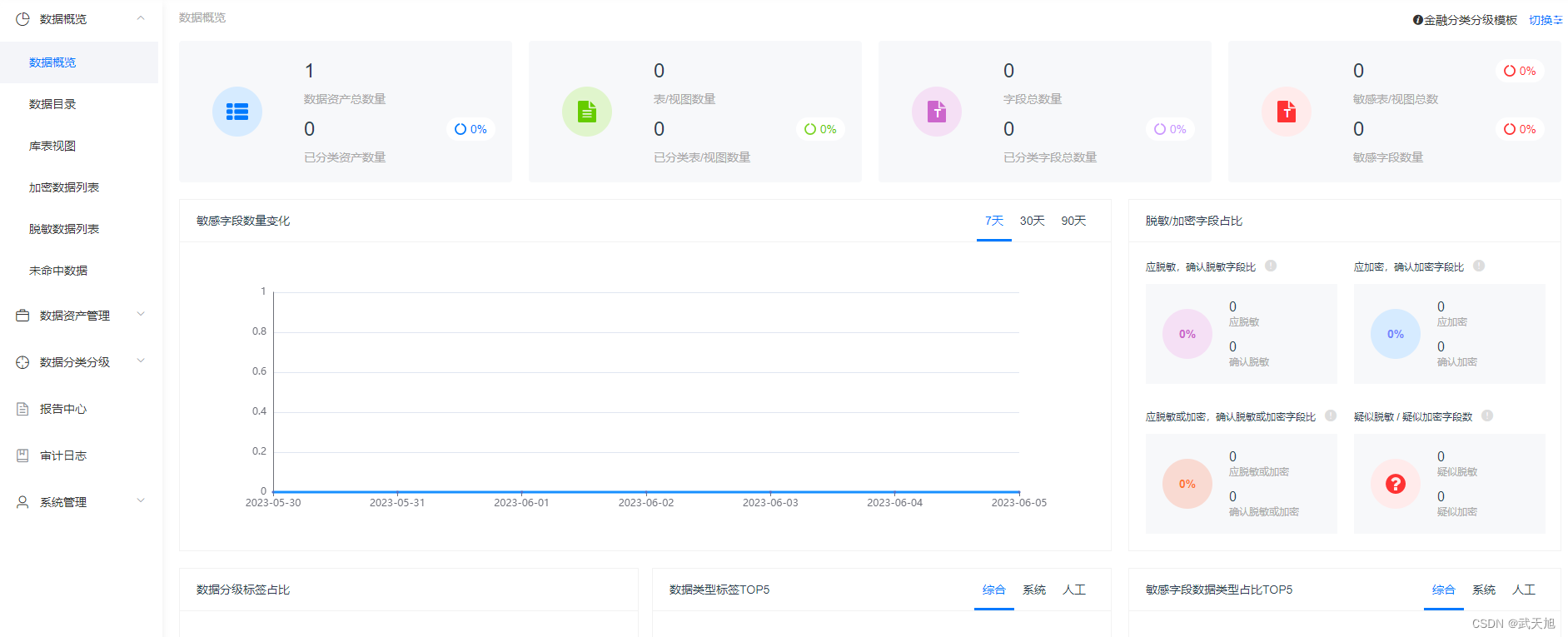
目录
- Introduction: sentiment analysis 引言:情感分析
- Word Semantics 单词语义
- Word meanings 单词含义
- WordNet
- Synsets 同义词集
- Noun Relations in WordNet
- Hypernymy Chain 上位链
- Word Similarity
- Word Similarity with Paths
- Beyond Path Length
- Abstract Nodes
- Concept Probability of A Node
- Similarity with Information Content
- Word Sense Disambiguation
- Supervised WSD
- Unsupervised WSD: Lesk
- Unsupervised WSD: Clustering
Introduction: sentiment analysis 引言:情感分析
在 NLP 中,我们为什么要关注词汇语义学?我们先来看一个情感分析的例子:假设现在我们有一个情感分析任务,我们需要预测一段给定文本的情感极性。
-
Bag-of-words, KNN classifier. Training data: 词袋模型,KNN分类器。训练数据
This is a good movie->positiveThis is a great movie->positiveThis is a terrible film->negativeThis is a wonderful film-> ?
-
Two problems here: 这里存在两个问题
- The model does not know that
movieandfilmare synonyms. Sincefilmappears only in negative examples, the model learns that it is a negative word. 模型不知道movie和film是同义词。由于film只在负面示例中出现,模型学习到它是一个负面词语 wonderfulis not in the vocabulary (OOV: Out-Of-Vocabulary)wonderful这个单词在词汇表中并没有出现过(OOV, Out-Of-Vocabulary)
- The model does not know that
-
Comparing words directly will not work. How to make sure we compare word meanings? 直接比较单词并不是一种很好的方法。我们应当如何保证我们是在比较单词的含义呢?
-
Solution: Add this information explicitly through a lexical database 解决方案:通过一个 词汇数据库(lexical database)来显式地加入这些信息。
Lexical Database 词汇数据库
Word Semantics 单词语义
-
Lexical Semantics: 词汇语义
- How th meanings of words connect to one another 单词含义之间如何相互联系
- Manually constructed resources 手动构建的资源:词汇表 (lexicons)、同义词词典 (thesauri)、本体论 (ontologies) 等。
我们可以用文本来描述单词的含义,我们也可以观察不同单词之间是如何相互联系的。例如:单词film和movie实际上是 同义词(synonym),所以,假如我们不知道film的意思,但是我们知道movie的意思,并且假如我们还知道两者是同义词关系的话,我们就可以知道单词film的意思。我们将看到如何通过手工构建这样的词汇数据库,这些同义词词典或者本体论捕获了单词含义之间的联系。
-
Distributional Semantics: 分布语义学
- How words relate to each other in the text 文本中的单词之间如何互相关联。
- Automatically created resources from corpora 从语料库中自动创建资源。
我们也可以用另一种方式完成同样的事情。我们的任务仍然是捕获单词的含义,但是相比雇佣语言学家来手工构建词汇数据库,我们可以尝试从语料库中直接学习单词含义。我们尝试利用机器学习或者语料库的一些统计学方法来观察单词之间是如何互相关联的,而不是从语言学专家那里直接得到相关信息。
Word meanings 单词含义
-
物理或社交世界中的被引用的对象
- 但通常在文本分析中没有用
回忆你小时候尝试学习一个新单词的场景,对于人类而言,单词的含义包含了对于物理世界的引用。例如:当你学习dog(狗)这个单词时,你会问自己,什么是dog?你不会仅通过文本或者口头描述来学习这个单词,而是通过观察真实世界中的狗来认识这个单词,这其中涉及到的信息不止包含语言学,而且还包括狗的叫声、气味等其他信息,所有这些信息共同构成了dog这个单词的含义。但是这些其他的信息通常在文本分析中并没有太大作用,并且我们也不容易对其进行表示。
- 但通常在文本分析中没有用
-
Dictionary definition: 字典定义
- Dictionary definitions are necessarily circular 字典定义必然是循环的
- Only useful if meaning is already understood 仅在已经理解含义的情况下才有用
因此,我们希望寻找一种其他方法来学习单词的含义:通过查词典学习单词含义。但是,我们会发现词典定义通常带有循环性质,我们用一些其他单词来解释目标单词。 - E.g
red: n. the color of blood or a ruby
blood: n. the red liquid that circulates in the heart, arteries, and veins of animals
Here the wordredis described bybloodandbloodis described byred. Therefore, to understandredandbloodboth meaning has to be understood
可以看到,在定义red(红色)这个单词时,我们将其描述为blood(血液)的颜色;然后在定义blood(血液)这个单词时,我们将其描述为心脏中的一种red(红色)液体。所以,我们用blood定义red,然后又用red定义blood。如果我们本身不知道这两个单词的含义,那么我们无法从定义中获得词义。但是,字典定义仍然是非常有用的,因为当我们通过字典学习一个新的单词时,我们通常已经具有了一定的词汇背景,例如当我们学习一门新的语言时,字典可以提供一些非常有用的信息。
-
Their relationships with other words. 它们与其他单词的关系
- Also circular, but better for text analysis 也是循环的,但更实用
另一种学习词义的方法是查看目标单词和其他单词的关系。同样,这种方法也涉及到循环性的问题,但是,当我们需要结合上下文使用某个单词时,这种方法非常有用,就像之前film和movie的例子。所以,单词之间的关系是另一种非常好的表征词义的方式。
- Also circular, but better for text analysis 也是循环的,但更实用
-
Word sense: A word sense describes one aspect of the meaning of a word 单词义项:单词义项描述了单词含义的一个方面
- E.g. mouse: a quiet animal like a mouse
-
Polysemous: If a word has multiple senses, it is polysemous. 多义词:如果一个单词有多个义项,那么它就是多义词。
- E.g.
- mouse1: a mouse controlling a computer system in 1968
- mouse2: a quiet animal like a mouse
- E.g.
-
Gloss: Textual definition of a sense, given by a dictionary 词义释义:由字典给出的一个义项的文本定义
-
Meaning Through Relations: 通过关系理解含义
- Synonymy(同义): near identical meaning 几乎相同的含义
- vomit - throw up
- big - large
- Antonymy(反义): opposite meaning 相反的含义
- long - short
- big - little
- Hypernymy(上位关系): is-a relation is-a 关系
- 前者为下位词 (hyponym),表示后者的一个更加具体的实例,例如
cat。 - 后者为上位词 (hypernym),表示比前者更宽泛的一个类别,例如
animal。 - cat - animal
- mango - fruit
- 前者为下位词 (hyponym),表示后者的一个更加具体的实例,例如
- Meronymy(部分-整体关系): part-whole relation 部分-整体关系
- 前者为部件词 (meronym),表示后者的一部分,例如
leg。 - 后者为 整体词 (holonym),表示包含前者的一个整体,例如
chair。 - leg - chair
- whel - car
- 前者为部件词 (meronym),表示后者的一部分,例如
Eg:
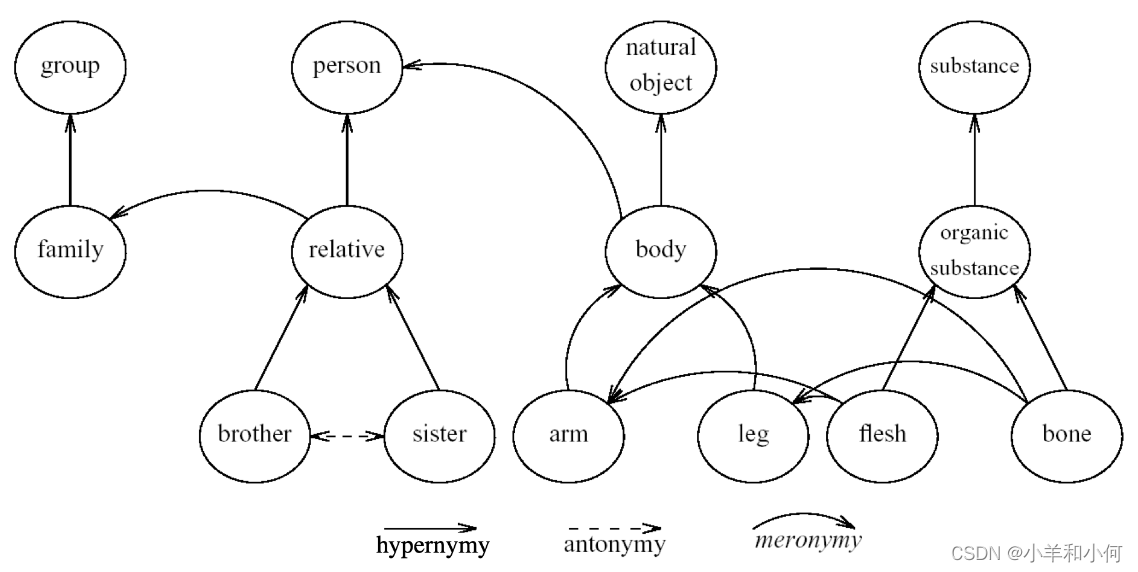
- Synonymy(同义): near identical meaning 几乎相同的含义
WordNet
-
A database of lexical relations 一个词汇关系的数据库
-
English WordNet includes ~120,000 nouns, ~12,000 verbs, ~21,000 adjectives, ~4,000 adverbs
-
On average: noun has 1.23 senses, verbs 2.16 平均来说:名词有1.23个义项,动词有2.16个义项
-
Eg:

-
可以看到,名词
bass的词义基本上可以分为两大类:音乐和鲈鱼。而 WordNet 又将其细分为了 8 个类别。但是,这种分类对于一般的 NLP 任务而言可能太细了,所以,在使用这些词义之前,我们通常会进行一些聚类(clustering)操作。
Synsets 同义词集
-
Nodes of WordNet are not words or lemmas, but senses WordNet 的节点不是单词或词形,而是义项
-
There are represented by sets of synonyms, or called synsets 这些都由一组同义词表示,或称为同义词集
-
E.g. Bass:
- {bass, deep}
- {bass, bass voice, basso}
Noun Relations in WordNet

Hypernymy Chain 上位链

Word Similarity
Word Similarity
-
Synonymy: file - movie
-
What about show - file and opera - film?
-
Unlike synonymy which is a binary relation, word similarity is a spectrum
-
Use lexical database or thesaurus(分类词词典) to estimate word similarity
Word Similarity with Paths
-
Given WordNet, find similarity based on path length
-
pathlen(c1, c2) = 1 + edge length in the shortest path between sense c1 and c2
-
Similarity between two senses:
-
Similarity between two words:
-
E.g.

Beyond Path Length
-
Problem of simple path length: Edges vary widely in actual semantic distance
- E.g. from last example tree:
- simpath(nickel, money) = 0.17
- simpath(nickel, Richter scale) = 0.13
- From the simple path length, similarity of
nickel-moneyandnickel-Richter scaleare very close. But in actual meanings nickel is much similar to money then Richter scale
- E.g. from last example tree:
-
Solution 1: include depth information
-
Use path to find lowest common subsumer (LCS)
-
Compare using depths:
High simwup when parent is deep or senses are shallow -
E.g.

-
Abstract Nodes
-
Node depth is still poor semantic distance metric. E.g.:
- simwup(nickel, money) = 0.44
- simwup(nickel, Richter scale) = 0.22
-
Node high in the hierarchy is very abstract or general
Concept Probability of A Node
-
Intuition:
- general node -> high concept probability
- narrow node -> low concept probability
-
Find all the children of the node, and sum up their unigram probabilities:
- child©: synsets that are children of c
-
E.g.

Abstract nodes in the higher hierarchy has a higher P©
Similarity with Information Content
-
Information Content:
- general concept = small values
- narrow concept = large values
-
simlin :
- High simlin when concept of parent is narrow or concept of senses are general
-
E.g
Word Sense Disambiguation
Word Sense Disambiguation
- Task: Selects the correct sense for words in a sentence
- Baseline: Assume the most popular sense
- Good WSD potentially useful for many tasks:
- Knowing which sense of mouse is used in a sentence is important
- Less popular nowadays because sense information is implicitly captured by contextual representations
Supervised WSD
- Apply standard machine classifiers
- Feature vectors are typically words and syntax around target
- Requires sense-tagged corpora
- E.g. SENSEVAL, SEMCOR
- Very time-consuming to create
Unsupervised WSD: Lesk
-
Lesk: Choose sense whose WordNet gloss overlaps most with the context
-
E.g.

Unsupervised WSD: Clustering
-
Gather usages of the word
-
Perform clustering on context words to learn the different senses
- Rationale: context words of the same sense should be similar
-
Disadvantages:
- Sense cluster not very interpretable
- Need to align with dictionary senses