Hugging face笔记
course url:https://huggingface.co/course/chapter5/8?fw=pt
函数详细情况:https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.TokenClassificationPipeline
基础掌握transformers和datasets,教程写得比较详细,在transformers模块就涉及了从tokenize到后面的输入模型以及模型内部以及输出head到后面预训练的过程。
0 setup
环境配置,使用jupyter notebook或者python文件的形式
1 transformer models
需要掌握的内容:
libraries from the Hugging Face ecosystem — 🤗 Transformers, 🤗 Datasets, 🤗 Tokenizers, and 🤗 Accelerate — as well as the Hugging Face Hub.
基础掌握transformers,datasets和accelerate三个库,能够调用大模型,进行训练,并能通过accelerate进行单机多卡和多级多卡训练,能了解nlp是在做什么,流程是什么,如何让计算机更好理解人类的自然语言,以及如何使用自己的数据训练,以及如何大批量高效处理数据,以及网站上的各种资源如何使用。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-44PoEHbT-1675320733552)(/Users/admin/Documents/note/assets/image-20230201171318285.png)]
NLP是什么以及挑战在哪里
挑战在于计算机不能理解人类语言,人类的语言对于计算机是符号,它只知道数字这类没有情感的符号,对于语言中蕴含的意思不能理解,因此NLP是为了让计算机理解人类语言。
一些任务:
句子分类/句子每个单词分类/文本生成/答案提取/阅读理解等。
Transformers 能做什么what can do?
library Transformers可以做什么?通过最高层也是最简单的pipeline()API告诉你他有多么简单强大。
pipeline
最高层封装,输入原始句子,输出结果,不能做其他操作。
from transformers import pipelineclassifier = pipeline("sentiment-analysis")
classifier("I've been waiting for a HuggingFace course my whole life.")
>[{'label': 'POSITIVE', 'score': 0.9598047137260437}]
classifier(["I've been waiting for a HuggingFace course my whole life.", "I hate this so much!"]
)
>[{'label': 'POSITIVE', 'score': 0.9598047137260437},{'label': 'NEGATIVE', 'score': 0.9994558095932007}]
其他pipeline():https://huggingface.co/docs/transformers/main_classes/pipelines 包括大量NLP任务,如情感分类等。
并提供网页尝试。
Transformers怎么做到的?how do it work?
2018年注意力机制和tranformer结构大火,并成为AI发展历程过程中的一个里程碑,但大模型消耗资源巨大,并且从原始文本到原始模型到下游任务还有很多步骤要做,hg(hugging face)做的就是简化规范这个过程,提供简单api能直接调用尝试大型的效果,封装更多原始操作,让写代码更简洁方便,让训练的门槛降低。
详情了解transformer模型见attention is all you need原始论文即可了解,简单来说就是设计了多头子注意力机制以及融合多种trick的结构,涉及成encoder-decoder结构,取得超高分数。
追溯到最原始是那里,但距离直接产生hg还有一段历史:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JpVSgge6-1675320733554)(/Users/admin/Documents/note/assets/image-20230201173943924.png)]
这些发展可以分为三类:
- GPT-like:自回归样式的,decoder式的,通过前面生成后面的。
- BERT-like:自编码样式的,输入一个word,输出一个embedding。
- BART/T5-like:sequence-to-sequence样式的,一段序列到另一份序列。
在训练过程中是按照语言模型来训练的,语言模型分为两种:
- 根据前面推测后面的:

- 根据左右两边生成中间的:

顺便提一下大模型的世界格局分布:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DGJbykv7-1675320733557)(/Users/admin/Documents/note/assets/image-20230201174849409.png)]
以及训练一次大模型就相当于全美7年的生活CO2CO^2CO2 排放量,因此hg意义重大,因为这些预训练好的模型很强大,而且对很多下游任务都有奇效,hg做的事情就是为这些大模型提供规范化的平台,让更多的人更方便的使用。
术语规范
Architecture:结构,包括layer,怎么连接,多少维度这样
Checkpoints:权重,是预训练之后留下的有用数据
Model:上面两个的泛称。
Bias and limitations
学习到预训练数据中的偏差,比如男女偏见/种族偏见等。
使用Transformers
设计原则包括方便使用,有灵活性,简单易用,因此功能强大。
整个pipeline流程包括:

首先要有词典,词典大小是所有单词的数量,给每个单词一个序号,首先将输入文本单词变成数字,然后将数字输入进模型,然后模型会输出一些列处理后的小数。成为logits,然后再根据logits做下游任务。
在上面的基础上,后面根据任务设计的模块(比如进行分类)称为head,然后能得到模型最后的输出:
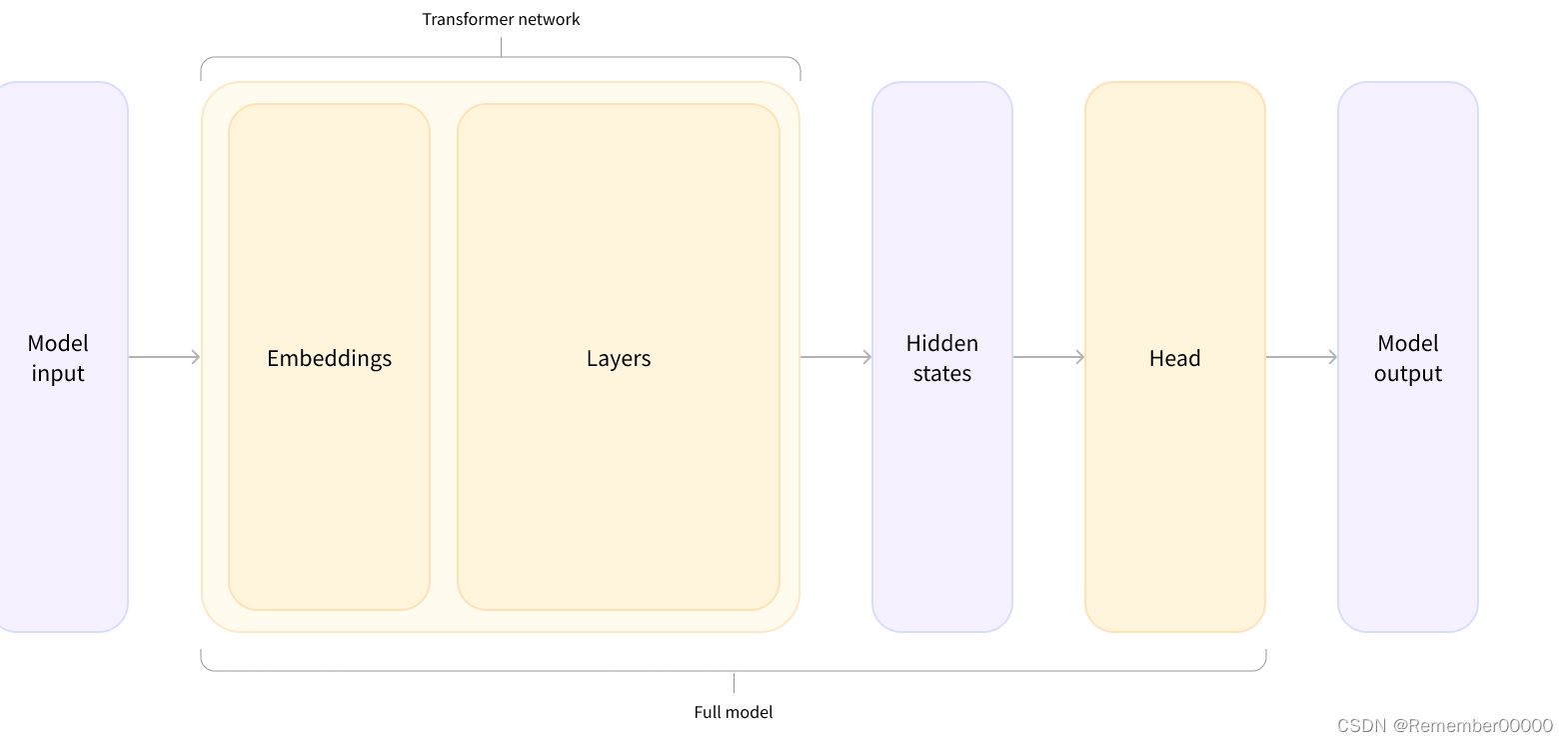
同上面的pipeline,方法使用Auto+**方法也能实现整个流程:
Here is a non-exhaustive list:
*Model(retrieve the hidden states)*ForCausalLM*ForMaskedLM*ForMultipleChoice*ForQuestionAnswering*ForSequenceClassification*ForTokenClassification- and others 🤗
from transformers import AutoModelForSequenceClassificationcheckpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
outputs = model(**inputs)
print(outputs.logits.shape)
>torch.Size([2, 2])
方法2:
from transformers import BertConfig, BertModel# Building the config
config = BertConfig()# Building the model from the config
model = BertModel(config)
from transformers import BertModelmodel = BertModel.from_pretrained("bert-base-cased")
保存模型:
model.save_pretrained("directory_on_my_computer")
Tokenizers
最小单元可以是word, 可以是字母, 也可以是subword, 就是将一个单词, 分成几个能够表示具体意义的subword, 然后使用subword的形式构建词典.
Loading and saving
一步到位
#法1:限制只能使用bert,较少使用
from transformers import BertTokenizertokenizer = BertTokenizer.from_pretrained("bert-base-cased")
#法2:根据选择模型调用,推荐
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
tokenizer("Using a Transformer network is simple")
#{'input_ids': [101, 7993, 170, 11303, 1200, 2443, 1110, 3014, 102],'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
#save
tokenizer.save_pretrained("directory_on_my_computer")分步骤:
Tokenization
tokenize:
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-cased")sequence = "Using a Transformer network is simple"
tokens = tokenizer.tokenize(sequence)print(tokens)
#['Using', 'a', 'transform', '##er', 'network', 'is', 'simple']
From tokens to input IDs:
ids = tokenizer.convert_tokens_to_ids(tokens)print(ids)
Decoding
decoded_string = tokenizer.decode([7993, 170, 11303, 1200, 2443, 1110, 3014])
print(decoded_string)
模型输入为一个batch,必须放在[]中
拆解流程:
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassificationcheckpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)sequence = "I've been waiting for a HuggingFace course my whole life."tokens = tokenizer.tokenize(sequence)
ids = tokenizer.convert_tokens_to_ids(tokens)input_ids = torch.tensor([ids])
print("Input IDs:", input_ids)output = model(input_ids)
print("Logits:", output.logits)
batched_ids = [ids, ids]
padding:输入必须是一个矩阵,对于不等长的要添加padding来使长度相同
padding_id = 100batched_ids = [[200, 200, 200],[200, 200, padding_id],
]
Attention masks
添加了padding之后,模型会综合上下文信息,因此要做mask,告诉模型忽略这部分信息
batched_ids = [[200, 200, 200],[200, 200, tokenizer.pad_token_id],
]attention_mask = [[1, 1, 1],[1, 1, 0],
]outputs = model(torch.tensor(batched_ids), attention_mask=torch.tensor(attention_mask))
print(outputs.logits)
sequence length:
模型一般是512/1024个token,更长的使用长模型或者裁剪。
参数padding,truncation,以及输入进模型必须是pytorch类型的return tensors可选
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassificationcheckpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]tokens = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt")
output = model(**tokens)
微调FINE-TUNE
id转化为token
tokenizer.convert_ids_to_tokens(inputs["input_ids"])
调用数据
from datasets import load_datasetraw_datasets = load_dataset("glue", "mrpc")
raw_datasets
#--
DatasetDict({train: Dataset({features: ['sentence1', 'sentence2', 'label', 'idx'],num_rows: 3668})validation: Dataset({features: ['sentence1', 'sentence2', 'label', 'idx'],num_rows: 408})test: Dataset({features: ['sentence1', 'sentence2', 'label', 'idx'],num_rows: 1725})
})
将两个句子一块输入进bert
#法1
tokenized_dataset = tokenizer(raw_datasets["train"]["sentence1"],raw_datasets["train"]["sentence2"],padding=True,truncation=True,
)
#法2
def tokenize_function(example):return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
tokenized_datasets
map()
迭代器函数,能够对数据集做批处理,()内能添加函数。
def tokenize_function(example):return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
Dynamic padding()
动态padding,但不适合TPU
from transformers import DataCollatorWithPaddingdata_collator = DataCollatorWithPadding(tokenizer=tokenizer)
samples = tokenized_datasets["train"][:8]
samples = {k: v for k, v in samples.items() if k not in ["idx", "sentence1", "sentence2"]}
[len(x) for x in samples["input_ids"]]
samples = tokenized_datasets["train"][:8]
samples = {k: v for k, v in samples.items() if k not in ["idx", "sentence1", "sentence2"]}
[len(x) for x in samples["input_ids"]]
Training
定义要训练的参数,参数是权重要保存的位置:
from transformers import TrainingArgumentstraining_args = TrainingArguments("test-trainer")
定义模型:
from transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2
定义训练器:
from transformers import Trainertrainer = Trainer(model,training_args,train_dataset=tokenized_datasets["train"],eval_dataset=tokenized_datasets["validation"],data_collator=data_collator,tokenizer=tokenizer,
)
微调:
trainer.train()
这样就开始微调以及每500步报告一次loss;
Evaluation
trainer开始预测:
predictions = trainer.predict(tokenized_datasets["validation"])
print(predictions.predictions.shape, predictions.label_ids.shape)
输出内容: predict() method is another named tuple with three fields: predictions, label_ids, and metrics. The metrics field will just contain the loss on the dataset passed, as well as some time metrics (how long it took to predict, in total and on average).
Evaluate library.
调用计算评测:
evaluate.load():
import evaluatemetric = evaluate.load("glue", "mrpc")
metric.compute(predictions=preds, references=predictions.label_ids)
{'accuracy': 0.8578431372549019, 'f1': 0.8996539792387542}
compute_metrics() function:
def compute_metrics(eval_preds):metric = evaluate.load("glue", "mrpc")logits, labels = eval_predspredictions = np.argmax(logits, axis=-1)return metric.compute(predictions=predictions, references=labels)
从训练到评测整个过程
def compute_metrics(eval_preds):#定义评价方式metric = evaluate.load("glue", "mrpc")logits, labels = eval_predspredictions = np.argmax(logits, axis=-1)return metric.compute(predictions=predictions, references=labels)
#训练参数保存位置以及evaluste按照epoch进行
training_args = TrainingArguments("test-trainer", evaluation_strategy="epoch")
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
#训练器定义
trainer = Trainer(model,training_args,train_dataset=tokenized_datasets["train"],eval_dataset=tokenized_datasets["validation"],data_collator=data_collator,tokenizer=tokenizer,compute_metrics=compute_metrics,
)
trainer.train()
整个训练过程:
数据预处理
from datasets import load_dataset
from transformers import AutoTokenizer, DataCollatorWithPaddingraw_datasets = load_dataset("glue", "mrpc")
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)def tokenize_function(example):return tokenizer(example["sentence1"], example["sentence2"], truncation=True)tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
将数据修改成trainer需要的模式
tokenized_datasets = tokenized_datasets.remove_columns(["sentence1", "sentence2", "idx"])
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format("torch")
tokenized_datasets["train"].column_names
dataloader
from torch.utils.data import DataLoadertrain_dataloader = DataLoader(tokenized_datasets["train"], shuffle=True, batch_size=8, collate_fn=data_collator
)
eval_dataloader = DataLoader(tokenized_datasets["validation"], batch_size=8, collate_fn=data_collator
)
检查数据预处理是否有问题:
for batch in train_dataloader:break
{k: v.shape for k, v in batch.items()}
{'attention_mask': torch.Size([8, 65]),'input_ids': torch.Size([8, 65]),'labels': torch.Size([8]),'token_type_ids': torch.Size([8, 65])}
定义模型:
from transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
检查是否有问题:
outputs = model(**batch)
print(outputs.loss, outputs.logits.shape)
tensor(0.5441, grad_fn=<NllLossBackward>) torch.Size([8, 2])
optimizer&learning rate scheduler:
from transformers import AdamWoptimizer = AdamW(model.parameters(), lr=5e-5)
from transformers import get_schedulernum_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler("linear",optimizer=optimizer,num_warmup_steps=0,num_training_steps=num_training_steps,
)
print(num_training_steps)
训练:
from tqdm.auto import tqdmprogress_bar = tqdm(range(num_training_steps))#可视化训练过程model.train()
for epoch in range(num_epochs):for batch in train_dataloader:batch = {k: v.to(device) for k, v in batch.items()}outputs = model(**batch)loss = outputs.lossloss.backward()optimizer.step()lr_scheduler.step()optimizer.zero_grad()progress_bar.update(1)
evaluate:
import evaluatemetric = evaluate.load("glue", "mrpc")
model.eval()
for batch in eval_dataloader:batch = {k: v.to(device) for k, v in batch.items()}with torch.no_grad():outputs = model(**batch)logits = outputs.logitspredictions = torch.argmax(logits, dim=-1)metric.add_batch(predictions=predictions, references=batch["labels"])metric.compute()
改为多GPU训练:
+ from accelerate import Acceleratorfrom transformers import AdamW, AutoModelForSequenceClassification, get_scheduler+ accelerator = Accelerator()model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)optimizer = AdamW(model.parameters(), lr=3e-5)- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
- model.to(device)+ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
+ train_dataloader, eval_dataloader, model, optimizer
+ )num_epochs = 3num_training_steps = num_epochs * len(train_dataloader)lr_scheduler = get_scheduler("linear",optimizer=optimizer,num_warmup_steps=0,num_training_steps=num_training_steps)progress_bar = tqdm(range(num_training_steps))model.train()for epoch in range(num_epochs):for batch in train_dataloader:
- batch = {k: v.to(device) for k, v in batch.items()}outputs = model(**batch)loss = outputs.loss
- loss.backward()
+ accelerator.backward(loss)optimizer.step()lr_scheduler.step()optimizer.zero_grad()progress_bar.update(1)
多卡训练:
accelerate config#设置config
accelerate launch train.py
DATASETS使用自己的数据
本地加载:
from datasets import load_datasetsquad_it_dataset = load_dataset("json", data_files="SQuAD_it-train.json", field="data")
#加载多个
data_files = {"train": "SQuAD_it-train.json", "test": "SQuAD_it-test.json"}
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
#不解压
data_files = {"train": "SQuAD_it-train.json.gz", "test": "SQuAD_it-test.json.gz"}
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")remote data load:
url = "https://github.com/crux82/squad-it/raw/master/"
data_files = {"train": url + "SQuAD_it-train.json.gz","test": url + "SQuAD_it-test.json.gz",
}
squad_it_dataset = load_dataset("json", data_files=data_files, field="data")
tsv格式和和csv格式区别:tst用\t分隔,因此加载和csv相同,只是用的分隔符不一样
from datasets import load_datasetdata_files = {"train": "drugsComTrain_raw.tsv", "test": "drugsComTest_raw.tsv"}
# \t is the tab character in Python
drug_dataset = load_dataset("csv", data_files=data_files, delimiter="\t")
提取部分数据查看:
drug_sample = drug_dataset["train"].shuffle(seed=42).select(range(1000))
# Peek at the first few examples
drug_sample[:3]
---------------------
{'Unnamed: 0': [87571, 178045, 80482],'drugName': ['Naproxen', 'Duloxetine', 'Mobic'],'condition': ['Gout, Acute', 'ibromyalgia', 'Inflammatory Conditions'],'review': ['"like the previous person mention, I'm a strong believer of aleve, it works faster for my gout than the prescription meds I take. No more going to the doctor for refills.....Aleve works!"','"I have taken Cymbalta for about a year and a half for fibromyalgia pain. It is great\r\nas a pain reducer and an anti-depressant, however, the side effects outweighed \r\nany benefit I got from it. I had trouble with restlessness, being tired constantly,\r\ndizziness, dry mouth, numbness and tingling in my feet, and horrible sweating. I am\r\nbeing weaned off of it now. Went from 60 mg to 30mg and now to 15 mg. I will be\r\noff completely in about a week. The fibro pain is coming back, but I would rather deal with it than the side effects."','"I have been taking Mobic for over a year with no side effects other than an elevated blood pressure. I had severe knee and ankle pain which completely went away after taking Mobic. I attempted to stop the medication however pain returned after a few days."'],'rating': [9.0, 3.0, 10.0],'date': ['September 2, 2015', 'November 7, 2011', 'June 5, 2013'],'usefulCount': [36, 13, 128]}
验证数据:
for split in drug_dataset.keys():assert len(drug_dataset[split]) == len(drug_dataset[split].unique("Unnamed: 0"))
修改数据列名:
drug_dataset = drug_dataset.rename_column(original_column_name="Unnamed: 0", new_column_name="patient_id"
)替换成小写:
def lowercase_condition(example):return {"condition": example["condition"].lower()}
drug_dataset.map(lowercase_condition)
数据筛选:
用于去掉不符合条件的数据:
def filter_nones(x):return x["condition"] is not None
用lambda函数来写:
lambda <arguments> : <expression>
lambda x : x * x
(lambda base, height: 0.5 * base * height)(4, 8)
----------
drug_dataset = drug_dataset.filter(lambda x: x["condition"] is not None)
drug_dataset = drug_dataset.map(lowercase_condition)
# Check that lowercasing worked
drug_dataset["train"]["condition"][:3]
创建新列:
def compute_review_length(example):return {"review_length": len(example["review"].split())}
drug_dataset = drug_dataset.map(compute_review_length)
# Inspect the first training example
drug_dataset["train"][0]
数据排序查看:
drug_dataset["train"].sort("review_length")[:3]
筛掉网页字符:
import htmltext = "I'm a transformer called BERT"
html.unescape(text)、
drug_dataset = drug_dataset.map(lambda x: {"review": html.unescape(x["review"])})
map()函数中使用batched=True能加速函数:
%time tokenized_dataset = drug_dataset.map(tokenize_function, batched=True)
%time为jupyter notebook魔法函数,只执行一次。
数据集分块,将train、valid、test汇总到一个datasetdict中:
drug_dataset_clean = drug_dataset["train"].train_test_split(train_size=0.8, seed=42)
# Rename the default "test" split to "validation"
drug_dataset_clean["validation"] = drug_dataset_clean.pop("test")
# Add the "test" set to our `DatasetDict`
drug_dataset_clean["test"] = drug_dataset["test"]
drug_dataset_clean
---
DatasetDict({train: Dataset({features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length', 'review_clean'],num_rows: 110811})validation: Dataset({features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length', 'review_clean'],num_rows: 27703})test: Dataset({features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length', 'review_clean'],num_rows: 46108})
})
保存数据集:
| Data format | Function |
|---|---|
| Arrow | Dataset.save_to_disk() |
| CSV | Dataset.to_csv() |
| JSON | Dataset.to_json() |
drug_dataset_clean.save_to_disk("drug-reviews")
提取数据集:
from datasets import load_from_diskdrug_dataset_reloaded = load_from_disk("drug-reviews")
drug_dataset_reloaded
---
DatasetDict({train: Dataset({features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length'],num_rows: 110811})validation: Dataset({features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length'],num_rows: 27703})test: Dataset({features: ['patient_id', 'drugName', 'condition', 'review', 'rating', 'date', 'usefulCount', 'review_length'],num_rows: 46108})
})
![P1075 [NOIP2012 普及组] 质因数分解](/images/no-images.jpg)