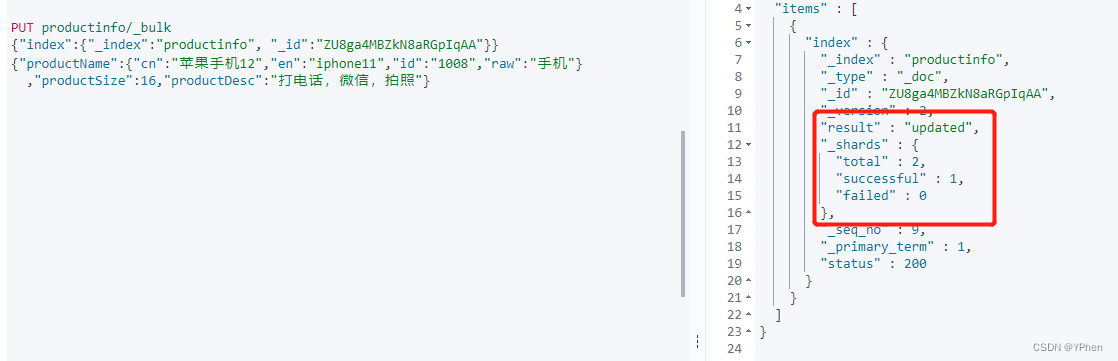
全文检索
数据分类:
- 结构化数据: 固定格式,有限长度 比如mysql存的数据
- 非结构化数据:不定长,无固定格式 比如邮件,word文档,日志
- 半结构化数据: 前两者结合 比如xml,html
搜索分类:
- 结构化数据搜索: 使用关系型数据库
- 非结构化数据搜索
- 顺序扫描
- 全文检索
设想一个关于搜索的场景,假设我们要搜索一首诗句内容中带“前”字的古诗
| name | content | author |
| 静夜思 | 床前明月光,疑是地上霜。举头望明月,低头思故乡。 | 李白 |
| 望庐山瀑布 | 日照香炉生紫烟,遥看瀑布挂前川。飞流直下三千尺,疑是银河落九天。 | 李白 |
| ... | ... | ... |
思考:用传统关系型数据库和ES 实现会有什么差别?
如果用像 MySQL 这样的 RDBMS 来存储古诗的话,我们应该会去使用这样的 SQL 去查询
select name from poems where content like "%前%"
这种我们称为顺序扫描法,需要遍历所有的记录进行匹配。不但效率低,而且不符合我们搜索时的期望,比如我们在搜索“ABCD"这样的关键词时,通常还希望看到"A","AB","CD",“ABC”的搜索结果。
什么是全文检索
全文检索是指:
- 通过一个程序扫描文本中的每一个单词,针对单词建立索引,并保存该单词在文本中的位置、以及出现的次数
- 用户查询时,通过之前建立好的索引来查询,将索引中单词对应的文本位置、出现的次数返回给用户,因为有了具体文本的位置,所以就可以将具体内容读取出来了
搜索原理简单概括的话可以分为这么几步:
- 内容爬取,停顿词过滤比如一些无用的像"的",“了”之类的语气词/连接词
- 内容分词,提取关键词
- 根据关键词建立倒排索引
- 用户输入关键词进行搜索
倒排索引
索引就类似于目录,平时我们使用的都是索引,都是通过主键定位到某条数据,那么倒排索引呢,刚好相反,数据对应到主键。

这里以一个博客文章的内容为例:
正排索引(正向索引)
| 文章ID | 文章标题 | 文章内容 |
| 1 | 浅析JAVA设计模式 | JAVA设计模式是每一个JAVA程序员都应该掌握的进阶知识 |
| 2 | JAVA多线程设计模式 | JAVA多线程与设计模式结合 |
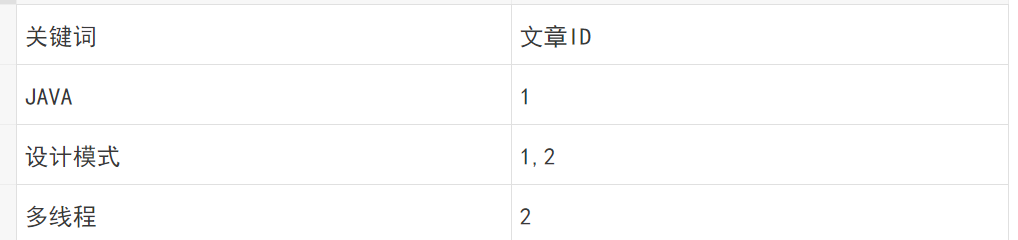
倒排索引(反向索引)
假如,我们有一个站内搜索的功能,通过某个关键词来搜索相关的文章,那么这个关键词可能出现在标题中,也可能出现在文章内容中,那我们将会在创建或修改文章的时候,建立一个关键词与文章的对应关系表,这种,我们可以称之为倒排索引。
like %java设计模式% java 设计模式
| 关键词 | 文章ID |
| JAVA | 1,2 |
| 设计模式 | 1,2 |
| 多线程 | 2 |
简单理解,正向索引是通过key找value,反向索引则是通过value找key。ES底层在检索时底层使用的就是倒排索引。
ElasticSearch简介
ElasticSearch是什么
ElasticSearch(简称ES)是一个分布式、RESTful 风格的搜索和数据分析引擎,是用Java开发并且是当前最流行的开源的企业级搜索引擎,能够达到近实时搜索,稳定,可靠,快速,安装使用方便。
客户端支持Java、.NET(C#)、PHP、Python、Ruby等多种语言。
官方网站: Free and Open Search: The Creators of Elasticsearch, ELK & Kibana | Elastic
下载地址:Past Releases of Elastic Stack Software | Elastic
搜索引擎排名:

参考网站:DB-Engines Ranking - popularity ranking of search engines
起源——Lucene
- 基于Java语言开发的搜索引擎库类
- 创建于1999年,2005年成为Apache 顶级开源项目
- Lucene具有高性能、易扩展的优点
- Lucene的局限性︰
-
- 只能基于Java语言开发
- 类库的接口学习曲线陡峭
- 原生并不支持水平扩展
Elasticsearch的诞生
Elasticsearch是构建在Apache Lucene之上的开源分布式搜索引擎。
- 2004年 Shay Banon 基于Lucene开发了Compass
- 2010年 Shay Banon重写了Compass,取名Elasticsearch
- 支持分布式,可水平扩展
- 降低全文检索的学习曲线,可以被任何编程语言调用
Elasticsearch 与 Lucene 核心库竞争的优势在于:
- 完美封装了 Lucene 核心库,设计了友好的 Restful-API,开发者无需过多关注底层机制,直接开箱即用。
- 分片与副本机制,直接解决了集群下性能与高可用问题。
ES Server进程 3节点 raft (奇数节点)
数据分片 -》lucene实例 分片和副本数 1个ES节点可以有多个lucene实例。也可以指定一个索引的多个分片
ElasticSearch版本特性
5.x新特性
- Lucene 6.x, 性能提升,默认打分机制从TF-IDF改为BM 25
- 支持Ingest节点/ Painless Scripting / Completion suggested支持/原生的Java REST客户端
- Type标记成deprecated, 支持了Keyword的类型
- 性能优化
- 内部引擎移除了避免同一文档并发更新的竞争锁,带来15% - 20%的性能提升
- Instant aggregation,支持分片,上聚合的缓存
- 新增了Profile API
6.x新特性
- Lucene 7.x
- 新功能
- 跨集群复制(CCR)
- 索引生命周期管理
- SQL的支持
- 更友好的的升级及数据迁移
- 在主要版本之间的迁移更为简化,体验升级
- 全新的基于操作的数据复制框架,可加快恢复数据
- 性能优化
- 有效存储稀疏字段的新方法,降低了存储成本
- 在索引时进行排序,可加快排序的查询性能
7.x新特性
- Lucene 8.0
- 重大改进-正式废除单个索引下多Type的支持
- 7.1开始,Security 功能免费使用
- ECK - Elasticseach Operator on Kubernetes
- 新功能
- New Cluster coordination
- Feature——Complete High Level REST Client
- Script Score Query
- 性能优化
- 默认的Primary Shard数从5改为1,避免Over Sharding
- 性能优化, 更快的Top K
8.x新特性
- Rest API相比较7.x而言做了比较大的改动(比如彻底删除_type)
- 默认开启安全配置
- 存储空间优化:对倒排文件使用新的编码集,对于keyword、match_only_text、text类型字段有效,有3.5%的空间优化提升,对于新建索引和segment自动生效。
- 优化geo_point,geo_shape类型的索引(写入)效率:15%的提升。
- 技术预览版KNN API发布,(K邻近算法),跟推荐系统、自然语言排名相关。
- Elasticsearch breaking changes | Elastic Installation and Upgrade Guide [8.2] | Elastic
ElasticSearch vs Solr
Solr 是第一个基于 Lucene 核心库功能完备的搜索引擎产品,诞生远早于 Elasticsearch。
当单纯的对已有数据进行搜索时,Solr更快。当实时建立索引时, Solr会产生io阻塞,查询性能较差, Elasticsearch具有明显的优势。

大型互联网公司,实际生产环境测试,将搜索引擎从Solr转到 Elasticsearch以后的平均查询速度有了50倍的提升。
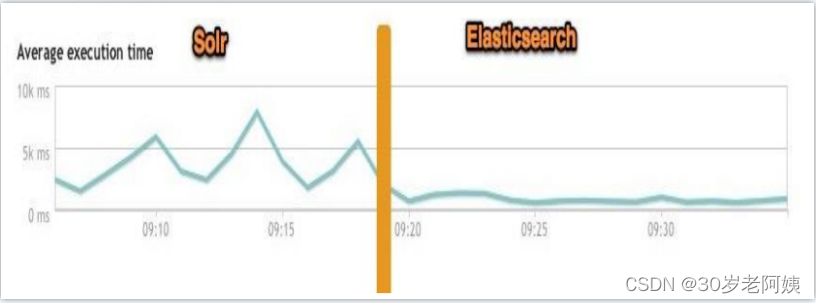
总结:
- Solr 利用 Zookeeper 进行分布式管理,而Elasticsearch 自身带有分布式协调管理功能。
- Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持json文件格式。
- Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch。
- Solr 是传统搜索应用的有力解决方案,但 Elasticsearch更适用于新兴的实时搜索应用。
Elastic Stack介绍
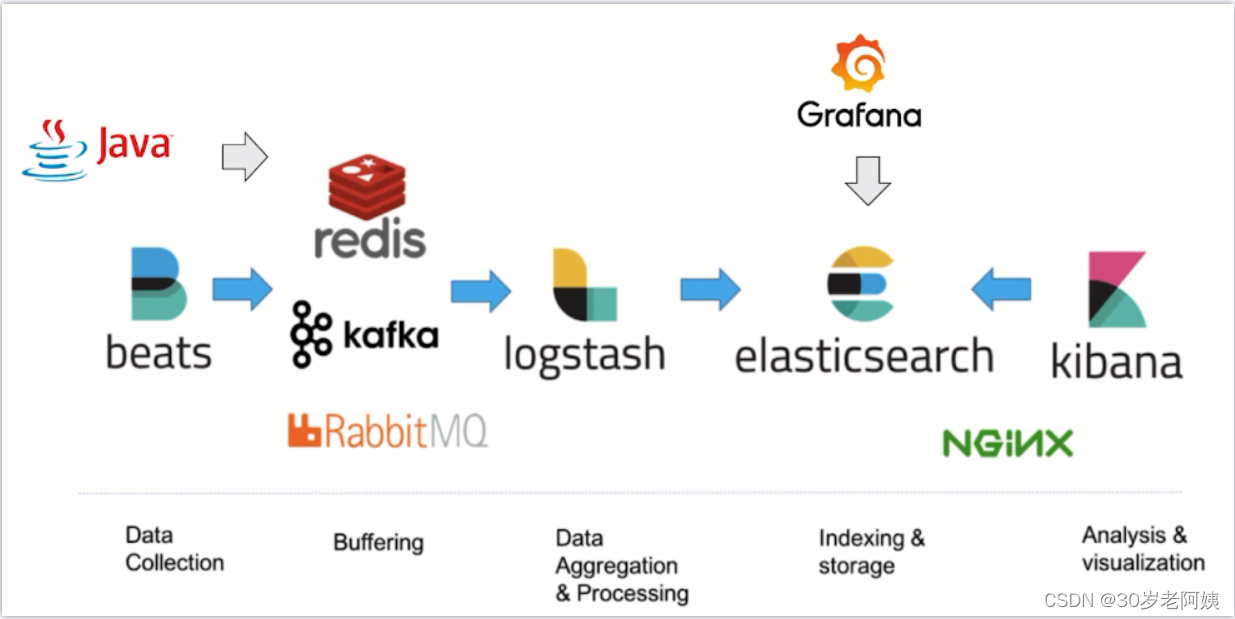
在Elastic Stack之前我们听说过ELK,ELK分别是Elasticsearch,Logstash,Kibana这三款软件在一起的简称,在发展的过程中又有新的成员Beats的加入,就形成了Elastic Stack。
Elastic Stack生态圈
在Elastic Stack生态圈中Elasticsearch作为数据存储和搜索,是生态圈的基石,Kibana在上层提供用户一个可视化及操作的界面,Logstash和Beat可以对数据进行收集。在上图的右侧X-Pack部分则是Elastic公司提供的商业项目。
指标分析/日志分析:
ElasticSearch应用场景
- 站内搜索
- 日志管理与分析
- 大数据分析
- 应用性能监控
- 机器学习
国内现在有大量的公司都在使用 Elasticsearch,包括携程、滴滴、今日头条、饿了么、360安全、小米、vivo等诸多知名公司。除了搜索之外,结合Kibana、Logstash、Beats,Elastic Stack还被广泛运用在大数据近实时分析领域,包括日志分析、指标监控、信息安全等多个领域。它可以帮助你探索海量结构化、非结构化数据,按需创建可视化报表,对监控数据设置报警阈值,甚至通过使用机器学习技术,自动识别异常状况。
通用数据处理流程:

ElasticSearch快速开始
ElasticSearch安装运行
环境准备
- 运行Elasticsearch,需安装并配置JDK
- 设置$JAVA_HOME
- 各个版本对Java的依赖 Support Matrix | Elastic
- Elasticsearch 5需要Java 8以上的版本
- Elasticsearch 从6.5开始支持Java 11
- 7.0开始,内置了Java环境
- ES比较耗内存,建议虚拟机4G或以上内存,jvm1g以上的内存分配
可以参考es的环境文件elasticsearch-env.bat

ES的jdk环境生效的优先级配置ES_JAVA_HOME>JAVA_HOME>ES_HOME
下载并解压ElasticSearch
下载地址: Past Releases of Elastic Stack Software | Elastic
选择版本:7.17.3
ElasticSearch文件目录结构
| 目录 | 描述 |
| bin | 脚本文件,包括启动elasticsearch,安装插件,运行统计数据等 |
| config | 配置文件目录,如elasticsearch配置、角色配置、jvm配置等。 |
| jdk | java运行环境 |
| data | 默认的数据存放目录,包含节点、分片、索引、文档的所有数据,生产环境需要修改。 |
| lib | elasticsearch依赖的Java类库 |
| logs | 默认的日志文件存储路径,生产环境需要修改。 |
| modules | 包含所有的Elasticsearch模块,如Cluster、Discovery、Indices等。 |
| plugins | 已安装插件目录 |
主配置文件elasticsearch.yml
- cluster.name
当前节点所属集群名称,多个节点如果要组成同一个集群,那么集群名称一定要配置成相同。默认值elasticsearch,生产环境建议根据ES集群的使用目的修改成合适的名字。
- node.name
当前节点名称,默认值当前节点部署所在机器的主机名,所以如果一台机器上要起多个ES节点的话,需要通过配置该属性明确指定不同的节点名称。
- path.data
配置数据存储目录,比如索引数据等,默认值 $ES_HOME/data,生产环境下强烈建议部署到另外的安全目录,防止ES升级导致数据被误删除。
- path.logs
配置日志存储目录,比如运行日志和集群健康信息等,默认值 $ES_HOME/logs,生产环境下强烈建议部署到另外的安全目录,防止ES升级导致数据被误删除。
- bootstrap.memory_lock
配置ES启动时是否进行内存锁定检查,默认值true。
ES对于内存的需求比较大,一般生产环境建议配置大内存,如果内存不足,容易导致内存交换到磁盘,严重影响ES的性能。所以默认启动时进行相应大小内存的锁定,如果无法锁定则会启动失败。
非生产环境可能机器内存本身就很小,能够供给ES使用的就更小,如果该参数配置为true的话很可能导致无法锁定内存以致ES无法成功启动,此时可以修改为false。
- network.host
配置能够访问当前节点的主机,默认值为当前节点所在机器的本机回环地址127.0.0.1 和[::1],这就导致默认情况下只能通过当前节点所在主机访问当前节点。可以配置为 0.0.0.0 ,表示所有主机均可访问。
- http.port
配置当前ES节点对外提供服务的http端口,默认值 9200
- discovery.seed_hosts
配置参与集群节点发现过程的主机列表,说白一点就是集群中所有节点所在的主机列表,可以是具体的IP地址,也可以是可解析的域名。
- cluster.initial_master_nodes
配置ES集群初始化时参与master选举的节点名称列表,必须与node.name配置的一致。ES集群首次构建完成后,应该将集群中所有节点的配置文件中的cluster.initial_master_nodes配置项移除,重启集群或者将新节点加入某个已存在的集群时切记不要设置该配置项。
#ES开启远程访问 network.host: 0.0.0.0
修改JVM配置
修改config/jvm.options配置文件,调整jvm堆内存大小
vim jvm.options -Xms4g -Xmx4g
配置的建议
- Xms和Xms设置成—样
- Xmx不要超过机器内存的50%
- 不要超过30GB - A Heap of Trouble: Managing Elasticsearch's Managed Heap | Elastic Blog