目录
- 1.什么是进程
- 2.描述进程 - PCB
- 3.进程的具体操作
- 3.1进程的属性与文件属性的关系
- 3.2查看进程
- 准备工作
- 使用指令查找对应进程:
- 在文件中查看进程
- 3.3关闭进程
- ctrl+c
- kill
- 3.4进程的一些特性
- 3.5通过系统调用获取进程标识符
- 3.6通过系统调用创建子进程
1.什么是进程
背景:
我们通过冯诺依曼体系结构知道,程序的运行需要通过CPU来处理,在操作系统的管理下安稳的交给内存,由内存传给CPU处理运行,由CPU处理后,返回给内存,在由内存传给输出设备,以此服务用户。
了解了这个背景,我们就能对进程得出下面的理解:
- 进程 就是被加载到内存中的程序,或者被运行起来的程序就叫做进程。

这也是很多教材上的说法,但它并不完全正确,甚至有些片面。
如上图,我们的计算机在运行后不论是我们自己打开的软件还是后台应用的程序,数量是很多的,如果这些程序就这样赤裸裸的交由操作系统来管理,会增加操作系统的负担,所以操作系统需要对每一个程序做整理,将其打包成一个对象,更抽象的讲,将其变成一个变量,操作系统只对这些变量进行管理,就会变得容易。
比如说,在学校中,每个学生都有自己的信息,如姓名、年龄、性别、各科成绩等等,这里的学生就是操作系统中的程序,想要对其进行管理,我们可以将学生的属性,如姓名、年龄等放入结构体中,在通过结构体创建对应的对象,管理这些对象即可,这样我们也就得出了进程的概念。
我们编写的程序通过编译、链接后生成一个可执行程序,该程序本质是一个文件,放在磁盘。在Windows中双击运行,在Linux中使用
./运行,使其加载到内存。在进程加载进内存后,操作系统要对其进行管理,也就是对程序的数据进行管理,从这些程序中抽象出所有的属性来构建一个结构体,然后将每一个进程都创建成一个结构体对象,最后再将所有的结构体对象使用某一种 高效的数据结构(在Linux中使用双链表 组织起来;
而想要获取每个进程中对应的代码时,根据结构体对象调用在内存中的对应的代码即可;
以此将所有的应用程序都已进程的方式运行,而每个进程都有自己独立的地址空间,使进程之间的地址相互隔离。CPU由操作系统同一进行分配,每个进程根据进程的
优先级的高低都会有机会得到CPU。
所以我们说,进程只是正在运行或将要运行的程序是不正确的,它的理解应当如下:
进程 = 内核关于进程的相关数据结构 + 进程对应的磁盘代码和数据
其中,在操作系统中,用来描述和组织进程的东西(抽象的可以看作结构体),被称为 进程控制块-PCB
2.描述进程 - PCB
从上面的知识中我们知道,单一的进程是由一个特定的结构体来描述出的,该结构体(数据结构)就是进程控制块,可以理解为进程属性的集合。
课本上将进程控制块称之为PCB(process control block),而不同的操作系统,PCB的名称不同,在Linux操作系统下的PCB是:task_struct

也就是说,每一个进程被加载到内存后,Linux操作系统都会对其创建
task_struct对象,并将其与加载到内存的代码和数据产生关联,然后将所有的task_struct使用指针连接成一个双链表(此时该进程即为操作系统内被管理的进程),这样对进程的管理就是对链表的增删查改。(此为简易路线,剩余内容之后会讲)
PCB是用来描述进程的,在C++中我们使用类来描述一个事务,在C语言中我们使用结构体描述,而Linux是用C语言编写的,所以Linux当作描述进程的进程控制块就是结构体task_struct实现的。
- task_struct是Linux内核的一种数据结构,被装再到内存(RAM)里,并且包含进程的信息。
了解了这些再来看一下在Linux中,task_struct包含的程序的各种属性内容,如下:
task_struct内容分类
- 标识符:描述本进程的唯一标示符,用来区别其他进程。
- 状态:任务状态,退出代码,退出信号等。
- 优先级:相对于其他进程的优先级。
- 程序计数器:程序中即将被执行的下一条指令的地址。
- 内存指针:包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。
- 上下文数据:进程执行时处理器的寄存器中的数据。
- I / O状态信息:包括显示的 I / O 请求,分配给进程的 I / O 设备和被进程使用的文件列表。
- 记账信息:可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
- 其他信息。
抽象出来,可以用如下结构体来表示(以LInux为例)
struct task_struct{//进程的所有属性....//进程对应的代码和数据的地址....//下一个进程的地址struct task_struct* next;
}
关于进程的进程控制块PCB的task_struct结构体的具体描述可以参考这篇博客Linux中进程控制块PCB-------task_struct结构体结构
了解了这些,我们也就能更具体的感受进程的概念:
进程 = 内核关于进程的相关数据结构 + 进程对应的磁盘代码和数据
总结:
-
PCB是什么
它就是一个struct结构体,这个结构体中包含着进程大部分的属性
-
为什么进程管理中要使用PCB?
为了管理进程
3.进程的具体操作
知道了进程是什么,我们接下来就来看一下,在LInux下进程的具体操作。
3.1进程的属性与文件属性的关系
我们知道在磁盘中的文件 = 内容 + 属性。
那一个文件,在磁盘当中向内存加载,加载的是这个文件的内容还是属性呢?
答:内容
我们知道,每一个进程都有自己的属性集合叫PCB,那在磁盘中文件的属性和进程的属性有关系吗?
答:有关系,但是关系不大
比如说,在磁盘中,文件的属性一般包含着文件的权限、拥有者、所属组、什么时间创建修改和文件名是什么等等,这些判断用户是否有权限去操作文件和文件的一些基本信息,
而PCB结构体是一种内核数据结构,是由操作系统去创建动态维护的,和磁盘里的属性没有关系,它是重起炉灶,另搭台。就是说,进程里的属性是由操作系统根据获取的代码和数据自己去创建和维护的,和磁盘中的文件属性不同。
例如,进程的pid(process id,进程的id号),这个是文件没有的,而如果操作系统想要知道某个进程对应的文件名或文件的体积大小,它也是可以知道的,所以我们说它们有关系,但关系不大。
3.2查看进程
准备工作
- 使用到vim、gcc、makefile,若是不熟悉,点击名称查看对应博客即可
我们在Linux中新建文件myprocess.c,编写如下代码

代码功能:我们知道当程序是以进程的模式在硬件中运行,在执行该程序后,陷入死循环,一直输出“hello process”,此时该程序对应的进程一定是存在的我们可以查看到。
所以我们可以得出如下结论:
结论:
- 在Windows系统中,通过双击或打开一个程序,程序就会以进程的方式运行。
- 在Linux系统中,执行可执行程序(
./)后即为将程序变为进程的形式
下图为makefile文件代码:

上图表示,我们编写代码的myprocess.c文件生成的对应可执行文件名为MyProcess,下面会直接使用MyProcess可执行文件执行运行该程序
小技巧
因为只有程序运行,才能保证进程的存在,所以我们要在程序运行的情况下,观察对应进程信息,这时我们就需要使用多个页面配合的方式,我使用的是Xshell,如果大家和我使用的相同可以使用如下方法创建多页面。
-
右击当前会话框,找到复制会话

-
复制出的会话与当前会话相同,处在同一文件,共用同一操作系统,一边的发生改变影响另一边
-
将复制好的进程拖至合适位置

- 复制会话,即为创建了一个新的bash进程,并且与原来的bash进程共用同一操作系统(后面会讲)
-
可使用该方法产生复制多个会话,一次运行多个程序,在查看进程
使用指令查找对应进程:
使用
ps axj | head -1 && ps axj | grep 可执行文件名 | grep -v grep指令查找。注意: 按具体需求使用该指令

解释:
指令:
ps axj为查看当前执行的所有进程,

|:管道符,表示将前面执行的结果传到后面,执行后面的指令
指令:
head -1取所有ps axj所有显示的第一行,也就是上面动图,最后使用白色部分选择的那行,给出每列名称,该指令具体内容查看该篇博客–常见指令

主要包含以下这几个名称:
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
这里介绍两个本文要用的,剩余的不做研究
- PID:process ID ,进程的编号
- PPID:父进程编号,即对应PID的父进程编号
&&:逻辑或,将两端指令的结果结合,输出到屏幕
指令:
grep 可执行文件名,grep指令用于查找对应字符串,并输出字符串所在行,该指令具体内容,可查看该篇博客–常见指令

在上面的一张动图中,最终显示的结果如下

其中打印出的第二行是我们不需要的,可以使用最后一个指令使其不在打印
指令:
grep -v grep,-v选项,表示不显示后面字符串(grep)所在行,具体内容,可查看该篇博客–常见指令

在文件中查看进程
在
/proc文件中查看(该方式比较冷门)

- 数字对应的是对应进程的PID
举例:
我们先执行MyProcess文件,在使用上面的指令查找对应的进程,找到该进程的PID,根据PID在/proc中查看对应文件,如下:

具体如下(上面得进程不小心关闭了,重新打开了一个)

当我们查看该PID对应文件的具体信息,会看到如下情况:

表明该进程对应的程序的位置。
3.3关闭进程
ctrl+c
如下图,在当我们打开一个程序,并处于运行状态,我们可以使用热键ctrl + c结束该程序(结束该进程)

kill
我们也可以使用kill指令加-9选项后根进程PID结束目标进程,如下
kill -9 PID

3.4进程的一些特性
-
一个程序可以同时形成多个进程
如下,我们对同一可执行文件执行两次,并查看进程

-
随着进程创建的先后顺序不同,它的PID是变化的
如下,我们打开关闭同一可执行文件,并查看对应进程PID的变化

如上图红色的框,表示每次运行该程序后,进程PID的变化,它是变化的,因为每次都需要重新将程序已进程得形式执行,不可能每次都使用相同得PID
-
一个程序它创建多次,虽然每次PID不同,但PPID(父进程)相同
如上图,虽然每次进程的PID不同,但它们的父进程PPID是相同的,再Linux中该父进程为bash
-
Linux中进程的父进程都是bash(有特殊情况,但毕竟是特殊情况)
每一次我们开机,都会启动操作系统,那就需要命令行解释器来帮我们做解释命令,所以,bash命令行解释器也是一个进程,它有独立的PID。命令行启动后的所有程序,最后都会变成进程,而该进程对应的父进程就是bash。
在该篇博客shell及其运行原理中提到过,shell为了保护自己,创建子进程来执行用户的指令。
如下,我们在
/proc文件中根据上图父进程的PID查看对应的信息,是否为bash
注意: 我们的指令(如:ls、touch等),是由C语言编写,
./后也会形成进程。 -
一个进程结束后,它对应的进程PID文件也会被删除无法打开
-
我们在进程结束后,尝试打开对应进程PID文件

如上图,打不开文件,并且在
/proc文件中找不到对应的文件 -
先打开进程PID文件,后结束进程,观察结束后该文件的变化

-
-
我们知道bash也是进程,它是所有进程的父进程,当我们关闭该进程后,相对应的对话就无法使用,需重新创建,如下,我们使用
kill指令关闭该进程(不同的系统下展现情况不同但意义相同)
上图我们创建了两个会话,虽然共用同一Linux操作系统,但对应得bash进程不同,我们查看的是右边会话对应得进程,所以它的父进程即为右边得bash,关闭后不会影响左边得会话。
3.5通过系统调用获取进程标识符
系统调用: 计算机是由用户层、操作系统、驱动、硬件等等组成,它们每一层使用接口与相邻层连接,而操作系统给出的供上层开发使用的接口统称为系统调用。(具体看该篇博客–操作系统)
当我们想在程序运行的时候显示它对应的进程PID和PPID,就需要使用系统调用。
我们使用系统调用接口getpid()和getppid()来获取进程PID和PPID,这里我们可以通过man手册来查看这两个函数(按q退出)
man getpid

注意: 函数的返回值pid_t,将其当作int即可,在打印时,使用%d
我们在将myprocess.c文件中的代码做如下修改

运行该程序后,查看对应的PID和PPID值是否正确

3.6通过系统调用创建子进程
通过上面的学习我们知道,Linux操作系统通过父进程bash来创建子进程,那父进程是如何来创建子进程的?如何在代码层面直接创建新的子进程呢?这就要学习第三个系统调用接口fork().
可通过man查看fork的信息
man fork

下面让我们使用fork()看一下结果
首先,我们先将myprocess.c的程序做如下修改:

运行后的结果如下:

如上图运行结果,形成两个进程,父进程的PID为10130,子进程的PID为10131(23286为该会话的bash进程PID)
最开始打印父进程的字符串"AAA",fork后打印了父进程的字符串“BBB”,最后打印子进程的字符串“BBB”。

这是因为在fork后执行流会变成两个执行流,变为两个进程,这两个进程共享fork后的代码,而且并不是必须要先运行父进程后运行子进程,这个根据服务器的不同,结果不同。
整个调用链为:当我们运行该程序时,产生了子进程,而该程序内通过fork又创建了它自己的子进程。
总结: 对于父子进程,子进程是再父进程的基础上创建。
那么问题就来了,操作系统如何知道那个是父进程,那个是子进程的?
答:通过fork的返回值。
让我们在来使用man指令查看fork,并找到它关于返回值的内容,如下:

若进程创建成功,将子进程的PID返回给父进程,将0返回给子进程,若失败将-1返回给父进程,没有子进程创建,显示errno
注意:返回值类型为
pid_t
我们通过下面修改的代码和修改后的运行结果理解上面的内容
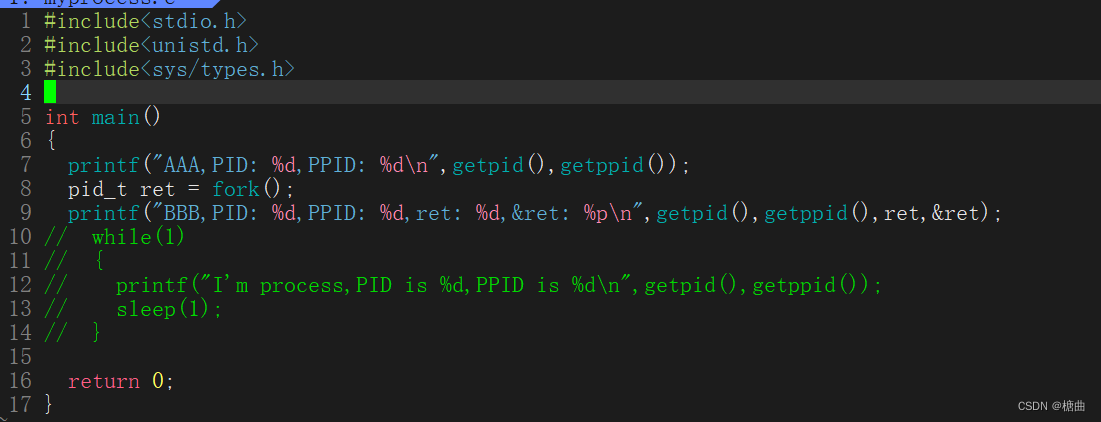

如上图,fork给父进程返回的是子进程的PID17881,给子进程返回的是0,以此来区分父子进程。
想必这里大家就会有疑问,为什么一个变量会接收到两个返回值?为什么同一个地址却有不同的值?第一个问题我们下面会讲到,第二个设计到进程地址空间,本文为进程的概念,第二个问题在之后的博客会讲到。
了解了这些知识和现象,我们在来看一下一般我们使用fork的方式,将代码修改如下:
 运行的结果如下:
运行的结果如下:

还是一个变量,有两个值,导致该程序即执行了if又执行了else if。这也是fork如何两个返回值的问题?
接下来我们按步骤解答这个问题:
-
fork做了什么?
答:创建了子进程。
我们知道一个
进程 = 内核关于进程的相关数据结构 + 进程对应的磁盘代码和数据像上面这段程序,运行后先创建了一个进程它有自己对应的代码和数据,在fork后,它创建了自己的子进程,而子进程对应的仍然是父进程的代码和数据,

-
fork创建子进程后,父子进程是否影响着彼此?
这里先要说一个概念:进程在运行的时候,是具有独立性的!
比如说,我们在Windows系统下,打开QQ、微信、爱奇艺等待软件,在关闭QQ对其他的软件是没有影响的。
而上面的程序是父子进程,运行的时候也是一样的,我们运行上面的程序,然后关闭父进程,查看子进程是否可以运行
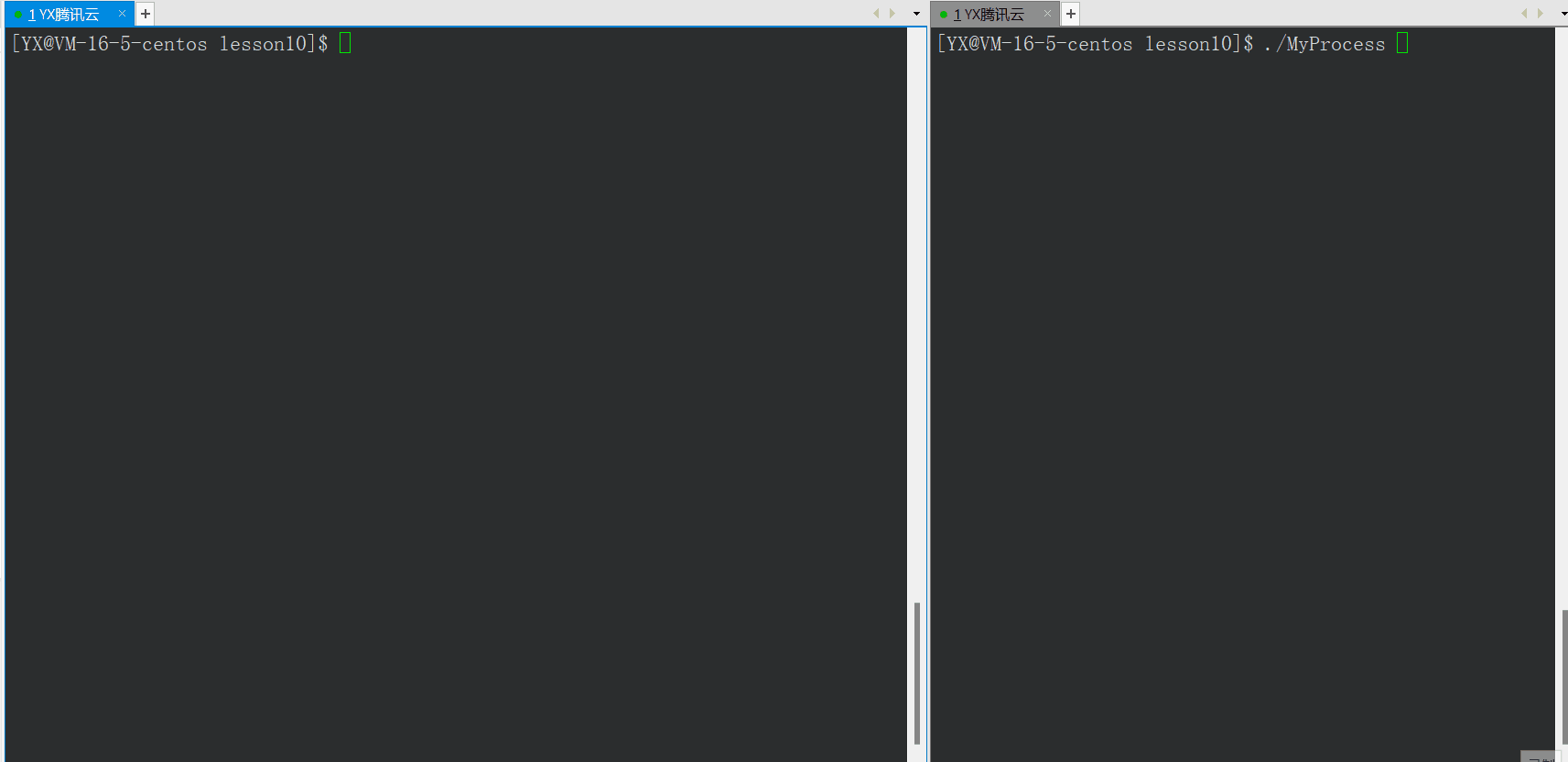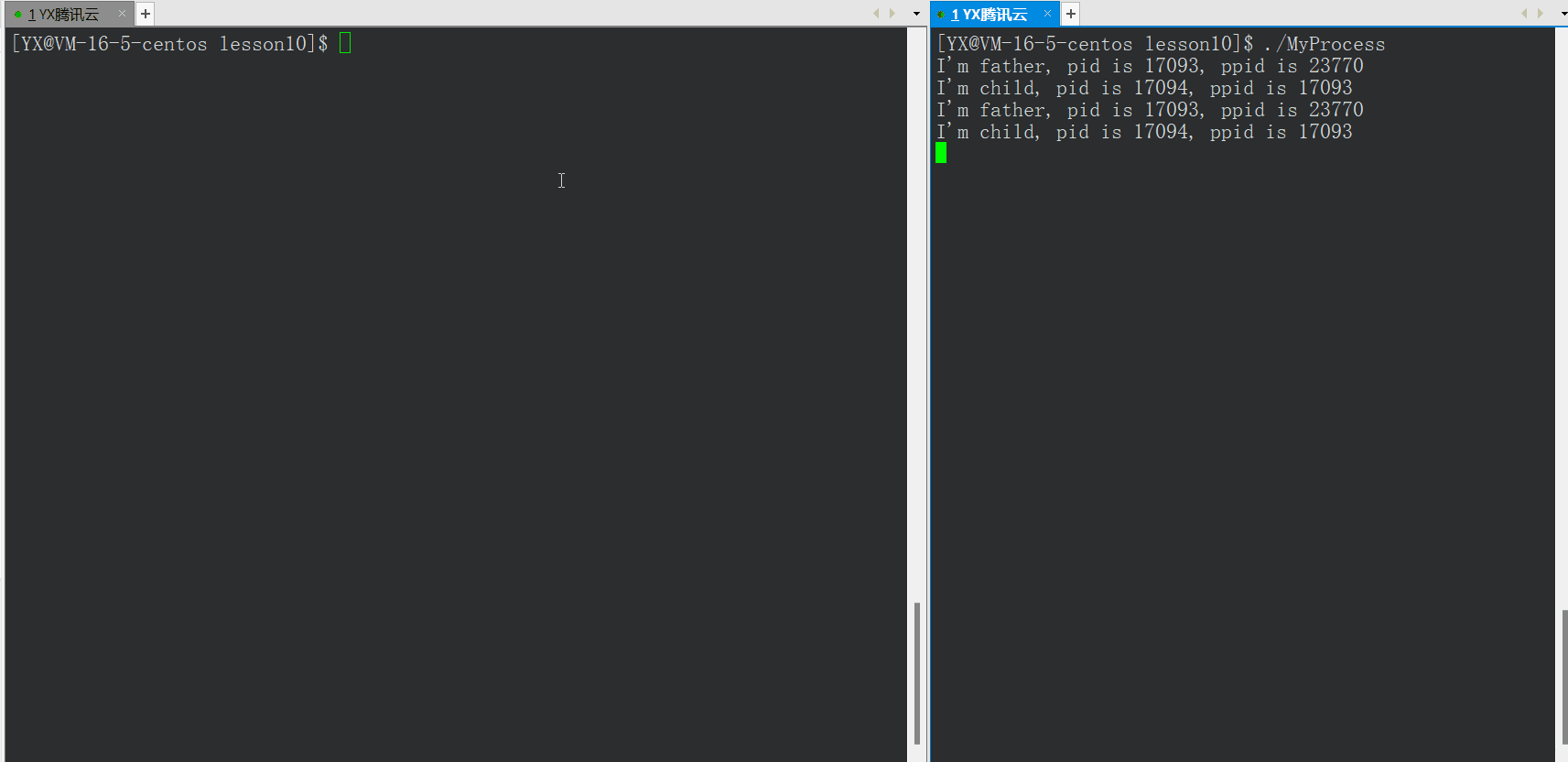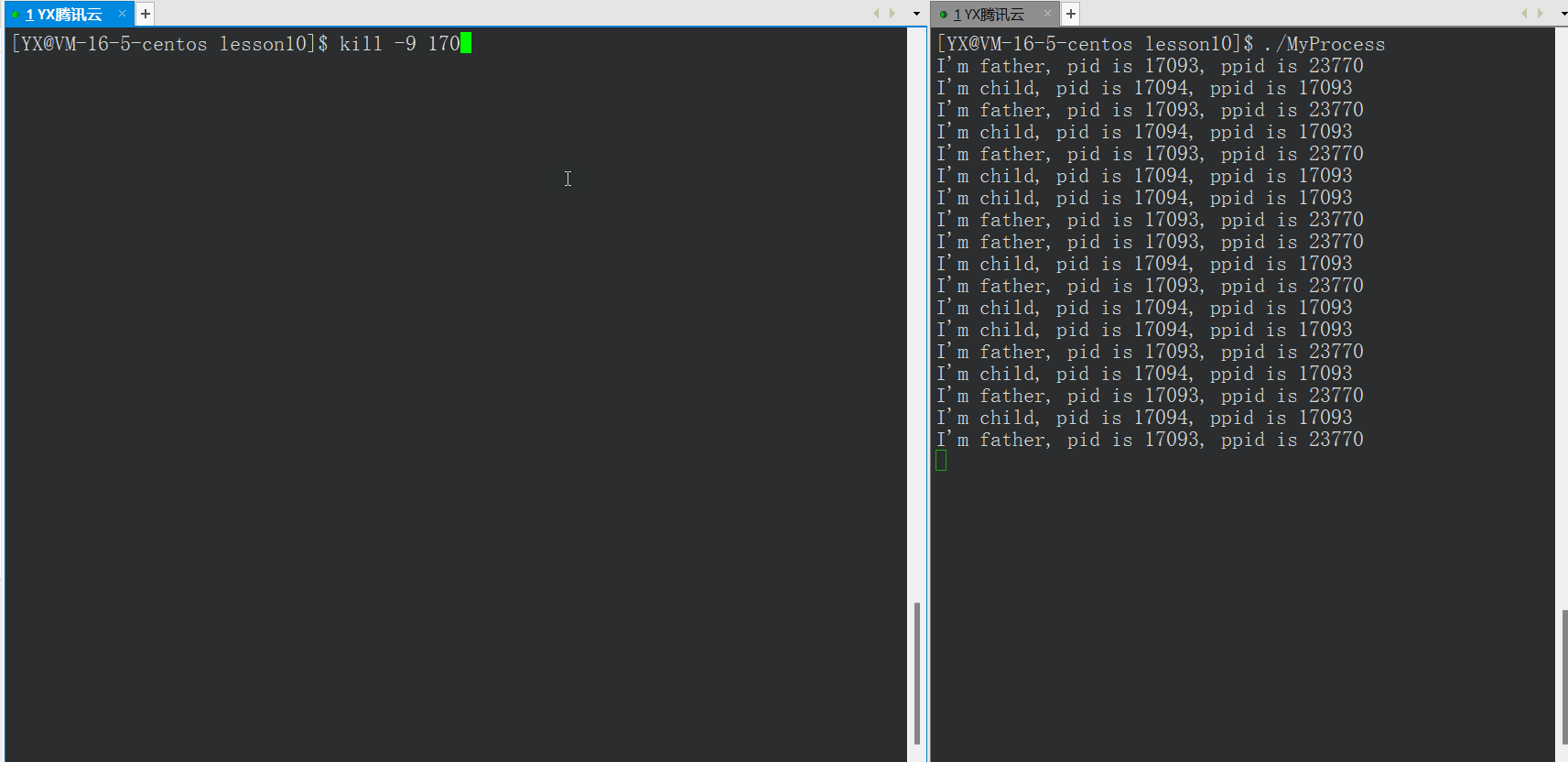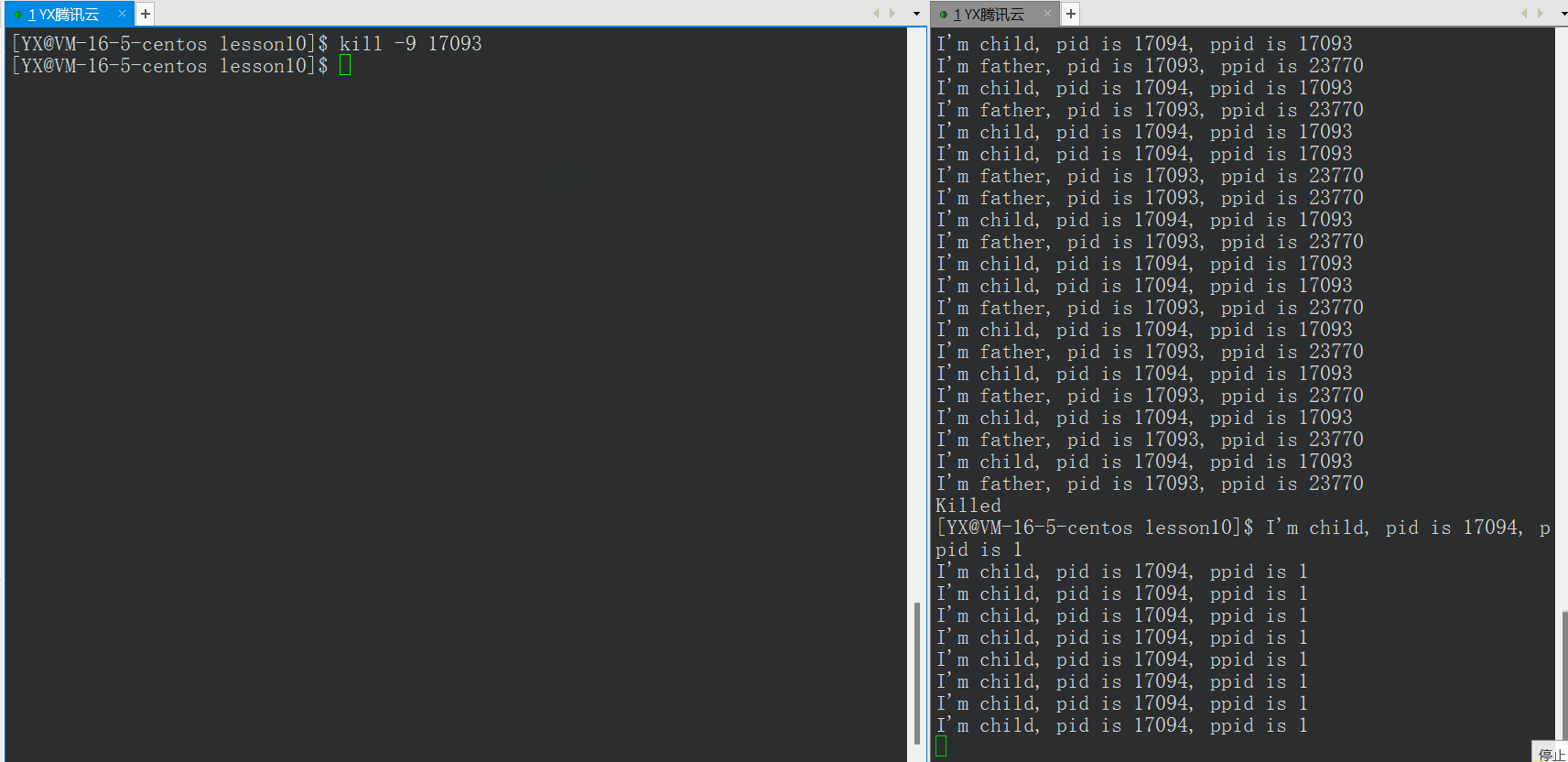
如上图,父进程关闭后,子进程还可以正常运行,其中子进程的PPID变为1,子进程变为
孤儿进程(孤儿进程此处作为了解,需在使用kill关闭子进程) -
fork如何看待代码和数据?
首先,我们编写的代码在运行后不会被改变,例如,某行使用的是if,运行后被改为while,这是不会的。
其次,运行程序后,在修改数据时,是将数据拷贝到另一个地方,在另一个地方对数据进行修改。
总结:
代码:代码是只读的,不会被改变
数据:当一个执行流尝试修改数据的时候,操作系统(OS)会自动给我们当前进程除法
写时拷贝所以在fork后形成两个进程共用同一代码和数据,代码时只读的无法进行修改,而数据以写实拷贝的方式两个进程各自私有一份,并且两进程 不互相干扰。(具体内容有关进程地址空间)
-
fork如何理解两个返回值问题?
首先,我们要明白,fork是一个系统调用接口,也就是一个函数,而一个函数在最后执行return前,它主要的功能已经执行完毕。其中,调用fork的是父进程,父进程一定执行了一遍fork并且return返回了值。
在来看fork,它的功能就是创建子进程PCB,使其跑起来,最后return返回值。
既然fork已经执行到return,说明它的主要功能已经执行完毕,也就是此时子进程已经创建,而子进程创建后也会执行代码,也就是说,fork执行到return后,父进程和子进程都会执行一次,导致返回了两个值。
这两个值被接收时又发生了写时拷贝,存入了不同的空间,虽然看起来存入同一变量,同一空间。