用python操作ms sql server,有好几种方法:
(1)利用pymssql (2)利用pyodbc
这里讲import pyodbc来操作sql server database。
pyodbc是Python包,使用ODBC驱动器来连接SQL Server数据库,其中pyodbc的基本类型是Connection,Cursor、Row
其中,Connection表示客户端和数据库的连接,并用于提交事务;
Cursor表示向数据库发送的查询请求;
Row表示获取的结果集。
首先查看自己电脑有没有安装sql server对应的odbc,在控制面板中可以查:
控制面板-->管理工具-->数据源(ODBC)
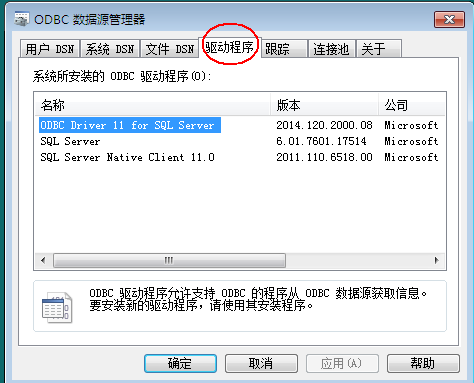
我电脑的版本是 ODBC Driver 11 for SQL Server
不同电脑安装了不同的sql server版本,可能driver不同,有可能是12、13、19等等版本。
然后利用powershell下载安装pyodbc包,如图输入
pip install pyodbc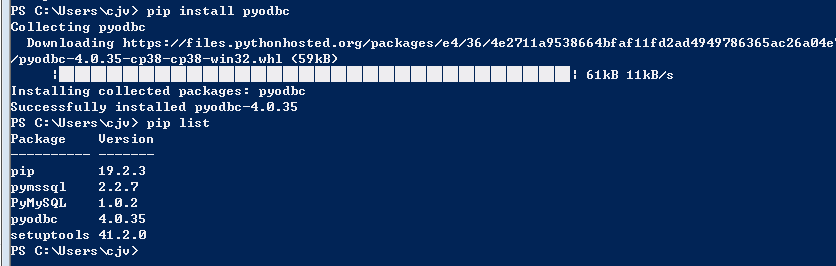
下载成功之后,输入看看有没有成功安装package
pip list成功安装package之后,就可以开始编辑python代码了。
代码如下(两个文件DBHelp_SqlServer.py 和 testConn.py):
文件1(DBHelp_SqlServer.py)
import pyodbcclass MSSQL:def __init__(self, IP, UserID, Pwd, db):self.host=IP;self.user=UserID;self.password=Pwd;self.dbname=db;def __getConnect(self):if not self.dbname:raise(NameError,"db name undefine error")else:connSTR="Driver={ODBC Driver 11 for SQL Server};SERVER=%s,1433;DATABASE=%s;UID=%s;PWD=%s" % (self.host, self.dbname, self.user, self.password)##example: Driver={ODBC Driver 11 for SQL Server};SERVER=127.0.0.1,1433;DATABASE=MyTestDB;UID=sa;PWD=Abc123self.conn = pyodbc.connect(connSTR);cu= self.conn.cursor();if not cu:raise(NameError,"db connect error");else:return cu;def ExecuteTableQuery(self,selectSql):cuu = self.__getConnect();selectRows = cuu.execute(selectSql);resList=selectRows.fetchall();self.conn.close();return resList;def ExecuteNonQuery(self,sql):cuu = self.__getConnect();cuu.execute(sql);self.conn.commit();self.conn.close();def PrintODBCDrivers(self):print(pyodbc.drivers() );文件2(testConn.py)
import DBHelp_SqlServerdb=DBHelp_SqlServer.MSSQL(IP="127.0.0.1", UserID="sa", Pwd="Abc123", db="MyTestDB");sqlinsert="insert into TeacherTable(TName,TClass) values('吕老师','三年级')"
db.ExecuteNonQuery(sql=sqlinsert);sql1="select * from TeacherTable";
datatable = db.ExecuteTableQuery(selectSql=sql1);
print(datatable);运行之后就能看到insert sql和select sql的结果了。
备注:如果使用pymssql,可能会出现中文乱码的问题,我搞不懂怎么解决。而使用pyodbc就没出现乱码。哪个简单用哪个。