开始头大,哈哈,这个东西真的很无聊且枯燥,奈何最近的学习中经常用到这些知识,还是过一遍比较放心。上一篇博客中我们讨论了http报文首部,其划分为请求头和响应头。请求头主要由请求行、请求字段、通用字段、实体字段组成,那么响应头也由响应行、响应首部字段、通用首部字段、实体首部字段等组成。
这些字段都有不同的用途, 每一个字段还有自己不同的指令,所以整体看起来还是有一些繁杂,不过没关系,一遍留个映像,大家在后续的持续学习中,会对经常用到的几个字段加以掌握深化就行。
1. 响应首部字段
响应首部字段是由服务器端向客户端返回响应报文中所使用的字段,用于补充响应的附加信息、服务器信息,以及对客户端的附加要求等信息。
1.1 Accept-Ranges
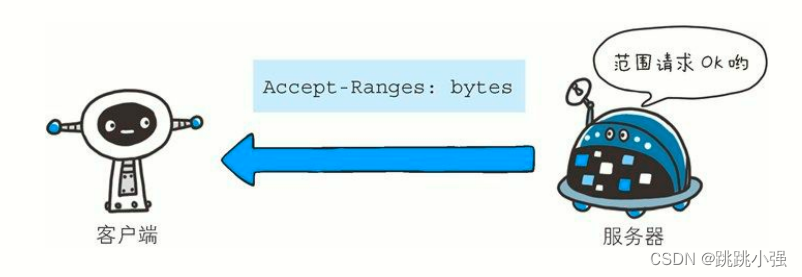
Accept-Ranges: bytes
首部字段 Accept-Ranges 是用来告知客户端服务器是否能处理范围请求,以指定获取服务器端某个部分的资源。
可指定的字段值有两种,可处理范围请求时指定其为 bytes,反之则指定其为 none。
1.2 Age
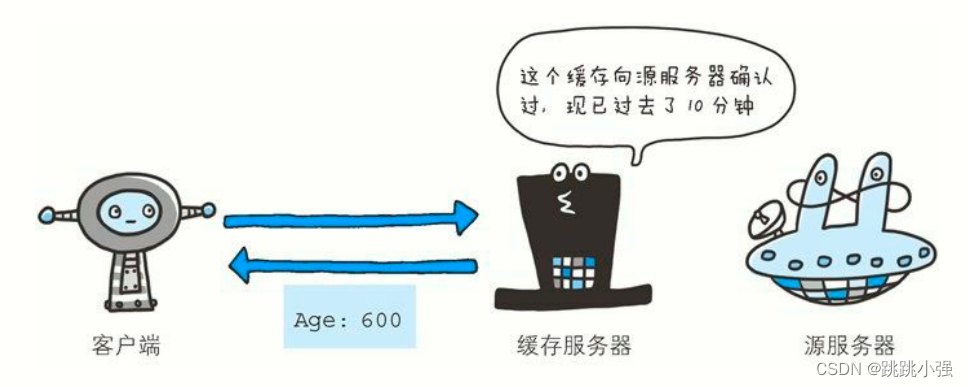
Age: 600
首部字段 Age 能告知客户端,源服务器在多久前创建了响应。字段值的单位为秒。
若创建该响应的服务器是缓存服务器,Age 值是指缓存后的响应再次发起认证到认证完成的时间值。代理创建响应时必须加上首部字段Age。
1.3 ETag
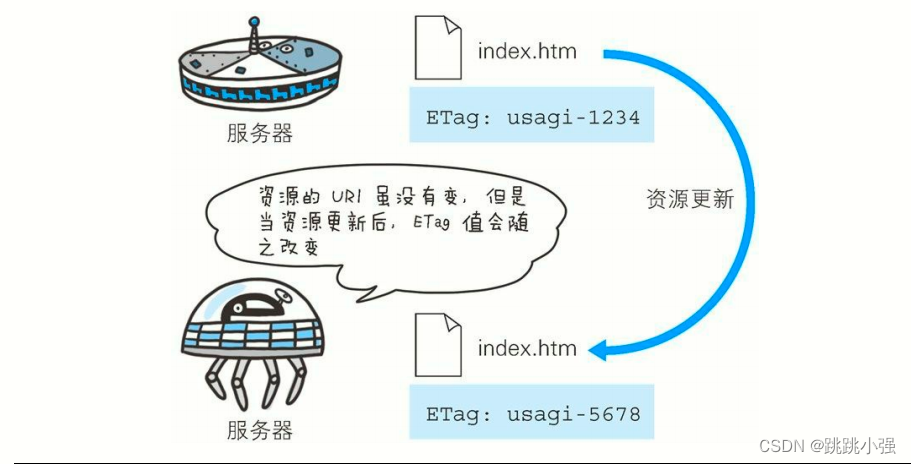
ETag: "82e22293907ce725faf67773957acd12"
首部字段 ETag 能告知客户端实体标识。它是一种可将资源以字符串形式做唯一性标识的方式。服务器会为每份资源分配对应的 ETag值。
另外,当资源更新时,ETag 值也需要更新。生成 ETag 值时,并没有统一的算法规则,而仅仅是由服务器来分配。
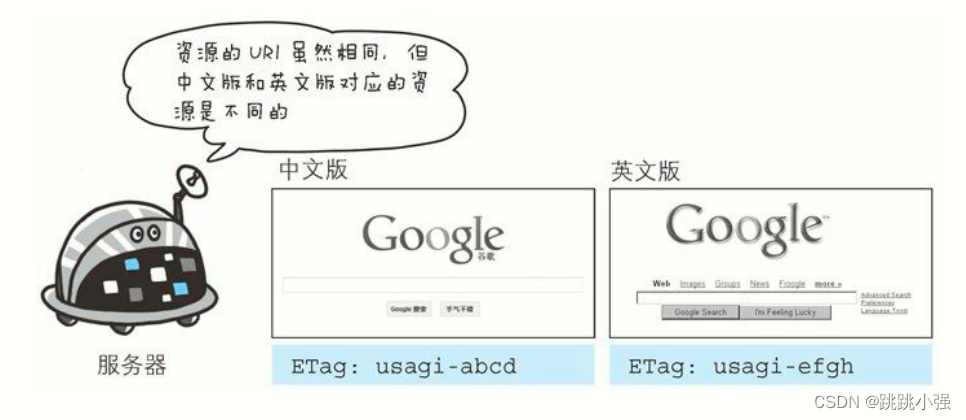
资源被缓存时,就会被分配唯一性标识。例如,当使用中文版的浏览器访问 http://www.google.com/ 时,就会返回中文版对应的资源,而使用英文版的浏览器访问时,则会返回英文版对应的资源。两者的URI 是相同的,所以仅凭 URI 指定缓存的资源是相当困难的。若在下载过程中出现连接中断、再连接的情况,都会依照 ETag 值来指定资源。
强 ETag 值和弱 Tag 值
强 ETag 值 – 不论实体发生多么细微的变化都会改变其值。
弱 ETag 值 – 弱 ETag 值只用于提示资源是否相同。只有资源发生了根本改变,产生差异时才会改变 ETag 值。这时,会在字段值最开始处附加 W/。
1.4 location
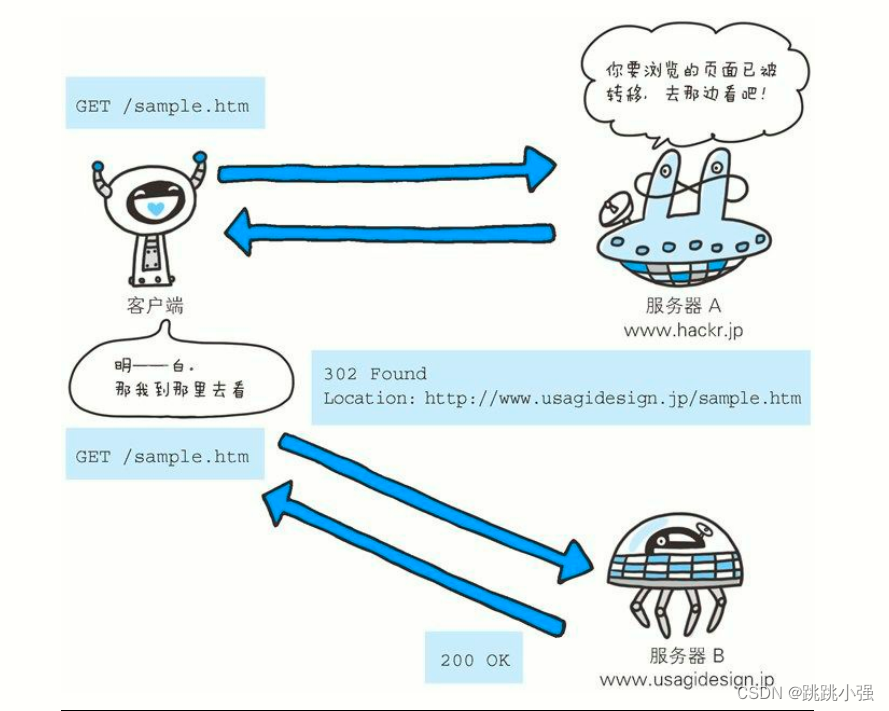
Location: http://www.usagidesign.jp/sample.html
使用首部字段 Location 可以将响应接收方引导至某个与请求 URI 位置不同的资源。
基本上,该字段会配合 3xx :Redirection 的响应,提供重定向的URI。
几乎所有的浏览器在接收到包含首部字段 Location 的响应后,都会强制性地尝试对已提示的重定向资源的访问。
1.5 Proxy-Authenticate
Proxy-Authenticate: Basic realm="Usagidesign Auth"
首部字段 Proxy-Authenticate 会把由代理服务器所要求的认证信息发送给客户端。
它与客户端和服务器之间的 HTTP 访问认证的行为相似,不同之处在于其认证行为是在客户端与代理之间进行的。而客户端与服务器之间进行认证时,首部字段 WWW-Authorization 有着相同的作用。有关HTTP 访问认证,后面的章节会再进行详尽阐述。
1.6 Retry-After
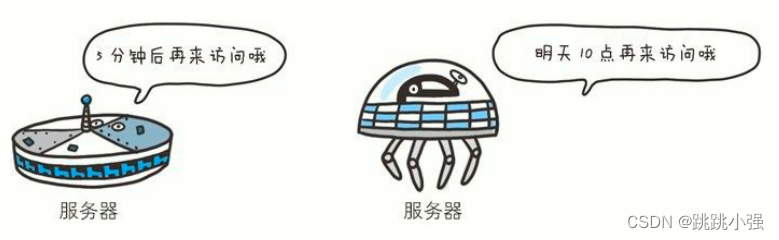
Retry-After:120
首部字段 Retry-After 告知客户端应该在多久之后再次发送请求。主要配合状态码 503 Service Unavailable 响应,或 3xx Redirect 响应一起使用。
字段值可以指定为具体的日期时间(Wed, 04 Jul 2012 06:34:24 GMT 等格式),也可以是创建响应后的秒数。
1.7 Server
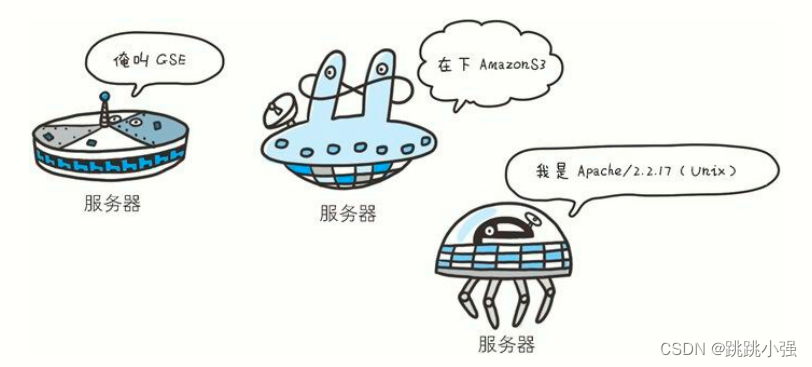
Server: Apache/2.2.17 (Unix)
首部字段 Server 告知客户端当前服务器上安装的 HTTP 服务器应用程序的信息。不单单会标出服务器上的软件应用名称,还有可能包括版本号和安装时启用的可选项。
1.8 Vary
当代理服务器接收到带有 Vary 首部字段指定获取资源的请求时,如果使用的 Accept-Language 字段的值相同,那么就直接从缓存返回响应。反之,则需要先从源服务器端获取资源后才能作为响应返回
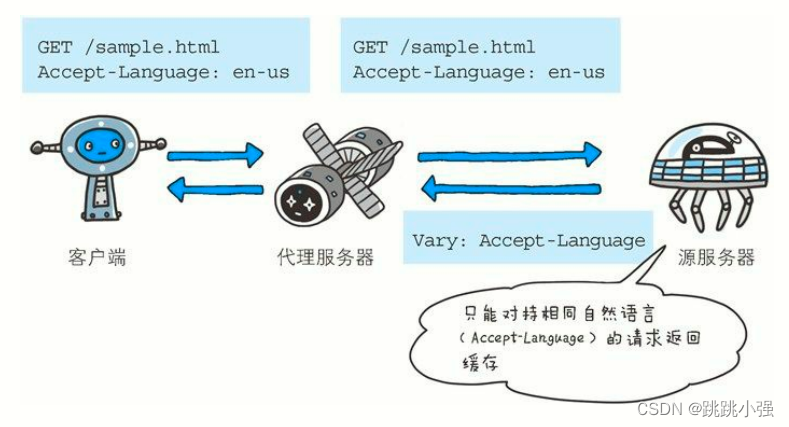
首部字段 Vary 可对缓存进行控制。源服务器会向代理服务器传达关于本地缓存使用方法的命令。
从代理服务器接收到源服务器返回包含 Vary 指定项的响应之后,若再要进行缓存,仅对请求中含有相同 Vary 指定首部字段的请求返回缓存。即使对相同资源发起请求,但由于 Vary 指定的首部字段不相同,因此必须要从源服务器重新获取资源。
1.9 WWW-Authenticate
WWW-Authenticate: Basic realm="Usagidesign Auth"
首部字段 WWW-Authenticate 用于 HTTP 访问认证。它会告知客户端适用于访问请求 URI 所指定资源的认证方案(Basic 或是 Digest)和带参数提示的质询(challenge)。状态码 401 Unauthorized 响应中,肯定带有首部字段 WWW-Authenticate。
2. 实体首部字段
实体首部字段是包含在请求报文和响应报文中的实体部分所使用的首部,用于补充内容的更新时间等与实体相关的信息。
2.1 Allow
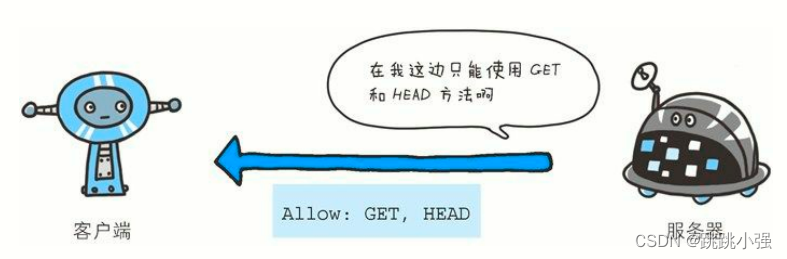
Allow: GET, HEAD
首部字段 Allow 用于通知客户端能够支持 Request-URI 指定资源的所有 HTTP 方法。当服务器接收到不支持的 HTTP 方法时,会以状态码405 Method Not Allowed 作为响应返回。与此同时,还会把所有能支持的 HTTP 方法写入首部字段 Allow 后返回。
2.2 Content-Encoding
Content-Encoding: gzip
首部字段 Content-Encoding 会告知客户端服务器对实体的主体部分选用的内容编码方式。内容编码是指在不丢失实体信息的前提下所进行的压缩。
2.3 Content-Language

Content-Language: zh-CN
首部字段 Content-Language 会告知客户端,实体主体使用的自然语言(指中文或英文等语言)。
2.4 Content-Length

Content-Length: 15000
首部字段 Content-Length 表明了实体主体部分的大小(单位是字节)。对实体主体进行内容编码传输时,不能再使用 Content-Length首部字段。由于实体主体大小的计算方法略微复杂,所以在此不再展开。读者若想一探究竟,可参考 RFC2616 的 4.4。
2.5 Content-Location
Content-Location: http://www.hackr.jp/index-ja.html
首部字段 Content-Location 给出与报文主体部分相对应的 URI。和首部字段 Location 不同,Content-Location 表示的是报文主体返回资源对应的 URI。
比如,对于使用首部字段 Accept-Language 的服务器驱动型请求,当返回的页面内容与实际请求的对象不同时,首部字段 Content-Location内会写明 URI。(访问 http://www.hackr.jp/ 返回的对象却是http://www.hackr.jp/index-ja.html 等类似情况)
2.6 Content-MD5
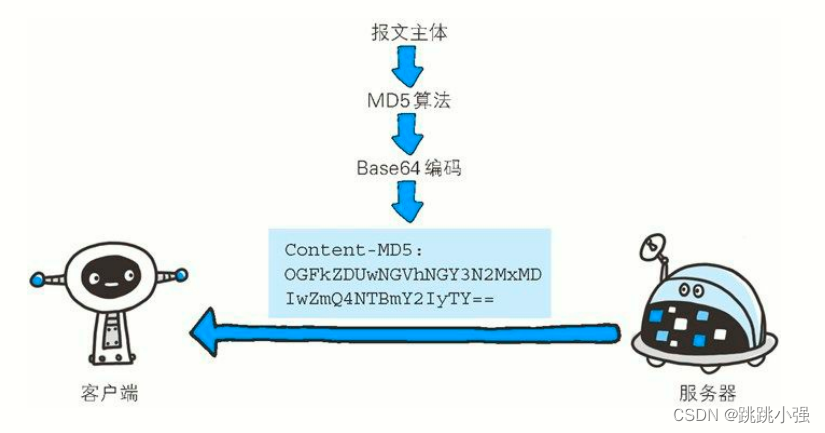
客户端会对接收的报文主体执行相同的 MD5 算法,然后与首部字段 Content-MD5 的字段值比较
Content-MD5: OGFkZDUwNGVhNGY3N2MxMDIwZmQ4NTBmY2IyTY==
首部字段 Content-MD5 是一串由 MD5 算法生成的值,其目的在于检查报文主体在传输过程中是否保持完整,以及确认传输到达。
对报文主体执行 MD5 算法获得的 128 位二进制数,再通过 Base64 编码后将结果写入 Content-MD5 字段值。由于 HTTP 首部无法记录二进制值,所以要通过 Base64 编码处理。为确保报文的有效性,作为接收方的客户端会对报文主体再执行一次相同的 MD5 算法。计算出的值与字段值作比较后,即可判断出报文主体的准确性。
采用这种方法,对内容上的偶发性改变是无从查证的,也无法检测出恶意篡改。其中一个原因在于,内容如果能够被篡改,那么同时意味着 Content-MD5 也可重新计算然后被篡改。所以处在接收阶段的客户端是无法意识到报文主体以及首部字段 Content-MD5 是已经被篡改过的。
2.7 Content-Range
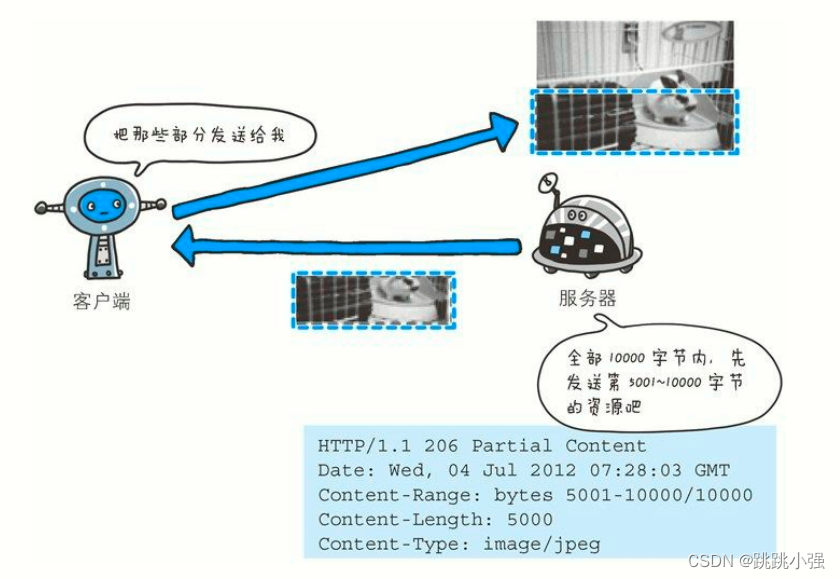
Content-Range: bytes 5001-10000/10000
针对范围请求,返回响应时使用的首部字段 Content-Range,能告知客户端作为响应返回的实体的哪个部分符合范围请求。字段值以字节为单位,表示当前发送部分及整个实体大小。
2.8 Content-Type
Content-Type: text/html; charset=UTF-8
首部字段 Content-Type 说明了实体主体内对象的媒体类型。和首部字段 Accept 一样,字段值用 type/subtype 形式赋值。
2.9 Expires
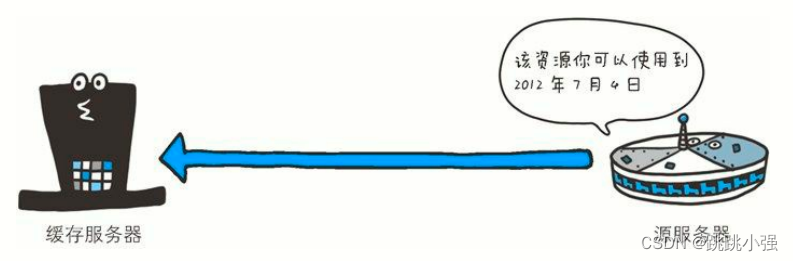
Expires: Wed, 04 Jul 2012 08:26:05 GMT
首部字段 Expires 会将资源失效的日期告知客户端。缓存服务器在接收到含有首部字段 Expires 的响应后,会以缓存来应答请求,在Expires 字段值指定的时间之前,响应的副本会一直被保存。当超过指定的时间后,缓存服务器在请求发送过来时,会转向源服务器请求资源。
源服务器不希望缓存服务器对资源缓存时,最好在 Expires 字段内写入与首部字段 Date 相同的时间值。
但是,当首部字段 Cache-Control 有指定 max-age 指令时,比起首部字段 Expires,会优先处理 max-age 指令。
2.10 Last-Modified

Last-Modified: Wed, 23 May 2012 09:59:55 GMT
首部字段 Last-Modified 指明资源最终修改的时间。一般来说,这个值就是 Request-URI 指定资源被修改的时间。但类似使用 CGI 脚本进行动态数据处理时,该值有可能会变成数据最终修改时的时间。
3.为 Cookie 服务的首部字段
管理服务器与客户端之间状态的 Cookie,虽然没有被编入标准化HTTP/1.1 的 RFC2616 中,但在 Web 网站方面得到了广泛的应用。
Cookie 的工作机制是用户识别及状态管理。Web 网站为了管理用户的状态会通过 Web 浏览器,把一些数据临时写入用户的计算机内。接着当用户访问该Web网站时,可通过通信方式取回之前发放的Cookie。
调用 Cookie 时,由于可校验 Cookie 的有效期,以及发送方的域、路径、协议等信息,所以正规发布的 Cookie 内的数据不会因来自其他Web 站点和攻击者的攻击而泄露。
至 2013 年 5 月,Cookie 的规格标准文档有以下 4 种。
由网景公司颁布的规格标准
网景通信公司设计并开发了 Cookie,并制定相关的规格标准。1994年前后,Cookie 正式应用在网景浏览器中。目前最为普及的 Cookie方式也是以此为基准的。
RFC2109
某企业尝试以独立技术对 Cookie 规格进行标准化统筹。原本的意图是想和网景公司制定的标准交互应用,可惜发生了微妙的差异。现在该标准已淡出了人们的视线。
RFC2965
为终结 Internet Explorer 浏览器与 Netscape Navigator 的标准差异而导致的浏览器战争,RFC2965 内定义了新的 HTTP 首部 Set-Cookie2 和Cookie2。可事实上,它们几乎没怎么投入使用。
RFC6265
将网景公司制定的标准作为业界事实标准(De facto standard),重新定义 Cookie 标准后的产物。
目前使用最广泛的 Cookie 标准却不是 RFC 中定义的任何一个。而是在网景公司制定的标准上进行扩展后的产物。
本节接下来就对目前使用最为广泛普及的标准进行说明。下面的表格内列举了与 Cookie 有关的首部字段。
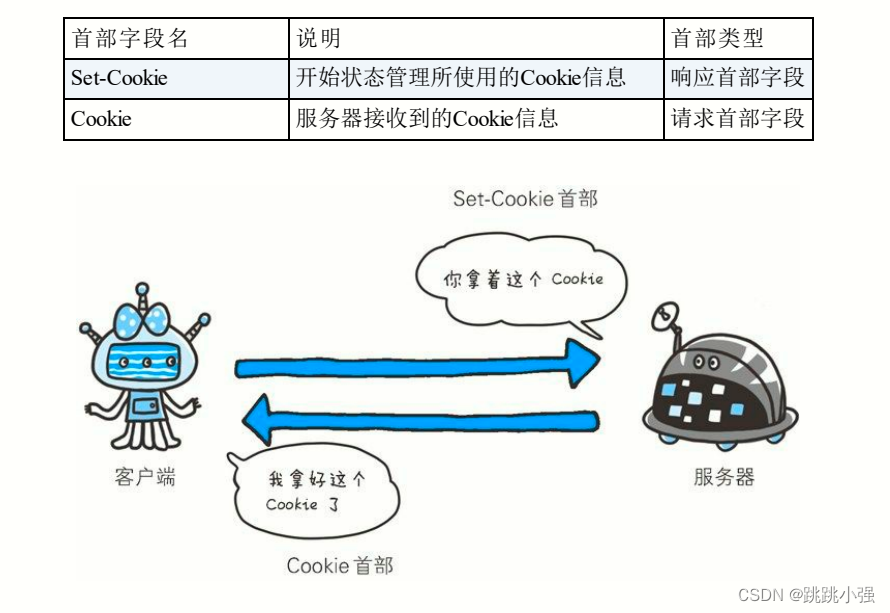
3.1 Set-Cookie
Set-Cookie: status=enable; expires=Tue, 05 Jul 2011 07:26:31
当服务器准备开始管理客户端的状态时,会事先告知各种信息。下表为set-cookie字段的一些字段值:

expires 属性
Cookie 的 expires 属性指定浏览器可发送 Cookie 的有效期。
当省略 expires 属性时,其有效期仅限于维持浏览器会话(Session)时间段内。这通常限于浏览器应用程序被关闭之前。
另外,一旦 Cookie 从服务器端发送至客户端,服务器端就不存在可以显式删除 Cookie 的方法。但可通过覆盖已过期的 Cookie,实现对客户端 Cookie 的实质性删除操作。
path 属性
Cookie 的 path 属性可用于限制指定 Cookie 的发送范围的文件目录。不过另有办法可避开这项限制,看来对其作为安全机制的效果不能抱有期待。
domain 属性
通过 Cookie 的 domain 属性指定的域名可做到与结尾匹配一致。比如,当指定 example.com 后,除 example.com 以外,www.example.com或 www2.example.com 等都可以发送 Cookie。
因此,除了针对具体指定的多个域名发送 Cookie 之 外,不指定 domain 属性显得更安全。
secure 属性
Cookie 的 secure 属性用于限制 Web 页面仅在 HTTPS 安全连接时,才可以发送 Cookie。
发送 Cookie 时,指定 secure 属性的方法如下所示。
Set-Cookie: name=value; secure
以上例子仅当在 https://www.example.com/(HTTPS)安全连接的情况下才会进行 Cookie 的回收。也就是说,即使域名相同http://www.example.com/(HTTP)也不会发生 Cookie 回收行为。
当省略 secure 属性时,不论 HTTP 还是 HTTPS,都会对 Cookie 进行回收。
HttpOnly 属性
Cookie 的 HttpOnly 属性是 Cookie 的扩展功能,它使 JavaScript 脚本无法获得 Cookie。其主要目的为防止跨站脚本攻击(Cross-site scripting,XSS)对 Cookie 的信息窃取。
发送指定 HttpOnly 属性的 Cookie 的方法如下所示。
Set-Cookie: name=value; HttpOnly
通过上述设置,通常从 Web 页面内还可以对 Cookie 进行读取操作。但使用 JavaScript 的 document.cookie 就无法读取附加 HttpOnly 属性后的 Cookie 的内容了。因此,也就无法在 XSS 中利用 JavaScript 劫持Cookie 了。
虽然是独立的扩展功能,但 Internet Explorer 6 SP1 以上版本等当下的主流浏览器都已经支持该扩展了。另外顺带一提,该扩展并非是为了防止 XSS 而开发的。
3.2 Cookie
Cookie: status=enable
首部字段 Cookie 会告知服务器,当客户端想获得 HTTP 状态管理支持时,就会在请求中包含从服务器接收到的 Cookie。接收到多个Cookie 时,同样可以以多个 Cookie 形式发送。
4.其他首部字段
HTTP 首部字段是可以自行扩展的。所以在 Web 服务器和浏览器的应用上,会出现各种非标准的首部字段。
接下来,我们就一些最为常用的首部字段进行说明。
- x-frame-options
- x-xss-protection
- dnt
- p3p
4.1 X-Frame-Options
X-Frame-Options: DENY
首部字段 X-Frame-Options 属于 HTTP 响应首部,用于控制网站内容在其他 Web 网站的 Frame 标签内的显示问题。其主要目的是为了防止点击劫持(clickjacking)攻击。
首部字段 X-Frame-Options 有以下两个可指定的字段值。
- DENY :拒绝
- SAMEORIGIN :仅同源域名下的页面(Top-level-browsingcontext)匹配时许可。(比如,当指定 http://hackr.jp/sample.html页面为 SAMEORIGIN 时,那么 hackr.jp 上所有页面的 frame 都被允许可加载该页面,而 example.com 等其他域名的页面就不行了)
- ALLOW-FROM:可以定义允许frame加载的页面地址
支持该首部字段的浏览器有:Internet Explorer 8、Firefox 3.6.9+、Chrome 4.1.249.1042+、Safari 4+ 和 Opera 10.50+ 等。现在主流的浏览器都已经支持。
能在所有的 Web 服务器端预先设定好 X-Frame-Options 字段值是最理想的状态。
注:关于点击劫持攻击
点击接触攻击可以理解为利用了ifram标签将目标网站(受害者网站)加载到伪装页面(黑客的攻击机)内部,使其敏感操作的按钮和伪装页面上的某些按钮重合,再利用css样式隐藏这样的目标页面,使得伪装页面内部看起来和正常网页相同。在诱骗用户点击了假的按钮后实现所谓的恶意攻击行为。
由于整个过程用户的点击被点到了别的地方,所以称之为点击劫持攻击。当然通过x-frame-options首部的设置即可解决这个问题。
4.2 X-XSS-Protection
X-XSS-Protection: 1
首部字段 X-XSS-Protection 属于 HTTP 响应首部,它是针对跨站脚本攻击(XSS)的一种对策,用于控制浏览器 XSS 防护机制的开关。
首部字段 X-XSS-Protection 可指定的字段值如下。
- 0 :将 XSS 过滤设置成无效状态
- 1 :将 XSS 过滤设置成有效状态
注:这个东西现在已经没用了,毕竟因为浏览器的限制能力常常被绕过或者又因为太严格影响访问,开发者们干脆取消这样的防御机制,将其交给服务器自己解决。
可以参考MDN上的解释进一步理解
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/X-XSS-Protection
4.3 DNT
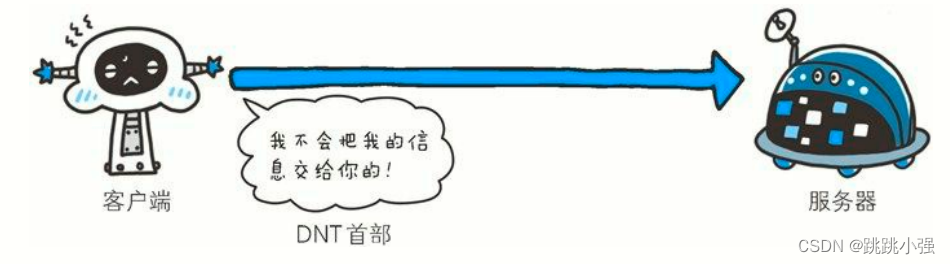
DNT: 1
首部字段 DNT 属于 HTTP 请求首部,其中 DNT 是 Do Not Track 的简称,意为拒绝个人信息被收集,是表示拒绝被精准广告追踪的一种方法。
首部字段 DNT 可指定的字段值如下。
- 0 :同意被追踪
- 1 :拒绝被追踪
由于首部字段 DNT 的功能具备有效性,所以 Web 服务器需要对 DNT
做对应的支持。
4.4 P3P
P3P: CP="CAO DSP LAW CURa ADMa DEVa TAIa PSAa PSDa IVAa IVDa
首部字段 P3P 属于 HTTP 相应首部,通过利用 P3P(The Platform for Privacy Preferences,在线隐私偏好平台)技术,可以让 Web 网站上的个人隐私变成一种仅供程序可理解的形式,以达到保护用户隐私的目的。
要进行 P3P 的设定,需按以下操作步骤进行。
步骤 1:创建 P3P 隐私
步骤 2:创建 P3P 隐私对照文件后,保存命名在 /w3c/p3p.xml
步骤 3:从 P3P 隐私中新建 Compact policies 后,输出到 HTTP 响应
中
有关 P3P 的详细规范标准请参看下方链接。
The Platform for Privacy Preferences 1.0(P3P1.0)Specification
协议中对 X- 前缀的废除:
在 HTTP 等多种协议中,通过给非标准参数加上前缀 X-,来区别于标准参数,并使那些非标准的参数作为扩展变成可能。但是这种简单粗暴的做法有百害而无一益,因此在“RFC 6648 - Deprecatingthe “X-” Prefix and Similar Constructs in Application Protocols”中提议停止该做法。然而,对已经在使用中的 X- 前缀来说,不应该要求其变更。
到这里,相信大家对于常见的http头部字段有所了解,关于更详细的内容大家可以参考《图解http》一书,讲的十分详细。