目录
前言
一、获取数据展示参数
二、可选展示选项
1.describe_option()
2.get_option()/set_option()
3.reset_option()
4. option_context()
三、 在Python/IPython环境中设置启动选项
四、常用选项
1.display.max_rows/display.max.columns
2.display.expand_frame_repr
3.display.large_repr
4.display.max_colwidth
5.display.max_info_columns
6.display.max_info_rows
7.display.precision
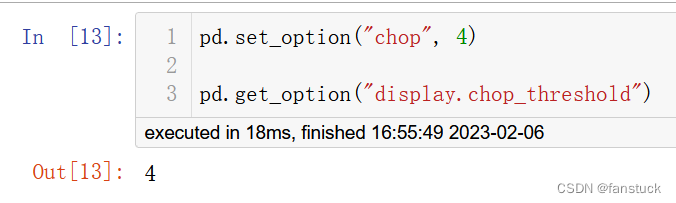
8.display.chop_threshold
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
前言
Pandas选项一般在数据展示和分析使用的比较频繁,尤其是配合上Jupyter Notebook使用敏捷开发时进行数据展示时,总会遇到一两个展示的问题比较头疼。而这又会牵扯到很多可视化效果的问题(比如pandas表默认科学计数法,无法展示全部数据等)。故了解Pandas选项设置是有必要的,这篇文章我会将一些pandas常用的选项设置元素一一列出其作用以及代码修改效果,另外会列出pandas部门优化选项设置,帮助更好的使用pandas。
Pandas数据分析系列专栏已经更新了很久了,基本覆盖到使用pandas处理日常业务以及常规的数据分析方方面面的问题。从基础的数据结构逐步入门到处理各类数据以及专业的pandas常用函数讲解都花费了大量时间和心思创作,如果大家有需要从事数据分析或者大数据开发的朋友推荐订阅专栏,将在第一时间学习到Pandas数据分析最实用常用的知识。此篇博客篇幅较长,涉及到数据可视化等各类操作,值得细读实践一番,我会将Pandas的精华部分挑出细讲实践。博主会长期维护博文,有错误或者疑惑可以在评论区指出,感谢大家的支持。
一、获取数据展示参数
panda有一个选项API,用于配置和定制与DataFrame显示、数据行为等相关的全局行为。
选项具有完整的“虚线样式”,不区分大小写的名称(例如display.max_rows)。可以直接获取/设置选项作为顶级选项属性的属性:
pd.options.display.max_rows 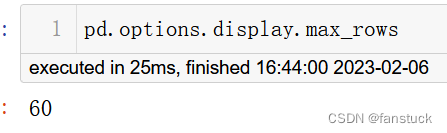
默认最大为60行展示 ,可以自定义修改:
pd.options.display.max_rows = 999pd.options.display.max_rows 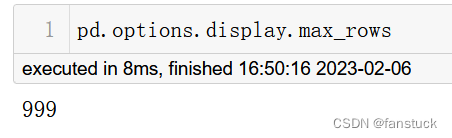
API由5个相关函数组成,可直接从panda命名空间获得:
- get_options()/set_option()-获取/设置单个选项的值。
- reset_option()-将一个或多个选项重置为默认值。
- describe_option()-打印一个或多个选项的描述。
- option_context()-使用一组选项执行代码块,这些选项在执行后恢复到以前的设置。
上面的所有函数都接受regexp模式(re.search样式)作为参数,以匹配明确的子字符串:
以下选项将不起作用,因为它匹配多个选项名称,例如display.max_colwidth、display.max.rows、display_max_columns。
二、可选展示选项
1.describe_option()
可以使用describe_option()获取可用选项及其描述的列表。当在没有参数的情况下调用describe_option()时,将打印出所有可用选项的描述。
pd.describe_option()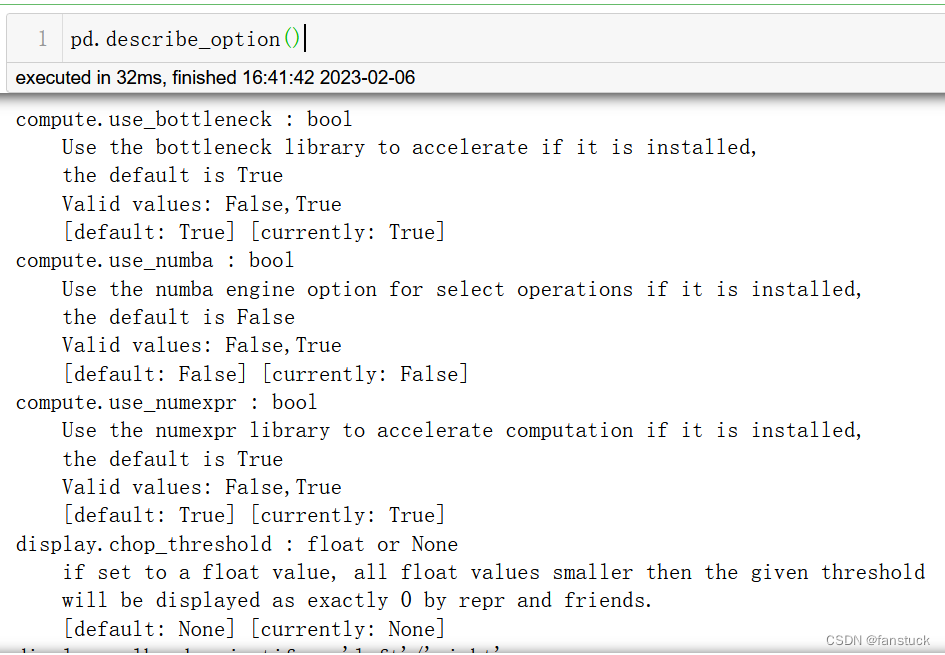
2.get_option()/set_option()
如上所述,get_option()和set_option()可从panda命名空间获得。要更改选项,则调用set_option(“选项正则表达式”,new_value)。
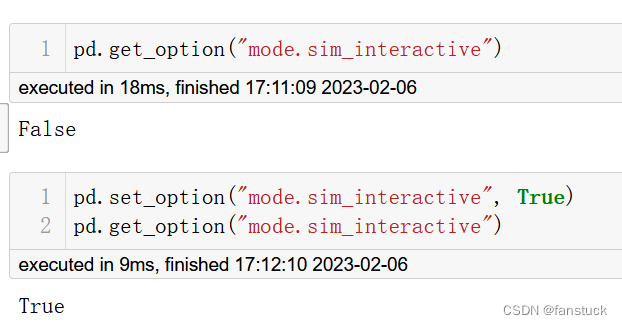
选项“mode.sim_interactive”主要用于调试目的。
3.reset_option()
您可以使用reset_option()还原为设置的默认值
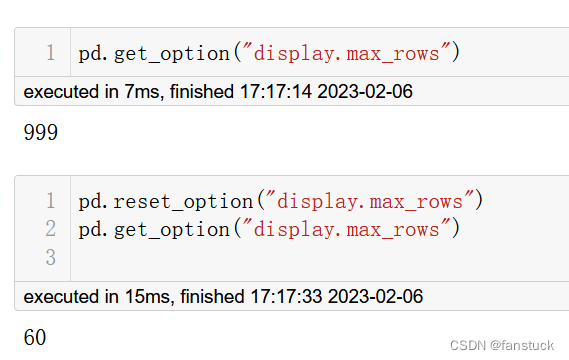
也可以一次重置多个选项(使用正则表达式):
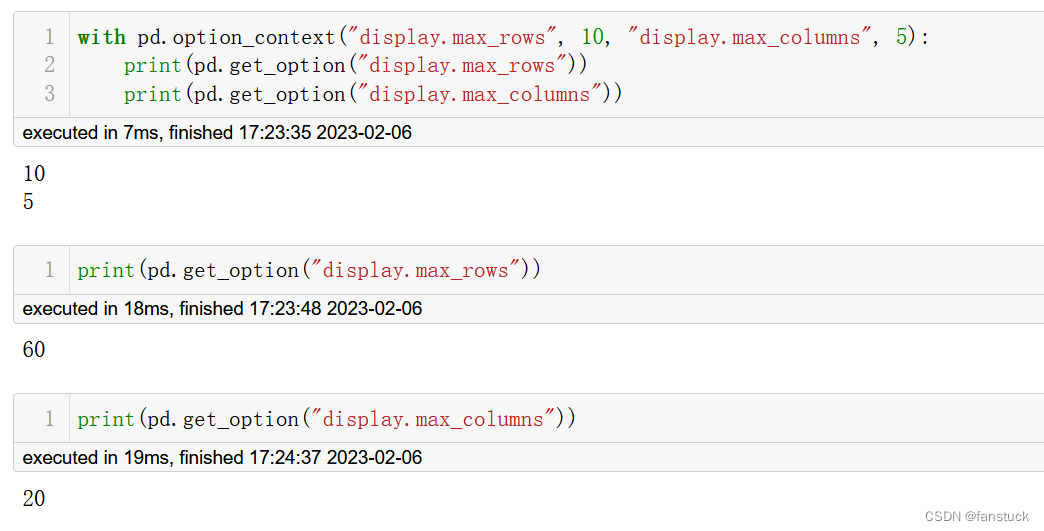
pd.reset_option("^display")4. option_context()
option_context()上下文管理器已通过top-levelAPI公开,允许使用给定的选项值执行代码。退出with块时,选项值将自动重置:
三、 在Python/IPython环境中设置启动选项
在Python/IPython环境中使用启动脚本来导入panda并设置选项,可以提高panda的工作效率。为此,在所需配置文件的启动目录中创建.py或.ipy脚本。启动文件夹位于默认IPython配置文件中的示例可以在以下位置找到:
$IPYTHONDIR/profile_default/startup更多信息可以在IPython文档中找到。panda的启动脚本示例如下:
import pandas as pdpd.set_option("display.max_rows", 999)
pd.set_option("display.precision", 5)四、常用选项
1.display.max_rows/display.max.columns
display.max_rows和display.max.columns设置显示的最大行数和列数。
pd.set_option("display.max_rows", 8)pd.set_option("display.min_rows", 4)2.display.expand_frame_repr
display.expand_frame_repr允许DataFrame的表示在页面上延伸,覆盖所有列。
df = pd.DataFrame(np.random.randn(5, 50))pd.set_option("expand_frame_repr", True)df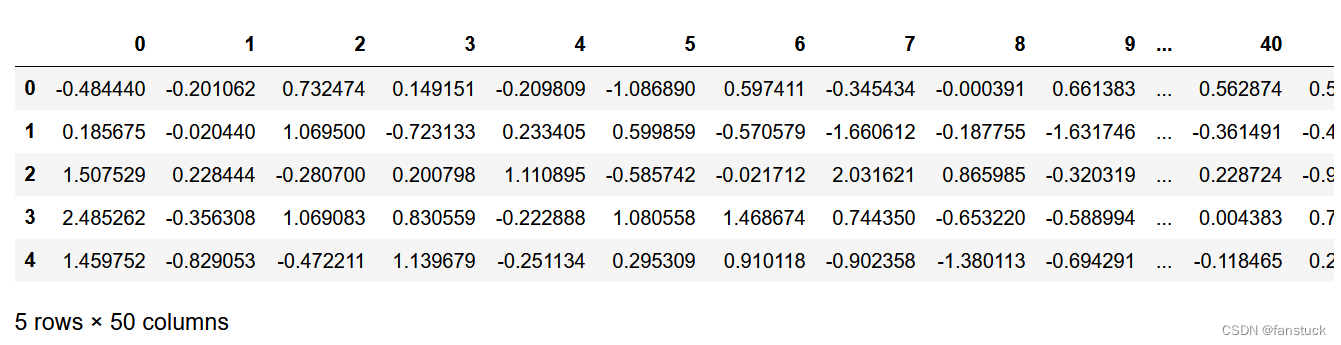
3.display.large_repr
display.large_repr将超过max_columns或max_rows的数据帧显示为截断帧或摘要。
df = pd.DataFrame(np.random.randn(10, 10))
pd.set_option("display.max_rows", 5)
pd.set_option("large_repr", "truncate")
df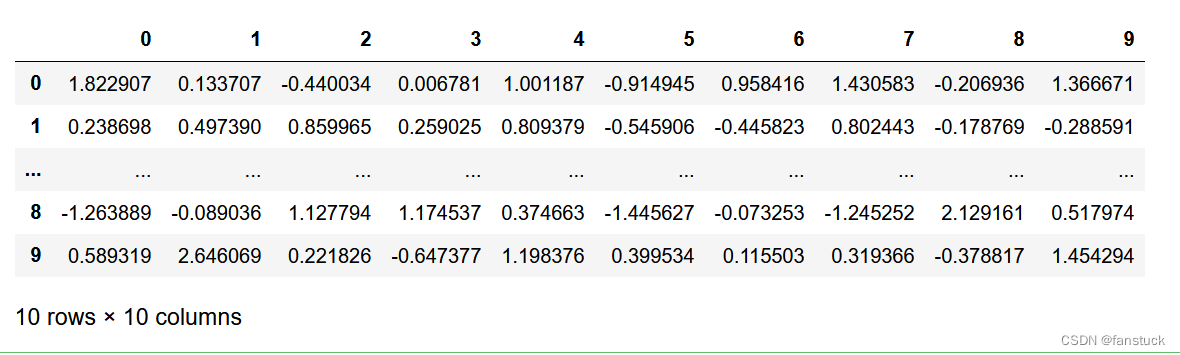
pd.set_option("large_repr", "info")
df 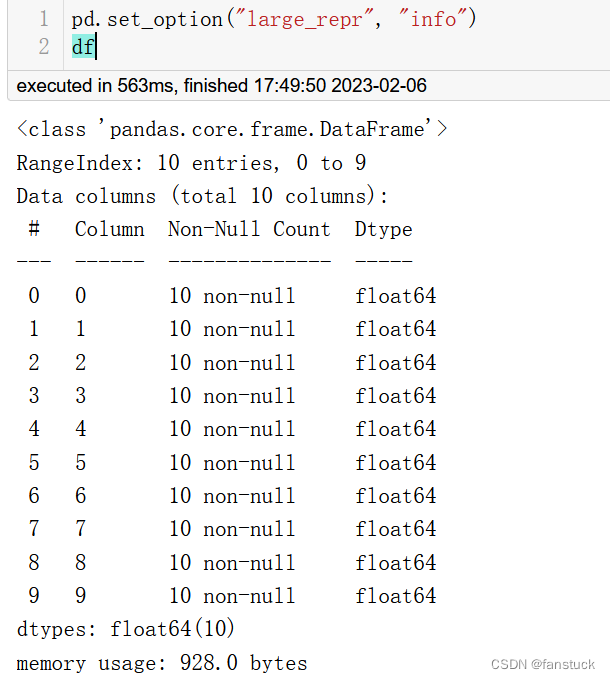
4.display.max_colwidth
display.max_colwidth设置列的最大宽度。此长度或更长的单元格将用省略号截断。
df = pd.DataFrame(np.array([["foo", "bar", "bim", "uncomfortably long string"],["horse", "cow", "banana", "apple"],])
)
pd.set_option("max_colwidth", 40)
df 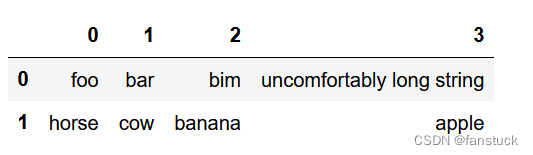
pd.set_option("max_colwidth", 6)
df 
5.display.max_info_columns
为调用info()时显示的列数设置阈值。
df = pd.DataFrame(np.random.randn(10, 10))pd.set_option("max_info_columns", 11)df.info() 
pd.set_option("max_info_columns", 5)
df.info() 
6.display.max_info_rows
info()通常会显示每列的空计数。对于大型DataFrame,这可能非常缓慢。max_info_rows和max_info_cols分别将空检查限制到指定的行和列。info()关键字参数null_counts=True将覆盖此属性。
df = pd.DataFrame(np.random.choice([0, 1, np.nan], size=(10, 10)))
df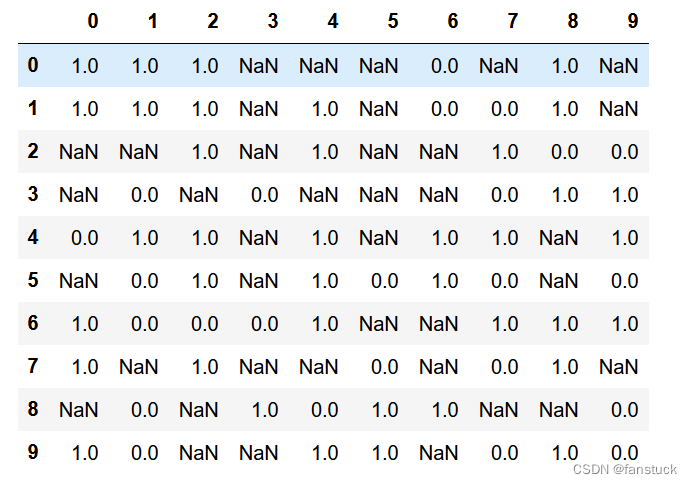
pd.set_option("max_info_rows", 11)
df.info() 
7.display.precision
display.precision以小数位数设置输出显示精度。
df = pd.DataFrame(np.random.randn(5, 5))
pd.set_option("display.precision", 7)
df 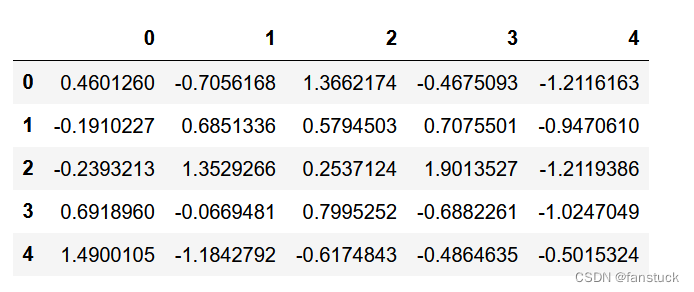
pd.set_option("display.precision", 4)
df 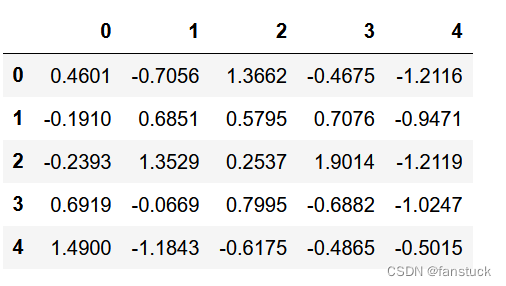
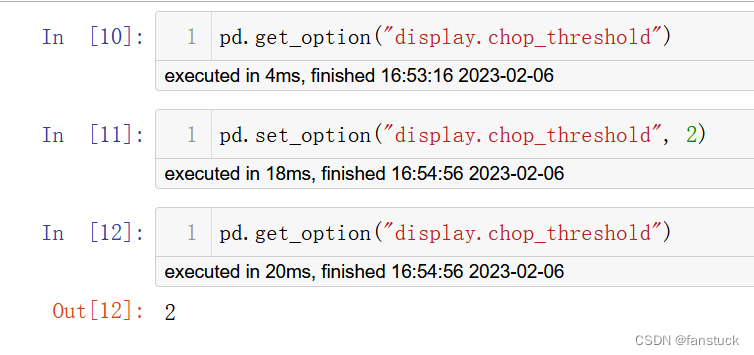
8.display.chop_threshold
显示Series或DataFrame时,将舍入阈值设置为零。此设置不会更改存储数字的精度。
df = pd.DataFrame(np.random.randn(6, 6))
pd.set_option("chop_threshold", 0)
df 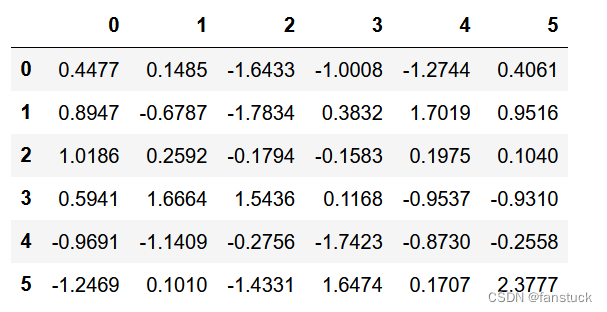
pd.set_option("chop_threshold", 0.5)
df 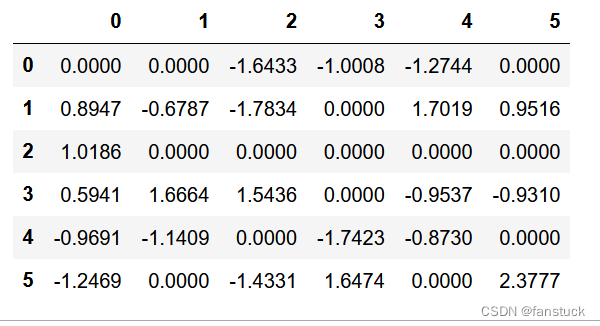
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。