K最近邻(KNN,K-NearestNeighbor)分类算法,是比较经典的分类算法,是将数据集合中每一个记录进行分类的方法,属于懒惰性学习算 法,只有当需要分类的向量到达时才开始构造泛化模型。是数据挖掘分类技术中最简单的方法之一。
算法中的每个样本都可以用它最接近的K个邻近值来代表。KNN算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
基本原理
在样本集中找出与 待分类向量 tVec 最相似的 k 个向量,然后统计这 k 个向量中 出现次数最多的类别,把 tVec 归属为此类。KNN算法主要涉及样本集、相似度的衡量、k 大小3个因素。
- 样本集也被称为训练集,是带有类别属性的向量集合;
- 两个向量的相似度一般通过计算它们的欧氏距离或余弦 度来衡量;
- k 的大小直接影响KNN算法的时空效率,如果 k 取值太小则容易受噪声的影响,k 取值过大,则近 邻中可能又包含过多其他类的数据点,因此一般情况 下, k 的取值一般不大于样本集的平方根。
KNN算法流程
步骤1 准备并预处理数据,即把样本数据和待分类数据采用合适的数据结构存储起来。
步骤2 设定参数 k ,从样本集随机抽取 k 个向量用来初始化大小为 k 的优先级队列,即分别计算 tVec 到这 k 个向量的欧氏距离(dis),然后把样本向量及其 dis存入优先级队列。
欧氏距离的计算公式为:(其中 xs、 xt 分别代表 d 维的样本向量和待分类向量, i 表示第 i 维的分量。 )
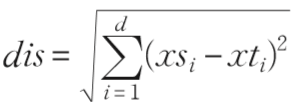
步骤3 遍历样本集中每个向量到 tVec 的 dis ,并将 dis 与优先级队列中的最大距离 (disMax) 比较大小, 若 dis<disMax ,则 disMax 及对应的向量出队,当前被 遍历到的向量及其 dis插入到优先级队列;否则,忽略当 前向量,继续在样本集中遍历下一个向量。
步骤4 遍历完毕得到与 tVec 距离最近的 k 个样本 向量集合(topK),统计出 k 个近邻中包含向量个数最多的类别,并把 tVec 归属到此类。
另一个博主实现的KNN例子:https://blog.csdn.net/saltriver/article/details/52502253
参考论文《基于Storm的流数据KNN分类算法的研究与实现》
论文中还涉及基于Storm的流数据KNN分类算法(S-KNN),算法拓扑图如下:

SDIpt和TDIpt分别代表样本集和待分类数据的数据源;
Partition负责对样本集的数据划分;
SKNNBolt是 负责计算 tVec 的pTopK的具体Bolt;
WRKNN由多个 Bolt组成,这里的每个Bolt称为WRKNNBolt,负责汇总 tVec 的pTopK成wTopK;
RetBolt是负责对 tVec 归类的 Bolt。
具体流程见原论文。