数据集地址:M5 Forecasting - Accuracy | Kaggle
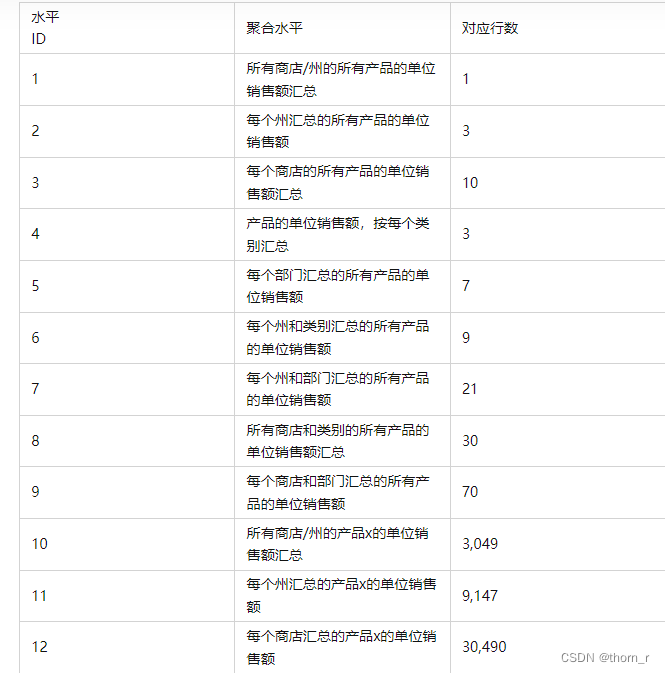
M系列竞赛是针对于时间序列预测的竞赛,从1982年至今已经举办了5届了。M5(最后一届)举行于2020年,使用了来自美国三个洲,三种产品类别,七个部门,3049种商品从2011到2016年的历史销量数据,选手们将要用它们用以预测之后28日的销售数据。具体数据集内容如图所示:
我将使用给定数据集中的最后28日作为测试集,剩下的部分作为训练集和验证集,使用各类回归模型这个问题进行预测。
我的探索数据以及特征工程在很大程度上参考了血泪参赛史 - M5时间序列预测(一)历史与概况 - 知乎这一系列的文章;以及这位叫Konstantin的老哥的策略M5 - Three shades of Dark: Darker magic | Kaggle(这只是他所有出列最后建模的步骤,其他步骤还需要在Code栏种搜索他的名字)。
一、数据探索
import pandas as pd
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as snsdf1 = pd.read_csv("calendar.csv")
df2 = pd.read_csv("sell_prices.csv")
df3 = pd.read_csv("sales_train_evaluation.csv")df3_all = df3.copy()
df3_all = df3_all.loc[:,df3_all.columns[6:]]
zeros_percentage = df3_all.apply(lambda x:x.value_counts()[0]/x.value_counts().sum(),axis=0)mpl.rcParams['font.family']='SimHei'
mpl.rcParams['axes.unicode_minus']=False每个日期的销售额被编码为以前缀d_开头的列。 这些是每天售出的商品数量(不是总金额)。其中有不少的零值。
ax = plt.gca()
#n,bins,patches = plt.hist(zeros_percentage,bins=20)
sns.kdeplot(zeros_percentage)
plt.xlim(0,1)
plt.xticks(np.arange(0,1,0.1))
ax.xaxis.set_major_formatter(mpl.ticker.PercentFormatter(xmax=1))
plt.title("当天销售为0的商品类别条目数量(%)")
plt.show()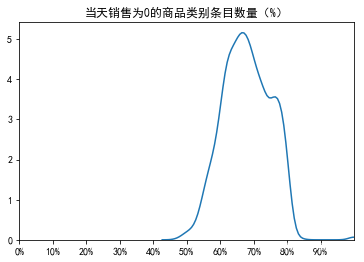
由于数据量过于庞大,我的硬件资源以及时间上暂时不支持将所有店铺与商品作预测,故只选取了德克萨斯州(TX)的家居一类(HOUSEHOLD1)商品。
df_hh1 = df3[df3.dept_id=="HOUSEHOLD_1"]
df_hh1 = df_hh1[df_hh1.state_id == 'TX']白噪声检验
首先将所有总销量作为序列作白噪声检验
df_all = df_hh1.sum()from statsmodels.stats.diagnostic import acorr_ljungboxprint(acorr_ljungbox(df_all))'''lb_stat lb_pvalue
1 1158.326786 6.953198e-254
2 1755.185421 0.000000e+00
3 2112.885102 0.000000e+00
4 2457.553665 0.000000e+00
5 3006.669919 0.000000e+00
6 4056.484892 0.000000e+00
7 5491.180820 0.000000e+00
8 6534.241632 0.000000e+00
9 7068.818539 0.000000e+00
10 7387.428123 0.000000e+00
'''p值<0.05,出现显著的自回归关系,不认为是白噪声。
时间序列分解
from statsmodels.tsa.seasonal import seasonal_decompose
df_all.index = df1.date[0:-28].astype(np.datetime64)
df_all
result = seasonal_decompose(df_all)
result.plot()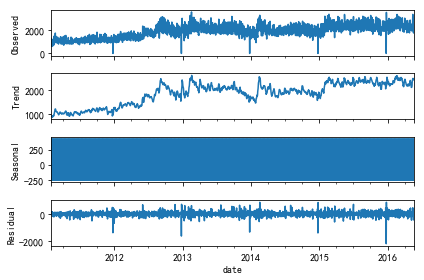
ax = plt.gca()
plt.plot(result.seasonal[0:31])
ax.xaxis.set_visible(False)
plt.show()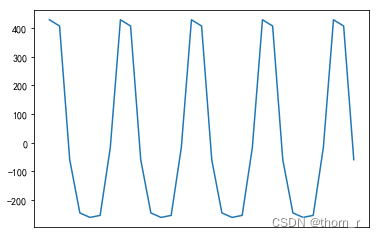
从趋势图来看,2011~2013年时家居类商品销量有明显上升趋势,而在之后趋于平稳。
而从结节性变化来看,销售的则是会集中在每周的某几天来买的,对此作进一步的验证:
df_cal_all = pd.DataFrame(columns=['date','wk_no','mth','data'])
df_cal_all.loc[:,'date']=pd.Series(df_all.index)
df_cal_all.loc[:,'wk_no']=pd.Series(df_all.index).dt.weekday
df_cal_all.wk_no = df_cal_all.wk_no+1
df_cal_all.loc[:,'mth']=pd.Series(df_all.index).dt.month
df_cal_all.loc[:,'data']=df_all.values
df_cal_all = df_cal_all.groupby(["wk_no","mth"]).sum()["data"]
df_cal_all = df_cal_all.reset_index()
sns.heatmap(pd.pivot(df_cal_all,'wk_no','mth'))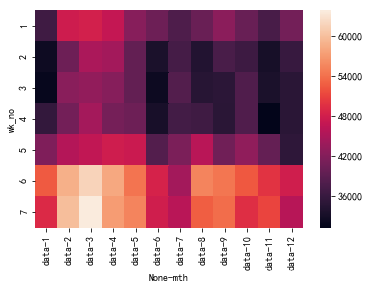
从热力图上来看,周六和周日(wk_no=6/7)的销量明显比周一至周五的销量更大。
节假日
将节假日分为四个类别:宗教类,文化类,国家纪念类以及体育活动类;观察其是否存在对销量的显著影响。
#某些不怎么熟悉的节日
#MemorialDay:阵亡纪念日,会放假? Purim End、Pesach End:犹太人的节日,会庆祝 Ramadan:伊斯兰教斋月,似乎不会有太大影响 VeteransDay:老兵节
#EidAlAdha:伊斯兰教开斋节和Eid al-Fitr是同一节日 Chanukah:犹太光明节 Cinco De Mayo:五五节#对每一类别的节日,将它们前14日的销售量作出折线图保存
idx_Religious = [i for i in df1.index if df1.event_type_1[i]=="Religious" or df1.event_type_2[i]=="Religious"]
date_Religious = df1.date[idx_Religious]
date_Religious.index = range(len(date_Religious))
df_all_Reg = pd.DataFrame(columns=["date","data","Regilious_date","holiday"])
for date in date_Religious:t = pd.to_datetime(date)h = list(df1[df1["date"]==date].event_name_1)[0]for i in df_all.index:if (i-t).days>=-14 and (i-t).days<=0:tmp = pd.Series({"date":i,"data":df_all[i],"Regilious_date":t,"holiday":h})df_all_Reg = df_all_Reg.append(tmp,ignore_index=True)elif (i-t).days>0:breakfor i in range(int(df_all_Reg.shape[0]/15)):plt.plot([(j-df_all_Reg.loc[(i+1)*15-1,"date"]).days for j in df_all_Reg.loc[i*15:(i+1)*15-1,"date"]],df_all_Reg.loc[i*15:(i+1)*15-1,"data"])plt.title(df_all_Reg.holiday[i*15])plt.savefig('./Regilious/'+df_all_Reg.holiday[i*15]+"_"+str(i)+'.png')print(i,"finish")plt.close()idx_National = [i for i in df1.index if df1.event_type_1[i]=="National" or df1.event_type_2[i]=="National"]
date_National = df1.date[idx_National]
date_National.index = range(len(date_National))
df_all_National = pd.DataFrame(columns=["date","data","National_date","holiday"])
for date in date_National:t = pd.to_datetime(date)h = list(df1[df1["date"]==date].event_name_1)[0]for i in df_all.index:if (i-t).days>=-14 and (i-t).days<=0:tmp = pd.Series({"date":i,"data":df_all[i],"National_date":t,"holiday":h})df_all_National = df_all_National.append(tmp,ignore_index=True)elif (i-t).days>0:breakfor i in range(int(df_all_National.shape[0]/15)):plt.plot([(j-df_all_National.loc[(i+1)*15-1,"date"]).days for j in df_all_National.loc[i*15:(i+1)*15-1,"date"]],df_all_National.loc[i*15:(i+1)*15-1,"data"])plt.title(df_all_National.holiday[i*15])plt.savefig('./National/'+df_all_National.holiday[i*15]+"_"+str(i)+'.png')print(i,"finish")plt.close()idx_Cultural = [i for i in df1.index if df1.event_type_1[i]=="Cultural" or df1.event_type_2[i]=="Cultural"]
date_Cultural = df1.date[idx_Cultural]
date_Cultural.index = range(len(date_Cultural))
df_all_Cultural = pd.DataFrame(columns=["date","data","Cultural_date","holiday"])
for date in date_Cultural:t = pd.to_datetime(date)h = list(df1[df1["date"]==date].event_name_1)[0]for i in df_all.index:if (i-t).days>=-14 and (i-t).days<=0:tmp = pd.Series({"date":i,"data":df_all[i],"Cultural_date":t,"holiday":h})df_all_Cultural = df_all_Cultural.append(tmp,ignore_index=True)elif (i-t).days>0:breakfor i in range(int(df_all_Cultural.shape[0]/15)):plt.plot([(j-df_all_Cultural.loc[(i+1)*15-1,"date"]).days for j in df_all_Cultural.loc[i*15:(i+1)*15-1,"date"]],df_all_Cultural.loc[i*15:(i+1)*15-1,"data"])plt.title(df_all_Cultural.holiday[i*15])plt.savefig('./Cultural/'+df_all_Cultural.holiday[i*15]+"_"+str(i)+'.png')print(i,"finish")plt.close()idx_Sporting = [i for i in df1.index if df1.event_type_1[i]=="Sporting" or df1.event_type_2[i]=="Sporting"]
date_Sporting = df1.date[idx_Sporting]
date_Sporting.index = range(len(date_Sporting))
df_all_Sporting = pd.DataFrame(columns=["date","data","Sporting_date","holiday"])
for date in date_Sporting:t = pd.to_datetime(date)h = list(df1[df1["date"]==date].event_name_1)[0]for i in df_all.index:if (i-t).days>=-14 and (i-t).days<=0:tmp = pd.Series({"date":i,"data":df_all[i],"Sporting_date":t,"holiday":h})df_all_Sporting = df_all_Sporting.append(tmp,ignore_index=True)elif (i-t).days>0:breakfor i in set(df_all_Sporting.Sporting_date):tmp_df = df_all_Sporting[df_all_Sporting.Sporting_date==i]plt.plot(tmp_df.date,tmp_df.data)plt.title(tmp_df.holiday.values[0])plt.savefig('./Sporting/'+tmp_df.holiday.values[0]+str(tmp_df.index[0])+'.png')print(i,"finish")plt.close()将节日当天以及前14天的销量作折线图:
从14天的折线图来看,节假日实际上并不会对“家用类商品”产生过多的影响,这也符合我们对于耐用消费品的一贯认知。

这里还有2个干扰因素:首先是圣诞节,不知道是有意还是无心,所有圣诞节当天的销售额全部为0。
有可能是因为当日的统筹不作数 ?也有可能是圣诞节当日不营业了。
还有就是在做完这个之后,我才想起来美国还有个叫“黑色星期五”的大促(有点类似于我们这里的双十一?)。竞赛中给出的calender.csv并没有给出这一日期的标注,大概是因为这一日期可以通过感恩节推算的缘故。在特征工程时,完全没有考虑到这一点。
同时在数据集中,有5天同时有2种假日。由于上述发现节假日对家居类产品没有显著影响,故而此处不再考虑。

二、特征工程
首先我们需要将原本将“天”作为列的数据集进行转置并加入价格信息以及节假日信息;删去了每个商品在第一次销售之前的行(参照price表)。并且为此加入一些简易的特征变量。
非常可惜的是,这一部分的代码因为我重装Anaconda时没有做好备份不翼而飞了。可以参考M5 - Simple FE | Kaggle 里的内容。这里我讲一下加入的各个特征具体有哪些含义。
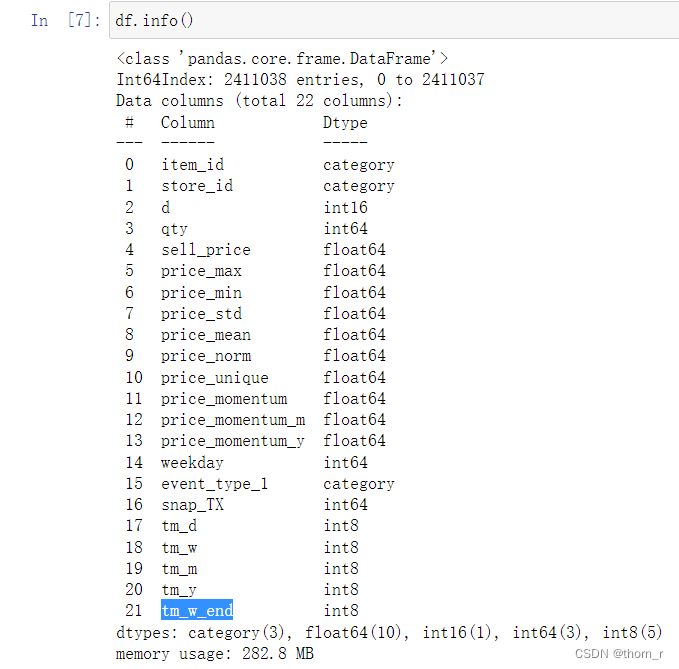
price_max:该商品历史最高价格
price_min:该商品历史最低价格
price_std:该商品历史价格的标准差
price_mean:该商品历史价格的均值
price_norm:“归一化”之后的价格
price_unique:商品历史上价格变动次数+1(没变动过就是1)
price_momentum:该商品的“动量”(即该商品相较于上一期(天)的价格变化),没有变化时为0
price_momentum_m:该商品当月的“平均价格”。(是的,尽管这里的变量名也是"momentum",但是在Konstantin的源码中就是直接取均值的,此处也使用这一特征)
price_momentum_y:该商品当年的“平均价格”。
weekday:星期几
event_type_1:节假日类型(calender.csv中的信息)
snap_TX:是否能使用食品优惠券
tm_d:每个月第几日
tm_w:当年第几周
tm_m:当年第几个月
tm_y:年份减去训练集中最小年份
tm_w_end:当天是否为周末
除了这些“常规”的特征外,我们还需要加入滞后项作为特征,以此在建模时达到“移动窗口”的效果,之后在建模过程中,会详细说明这一点。
for i in range(28):df["qty_lag"+str(i+1)] = df.groupby(["item_id","store_id"])["qty"].transform(lambda x:x.shift(i+1))同时此处还加入了“滞后28日的滑动平均”与“滞后28日的滑动标准差”这两个特征,具体而言就是“从28天前那一天,再往前推n天的平均值与标准差”。
shift_day=28
for i in [7,14,30,60,180]:df["rolling_mean_"+str(i)] = df.groupby(["item_id","store_id"])["qty"].transform(lambda x:x.shift(shift_day).rolling(i).mean())df["rolling_std_"+str(i)] = df.groupby(["item_id","store_id"])["qty"].transform(lambda x:x.shift(shift_day).rolling(i).std())还有就是在建模时,会将所有商品的历史均值与标准差作为特征的一部分,在Konstantin的notebook中称其为“Encoding”。
def encoding_item_in_train_part(df):# KONSTANTIN此处用的就是“Encoding”res = df.groupby(["item_id"]).agg({"qty":["mean","std"]})res.columns=["item_train_mean","item_train_std"]res = res.reset_index()return res三、建模
backtest
时间序列问题不能使用交叉验证。 因为交叉验证是随机将数据集分为验证集和训练集,就会造成“5月的数据在验证集,6月的数据却在训练集”的数据泄露(data leakage)的情形。这就会导致模型最终出现过拟合的现象。
因此,应该采用backtest方法:将数据中的时间分为2段,前一段时间作为训练集,而后一段时间用作验证集。在训练集中,给每个时间段作滑动窗口,将前n天的数据作为特征的一部分,以此预测当前值。这也是为什么在特征工程时,需要加入销量的滞后值。
recursive forecasting
这一策略的逻辑是:在最终的28日中,首先预测第一日的销量,然后将其当作特征的一部分,计算第二日的滞后项……以此类推,凑齐28日的预测值。我这里采用了这一方法是因为我的特征工程实际上是很依赖于滞后项的。(当然,也可以直接将最后一日的数字作为滞后项将28日的特征“填满”,具体效果未知)。
顺带一提,由于预测的日期过短(仅28日),所以在正式比赛时,直接一次性预测28日数据反而效果更好(参见血泪参赛史 - M5时间序列预测(三)血泪 - 知乎)。
贝叶斯优化调参
贝叶斯调参数学原理笔者暂时还在学习当中。基本原理就是:由于本身损失函数的形状是未知的(否则就直接给出最优点了),于是就使用一个Sampler(如高斯/TPE等)去采样几个点来模拟出一个“代理函数”(注意:代理函数并非直接用来逼近真实的损失函数)。根据代理函数的结果,在损失值较小的那几个点附近采样更多的点(其他位置也会采样,但是权重减小),以此类推来找到最优点。
更多的其实还是学习了optuna这个包的使用。
blending
由于时间序列问题不能使用交叉验证,所以也不能使用stacking了。此处使用blending将多个模型融合起来:使用训练集训练3个子模型,之后再使用验证集给出3个预测值;将3个预测值作为特征,再训练出最终的模型。测试集上先使用3个子模型预测出3个特征值,再使用这3个特征值预测出最终结果。
RMMSE
比赛使用的是RMSSE后加权来作为最终分数的;RMSSE的公式为:
其中,分子部分乘以1/h是简单的RMSE,而分母部分则是所有训练集中,当前值减去前一期值的差的均方和。
关于这个度量,我引用血泪参赛史 - M5时间序列预测(一)历史与概况 - 知乎里的解释:

关于这个损失函数的相关理论基础,我暂时没有研究。
catboost模型训练代码
import pandas as pd
import numpy as npdf = pd.read_pickle("df_with_lags.pickle/df_with_lags.pickle")
#其实下面三行应该是不需要进行的,就是转换为category而已
df["event_type_1"] = df["event_type_1"].astype("str")
df["event_type_1"].fillna("None",inplace=True)
df["event_type_1"] = df["event_type_1"].astype("category")
#训练集与测试集
train = df[df.d<=1913]
test = df[df.d>1913]import xgboost as xgb
import lightgbm as lgb
import catboost as cat
#训练集与验证集
train_data = train[train["d"]<=1700]
valid_data = train[train["d"]>1700]#此处就是“特征工程”中写到的“针对于每个商品进行的Encoding”。
tmp_df = encoding_item_in_train_part(train_data)
train_data = train_data.merge(tmp_df,how="left",on = 'item_id')
valid_data = valid_data.merge(tmp_df,how="left",on = 'item_id')
#“第几天”不作为特征
train_data.drop(["d"],axis=1,inplace=True)
valid_data.drop(["d"],axis=1,inplace=True)
#在训练时,我们还是采用RMSE来作为损失值
def RMSE(y_pred,y_real):return np.sqrt(np.mean(np.square(y_pred-y_real)))train_data = cat.Pool(data = x_tr,label=y_tr,cat_features=["item_id","store_id","event_type_1"])
valid_data = cat.Pool(data = x_va,label=y_va,cat_features=["item_id","store_id","event_type_1"])import optuna
from optuna.integration import SkoptSampler#optuna自动调参需要有2部分组成:第一部分是objective(训练过程以及优化目标)。传入的trial是optuna的trial对象。使用suggest_+变量类型来限定超参的范围#注意这里我忘记设置catboost的verbose了,训练时每棵树的建模情况都打印在了notebook中def optuna_objective(trial):od_pval = trial.suggest_float("od_pval",1e-10,1e-2)max_depth = trial.suggest_int("max_depth",6,10)iterations = trial.suggest_int("iterations",1000,5000,step=1000)learning_rate = trial.suggest_float("learning_rate",0.01,0.05,step=0.01)model = cat.CatBoostRegressor(iterations=iterations,#use_best_model=True,od_type="IncToDec",od_pval=od_pval,max_depth = max_depth,learning_rate=learning_rate,task_type="GPU")model.fit(train_data)y_pred = model.predict(valid_data)return RMSE(y_pred,y_va)#optuna自动调参的第二部分是优化器,用以设定sampler以及训练中需要输出的信息等。
#n_trials是实验次数,而algo则是选定的sampler
#选择GP(高斯过程)时,还需额外载入skopt包;由于TPE速度更快,此处我选用TPE了。def optimizer_optuna(n_trials,algo):if algo=="TPE":algo = optuna.samplers.TPESampler(n_startup_trials=10,n_ei_candidates=24)elif algo=="GP":algo = SkoptSampler(skopt_kwargs={"base_estimator":"GP","n_initial_points":10,"acq_func":"EI"})study = optuna.create_study(sampler=algo,direction="minimize")study.optimize(optuna_objective,n_trials=n_trials,show_progress_bar=True)print("\r\n","best params:",study.best_trial.params,"\r\n","best score:",study.best_trial.values)return study,study.best_trial.params,study.best_trial.valuesoptuna.logging.set_verbosity(optuna.logging.ERROR) #不输出调参时的每个log
study,best_params,best_score = optimizer_optuna(20,"GP")print(study,best_params,best_score)
"""
<optuna.study.study.Study object at 0x7f5afb36d730> {'od_pval': 0.009914919194014923, 'max_depth': 10, 'iterations': 3000, 'learning_rate': 0.03} [1.7075616589345162]
"""在得到最佳参数后,使用这个超参训练2个模b型:1个用作最终测试结果,另一个作为blending的子模型。
model_catboost_for_blending = cat.CatBoostRegressor(od_pval=0.009914919194014923,max_depth=10,iterations=3000,learning_rate=0.03,task_type="GPU",verbose=200)model_catboost_for_blending.fit(train_data)tmp_df = encoding_item_in_train_part(train)
train_all = train.merge(tmp_df,how="left",on = 'item_id')
train_all.drop(["d"],axis=1,inplace=True)
x_tr = train_all[[col for col in train_all.columns if col!="qty"]]
y_tr = train_all["qty"]
train_data = cat.Pool(data = x_tr,label=y_tr,cat_features=["item_id","store_id","event_type_1"])
model_catboost = cat.CatBoostRegressor(od_pval=0.009914919194014923,max_depth=10,iterations=3000,learning_rate=0.03,task_type="GPU",verbose=200)
model_catboost.fit(train_data)#保存文件
import picklewith open("model_catBoost_for_blending.pkl","wb") as f:pickle.dump(model_catboost_for_blending,f)
with open("model_catBoost.pkl","wb") as f:pickle.dump(model_catBoost,f)lightGBM代码
def optuna_objective(trial):objective = trial.suggest_categorical("objective",["tweedie","regression"])n_estimators = trial.suggest_int("n_estimators",1000,2000,step=200)max_depth = trial.suggest_int("max_depth",8,12,step=1)model = lgb.LGBMRegressor(objective=objective,n_estimators=n_estimators,max_depth = max_depth,learning_rate=0.03,verbose=-1)model.fit(x_tr,y_tr)y_pred = model.predict(x_va)return RMSE(y_pred,y_va)def optimizer_optuna(n_trials):algo = optuna.samplers.TPESampler(n_startup_trials=10,n_ei_candidates=24)study = optuna.create_study(sampler=algo,direction="minimize")study.optimize(optuna_objective,n_trials=n_trials,show_progress_bar=True)return study,study.best_trial.params,study.best_trial.valuesoptuna.logging.set_verbosity(optuna.logging.ERROR)
study,best_param,best_score = optimizer_optuna(100)print(best_param,best_score)
"""
{'objective': 'regression', 'n_estimators': 1000, 'max_depth': 9} [1.7148328055683268]
"""保存模型部分代码省略。
XGBoost模型代码
由于在训练时,笔者尚不直到XGBoost包已经支持category类型的数据,故而舍弃了item_id这一特征,并将其他特征哑变量化了。
df.drop(["item_id"],axis=1,inplace=True)
df_for_xgboost = pd.get_dummies(df)
train = df_for_xgboost[df_for_xgboost.d<=1913]
test = df_for_xgboost[df_for_xgboost.d>1913]train_data = train[train["d"]<=1700]
valid_data = train[train["d"]>1700]
train_data.drop(["d"],axis=1,inplace=True)
valid_data.drop(["d"],axis=1,inplace=True)
x_tr = train_data[[col for col in train_data.columns if col!="qty"]]
y_tr = train_data["qty"]
x_va = valid_data[[col for col in valid_data.columns if col!="qty"]]
y_va = valid_data["qty"]def optimize_objective(trial):learning_rate = trial.suggest_float("learning_rate",0.01,0.05,step=0.01)max_depth = trial.suggest_int("max_depth",8,12,step=1)n_estimators = trial.suggest_int("n_estimators",500,2000,step=500)model = xgb.XGBRegressor(learning_rate=learning_rate,max_depth=max_depth,n_estimators=n_estimators,tree_method="hist")model.fit(x_tr,y_tr)y_pred = model.predict(x_va)return RMSE(y_pred,y_va)def optimizer_TPE(n_trials):algo = optuna.samplers.TPESampler(n_startup_trials=10,n_ei_candidates=24)study = optuna.create_study(sampler=algo,direction="minimize")study.optimize(optimize_objective,n_trials=n_trials,show_progress_bar=True)return study.best_trial.params,study.best_trial.valuesoptuna.logging.set_verbosity(optuna.logging.ERROR)
best_params,best_score = optimizer_TPE(100)print(best_params,best_score)
"""
{'learning_rate': 0.01, 'max_depth': 8, 'n_estimators': 1000} [1.7046778132433156]
"""注意:使用XGboost保存模型时,不要使用pickle.dump来保存。这一保存方法并不稳定;需要使用其自带的"save_model"方法。
model_xgboost_for_blending.save_model("model_xgboost_for_blending.json")
model_xgboost.save_model("model_xgboost.json")Blending过程
import pandas as pd
import xgboost as xgb
import catboost as cat
import lightgbm as lgb
import numpy as np
import pickle
import warnings
warnings.filterwarnings("ignore")#读取数据集并作分割处理,同上文部分,不再作注释
df = pd.read_pickle("df_with_lags.pickle")df["event_type_1"] = df["event_type_1"].astype("str")
df["event_type_1"].fillna("None",inplace=True)
df["event_type_1"] = df["event_type_1"].astype("category")def encoding_item_in_train_part(df):tmp = df[df.d<=1913]res = df.groupby(["item_id"]).agg({"qty":["mean","std"]})res.columns=["item_train_mean","item_train_std"]res = res.reset_index()return restmp_df = encoding_item_in_train_part(df)
df = df.merge(tmp_df,how="left",on="item_id")train = df[df.d<=1913]
test = df[df.d>1913]train_data = train[train["d"]<=1700]
valid_data = train[train["d"]>1700]valid_data.reset_index(inplace=True)
with open("train_for_blending.plk","wb") as f:pickle.dump(train_data,f)
with open("valid_for_blending.plk","wb") as f:pickle.dump(valid_data,f)
with open("test_for_blending.plk","wb") as f:pickle.dump(test,f)item_id = df["item_id"]
df_for_xgboost = df.drop(["item_id"],axis=1)
df_for_xgboost = pd.get_dummies(df_for_xgboost)df_for_xgboost = pd.concat([item_id,df_for_xgboost],axis=1)train_valid_xgboost = df_for_xgboost[df_for_xgboost.d<=1913]
test_xgboost = df_for_xgboost[df_for_xgboost.d>1913]train_xgboost = train_valid_xgboost[train_valid_xgboost["d"]<=1700]
valid_xgboost = train_valid_xgboost[train_valid_xgboost["d"]>1700]with open("train_for_blending_xgboost.plk","wb") as f:pickle.dump(train_xgboost,f)
with open("valid_for_blending_xgboost.plk","wb") as f:pickle.dump(valid_xgboost,f)
with open("test_for_blending_xgboost.plk","wb") as f:pickle.dump(test_xgboost,f)#拿训练集使用子模型作为特征#读取模型
model_for_feature1 = xgb.Booster()
model_for_feature1.load_model("model_xgboost_for_blending.json")with open("model_lightGBM_for_blending.pkl","rb") as f:model_for_feature2=pickle.load(f)with open("model_catBoost_for_blending.pkl","rb") as f:model_for_feature3=pickle.load(f)#这个主要拿来给测试集作“滞后项”
df_with_valid = pd.concat([df_all,valid],axis=0)valid.drop("index",axis=1,inplace=True)def get_blending_feature(df_all,valid,model):"""df_all:拿来作为滞后项的数据valid:拿来生成“模型结果”作为特征值的数据model:子模型为模型在valid上作recursive forecasting得到特征值也可以直接拿来recursive forecasting出预测值"""for d in range(valid.d.min(),valid.d.max()+1):sub_df = valid[valid.d == d]x_va = sub_df[[i for i in sub_df.columns if i != "qty" and i !="d"]]if model.__class__ == xgb.Booster:
#XGBoost需要去掉item_iditem_id = x_va["item_id"] x_va.drop(["item_id"],axis=1,inplace=True)x_va = xgb.DMatrix(x_va)sub_df["qty"]=model.predict(x_va)
# if model.__class__ == xgb.Booster:
# sub_df = pd.concat([item_id,sub_df])df_all = pd.concat([df_all,sub_df],axis=0)#df_all.reset_index(inplace=True)#使用df_all来计算滞后项以及rolling#lag_day:if model.__class__ == xgb.Booster:
#XGBoost中,item_id作为哑变量groupby_list = ['store_id_TX_1','store_id_TX_2', 'store_id_TX_3',"item_id"]else:groupby_list = ["item_id","store_id"]for lag_day in range(28):df_all.loc[df_all.d==d,"qty_lag"+str(lag_day+1)] = df_all[df_all.d>=d-28].groupby(groupby_list)["qty"].transform(lambda x:x.shift(lag_day+1))[-sub_df.shape[0]:]#rolling:for i in [7,14,30,60,180]:df_all.loc[df_all.d==d,"rolling_mean_"+str(i)] = df_all[df_all.d>=d-28-181].groupby(groupby_list)["qty"].transform(lambda x:x.shift(28).rolling(i).mean())[-sub_df.shape[0]:]df_all.loc[df_all.d==d,"rolling_std_"+str(i)] = df_all[df_all.d>=d-28-181].groupby(groupby_list)["qty"].transform(lambda x:x.shift(28).rolling(i).std())[-sub_df.shape[0]:]print(d,"finish")return df_alldf_cat = get_blending_feature(df_all,valid,model_for_feature3)
df_cat_valid = df_cat.loc[df_cat.d>=1701,["store_id","item_id","d","qty"]]
df_cat = get_blending_feature(df_with_valid,test,model_for_feature3)
df_cat_test = df_cat.loc[df_cat.d>=1914,["store_id","item_id","d","qty"]]df_lgb = get_blending_feature(df_all,valid,model_for_feature2)
df_lgb_valid = df_lgb.loc[df_lgb.d>=1701,["store_id","item_id","d","qty"]]
df_lgb = get_blending_feature(df_with_valid,test,model_for_feature2)
df_lgb_test = df_lgb.loc[df_lgb.d>=1914,["store_id","item_id","d","qty"]]df_cat_valid.to_pickle("blending_df_cat_valid.pkl")
df_cat_test.to_pickle("blending_df_cat_test.pkl")
df_lgb_valid.to_pickle("blending_df_lgb_valid.pkl")
df_lgb_test.to_pickle("blending_df_lgb_test.pkl")#XGBOOST单独作处理
df_all = pd.read_pickle("train_for_blending_xgboost.plk")
valid = pd.read_pickle("valid_for_blending_xgboost.plk")
test = pd.read_pickle("test_for_blending_xgboost.plk")
df_with_valid = pd.concat([df_all,valid],axis=0)df_xgb = get_blending_feature(df_all,valid,model_for_feature1)
df_xgb_valid = df_xgb.loc[df_xgb.d>=1701,['store_id_TX_1','store_id_TX_2', 'store_id_TX_3',"item_id","d","qty"]]
df_xgb = get_blending_feature(df_with_valid,test,model_for_feature1)
df_xgb_test = df_xgb.loc[df_xgb.d>=1914,['store_id_TX_1','store_id_TX_2', 'store_id_TX_3',"item_id","d","qty"]]df_xgb_valid.to_pickle("blending_df_xgb_valid.pkl")
df_xgb_test.to_pickle("blending_df_xgb_test.pkl")接下来,使用随机森林将各个模型生成的特征再作最终的预测。
from sklearn.ensemble import RandomForestRegressorvalid = pd.read_pickle("valid_for_blending.plk")
test = pd.read_pickle("test_for_blending.plk")blending_valid_1 = pd.read_pickle("blending_df_xgb_valid.pkl")
blending_test_1 = pd.read_pickle("blending_df_xgb_test.pkl")blending_valid_2 = pd.read_pickle("blending_df_cat_valid.pkl")
blending_test_2 = pd.read_pickle("blending_df_cat_test.pkl")blending_valid_3 = pd.read_pickle("blending_df_lgb_valid.pkl")
blending_test_3 = pd.read_pickle("blending_df_lgb_test.pkl")valid = valid[["item_id","d","store_id","qty"]]
test = test[["item_id","d","store_id","qty"]]#对于XGBoost,还需要将哑变量重新换回1列。def merge_store_id(df):df["store_id"]=df["store_id_TX_1"].astype("str")+df["store_id_TX_2"].astype("str")+df["store_id_TX_3"].astype("str")df["store_id"].replace("100","TX_1",inplace=True)df["store_id"].replace("010","TX_2",inplace=True)df["store_id"].replace("001","TX_3",inplace=True)return df.drop(["store_id_TX_1","store_id_TX_2","store_id_TX_3"],axis=1)#将3个模型的结果融合起来成为3个特征:qty_1、qty_2、qty_3
blending_valid_1 = merge_store_id(blending_valid_1)
blending_test_1 = merge_store_id(blending_test_1)
blending_valid_1.rename(columns={"qty":"qty_1"},inplace=True)
blending_valid_2.rename(columns={"qty":"qty_2"},inplace=True)
blending_valid_3.rename(columns={"qty":"qty_3"},inplace=True)
blending_test_1.rename(columns={"qty":"qty_1"},inplace=True)
blending_test_2.rename(columns={"qty":"qty_2"},inplace=True)
blending_test_3.rename(columns={"qty":"qty_3"},inplace=True)valid_blending = blending_valid_1
valid_blending = valid_blending.merge(blending_valid_2,on=["store_id","item_id","d"])
valid_blending = valid_blending.merge(blending_valid_3,on=["store_id","item_id","d"])test_blending = blending_test_1
test_blending = test_blending.merge(blending_test_2,on=["store_id","item_id","d"])
test_blending = test_blending.merge(blending_test_3,on=["store_id","item_id","d"])#将特征与目标值放入同意表格内
valid_blending = valid_blending.merge(valid,on=["store_id","item_id","d"])
test_blending = test_blending.merge(test,on=["store_id","item_id","d"])#建模
rfr = RandomForestRegressor()
rfr.fit(valid_blending[["qty_1","qty_2","qty_3"]],valid_blending["qty"])模型评价
df_all = df_all[df_all.d!=1]
coef = (1/28)*(1/(np.sum(np.square(df_all.qty-df_all.qty_lag1))/df_all.index.max()))
def RMMSE(y_pred,y_real):return np.sqrt(coef*np.sum(np.square(y_pred-y_real)))#blending效果:
y_pred = rfr.predict(test_blending[["qty_1","qty_2","qty_3"]])
RMMSE(np.round(y_pred),test_blending.qty)/len(set(test_blending.item_id.values)) #假设所有的系数都一样"""
0.044124870056356194
"""#加载“使用所有前1912日训练”的模型并预测1913~1941的结果
df_all = pd.read_pickle("train_for_blending.plk")
valid = pd.read_pickle("valid_for_blending.plk")
test = pd.read_pickle("test_for_blending.plk")df_with_valid = pd.concat([df_all,valid],axis=0)with open("model_lightGBM.pkl","rb") as f:model_LGBM=pickle.load(f)
res_lgb = get_blending_feature(df_with_valid,test,model_LGBM)with open("model_catBoost.pkl","rb") as f:model_cat=pickle.load(f)
res_cat = get_blending_feature(df_with_valid,test,model_cat)model_xgb = xgb.Booster()
model_xgb.load_model("model_xgboost.json")df_all = pd.read_pickle("train_for_blending_xgboost.plk")
valid = pd.read_pickle("valid_for_blending_xgboost.plk")
test = pd.read_pickle("test_for_blending_xgboost.plk")
df_with_valid = pd.concat([df_all,valid],axis=0)
res_xgb = get_blending_feature(df_with_valid,test,model_xgb)#catBoost结果:
RMMSE(np.round(res_cat[res_cat.d>=1913].qty),test.qty)/len(set(test.item_id.values))
"""
0.04232242611844931
"""
#LightGBM结果:
RMMSE(np.round(res_lgb[res_lgb.d>=1913].qty),test.qty)/len(set(test.item_id.values))
"""
0.042464866322963125
"""
#XGBoost结果:
RMMSE(np.round(res_xgb[res_xgb.d>=1913].qty),test.qty)/len(set(test.item_id.values))
"""
0.04233898393961455
"""从结果上来看,是CatBoost的结果最优。然而,由于我们不清楚实际上的权重,故而不能直接与Leaderboard上的值进行比较,只能说这个结果的量级算是“正常范围”。
而且可以看出,或许是由于各个子模型的结构趋同(都是决策树模型的Boosting集成),故而blending的效果并不比单个子模型好。
四、反思
首先是关于这个竞赛的结果的反思:在资料中有提到过,预测的那28日实际上德克萨斯州(TX)实际上全都有洪水灾害;而由于竞赛方规则不能使用外来数据,导致了很多人在使用保险系数(乘以一个小于1的系数)后会得到不错的成绩。这位Konstantin老哥更是在Discussion中戏称其为“黑魔法”。这也表明了时间序列在遇到“状况外”时的局限性。
同时还有数据的截取。当时因为看到“家居类”商品数据量最小而直接选择了它。但是细细想来,应该选取食品类似乎更为合适:
食品类商品属于快消品,每日都会有销售额,相对不那么“稀疏”,预测的意义更大。而且食品类商品会受到节假日以及“食品券”的影响比较大,可以将先验知识放入其中,练习更有价值。
还有就是Blending策略中,没有考虑到3种集成学习实际上是有点“换汤不换药”的感觉,所以融合出来的Blending实际上并不是那么优秀,这点也需要注意。但是在建模时,我还是首次接触到LightGBM(在XGBoost基础上支持分类特征并且在特征选择上使用了"histogram"的策略)以及optuna自动调参工具,并且也跟着大佬的notebook学习了时序数据的预处理,也算是颇有收获了,接下来还是需要了解一下贝叶斯调参以及LightGBM等原理。
最后还是那句老话:本文主要用作自我学习使用,如有不足或是错误之处,还请不吝指出。
是否需要使用Autoformer预测?待定……