摘抄自CUDA并行程序设计 GPU编程指南:1.11
1.11.1 OpenCL
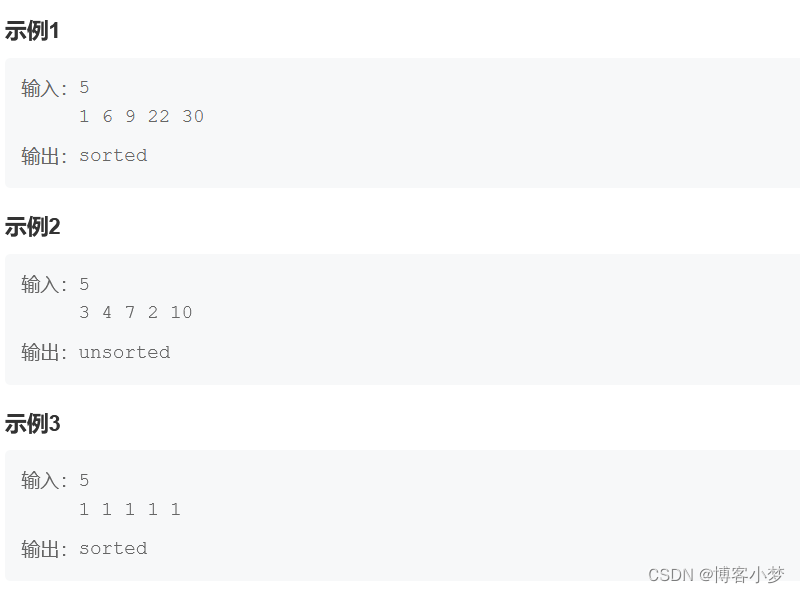
那么其他的 GPU 制造商,如 ATI(现在是AMD)能够成为主要的厂商吗? 从计算能力上看,AMD 的产品和英伟达的产品是旗鼓相当的。但是,在英伟达引入 CUDA 很长时间之后,AMD 才将流计算技术引入市场。从而导致英伟达针对 CUDA 可用的应用程序要远远多于AMD/ATI在其技术框架上的应用程序。
OpenCL(Open Computing Language)和“直接计算”( Direct Compute)不是本书详细讨论的内容,但是作为 CUDA 的替代选择,应当提及。目前,CUDA 仅仅能够正式运行于英伟达的硬件产品上。虽然英伟达在 GPU 市场上占有很大的份额,但是其他竞争者所拥有的份额也不小。作为开发者,我们希望开发出的产品能够面向的市场越大越好,尤其是消费者市场。同样的,人们也关心是否有能够同时支持英伟达和其他厂商硬件产品的 CUDA 的替代品。
OpenCL 是一个开放的、免版税的标准,由英伟达、AMD 和其他厂商所支持。OpenCL的商标持有者是苹果公司,它制定出一个允许使用多种计算设备的开放标准。计算设备可以是GPU、CPU 或者其他存在OpenCL驱动程序的专业设备。截至2012 年,OpenCL 支持绝大多数品牌的 GPU设备,包括那些至少支持 SSE3(SSE3 是 Streaming SIMD Extensions 3 的缩写,表示“单指多数据流扩展指3”。)的CPU。
任何熟悉CUDA 的程序员都可以相对轻松地使用 OpenCL,因为它们的基础概念十分相似。但是,与CUDA 相比,使用 OpenCL 会复杂一些,因为很多由 CUDA 运行时API(应用程序编程接口)所完成的功能,在OpenCL 中需要由程序员显式地编程实现。
在 http://www.khronos.org/opencl/ 网站上有更多关于OpenCL的内容。而且也有很多关于OpenCL的书籍。我个人推荐:在学习 OpenCL之前,先学习 CUDA。因为在某种意义上讲,CUDA 是一种比 OpenCL 更高级的语言扩展。
1.11.2 DirectCompute
DirectCompute 是微软开发的可替代CUDA和OpenCL的产品。它是集成在 Windows 操作系统,特别是 DirectX 11 API上的专用产品。对于之前从事显卡编程的人来说,DirectXAPI是一个巨大的飞跃。这种产品使得开发者只需掌握一个 API库,就可以对所有的显卡进行编程,而不必为每个主要的显卡生产商编写或发布驱动程序。
DirectX 11是最新的标准并且 Windows 7 操作系统能够支持它。由于标准背后的支持商是微软,你可以想象得到它会被开发者群体迅速接受。对于已经熟悉 DirectX API的开发人员,情况更是这样的。如果你熟悉CUDA和 DirectCompute,那么将一个CUDA 应用程序移植到 OpenCL的确是一项轻松的任务。据微软所言,对同时熟悉两种产品的人来说,这通常仅仅是一个下午的工作量。但是,由于以 Windows 操作系统为核心,DirectCompute 技术被排除在各种版本的 UNIX 占主导地位的高端系统之外。
微软还推出了基于 C++的AMP (加速大规模并行计算)库,它标准模板库(StandardTemplate Library,STL)的补充部分。对于熟悉 C++ 风格的STL的程序员,它更具有吸引力。
1.11.3 CPU的替代选择
主要的并行程序设计扩展语言有 MPI和OpenMP,在 Linux 下开发时,还有 Pthreads。Windows 操作系统下有 Windows 线程模型和OpeMP。MPI和Pthreads 被用作与UNIX进行
联系的接口。
MPI(Message Passing Iterface)可能是目前使用最广泛的消息传递接口。它是基于进程的,通常在各个大规模计算实验室中得到应用。它需要一个系统管理员来正确地安装配置,并且它适合于可控的计算环境。它实现的并行处理表现为,在集群的各个节点上,派生出成百上千个进程,通常这些进程通过基于网络的高速通信链路(如,以太网或ImfniBand显式地交换消息,以协同完成一个大的任务。MPI被广泛使用和学习。在可控的集群环境下它是一个很好的解决方案。
OpenMP(Open Multi-Processing)是专门面向单个节点或单个计算机系统而设计的并行计算平台,它的工作方式是完全不同的。在使用 OpenMP 时,程序员需要利用编译器指令精确写出并行运算指令。然后编译器根据可用的处理器核数,自动将问题分为N部分。很多编译器对 OpenMP 的支持都是内嵌的,包括用于CUDA的NVCC 编译器。OpenMP 希望根据底层的 CPU 架构,实现对问题的可扩展并行处理。但是,CPU 内的访存带宽常常不够大满足不了所有核连续将数据写人内存或者从内存中取出数据的要求。
pthreads 是一个主要应用于 Linux 上的多线程应用程序库。同OpenMP一样,pthreads使用线程而不是进程,因为它是设计用来在单个节点内实行并行处理的。和 OpenMP 不同的是,线程管理和线程同步由程序员来负责。这提供了更多的灵活性,因此精心设计的程序会带来很好的性能。
ZeroMO (0MQ)也值得一提,这是一个你可以链接的简单的库。在本书的后面,我们将使用它来开发一个多节点、多GPU 的例子。ZeroMO 使用一个跨平台的API来支持基于线程、基于进程和基于网络的通信模型。Linux 和 Windows 平台都支持 ZeroMQ。它是针对分布式计算而设计的,所以连接是动态的,节点失效不会影响它的工作。
Hadoop 也是你应当考虑的技术。Hadoop 是谷歌MapReduce 框架的一个开源版本。它针对的是 Linux 平台。其概念是你取来一个大数据集然后将其切或映射 (map)成很多小的数据块。然而,并不是将数据发送到各个节点,取而代之的是数据集通过并行文件系统已经被划分给上百个或者上千个节点。因此,归约(reduce)步骤是把程序发送到已经包含数据的节点上。输出结果写入本地节点并保存在那里。后续 MapReduce 程序取得之前的输出并以某种方式对其进行转换。由于数据实际上映射到了多个节点上,因此它可以应用于高容错和高吞吐率系统。
1.11.4编译指令和库
很多编译器厂商,如 PGI、CAPS 以及最著名的 Cray,都支持最近发布的针对 GPU的OpenACC编译器指令集。在本质上,这些是 OpenMP 方法的复制。它们都要求程序员在程序中插入编译器指令来标注出“应该在 GPU 上执行”的代码区域。然后编译器就做些简单的工作,即从 GPU上移入或移出数据、调用内核程序等。
若使用 pthreads 替代OpenMP,由于 pthreads 提供更底层的控制,所以你可以获得更高的性能。使用CUDA 替代 OpenACC 也是这样。但是,对额外层面的控制,要求程序员掌握更高水平的编程知识,也会带来更高的出错风险,进而对开发进度产生影响。目前,OpenACC 不仅要求用指令标注出哪些区域的代码需要运行在GPU 上,而且还要指明数据要存储在哪种类型的内存上。英伟达宣称使用这类指令可以获得5 倍以上的速度提升。对于那些想要程序跑得更快的程序员来说,这是一个很好的选择。对于那些把程序设计放在次要位置,仅仅考虑在合理的时间内完成任务的人来说,这也是一个很棒的选择。
库的使用也是很重要的,因为它可以让你的生产效率以及执行程序时间的加速比提高些库提供的通用函数的执行效率很高,例如,SDK 提供的 Thrust。诸如 CUBLAS 这样的库是针对线性代数最好的库。很多诸如Matlab 和 Mathematica 这样著名的应用程序中都有库的存在。在某些语言中,如 Python、Perl、Java 和许多其他的语言中,库是以语言绑定的形式存在的。CUDA 甚至还被集成进 Excel 里。
在现代化软件开发的各个方面,很多你准备开发的东西别人已经做好了。在你准备花费数周时间开发一个库之前,请先去互联网上搜索一下,看看哪些是已经存在的。除非你是一个CUDA 专家,否则你自己开发不大可能比使用已有的更快。