ElasticSearch的作用
ElasticSearch属于Nosql,是一款非关系型数据库,主要用于数据的全文检/搜索
Mysql不具备快速搜索海量数据的能力.
强事务控制
redis做数据缓存,降低mysql的压力
数据库排行榜: https://db-engines.com/en/
ElasticSearch引入倒排索引技术,来解决传统关系型数据库无法快速搜索海量数据的能力,ES的特性就是利用索引进行快速的查询,对于ES技术,“万物皆索引”来形容可以说是最为贴切了;
传统的关系型数据库的查找流程,即遍历查找,假若我们现在拥有500w个数据需要检索,直接拜拜;
ES提供了倒排索引的机制,对比形象的理解的就是新华字典里,我们通过前面的偏旁部首和拼音,可以很快就找到我们不认识的汉字,想想如果这种搜索方式不存在,那我们需要一个字一个字查找整本约9w字的新华字典!这个耗时是无法接受的;
检索数据流程

ES的底层
ES的底层同样来自给这个世界带来无限可能的Apache公司,Apache早前提供了一套用于全文检索和搜寻的开源程序库,Lucene;
Lucene提供了一个简单却强大的应用程序接口(API),能够做全文索引和搜寻,在Java开发环境里Lucene是一个成熟的免费开放源代码工具;
面向服务编程:
ElasticSearch是一个web服务,当ElasticSearch启动时,就相当于启动了一个web项目,直接通过浏览器访问即可.遵循RestFul风格的路径,返回json格式的数据
安装与使用
傻瓜式安装然后双击elasticsearch.bat文件即可启动。可以看到日志中的IP和端口信息:

Kibana
ElasticSearch是一个web服务,但是没有提供图形化界面来操作。因此我们需要安装Kibana,方便学习。
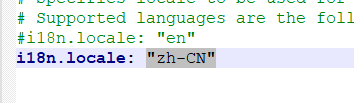
中文界面需要进入其配置文件config→kibana.yml中,配置"zh-CN"
ES-headmaster
ES-headmaster是一个可视化的ES数据库界面,通过访问端口,我们可以监控我们的数据信息;
安装时必须提供node.js软件,解压后,cmd→cnpm install→npm start


分词器
我们需要引入中文分词器来使用ES技术;
解压后,将ik文件夹放在ES的plugins文件夹下;

动态模板
基本语法
默认映射规则不一定符合我们的需求,我们可以按照自己的方式来定义默认规则。这就需要用到动态模板了。
动态模板的语法:

- 模板名称,随便起
- 匹配条件,凡是符合条件的未定义字段,都会按照这个mapping中的规则来映射,匹配规则包括:
match_mapping_type:按照数据类型匹配,如:string匹配字符串类型,long匹配整型match和unmatch:按照名称通配符匹配,如:t_*匹配名称以t开头的字段
- 映射规则,匹配成功后的映射规则
凡是映射规则中未定义,而符合2中的匹配条件的字段,就会按照3中定义的映射方式来映射
示例
# 动态模板
PUT heima3
{"mappings": {"properties": {"title": {"type": "text","analyzer": "ik_max_word"}},"dynamic_templates": [{"strings": {"match_mapping_type": "string","mapping": {"type": "keyword"}}}]}
}
这个动态模板的意思是:凡是string类型的字段,统一按照 keyword来处理。
接下来新增一个数据试试:
POST /heima3/_doc/1{
"title":"超大米手机",
"images":"http://image.leyou.com/12479122.jpg", "price":3299.00}
然后查看映射:
GET /heima3/_mapping
结果:
{"heima3" : {"mappings" : {"dynamic_templates" : [{"strings" : {"match_mapping_type" : "string","mapping" : {"type" : "keyword"}}}],"properties" : {"images" : {"type" : "keyword"},"price" : {"type" : "float"},"title" : {"type" : "text","analyzer" : "ik_max_word"}}}}
}路由计算&分片控制
我们在ES中进行插入和查询数据的时候,是遵循一种被称为路由计算的规则
的;
这种规则也是为什么ES的主分片决定好之后就无法再修改,但是副本却可以动态修改的原因;
因为主分片是查询数据的关键,我们需要通过主分片数来决定数据存储的位置,而副本只是起到备份的作用,所有的数据还是围绕着主分片进行的,如果我们允许动态修改主分片数,那么路由运算就会被打乱,这将造成此前已经插入的数据无法查询到的窘境;
路由计算:hash(id)%主分片数量=对应的主分片所以库
我们在查询的时候,因为ES集群的主副特性,其实查任意一个node都是没有问题的,但是有时候某些node太忙了,那这个时候此node就会转移请求给别的空闲的node,这就是我们说的ES在查询数据时实施的策略,分片控制,以轮询的概念,负载均衡访问的数量给每个节点;
高亮搜索的实现
高亮是在搜索结果中把搜索关键字标记出来,因此必须使用match这样的条件搜索。
elasticsearch中实现高亮的语法比较简单:
GET /heima/_search
{"query": {"match": {"title": "手机"}},"highlight": {"pre_tags": "<em>","post_tags": "</em>", "fields": {"title": {}}}
}
Source筛选
默认情况下,elasticsearch在搜索的结果中,会把文档中保存在_source的所有字段都返回。
如果我们只想获取其中的部分字段,我们可以添加_source的过滤
直接指定字段
示例:
GET /heima/_search
{"_source": ["title","price"],"query": {"term": {"price": 2699}}
}
返回的结果:
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "heima","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"price" : 2699.0,"title" : "小米手机"}}]}
}
指定includes和excludes
我们也可以通过:
- includes:来指定想要显示的字段
- excludes:来指定不想要显示的字段
二者都是可选的。
示例:
GET /heima/_search
{"_source": {"includes":["title","price"]},"query": {"term": {"price": 2699}}
}
与下面的结果将是一样的:
GET /heima/_search
{"_source": {"excludes": ["images"]},"query": {"term": {"price": 2699}}
}
Docker中设置开机自启指令
ES集群
-
什么是集群?为什么需要ES集群?
集群可以简单理解为多台服务器,以ES为例,作为一个非关系型数据库,用户在访问的时候,加入我们的服务器宕机了,很可能因此就失去了这个用户,为了保证服务的高可用,我们为ES建立一个集群,这样,在某台服务器宕机的时候,我们就可以保证用户依然能够正常进行访问等业务; -
那服务器配多少台比较合适呢?
服务器配置的数量,从经验上讲,我们应该配置的总数量一定要呈单数,因为服务器理论上要符合50%原则,即宕机数不能超过服务器数量的一半,如果超过了,除了硬件问题等无法预知的事件,其实就是集群搭建是不合理的,服务器数量保持在单数,可以很好的规避一半原则; -
配置这么多台服务器,我们的数据每台都放吗?还是有其它的解决方案,因为如果每台都放,成本会太大了吧,能说说看吗?
对于这个事情,以ES集群为例,我们可以采用数据分片的分布式存储方式来解决,就好比一本新华字典的结果页分成等额的份,分别存储在各节点上; -
如果一个服务器宕机,数据不就不完整了吗,这要怎么解决呢?
这个时候,我们一般在采用分布式存储的方案的同时,还会进行数据备份,数据备份如果是以ES集群为例,两两备份是常见的解决方案,相邻的节点间互相备份,来解决这个问题; -
那两两宕机的话,如果连着很多个服务器都宕机呢,这要怎么解决?
两两节点的备份是大部分中小型公司采用的数据备份方式,由于成本原因,这是相对较好的解决方式,剩下的就是要看公司的预算以及某些数据的重要性来选择是否多重备份了; -
ES集群中的节点概念
节点node就是指ES本身,ES集群本身指的就是多个ES开启运行,每运行一个ES,就代表此ES作为一个节点在集群中发布;
单节点集群
单节点集群其实并不能成为集群,因为节点只有一个,集群应该是要至少两台ES服务器在运行才能成为集群,群是复数;
- 单节点集群会即运行主分片的索引库,又运行主分片副本的索引库吗?
如果是单节点集群,还会出现一个尴尬的局面,那就是节点索引主分片的副本不会被运行,因为只有一个节点,主分片是可以正常运行的,而副本分片,是不允许在其所属的主分片中运行的,副本副本,本来就是为了高可用备份出来的东西,怎么可能一个节点运行自己的索引库两次或者多次呢?这是错误的,副本节点的出生就是由ES自动分配到其他节点上进行运行的;
单节点运行如下图:
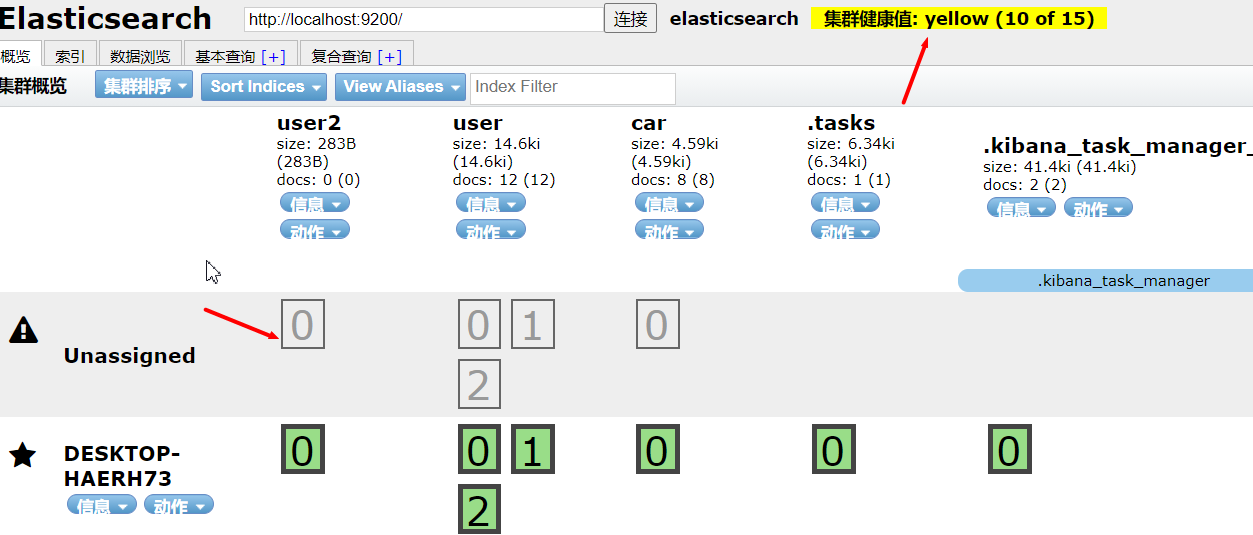
健康值是yellow代表主分片索引正常运行,但由于是单节点,其主分片副本无法分配至其他节点运行,呈灰色,一共有5个,所以就表示,这个节点挂了的话,这些数据信息将直接无法被访问;
Unassigned意为当前节点没用被分配到任何节点;
多节点集群
启动多一个节点时,如下图:
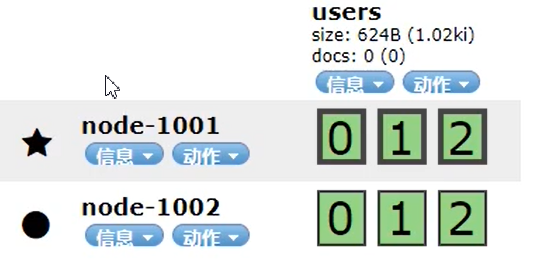

新的node2中,副本开始运行了,如何分辨副本与主分片,分片数据边框加粗的就是主分片索引库,没用加粗的就是副本;
健康值也变成了green;
其中有一个需要注意的就是,ES自动选择了node1为master节点,从图中是可以看出来的,因为node1边上标记了☆,而从节点node2则是正常的●;
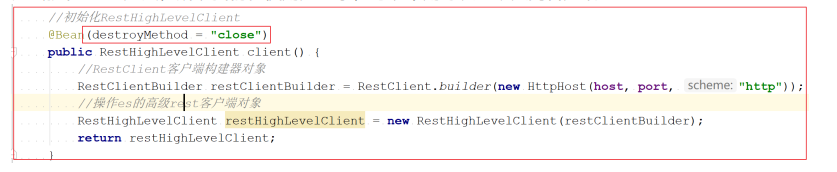
Java中连接ES
创建客户端来建立连接
private RestHighLevelClient client;/*** 建立连接*/@Beforepublic void init() throws IOException {client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));}/*** 关闭客户端连接*/@Afterpublic void close() throws IOException {client.close();}
创建索引库:
@Testpublic void test01Index() throws IOException {//1.创建请求对象 (指定索引库)CreateIndexRequest request = new CreateIndexRequest("user1");//2.描述本次请求的语义//request.settings(Settings.builder()// .put("index.number_of_shards", 3)// .put("index.number_of_replicas", 2)//);//3.发送请求给ES,并接收响应结果CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);//4.处理响应结果,并关闭客户端对象System.out.println(createIndexResponse);System.out.println(createIndexResponse.isAcknowledged());}
查看索引库:
// 查看索引库@Testpublic void test03Index() throws IOException {//1.创建请求对象 (指定索引库)indexGetIndexRequest request = new GetIndexRequest("user2");//发送请求GetIndexResponse getIndexResponse = client.indices().get(request, RequestOptions.DEFAULT);// 获取索引库的 属性映射信息Map<String, MappingMetaData> mappings = getIndexResponse.getMappings();MappingMetaData metaData = mappings.get("user2");Map<String, Object> map = metaData.sourceAsMap();System.out.println(map);// 获取索引库的配置信息Map<String, Settings> settings = getIndexResponse.getSettings();Settings user2 = settings.get("user2");System.out.println(user2.getAsGroups());System.out.println(getIndexResponse);}
删除索引库:
// 删除索引库@Testpublic void test04Index() throws IOException {DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("user1");AcknowledgedResponse response = client.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);System.out.println(response.isAcknowledged());}Java中实现ES文档的CRUD
新增文档:
@Testpublic void docPost1() throws IOException {IndexRequest request = new IndexRequest("user");request.id("2");String jsonString = "{\n" +" \"age\" : 18,\n" +" \"gender\" :\"女\",\n" +" \"name\" : \"大幂幂\",\n" +" \"note\" : \"我好美啊.\"\n" +"}";request.source(jsonString, XContentType.JSON);IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);System.out.println(indexResponse.status());}
从数据库查询并新增至ES文档:
@Testpublic void docPost2() throws IOException {User user = userService.findById(12L);System.out.println(user);IndexRequest request = new IndexRequest("user");// 设置添加的文档id值//request.id(user.getId().toString());request.id("1");// 设置文档数据信息String jsonString = JSON.toJSONString(user);System.out.println(jsonString);request.source(jsonString, XContentType.JSON);IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);//System.out.println(indexResponse.status());System.out.println(indexResponse.getResult());}
实现修改:
@Testpublic void docUpdate() throws IOException {UpdateRequest request = new UpdateRequest("user","1");// 设置需要修改的字段信息request.doc("name","宋广洋");UpdateResponse updateResponse =client.update(request, RequestOptions.DEFAULT);System.out.println(updateResponse.getResult());}
删除:
@Testpublic void docDelete() throws IOException {DeleteRequest request = new DeleteRequest("user", "1");DeleteResponse deleteResponse = client.delete(request, RequestOptions.DEFAULT);System.out.println(deleteResponse.getResult());}
批量添加:
/*** 批量添加* @throws IOException*/@Testpublic void docBulk() throws IOException {// 查询mysql中的数据信息List<User> userList = service.findAll();BulkRequest request = new BulkRequest("user");for (User user : userList) {IndexRequest indexRequest = new IndexRequest();indexRequest.id(user.getId().toString());String userJson = JSON.toJSONString(user);indexRequest.source(userJson,XContentType.JSON);request.add(indexRequest);}BulkResponse bulkResponse = client.bulk(request, RequestOptions.DEFAULT);System.out.println(bulkResponse.status());}
可以在Kibana中查看ES的数据情况:
首先点击这个按钮的时候,会出现索引模式的超链接,点击建立想要图形化展示的索引库,然后刷新再次点击就会出现以下界面(需要注意的是,之前的数据不会同步,刷新也不会,如果想要实时的所有数据,还是要导入es-headmaster插件来监控):
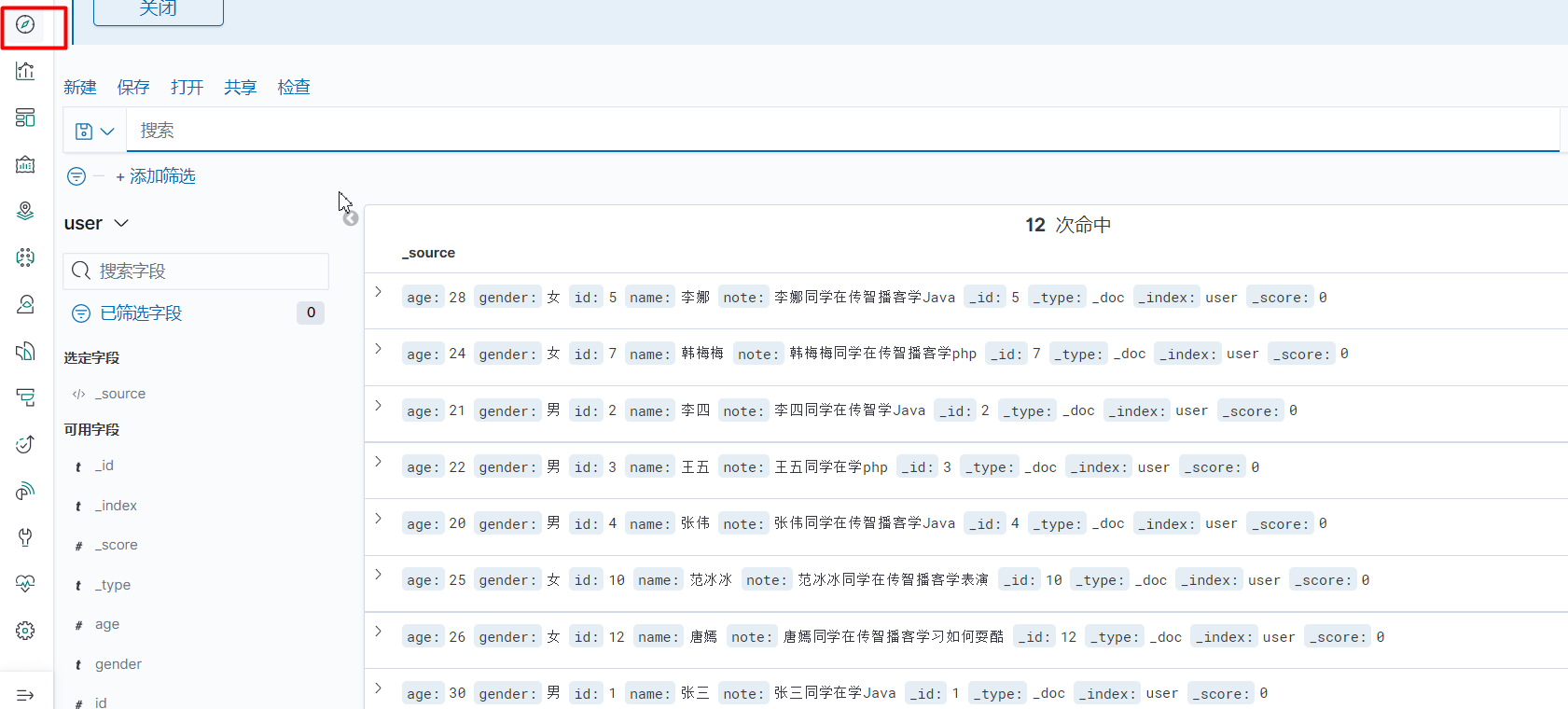
查询:
查询所有:
@Testpublic void searchAll() throws IOException {//TODO:1.创建查询请求对象SearchRequest searchRequest = new SearchRequest("user");//TODO:2.构建查询语义//创建搜索对象,用于构建搜索条件SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();// 指定搜索方式 查询所有 分词查询 词条查询 范围查询 bool查询searchSourceBuilder.query(QueryBuilders.matchAllQuery());// 将查询语义,存放到当前请求对象中searchRequest.source(searchSourceBuilder);//TODO:3.发送请求SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);SearchHits hits = searchResponse.getHits();System.out.println("总条数: "+hits.getTotalHits().value);SearchHit[] hitsHits = hits.getHits();for (SearchHit hit : hitsHits) {String userStr = hit.getSourceAsString();System.out.println(userStr);User user = JSON.parseObject(userStr, User.class);System.out.println(user);}}
分词查询:
@Testpublic void testBasicSearch() throws IOException {// TODO:1.创建请求对象SearchRequest request = new SearchRequest("user");// TODO:2.创建语义对象 - 分词查询SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();sourceBuilder.query(QueryBuilders.matchQuery("note", "唱歌表演"));request.source(sourceBuilder);// TODO:3.发起请求,得到结果SearchResponse searchResponse = client.search(request, RequestOptions.DEFAULT);// TODO:4.解析SearchHits hits = searchResponse.getHits();System.out.println("总条数: "+hits.getTotalHits().value);SearchHit[] hitsHits = hits.getHits();for (SearchHit hit : hitsHits) {String userStr = hit.getSourceAsString();//System.out.println(userStr);User user = JSON.parseObject(userStr, User.class);System.out.println(user);}}
布尔查询
BooleanQuery就是布尔查询,需要把其它几个查询用must、must_not组合,另外过滤条件最好使用filter来实现。比如:
// 布尔查询
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
// 添加must条件
queryBuilder.must(QueryBuilders.matchQuery("note", "唱歌表演"));
// 添加filter条件,不参与打分
queryBuilder.filter(QueryBuilders.rangeQuery("age").gte(18).lte(24));
sourceBuilder.query(queryBuilder);
完整代码:
@Testpublic void search4() throws IOException {// TODO:1.创建请求对象SearchRequest searchRequest = new SearchRequest("user");// TODO:2.构建语义对象// =====构建bool查询的具体语义// 构建检索语义SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();// 布尔检索BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();// 添加must条件//queryBuilder.must(QueryBuilders.matchQuery("note", "唱歌表演"));queryBuilder.must(QueryBuilders.matchQuery("gender", "女"));// 添加filter条件,不影响分值queryBuilder.filter(QueryBuilders.rangeQuery("age").gte(18).lte(24));sourceBuilder.query(queryBuilder);//=======searchRequest.source(sourceBuilder);//TODO:3.发送请求SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);// TODO:4.解析SearchHits hits = searchResponse.getHits();System.out.println("总条数: "+hits.getTotalHits().value);SearchHit[] hitsHits = hits.getHits();for (SearchHit hit : hitsHits) {String userStr = hit.getSourceAsString();//System.out.println(userStr);User user = JSON.parseObject(userStr, User.class);System.out.println(user);}}
过滤
在原来搜索的基础上,通过SearchSourceBuilder的fetchSource(String[] includes, String[] excludes)方法实现:
- includes:包含的字段
- excludes:要排除的字段
代码:
// 2.source过滤,指定includes,只要id、name、note
sourceBuilder.fetchSource(new String[]{"id", "name", "note"}, new String[0]);
完整代码:
@Testpublic void testBasicSearch1() throws IOException {// TODO:1.创建请求对象SearchRequest searchRequest = new SearchRequest("user");// TODO:2.构建语义对象// =====构建bool查询的具体语义// 构建检索语义SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();// 参数1: 需要展示的字段// 参数2: 排除的字段sourceBuilder.fetchSource(new String[0], new String[]{"id", "name", "note"});// 布尔检索BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();// 添加must条件//queryBuilder.must(QueryBuilders.matchQuery("note", "唱歌表演"));queryBuilder.must(QueryBuilders.matchQuery("gender", "女"));// 添加filter条件,不影响分值queryBuilder.filter(QueryBuilders.rangeQuery("age").gte(18).lte(24));sourceBuilder.query(queryBuilder);//=======searchRequest.source(sourceBuilder);//TODO:3.发送请求SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);// TODO:4.解析SearchHits hits = searchResponse.getHits();System.out.println("总条数: "+hits.getTotalHits().value);SearchHit[] hitsHits = hits.getHits();for (SearchHit hit : hitsHits) {String userStr = hit.getSourceAsString();//System.out.println(userStr);User user = JSON.parseObject(userStr, User.class);System.out.println(user);}}
排序&分页
通过SearchSourceBuilder的sort(String, SortOrder)方法用来实现排序条件的封装:
/*** Adds a sort against the given field name and the sort ordering.** @param name The name of the field,排序字段名称* @param order The sort ordering,排序的方式*/
public SearchSourceBuilder sort(String name, SortOrder order) {// ...
}
在原由查询的基础上,给SearchSourceBuilder中添加sort即可:
// 1.2.添加排序条件sourceBuilder.sort("id", SortOrder.ASC);
完整代码如下:
/*** order* SearchSourceBuilder: 构建具体的查询条件* - query(QueryBuilder):查询条件* - sort(String, SortOrder):排序条件* - from(int)和size(int):分页条件* - highlight(HighlightBuilder):高亮条件* - aggregation(AggregationBuilder):聚合条件*/@Testpublic void searchOrder() throws IOException {// TODO:1.创建请求对象SearchRequest searchRequest = new SearchRequest("user");// TODO:2.描述查询的语义// 构建查询条件 五大类SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.query(QueryBuilders.matchAllQuery());// TODO:分页searchSourceBuilder.from(0);searchSourceBuilder.size(100);// TODO:排序//searchSourceBuilder.sort(new ScoreSortBuilder().order(SortOrder.DESC));searchSourceBuilder.sort(new FieldSortBuilder("id").order(SortOrder.ASC));// 将查询条件对象赋给查询语义对象searchRequest.source(searchSourceBuilder);// TODO:3.发送请求查询SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);// TODO:4.解析SearchHits hits = searchResponse.getHits();System.out.println("总条数: "+hits.getTotalHits().value);SearchHit[] hitsHits = hits.getHits();for (SearchHit hit : hitsHits) {String userStr = hit.getSourceAsString();//System.out.println(userStr);User user = JSON.parseObject(userStr, User.class);System.out.println(user);}}
高亮
高亮需要在SearchSourceBuilder的highlighter()方法来实现:
// 2.高亮,指定高亮字段
sourceBuilder.highlighter(new HighlightBuilder().field("note"));
完整代码:
@Test
public void testHighlight() throws IOException {// 1.创建SearchSourceBuilder对象SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();// 1.1.添加查询条件QueryBuilderssourceBuilder.query(QueryBuilders.matchQuery("note", "唱歌表演"));// 2.高亮,指定高亮字段sourceBuilder.highlighter(new HighlightBuilder().field("note"));// 3.创建SearchRequest对象,并制定索引库名称SearchRequest request = new SearchRequest("user");// 4.添加SearchSourceBuilder对象到SearchRequest对象中request.source(sourceBuilder);// 5.发起请求,得到结果SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 6.解析结果SearchHits searchHits = response.getHits();// 6.1.获取总条数long total = searchHits.getTotalHits().value;System.out.println("total = " + total);// 6.2.获取SearchHits数组,并遍历SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {// - 获取其中的`_source`,是JSON数据String json = hit.getSourceAsString();// - 把`_source`反序列化为User对象User user = JSON.parseObject(json, User.class);System.out.println("user = " + user);}
}
Java实现聚合
举例,假如对性别字段gender做聚合,代码如下:
sourceBuilder.aggregation(AggregationBuilders.terms("gender_agg").field("gender"));
- terms(String):确定聚合类型是Term类型
- term(“gender_agg”):给聚合起个名字,要唯一,获取聚合结果以名称获取。
- field(“gender”):确定要聚合的字段名称,这里是gender
完整代码:
/*** 聚合* @throws IOException*/@Testpublic void searchAggs() throws IOException {// TODO:1.创建请求对象SearchRequest searchRequest = new SearchRequest("user");// TODO:2.描述查询的语义// 构建查询条件SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.query(QueryBuilders.matchAllQuery());// TODO:聚合分桶searchSourceBuilder.aggregation(AggregationBuilders.terms("gender_agg_name").field("gender"));// 将查询条件对象赋给查询语义对象searchRequest.source(searchSourceBuilder);// TODO:3.发送请求查询SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);//TODO:4.解析SearchHits hits = searchResponse.getHits();System.out.println("总条数: "+hits.getTotalHits().value);SearchHit[] hitsHits = hits.getHits();for (SearchHit hit : hitsHits) {String userStr = hit.getSourceAsString();//System.out.println(userStr);User user = JSON.parseObject(userStr, User.class);System.out.println(user);}System.out.println("===============================");// 解析结果Aggregations aggregations = searchResponse.getAggregations();// 根据桶名获取数据信息Terms terms = aggregations.get("gender_agg_name");List<? extends Terms.Bucket> buckets = terms.getBuckets();for (Terms.Bucket bucket : buckets) {// 6.4.获取keyString key = bucket.getKeyAsString();System.out.println("key = " + key);// 6.5.获取countlong count = bucket.getDocCount();System.out.println("count = " + count);}}
ES调优
硬件选择
1.选择SSD(固态硬盘),ES底层Lucene所有的数据都是存储在本地的磁盘中,为什么不选择机械硬盘是因为机械硬盘是使用坚硬的旋转盘片为基础的电脑存储设备,依赖于旋转的机械马达的驱动,速度的提高会带来发热、磨损等问题;
2.选择RAID 0,条带化RAID会提高磁盘I/O,但是代价就是一块硬盘故障时,整个就都故障了;
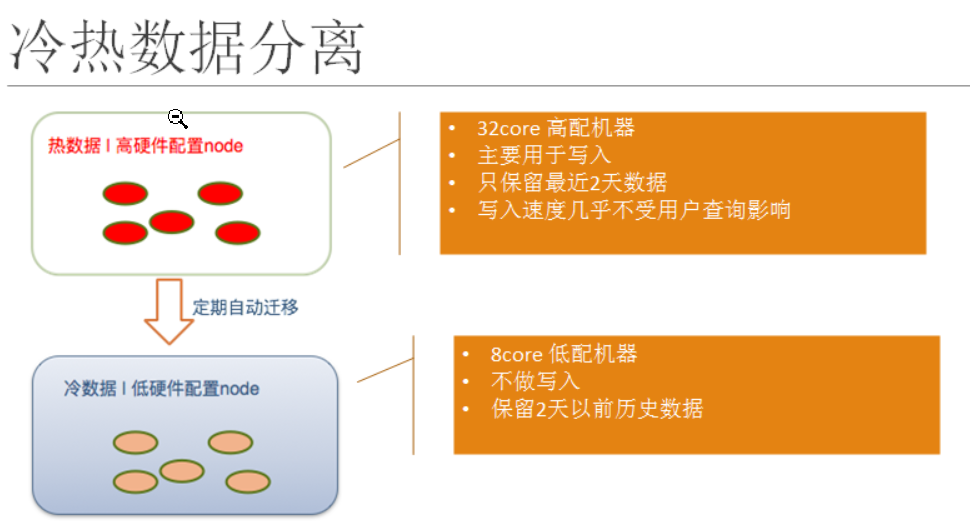
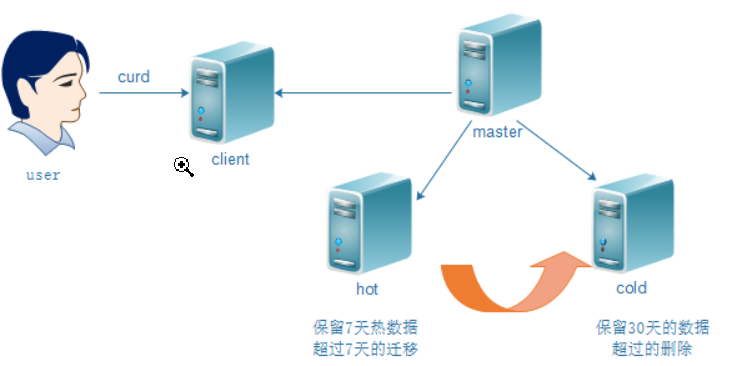
数据冷热分离(Allocate)
ES对于初学者而言,很多时候的场景只创建了一个索引库,并且学习用的那点数据都一股脑放在一个库中;
但是在企业中,我们会经常的面临这样一个现象就是很多时候用户大量访问的是最近一周至一个月的数据,这个时候为了保证服务效率,我们可以对ES采用冷热分离来解决这个问题,就像下图中描述的,把近期的数据放在更好的机器中,以此达到服务最佳的效果,而不常用的数据则直接作为冷数据放在低配置的机器中保存即可;
查询速度:hot>warm>cold>snapshot;