本博客地址:https://security.blog.csdn.net/article/details/131033616
一、引子
数据安全采集阶段的防护措施主要是从三个方面来开展的,第一个是从个人数据主体采集方面,第二个是从外部机构采集方面,以上两个方面基本涵盖了数据采集的源头,但由于数据源头不同,所做的数据防护措施也是不一样的,第三个方面是老生常谈的数据分类分级。
二、从个人数据主体采集
从个人数据主体采集数据的防护措施主要有以下:
1、采集数据的客户端在完成对应的业务之后,本地不应该留存敏感数据,这里的客户端包含APP、Web等,同时,要及时清理客户端的缓存,防止采集的数据泄露;
2、采集数据时不应该超范围采集数据,这里主要是要做到采集的个人信息应与提供的服务直接相关,同时与合同协议条款、隐私政策中约定采集的内容保持一致;
3、采集的合规性保障,主要包括不违规采集数据,例如采集频率过高等;不隐瞒采集数据,例如实际上采集了但隐私政策等文件中没有说明;不通过诱骗、误导用户的方式来采集数据等等;
4、采集的生命周期要与业务服务周期一致,当提供的产品或服务停止运营时,数据的采集活动也要相应的停止。
三、从外部机构采集
从外部机构采集数据的防护措施主要有以下:
1、合同约束,在从外部机构采集数据时,需要通过合同协议等方式,明确双方在数据安全方面的责任及义务,明确数据采集范围、频度、类型、用途等,以此确保外部机构数据的合法合规性和真实性,必要时提供相关个人信息主体的授权;
2、约束机制,在从外部数据供应方处采集数据时,需要制定数据供应方约束机制,并明确数据源、数据采集范围和频度,并事前开展数据安全影响评估;
3、采集数据时不应该超范围采集数据,这里主要是要做到采集的企业客户数据应与提供的产品或服务直接相关,并与合同协议条款、隐私政策中约定采集的内容保持一致。
四、数据分类分级
数据分类分级是一个理论上很简单,但实际操作起来非常复杂的事情,这主要介绍数据分类分级的实践。
数据分类分级本身在数据防护中不会产生太大的价值,它的意义在于将分类分级结果输入给其他安全防护能力,之后可以对不同类别、不同级别数据进行不同的防护措施,从而开展差异化的数据安全防护。
1、建立数据分类分级制度
做数据分类分级,第一步要做的就是建立分类分级规范制度,这也是数据分类分级工作中最容易做的一步,这里主要介绍一下数据分类分级制度的思路。
在数据分类分级制度中,第一要明确数据分类分级的步骤和数据分类分级的原则,数据分类分级的步骤一般都是先细分业务、然后根据业务归类数据,之后划分数据级别,最后做后续操作。第二是对数据分类分级的步骤进行详细描述即可。同时,在该制度中还应当根据公司的具体情况列明哪些数据属于哪些类别和级别(这里列明主要数据即可)。
数据分类分级的规范制度是为后续数据全生命周期涉及到的技术和管理提供依据的。
2、建立数据分类分级平台
数据分类分级的实际工作全部都集中在数据分类分级平台上开展,那如何建立数据分类分级平台呢?答案只有一个字:买!或者两个字:自研。这个具体就不多说了。
3、数据资产梳理及接入
这里梳理的数据资产主要是指数据库,因为平台化的东西都需要结构化的数据来对接。当然,对于类似word/excel等办公文档也是需要梳理的,只是这些文档不能很好的与数据分类分级平台集成。
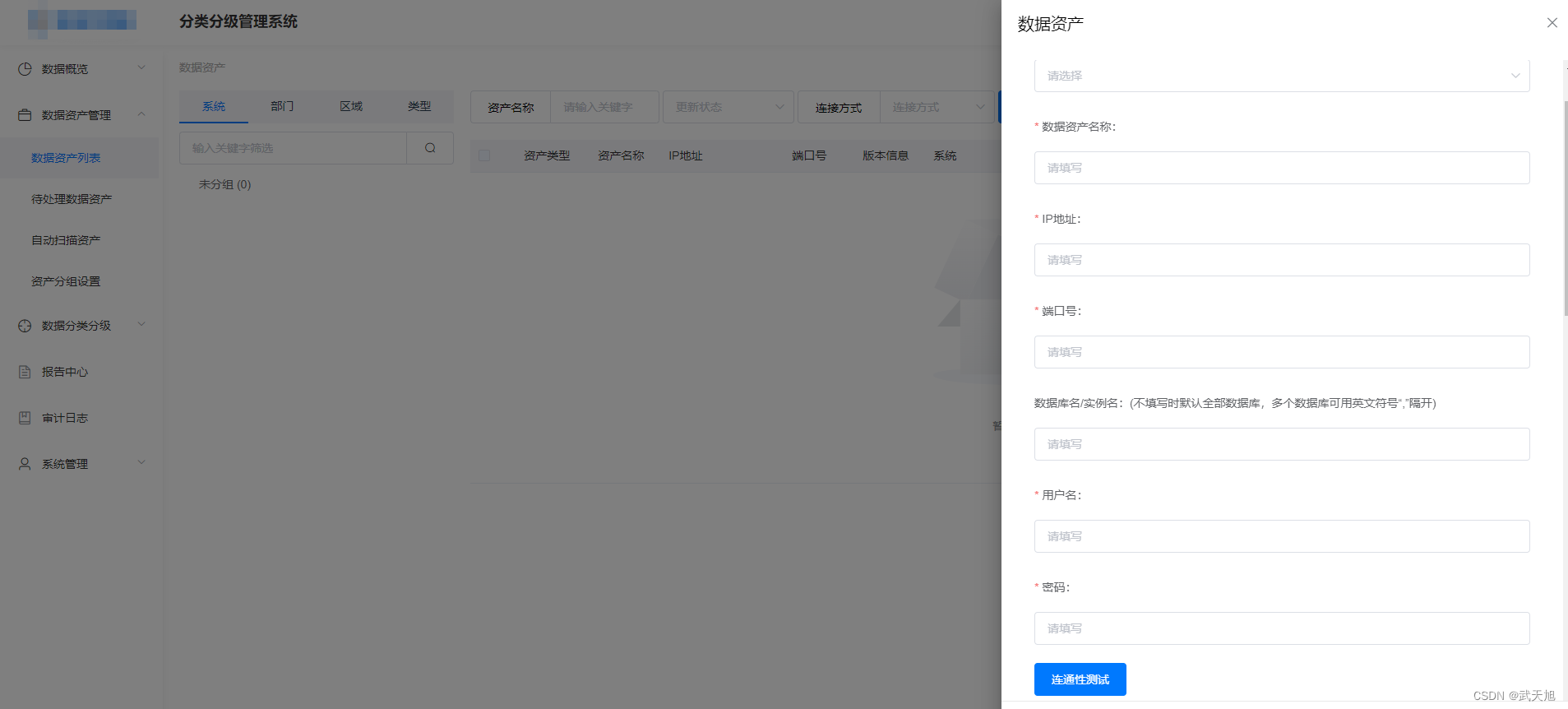
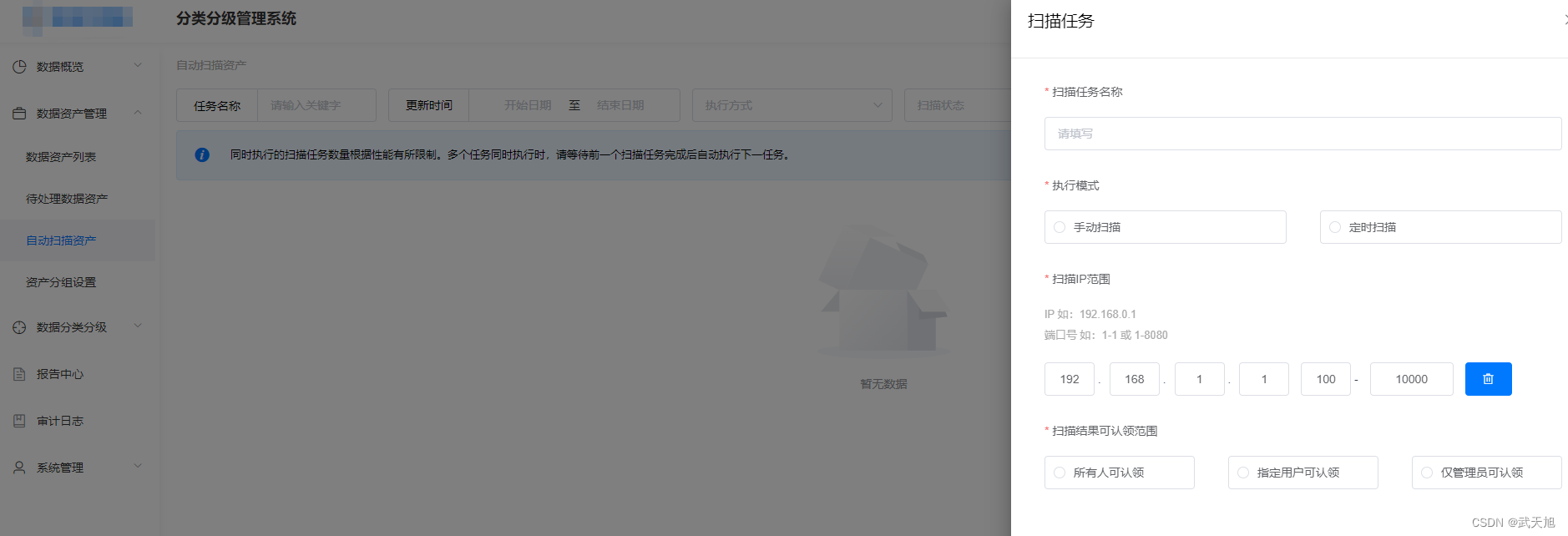
梳理完数据资产后,就需要将这些数据资产接入数据分类分级平台了,除了靠人工梳理的数据资产外,还可以通过扫描的方式发现数据资产。
人工梳理资产接入如图所示:
自动扫描发现数据资产如图所示:
4、分类分级模板维护
分类分级模板维护是数据分类分级工作中最为关键的一步,也是最难的一步。
这一步我们首先需要设计数据分类分级的架构,例如分多少个一级类多少个二级类,每个类叫啥名等等,然后分多少个级别,每个级别如何定义等等,这里主要是根据前面编撰好的数据分类分级规范来开展即可。
需要注意的是,分类分级模板需要覆盖到所有数据。在这里,我们会发现实际上的数据远比理论上的数据复杂的多,会冒出很多奇奇怪怪的数据字段出来,例如这个名称那个类型的种种,所以在分类分级制度中我有提到,我们只需要列举主要字段所在的类别和级别就可以了,因为制度中是写不全的。
另外,实际中的数据还会存在诸多问题,例如姓名字段,有叫name、names、username、usersname、xingming、yonghu、yonghuming、shouhuoren……等等各式各样的名称,如果数据库中的字段没有写备注,那就只能靠挨个排查,而面对天量的数据库,这是一个很难完成的工作。除此之外,还有例如在这个库中username字段是指姓名,而另一个库中username是指口令名(可能是邮箱、QQ号、手机号之类的东西),导致同一个字段的释义是完全是两个不同的概念。
除以上之外,实际的数据库中还有很多其他问题,就不一一例举了,这些问题会严重影响分类分级模板的准确性与维护的难度!
目前对于分类分级模板的维护尚未有较好的解决办法,相对比较柔和的办法是每个库都维护一个独立的分类分级模板,毕竟就单一库来说,存在一些坑爹问题的概率要低很多。而分类分级模板可以直接复制,这样相同字段的规则就可以直接使用了。
模板如下所示(图片不涉及泄密,因为这是官方的demo):

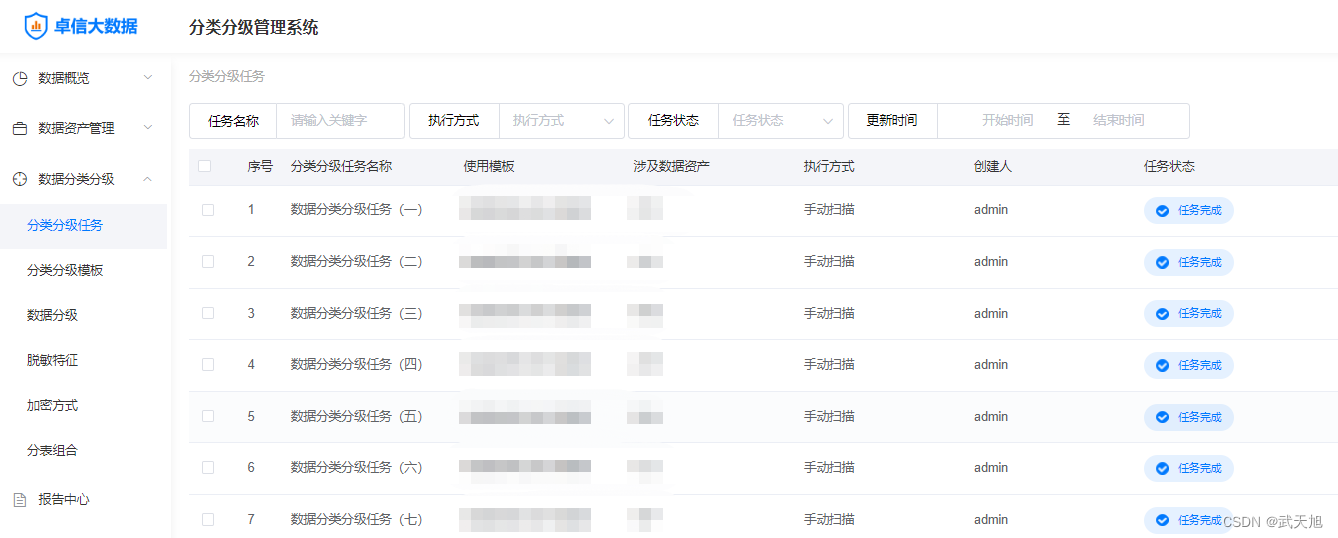
5、分类分级任务执行
分类分级模板设置完成之后,选中对应的数据资产使用分类分级模板执行分类分级任务即可,分类分级任务是一键执行的。
那这里我们主要做什么工作呢?这里主要关注并解决的问题是:由于分类分级模板的不完善,导致部分数据字段没有被匹配到或者匹配错误的问题。
对于以上两个问题,主要的解决办法是通过回头完善分类分级模板,之后再次执行分类分级任务。同时也可以对未匹配到的数据字段进行人工打标,即人工指定该字段所属的类型与级别。
这里的工作量主要取决于产生问题的数据字段的多少,如果产生问题的数据字段不多,则可以很快完成问题字段的修补,如果产生问题的数据字段很多,则工作量较大。
将所有数据字段都划分到对应的类别和级别后,数据分类分级工作就算是基本完成了,至于分类分级数据的报表这种,一般平台会自动生成,后续主要维护好新增数据库表和新增数据字段即可。
分类分级任务执行如图所示:
分类分级数据报表如图所示:
6、联动其他防护平台
我们前面说到,单纯的只做数据分类分级工作并没有特别大的价值,分类分级的目的是为了对数据进行更好的差异化管理,而不是一把梭式的管理,所以对数据做完分类分级后,需要将分类分级的结果对接到其他的防护平台中进行差异化防护。
举个例子,我们将数据分类分级结果对接到OA审批系统中,即可实现数据外发审批的自动化,当数据是公开级别时,可自动判定无审批通过,当数据级别不是公开级别时,将依据不同的数据级别自动对接不同的审批层级。
再举个例子,我们将数据分类分级的结果对接到数据防泄漏系统中,公开级别的数据外发不会触发DLP的拦截规则,而不是公开级别的数据外发,则会根据外发数据的敏感度、数据量来触发不同的告警。
总体来说,使用数据分类分级工具可以帮助我们完成资产的梳理与发现工作,并大大降低了数据分类分级的难度,弥补手工分类分级的各种短板。