文章目录
- 一、RDD持久化
- (一)引入持久化的必要性
- (二)案例演示持久化操作
- 1、RDD的依赖关系图
- 2、不采用持久化操作
- 3、采用持久化操作
- 二、存储级别
- (一)持久化方法的参数
- (二)Spark RDD存储级别表
- (三)如何选择存储级别
- (四)persist()与cache()的关系
- (五)案例演示设置存储级别
- 三、利用Spark WebUI查看缓存
- (一)创建RDD并标记为持久化
- (二)Spark WebUI查看RDD存储信息
- (三)将RDD从缓存中删除
一、RDD持久化

(一)引入持久化的必要性
Spark中的RDD是懒加载的,只有当遇到行动算子时才会从头计算所有RDD,而且当同一个RDD被多次使用时,每次都需要重新计算一遍,这样会严重增加消耗。为了避免重复计算同一个RDD,可以将RDD进行持久化。
Spark中重要的功能之一是可以将某个RDD中的数据保存到内存或者磁盘中,每次需要对这个RDD进行算子操作时,可以直接从内存或磁盘中取出该RDD的持久化数据,而不需要从头计算才能得到这个RDD。
(二)案例演示持久化操作
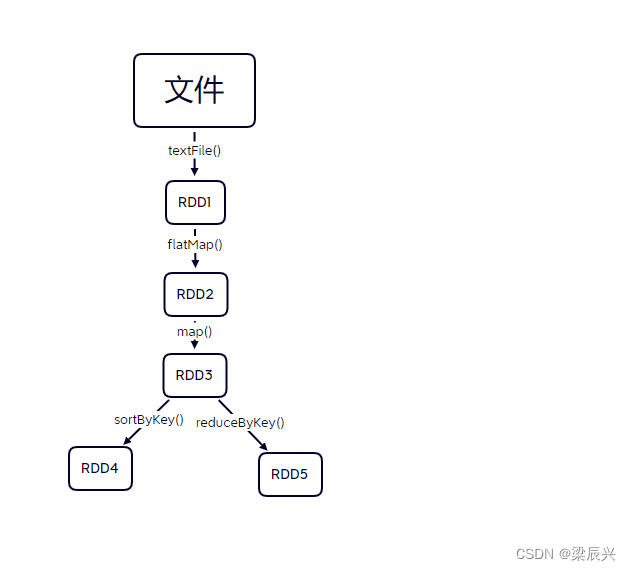
1、RDD的依赖关系图
读取文件,进行一系列操作,有多个RDD,如下图所示。
2、不采用持久化操作
在上图中,对RDD3进行了两次算子操作,分别生成了RDD4和RDD5。若RDD3没有持久化保存,则每次对RDD3进行操作时都需要从textFile()开始计算,将文件数据转化为RDD1,再转化为RDD2,最终才得到RDD3。
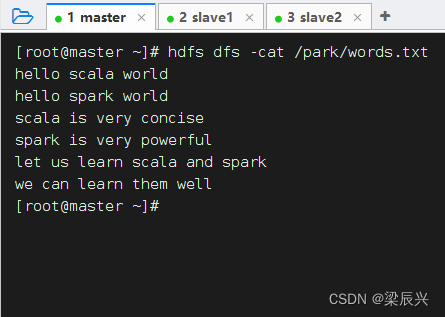
查看要操作的HDFS文件
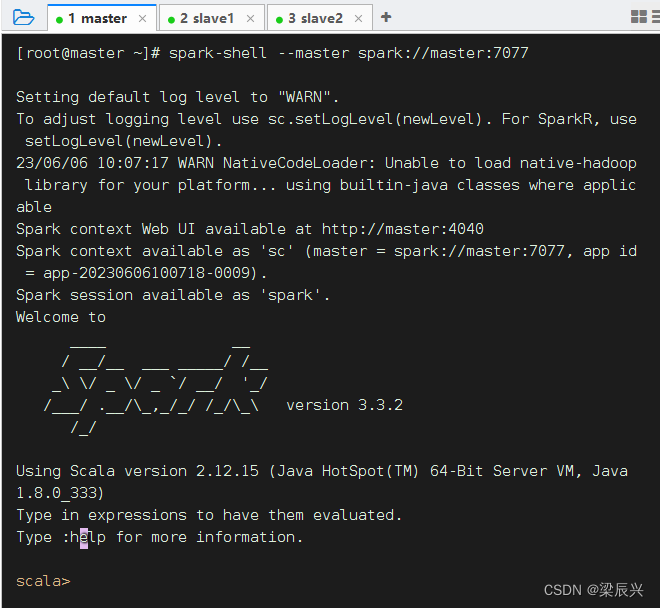
以集群模式启动Spark Shell
按照图示进行操作,得RDD4和RDD5
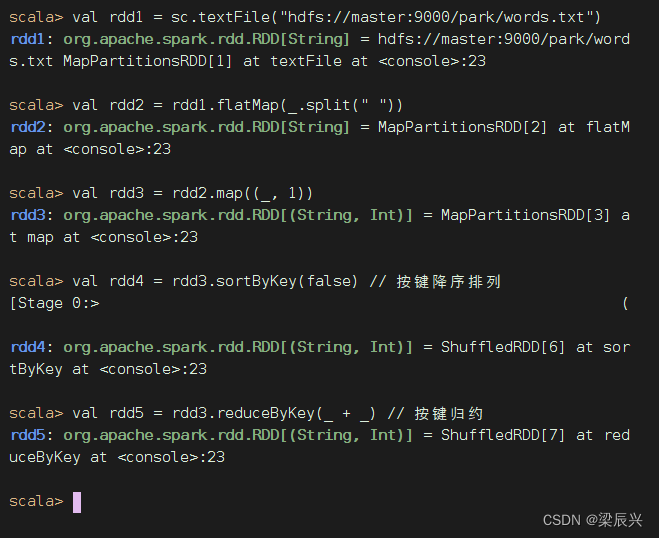
查看RDD4内容,会从RDD1到RDD2到RDD3到RDD4跑一趟
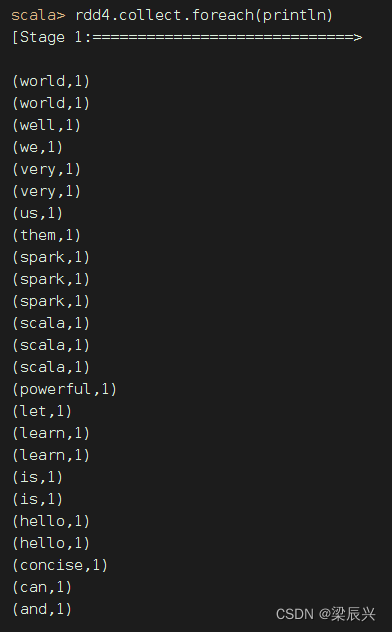
显示RDD5内容,也会从RDD1到RDD2到RDD3到RDD5跑一趟
3、采用持久化操作
可以在RDD上使用persist()或cache()方法来标记要持久化的RDD(cache()方法实际上底层调用的是persist()方法)。在第一次行动操作时将对数据进行计算,并缓存在节点的内存中。Spark的缓存是容错的:如果缓存的RDD的任何分区丢失,Spark就会按照该RDD原来的转换过程自动重新计算并缓存。
计算到RDD3时,标记持久化
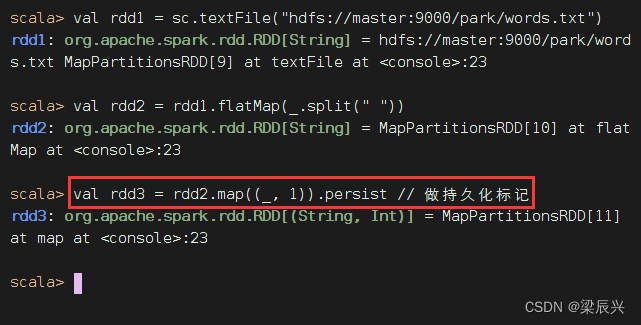
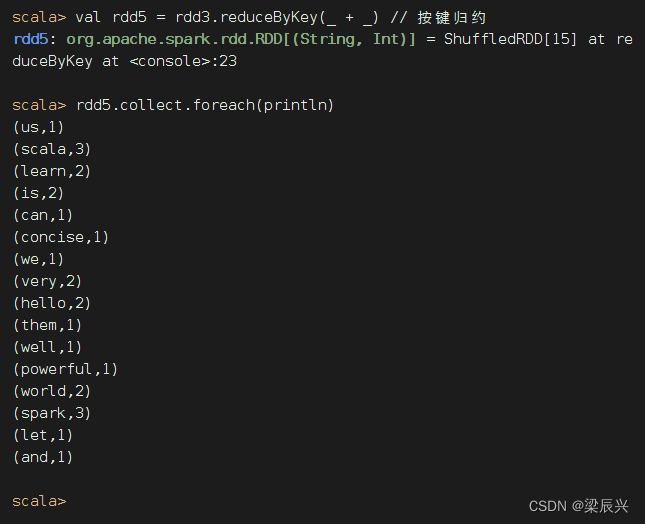
计算RDD4,就是基于RDD3缓存的数据开始计算,不用从头到尾跑一趟
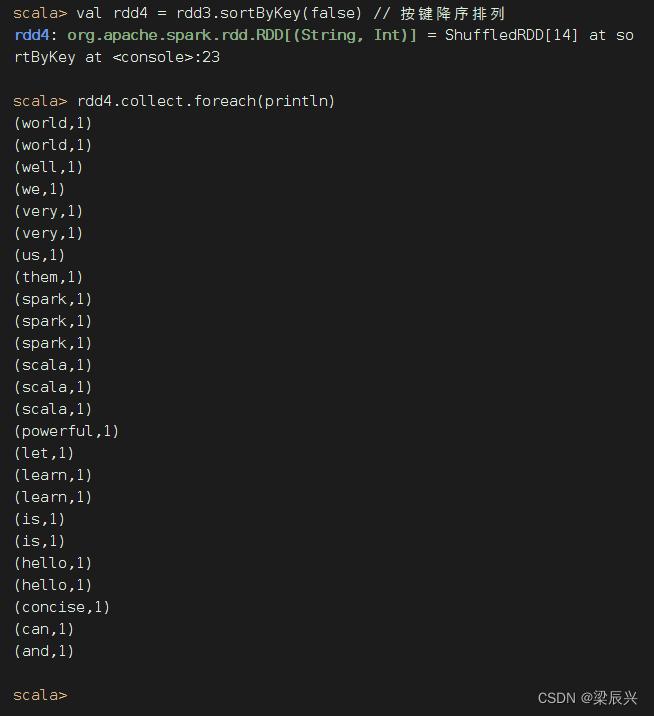
计算RDD5,就是基于RDD3缓存的数据开始计算,不用从头到尾跑一趟
二、存储级别
(一)持久化方法的参数
利用RDD的persist()方法实现持久化,向persist()方法中传入一个StorageLevel对象指定存储级别。每个持久化的RDD都可以使用不同的存储级别存储,默认的存储级别是StorageLevel.MEMORY_ONLY。
(二)Spark RDD存储级别表
Spark RDD有七种存储级别
| 存储级别 | 说明 |
|---|---|
| MEMORY_ONLY | 将RDD存储为JVM中的反序列化Java对象。如果内存不够,部分分区就不会被缓存,并且在每次需要这些分区的时候都会被动态地重新计算。此为默认级别。 |
| MEMORY_AND_DISK | 将RDD存储为JVM中的反序列化Java对象。如果内存不够,就将未缓存的分区存储在磁盘上,并在需要这些分区时从磁盘读取。 |
| MEMORY_ONLY_SER | 将RDD存储为序列化的Java对象(每个分区一个字节数组)。这通常比反序列化对象更节省空间,特别是在使用快速序列化时,但读取时会增加 CPU负担。 |
| MEMORY_AND_DISK_SER | 类似于MEMORY_ONLY_SER,但是溢出的分区将写到磁盘,而不是每次需要对其动态地重新计算。 |
| DISK_ONLY | 只在磁盘上存储RDD分区。 |
| MEMORY_ONLY_2 | 与MEMORY_ONLY 相同,只是每个持久化的分区都会复制一份副本,存储在其他节点上。这种机制主要用于容错,一旦持久化数据丢失,可以使用副本数据,而不需要重新计算。 |
| MEMORY_AND_DISK_2 | 与MEMORY_AND_DISK相同,只是每个持久化的分区都会复制一份副本,存储在其他节点上。这种机制主要用于容错,一旦持久化数据丢失,可以使用副本数据,而不需要重新计算。 |
在Spark的Shuffle操作(例如reduceByKey()中,即使用户没有使用persist()方法,也会自动保存一些中间数据。这样做是为了避免在节点洗牌的过程中失败时重新计算整个输入。如果想多次使用某个RDD,那么强烈建议在该RDD上调用persist()方法。
(三)如何选择存储级别
选择原则:权衡内存使用率和CPU效率
如果RDD存储在内存中不会发生溢出,那么优先使用默认存储级别(MEMORY_ONLY),该级别会最大程度发挥CPU的性能,使在RDD上的操作以最快的速度运行。
如果RDD存储在内存中会发生溢出,那么使用MEMORY_ONLY_SER并选择一个快速序列化库将对象序列化,以节省空间,访问速度仍然相当快。
除非计算RDD的代价非常大,或者该RDD过滤了大量数据,否则不要将溢出的数据写入磁盘,因为重新计算分区的速度可能与从磁盘读取分区一样快。
如果希望在服务器出故障时能够快速恢复,那么可以使用多副本存储级别MEMORY_ONLY_2或MEMORY_AND_DISK_2。该存储级别在数据丢失后允许在RDD上继续运行任务,而不必等待重新计算丢失的分区。其他存储级别在发生数据丢失后,需要重新计算丢失的分区。
(四)persist()与cache()的关系
查看两个方法的源码
/** * 在第一次行动操作时持久化RDD,并设置存储级别,当RDD从来没有设置过存储级别时才能使用该方法 */
def persist(newLevel: StorageLevel): this.type = { if (isLocallyCheckpointed) { // 如果之前已将该RDD设置为localCheckpoint,就覆盖之前的存储级别 persist(LocalRDDCheckpointData.transformStorageLevel(newLevel), allowOverride = true) } else { persist(newLevel, allowOverride = false) }
}
/** * 持久化RDD,使用默认存储级别(MEMORY_ONLY) */
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY) /** * 持久化RDD,使用默认存储级别(MEMORY_ONLY) */
def cache(): this.type = persist()
从上述代码可以看出,cache()方法调用了无参的persist()方法,两者的默认存储级别都为MEMORY_ONLY,但cache()方法不可更改存储级别,而persist()方法可以通过参数自定义存储级别。
(五)案例演示设置存储级别
在net.army.rdd根包里创建day05子包,然后在子包里创建SetStorageLevel对象
运行程序,查看结果

三、利用Spark WebUI查看缓存
使用集群方式重启Spark Shell
(一)创建RDD并标记为持久化
执行命令:val rdd = sc.parallelize(List(56, 67, 32, 89, 90, 66, 100))
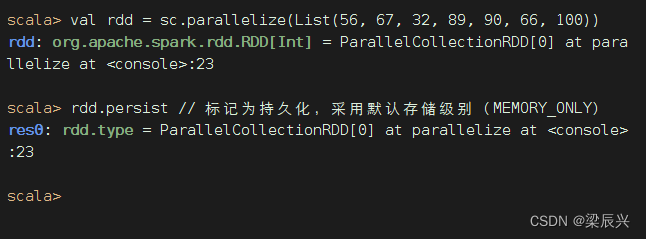
(二)Spark WebUI查看RDD存储信息
浏览器中访问Spark Shell的WebUI http://master:4040/storage/ 查看RDD存储信息,可以看到存储信息为空

执行命令:rdd.collect,收集RDD数据
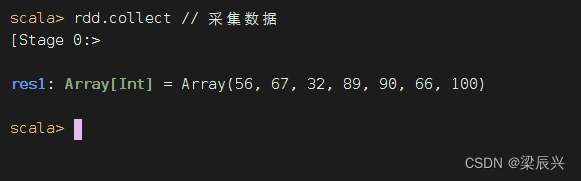
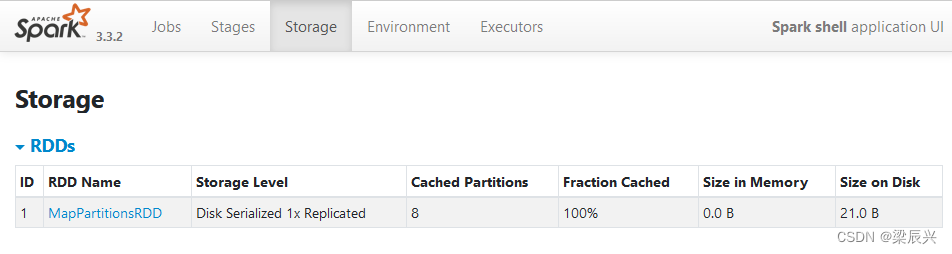
刷新WebUI,发现出现了一个ParallelCollectionRDD的存储信息,该RDD的存储级别为MEMORY,持久化的分区为8,完全存储于内存中。
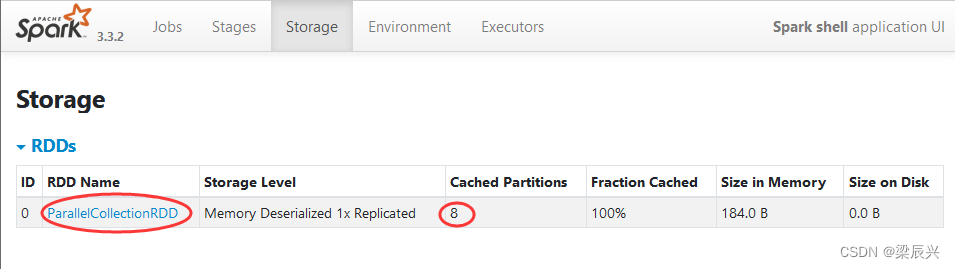
单击ParallelCollectionRDD超链接,可以查看该RDD的详细存储信息

上述操作说明,调用RDD的persist()方法只是将该RDD标记为持久化,当执行行动操作时才会对标记为持久化的RDD进行持久化操作。
执行以下命令,创建rdd2,并将rdd2持久化到磁盘
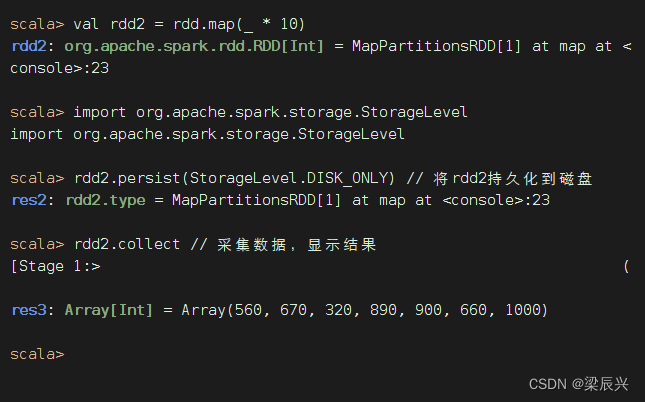
刷新WebUI,发现多了一个MapPartitionsRDD的存储信息,该RDD的存储级别为DISK,持久化的分区为8,完全存储于磁盘中。

(三)将RDD从缓存中删除
Spark会自动监视每个节点上的缓存使用情况,并以最近最少使用的方式从缓存中删除旧的分区数据。如果希望手动删除RDD,而不是等待该RDD被Spark自动从缓存中删除,那么可以使用RDD的unpersist()方法。
执行命令:rdd.unpersist(),将rdd(ParallelCollectionRDD)从缓存中删除

刷新WebUI,发现只剩下了MapPartitionsRDD,ParallelCollectionRDD已被移除。