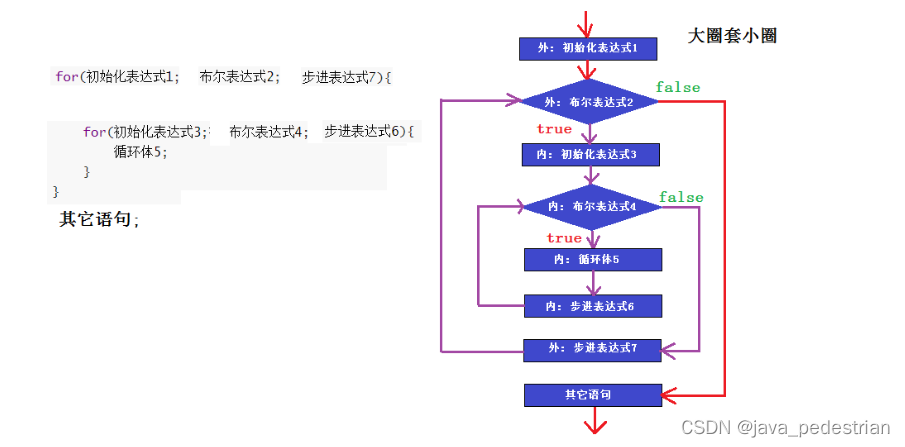
- 数据库优化通常是为了减轻对数据库压力,优化方式可以从使用缓存、数据库配置、sql和索引优化入手;
使用缓存可以将系统请求先打向缓存,如果缓存中有我们要获取的数据,那将不会再走数据库。
数据库配置方面是指可以通过修改数据库配置文件入手,将服务器资源利用率最大化。
sql和索引优化中我们知道在写sql的时候正确的使用索引能够大幅度提高执行速度,比如多表关联时数据量很大的时候,关联条件涉及的字段可以使用普通索引和组合索引。
·
·
·
- sql上的优化可以是
尽量让它避免全表扫描、
使用到索引、
减少无用字段的查询。
·
·
·
- 举几个列子
1.在进行模糊检索的时候尽量避免字段开头使用全表扫描
2.需要使用条件的时候可以通过使用union联合关键字来替换
3.尽量避免null空值判断,可以通过设置默认值来用默认值判断
4.where条件中的等于号左边尽量避免复杂的表达式
5.避免select * 这种sql的出现,这会增加是数据库解析成本
6.避免无用字段的查询,无用字段的查询会增加网络消耗,也增加解析成本
等等。 - 另外还可以通过分库分表的方式对数据库结构优化。
·
·
·
-
聚集索引(主键索引(唯一索引))也称聚族索引
保证数据的唯一性 -
唯一索引
避免数据列值重复 -
普通索引
快速检索数据 -
全文索引
大数据集情况下快速检索数据
·
·
·
- 在InnoDB中,索引是使用B+树来作为索引结构,根据其叶子节点的不同可以分聚集索引和非聚集索引;
聚集索引就是所谓的主键索引,其所在的叶子节点存储的是整行数据,在检索索引的时候检索到就直接返回整行数据;
非聚集索引所在的节点存储的其实是行数据主键的值,检索过程中,当根据非聚集索引检索到对应节点会返回节点存储的行数据主键的值,
然后去检索主键索引树拿到要检索的数据,这个过程就是回表。
·
·
·
- 避免回表:
1.尽量使用主键
2.查询的时候用到的索引在检索列中出现就不会回表。
3.根据实际情况考虑用组合索引,使其能够在一颗B+树就能检索到需要的数据。