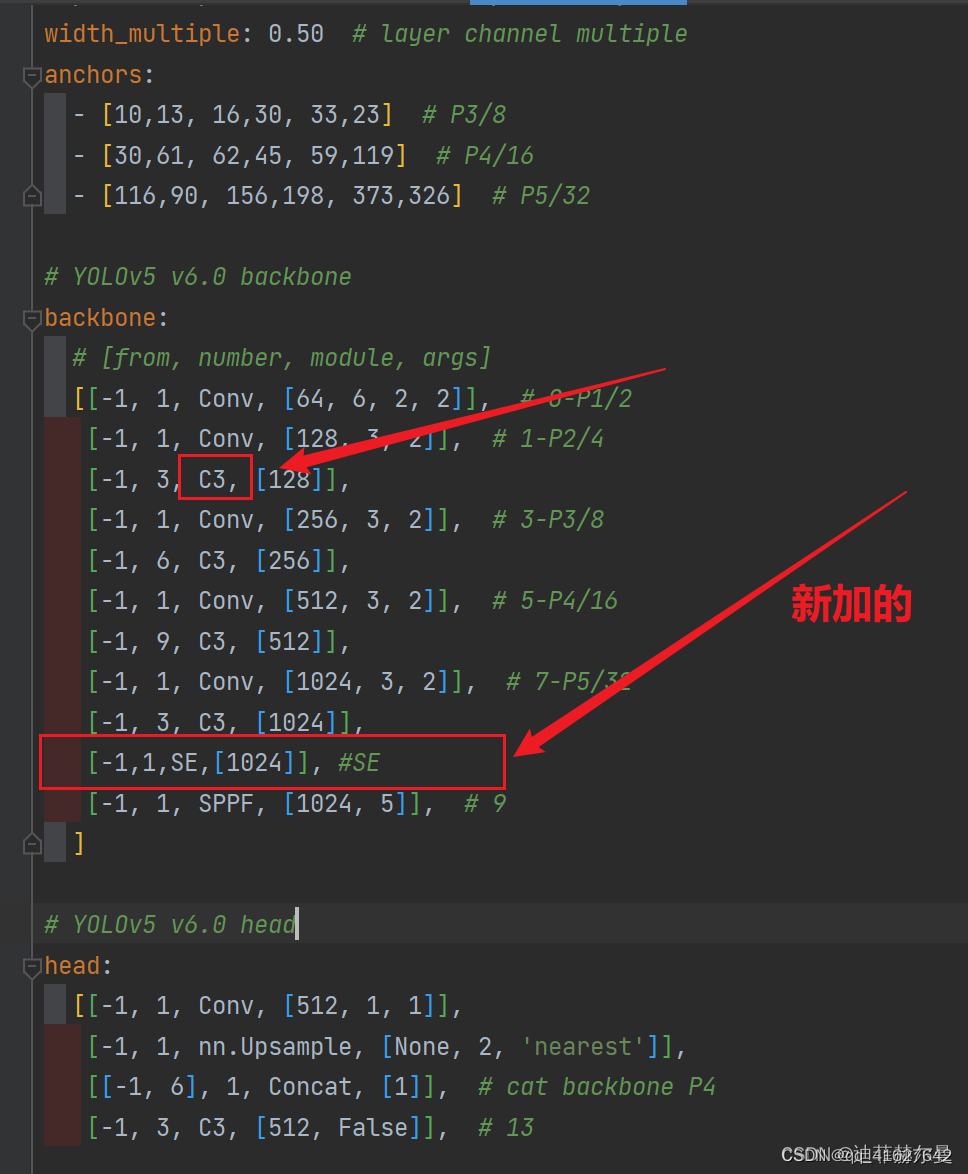
看下图,原本Detect指定的是[ 17 , 20 , 23 ] [17,20,23][17,20,23]层,所以在我们添加了SE注意力层之后也要Detect对这里进行修改,即原来的17 1717层变成了18 1818层;原来的20 2020层变成了21 2121层;原来的23 2323层变成了24 2424层;所以Detecet的from系数要改为[ 18 , 21 , 24 ] [18,21,24][18,21,24]
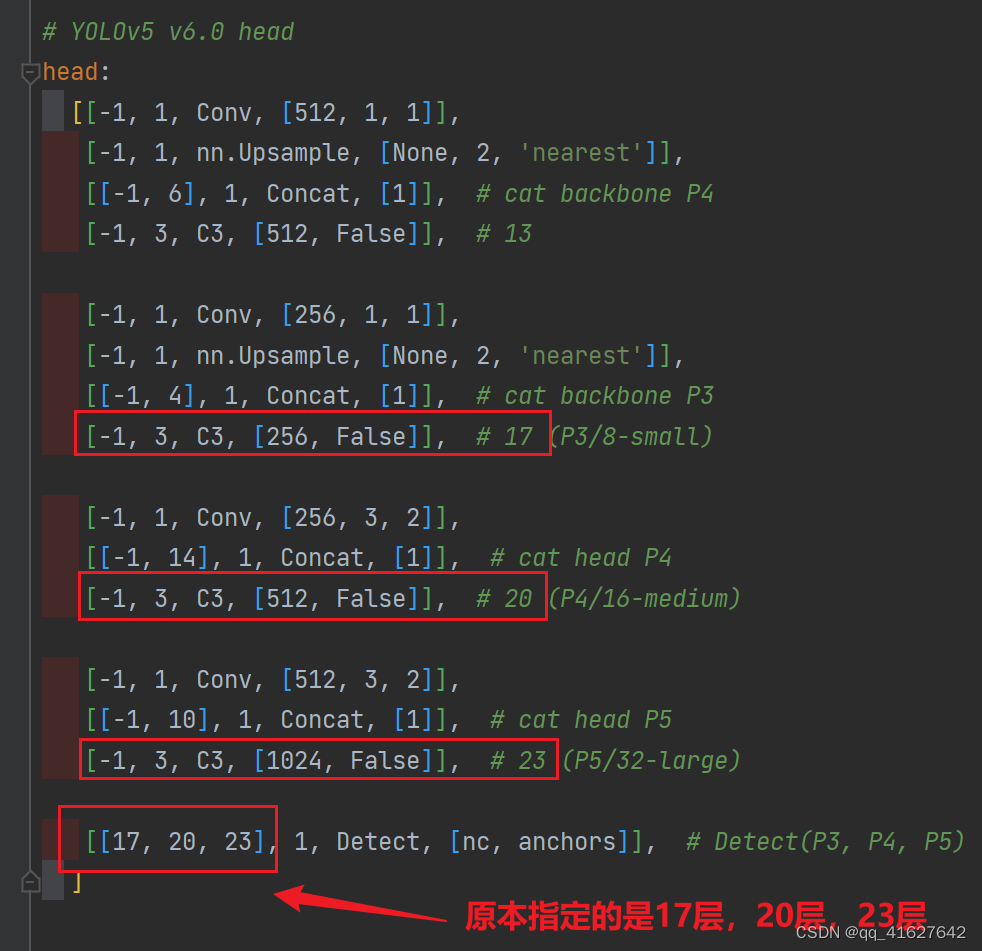
同样的,Concat的from系数也要修改,这样才能保持原网络结构不发生特别大的改变,我们刚才把SE层加到了第9层,所以第9层之后的编号都会加1,这里我们要把后面两个Concat的from系数分别由[ − 1 , 14 ] , [ − 1 , 10 ] [-1,14],[-1,10][−1,14],[−1,10]改为[ − 1 , 15 ] , [ − 1 , 11 ] [-1,15],[-1,11][−1,15],[−1,11]
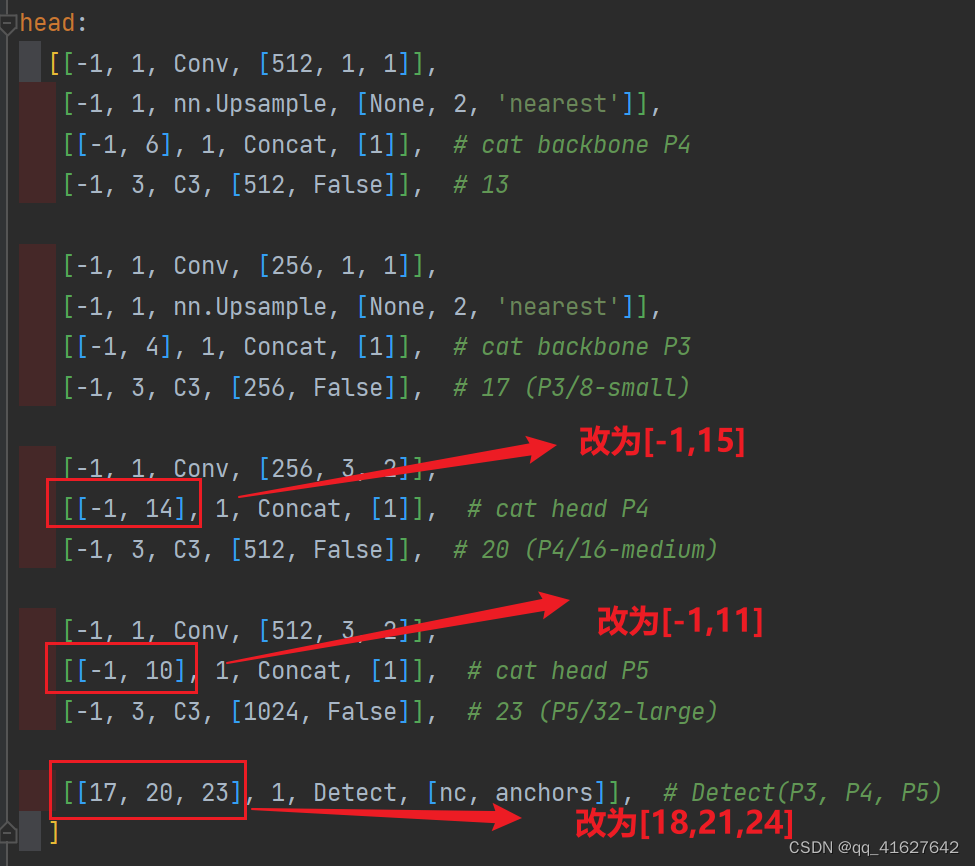
这里放上我加入SE注意力层后完整的配置文件SE.yaml
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone+SE
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1,1,SE,[1024]], #SE[-1, 1, SPPF, [1024, 5]], # 10]# YOLOv5+SE v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 14[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 18 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 15], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 21 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 11], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 24 (P5/32-large)[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]加好了就可以训练了,在运行的时候会看到我们注意力层的位置: