Attention-自注意机制
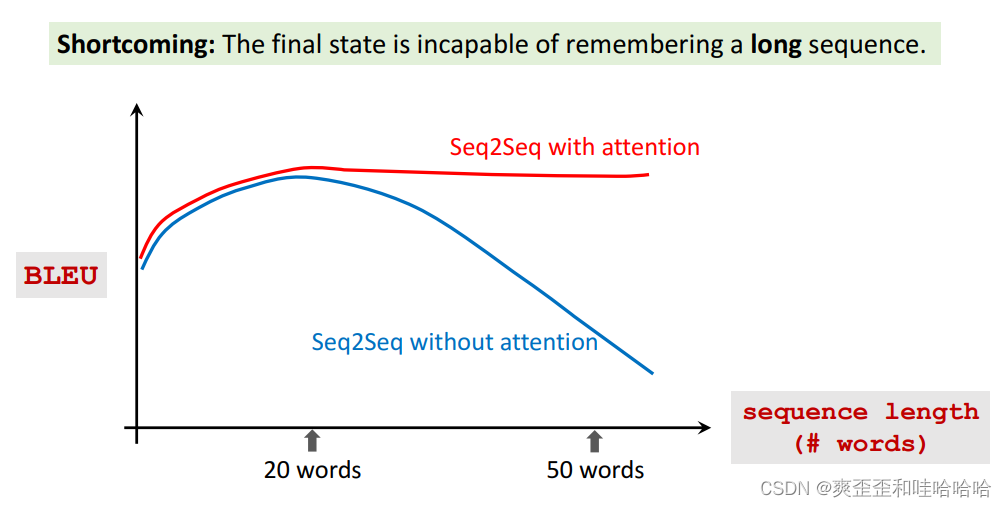
Attention 可以大幅提升seq2seq的遗忘问题。有了Attention,Seq2Seq 模型不会忘记源输入,且decoder解码器就知道该把注意力集中在哪里。
缺点: 计算量大得多
Original paper:
• Bahdanau,Cho,& Bengio. Neural machine translation by jointly learning to align and translate. In ICLR, 2015.
Attention会记录第i个状态hi和当前状态s0的相关性 align,记为权重ai, 所有的a加起来等于1.
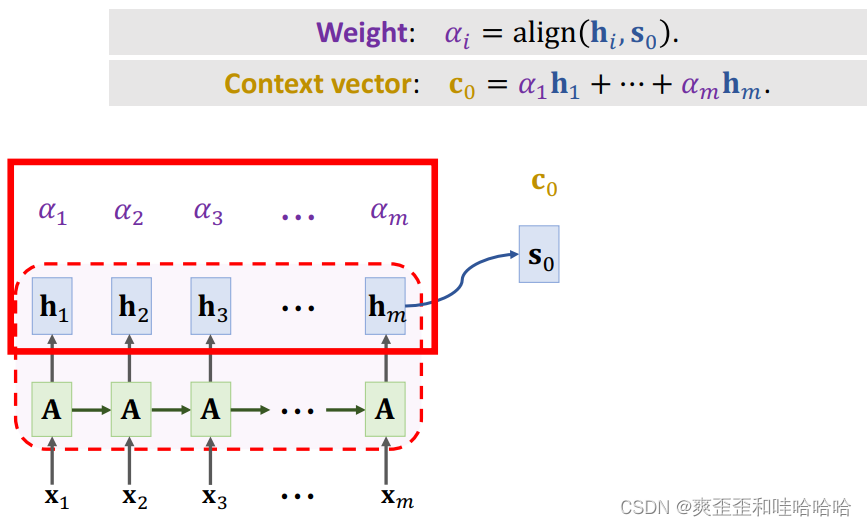
计算ai有很多方法。
第一种方法:(V T 矩阵 都是训练的参数)

第二种方法:

Context vector: C0 = a1h1 + …+ amhm.
C0知道输入x1-xm的完整信息,解决遗忘问题
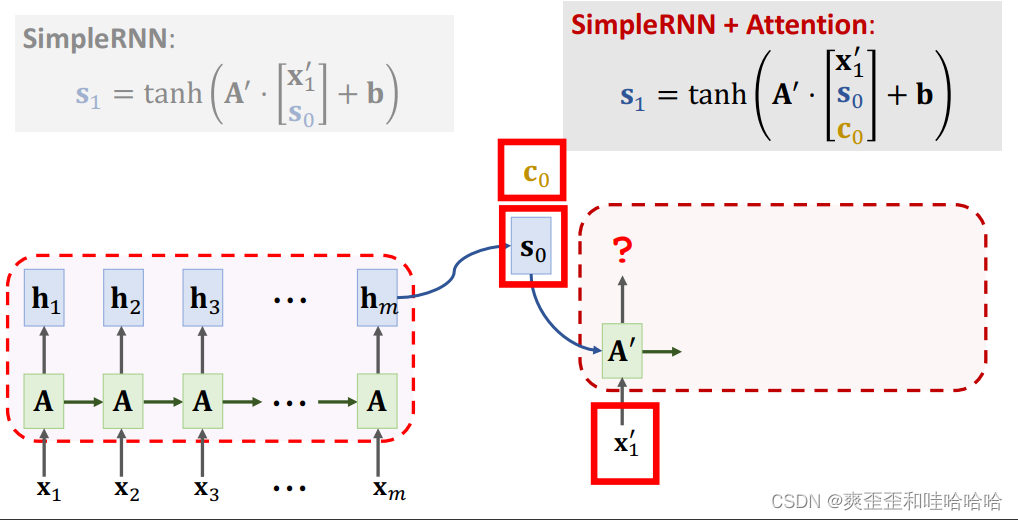 a每次要更新!
a每次要更新!
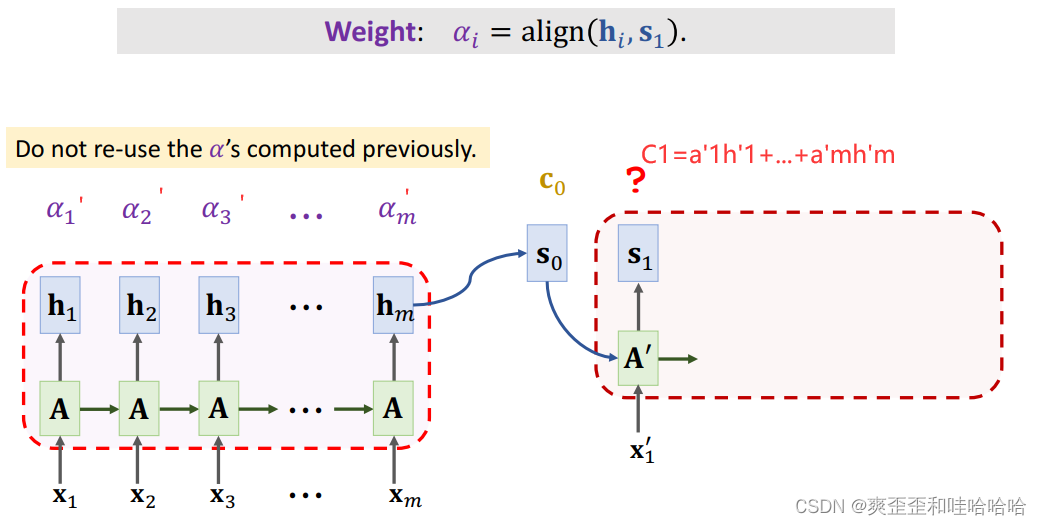
为了计算一个向量Cj,我们计算权重: a1 …am。
解码器到状态t时,我们一共计算了mt个权重。
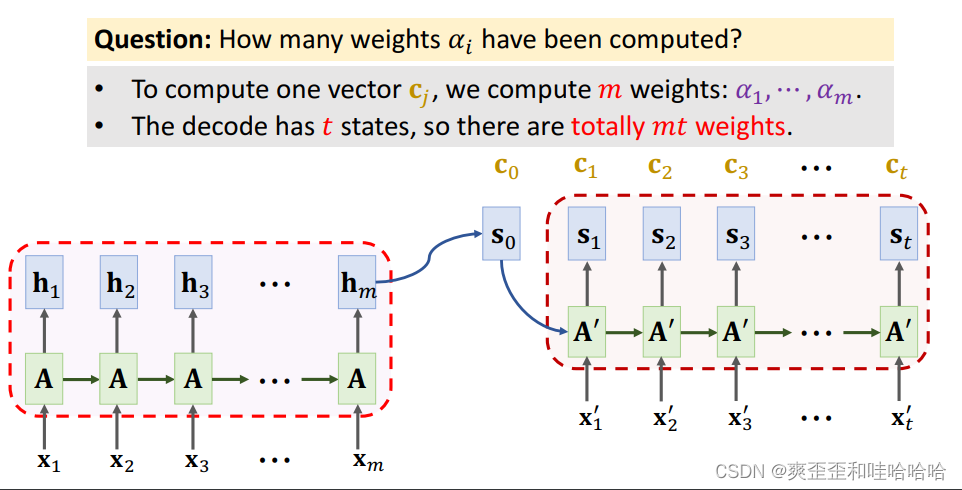
所以attention解决了遗忘问题,提高了准确率,但是代价就是计算量的提高。