上节我们知道了List 下的两大 子类 ArrayList 跟 linkedList
ArrayList 数组结构 查询快,增删慢
LinkedList 链表结构 查询慢,增删快
来看看我们今天的主角: Set
Set 是 不可重复的,其底下也有两大子接口:
HashSet:无序且唯一
TreeSet :有序且唯一
先礼后兵,我们直接来看操作set集合有哪些方法,其实与list 的方法一样,两个子类都是,我们拿最常用的HashSet为例子
- 添加(add)
Set<String> hashSet = new HashSet<>();hashSet.add("java");hashSet.add("资讯");for (String item : hashSet) {System.out.println(item);}
- 移除(remove)
Set<String> hashSet = new HashSet<>();hashSet.add("java");hashSet.add("公众号搜索:“java资讯");hashSet.remove("公众号搜索:“java资讯");for (String item : hashSet) {System.out.println(item);}

- 判断集合中是否有该元素(contains)
Set<String> hashSet = new HashSet<>();hashSet.add("java");hashSet.add("资讯");boolean flag = hashSet.contains("java");System.out.println(flag);

- 获取集合的大小(size)
Set<String> hashSet = new HashSet<>();hashSet.add("java");hashSet.add("资讯");int size = hashSet.size();System.out.println(size);

- 判断集合是否为空(isEmpty)
Set<String> hashSet = new HashSet<>();hashSet.add("java");hashSet.add("资讯");boolean flag = hashSet.isEmpty();System.out.println(flag);
接下来我们一起看探索set 三个子类的底层 (面试会问,需了解,建议收藏,留个印象)
- HashSet (无序且唯一)
HashSet 是Set 接口中最常见的实现类,底层数据结构是哈希表
什么是哈希表?
用一个例子来说明:
有这么24个篮球,编号分别为1-24,需要将篮球分成六组应该怎么分
这还不简单 :
编号 1 -4 第一组 5-8 第二组 9-12 第三组
编号 13-16 第四组 17-20 第五组 21-24 第六组
那如果我要找 16 号篮球球在哪个组呢? 这数据才24, 要找到也方便,要是数据量变大,成百上千,分成多个组,要快速找到想要的编号在哪个组,就显得困难了
这时候就推出了哈希,进行散列
具体实现:
分成6组
将 编号除 6 余数为0 的为 第零组:6、12、18、24
将 编号除 6 余数为1 的为 第一组:1、7、13、19
将 编号除 6 余数为2 的为 第二组:2、8、14、20
将 编号除 6 余数为3 的为 第三组:3、9、15、21
将 编号除 6 余数为4 的为 第四组:4、10、16、22
将 编号除 6 余数为5 的为 第五组:5、11、17、23
这要我们要找一个编号就很方便,比如找16,16%6 =4 16 在第四组 ,这种方式就是高效的散列,我们称之为Hash
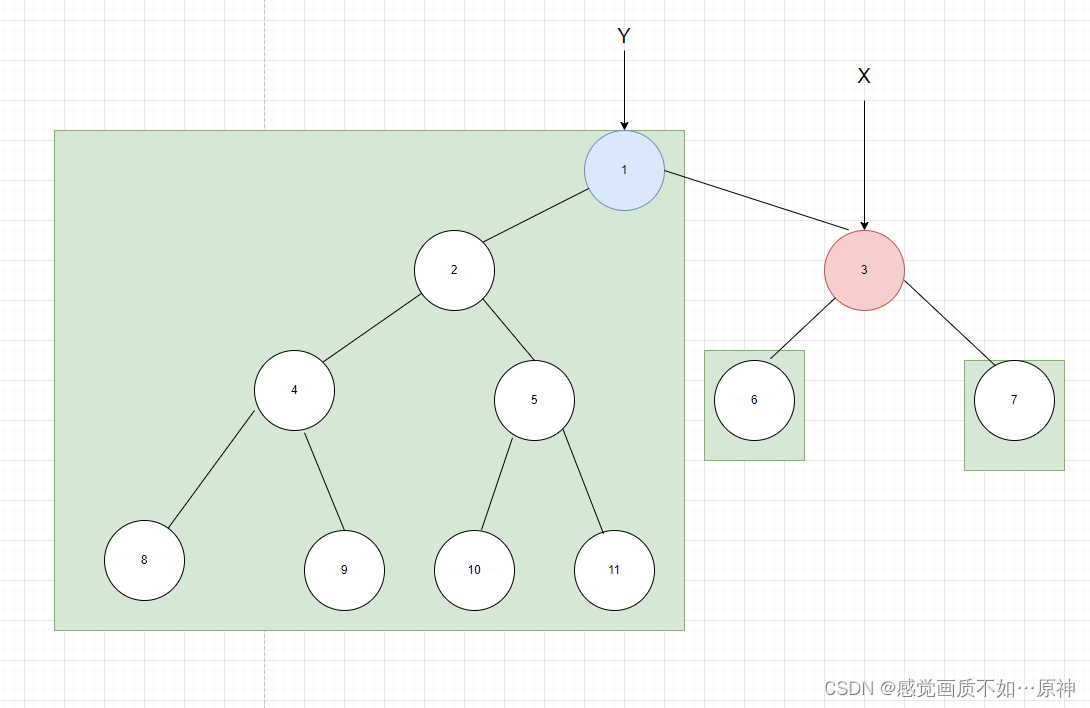
来看看哈希的运行图解,还是以上述篮球分组为例:

这里有几个概念:
key:就是编号
索引:数组的下标,可以快速定位,检索,我们分组的序号
哈希函数:将编号映射到索引上,采用的是取余方法 % 余数代表数组下标
哈希桶:保存索引的值的数组或链表,每个索引相同的元素以链表形式连接
通过上述,可以知道,这个存放数据的散列表就是我们说的哈希表
现在我们来看看 HashSet 的无序且唯一这个特性,通过对比代码呈现
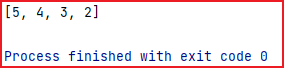
public static void main(String[] args) {List<String> list = new ArrayList<>();list.add("张三");list.add("李四");list.add("王五");list.add("王五");for (String item : list) {System.out.println(item);}System.out.println("-------------------------");Set<String> hashSet = new HashSet<>();hashSet.add("张三");hashSet.add("李四");hashSet.add("王五");hashSet.add("王五");for (String item : hashSet) {System.out.println(item);}
}
输出结果
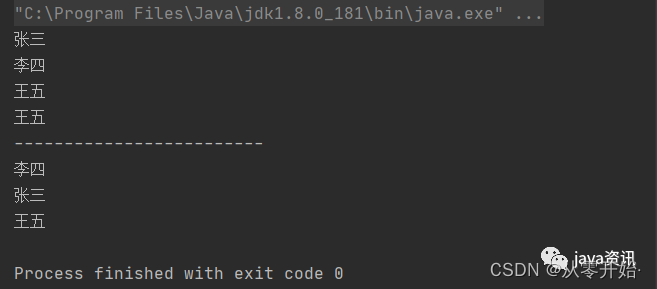
可以看出,List 是有序的,谁先添加,谁先输出,而set没有按照顺序来,
并且list可以存储重复的数据,set会自动去重
- TreeSet (有序,唯一)
TreeSet 底层实现是红黑树,默认排序为从小到大。是有序的,
注意:这里的有序并不是list 的 先进先出的有序,他会进行自然排序 ,对数据进行排序后输出
Set<Integer> treeSet = new TreeSet<>();treeSet.add(88);treeSet.add(66);treeSet.add(10);treeSet.add(3);treeSet.add(6);for (Integer item : treeSet) {System.out.println(item);}
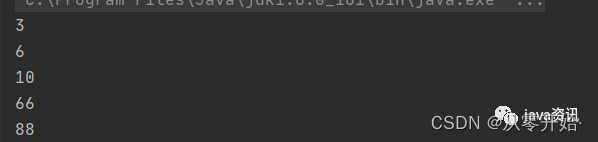
红黑树,这边有一个演示地址,复制到浏览器进行打开,https://www.cs.usfca.edu/~galles/visualization/RedBlack.html
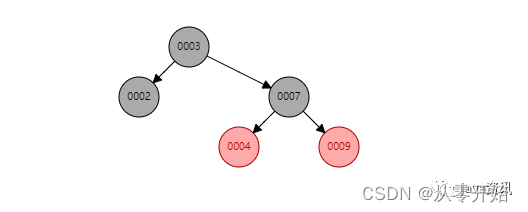
第一次存储数据没有树根就创建树根,然后这个元素 就是树根
第二次存储元素先跟节点比较,
当存储元素的值大于根节点的值,将元素存储在右边当存储元素的值小于根节点的值,将元素存储在左边当存储元素的值等于根节点的值,那就不存了,因为是唯一的
TreeSet 有两个排序机制,体现在它的构造器上,分为:自然排序,比较器排序
可以看看他的构造器:
//构造一个新的空 自然顺序进行排序。
TreeSet()
// 指定比较器进行排序。
TreeSet(Comparator<? super E> comparator)
自然排序用的是Comparable 接口有一个 compareTo(Object o) 方法,两个元素为0 相同,不再重复存储,返回正数 表明 前数据 大于 后数据 ,负数则反之
比较器排序 用的是 compare(Object o1,Object o2),返回结果跟判断原则跟compareTo 一样
主要区别,构造上也能看到,一个对应空参创建TreeSet 一个对应有参创建TreeSet
扩展
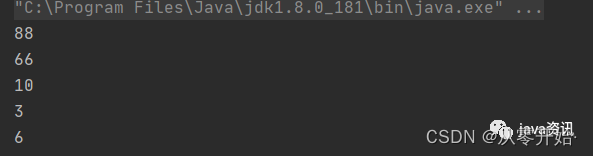
linkedHashSet (这个是HashSet的子节点),它是有序且唯一,底层结构为链表加哈希表,链表保证了元素有序(这个有序是顺序,不是排序的大小),有序是因为它在节点处增加了前和后 (属性维护节点的前后添加顺序)
Set<Integer> treeSet = new LinkedHashSet<>();treeSet.add(88);treeSet.add(66);treeSet.add(10);treeSet.add(3);treeSet.add(6);for (Integer item : treeSet) {System.out.println(item);}

java进阶—List
Java中的集合
二维数组详细解析
Java中的注释