👑作者主页:@安 度 因
🏠学习社区:StackFrame
📖专栏链接:C++修炼之路
文章目录
- 一、前言
- 二、函数重载
- 1、重载规则
- 2、函数名修饰规则
- 三、引用
- 1、区分
- 2、本质
- 3、特性
- 4、应用
- a、做参数
- b、做返回值
- 5、效率比较
- 6、常引用
- 7、指针和引用区别
- 四、结语
如果无聊的话,就来逛逛 我的博客栈 吧! 🌹
一、前言
小伙伴们好,我是 anduinanduinanduin . 今天我们继续讲解 C++ 入门的知识,内容主要为两大块:函数重载和引用 ,这两块在 C++ 中可谓是重量级选手,特别是引用,学完使用会很舒适。虽然引用的点很多,但是没关系,anduinanduinanduin 对它全方面进行了讲解。
话不多说,我们开始学习吧!
二、函数重载
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型不同的问题。
对于c语言是不允许重名函数的存在的,当函数名字相同时,就会报错。但是对于 c++ 可以。
1、重载规则
当函数重载条件满足如下三条时,则可以构成函数重载:
- 参数类型不同
- 参数个数不同
- 参数类型顺序不同
对于 c++ ,同名函数是允许存在的:
// 参数类型不同
int add(int left, int right)
{return left + right;
}int add(double left, double right)
{return left + right;
}// 参数个数不同
int add(double left, double right, int mid)
{return left + right;
}// 参数类型顺序不同
int add(int left, char right)
{return left + right;
}int add(char right, int left)
{return left + right;
}
函数重载需要在同一个命名空间。
对于相同类型的数据,顺序不同,不构成函数重载,因为编译器无法识别:
int add(int right, int left)
{return left + right;
}int add(int left, int right)
{return left + right;
}
因为函数重载是根据类型识别的。
2、函数名修饰规则
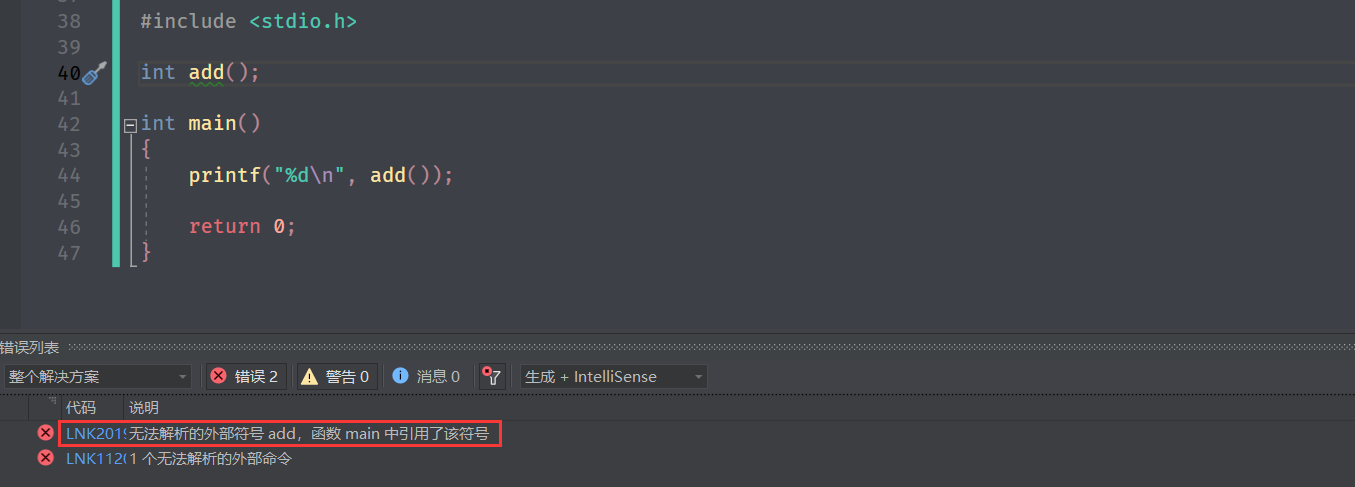
对于函数重载后的函数,执行会不会变慢?不会,因为不是在运行时匹配,而是在编译时。
编译时如何进行识别?
对于编译而言,调用函数处会变成 call + add(地址) 的形式,然后通过汇编指令完成调用。
那么调用函数时,如何找到这个函数?
对于C语言来说,就是依靠函数名去找函数的,如果函数名相同,则会冲突,因为不知道找哪个.
证明修饰规则:
对于C++来说,不同平台就有不同的修饰规则,对于 vs 上比较复杂,暂且不谈;这里我们讲 linux 上的:
int add(int left, int right)
{return left + right;
}
对于这个函数,就会被修饰为 _Z3addii :
_Z是前缀- 3 是函数名长度
- ii 代表参数类型的首字母
当编译时,就拿修饰以后的函数的名字去找,找到了就可以调用了。所以只要参数类型,个数,顺序不同均可以满足,因为此刻修饰后的函数名是可以被区分的。
从这里也可以看出为什么参数类型相同但是顺序不同不可以构成重载:因为识别不了。
Linux 下修饰规则(重要):格式:_Z+函数名称长度+函数名+类型首字母\_Z+函数名称长度+函数名+类型首字母_Z+函数名称长度+函数名+类型首字母
证明:
code:
#include <iostream>using namespace std;int add(int left, int right) {}int main()
{return 0;
}
编译自定义名称为 mytest :

使用 objdump -S exeName 查看修饰规则,exeName 为可执行程序名称:

发现名字是符合修饰规则的。
修改代码,再次验证:
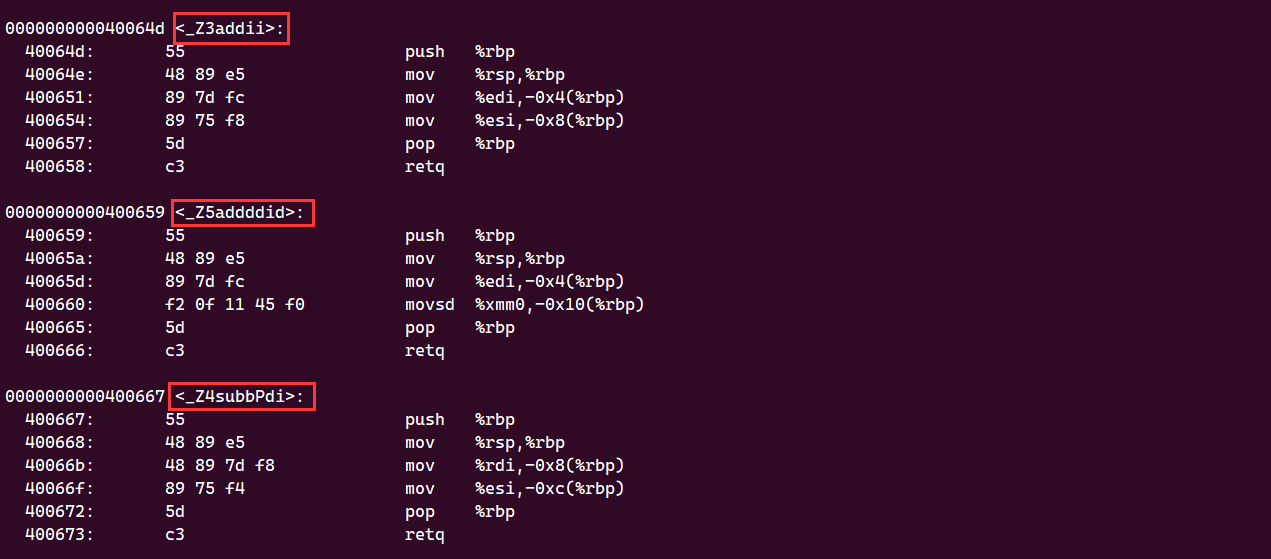
#include <iostream>using namespace std;int add(int left, int right) {}int adddd(int left, double right) {}char subb(double* left, int right) {} // 验证指针int main()
{return 0;
}
对于指针参数,则会在参数类型首字母前加上大写P修饰,P代表point,表示它是个指针 :
对于相同名字的函数,函数重载就根据参数的类型,顺序,个数,以这些为基准,来区别不同的函数。
而根据上面的验证,我们也知道为什么 返回值不同 和 参数类型相同但顺序不同 为什么不能构成函数重载的原因:
因为对于 参数类型相同但顺序不同,形成的后缀还是一样的 ,并不能区分该调用哪个函数;而对于返回值不同的其他都相同的函数来说,则是因为分不清调用哪个函数,不仅仅是因为函数返回值不在修饰规则内。
比如 int add() 和 double add() ,在函数调用时,我该调用哪个?编译器在这时候就错乱了,根本上是语法层面的问题。
Windows 下修饰规则(简单了解):
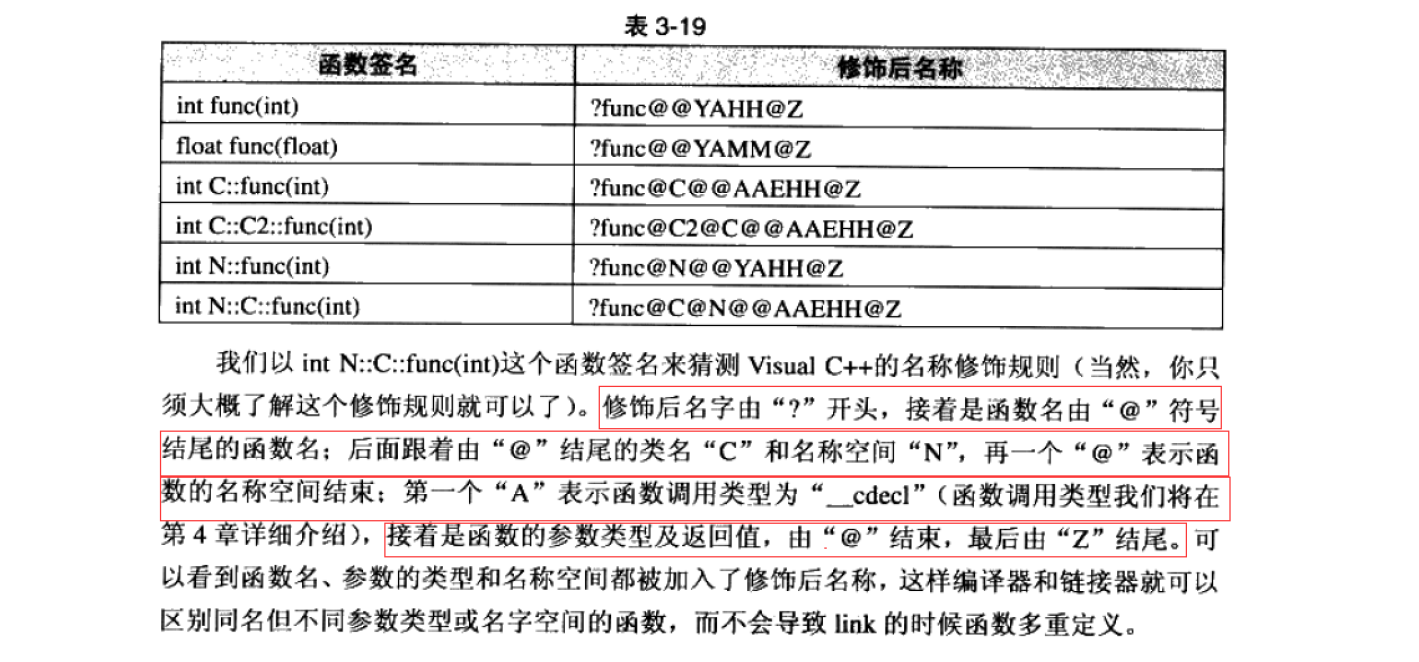
去除函数定义,主函数调用后报错:
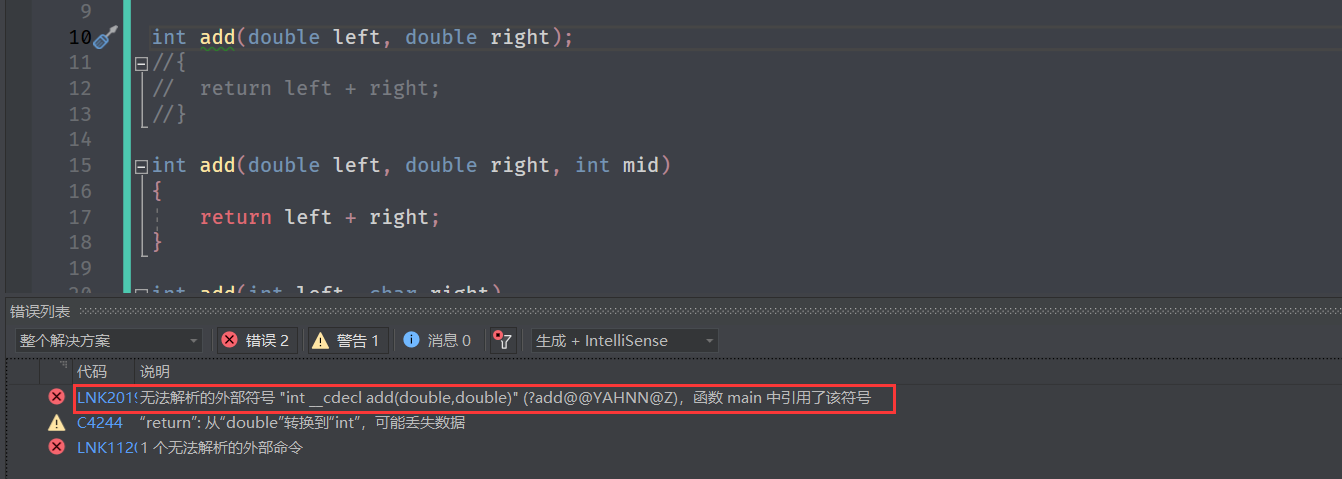
三、引用
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
别名,又可以说是外号,代称,比如水浒传里几乎是别名最多的地方。李逵,在家称为"铁牛",江湖上人称"黑旋风"。铁牛和黑旋风就是李逵的别名。
1、区分
& 就是引用,但是& 这个操作符和取地址 & 操作符是重叠的。
所以它们需要不同的场景规范:
当 &b 单独存在时,这时就代表取地址,为取出变量的地址。
但是如果这样:
int main()
{int a = 10;int& b = a; // 引用int* p = &b; // 取地址return 0;
}
当 & 位于类型和变量名之间时,为引用。
2、本质
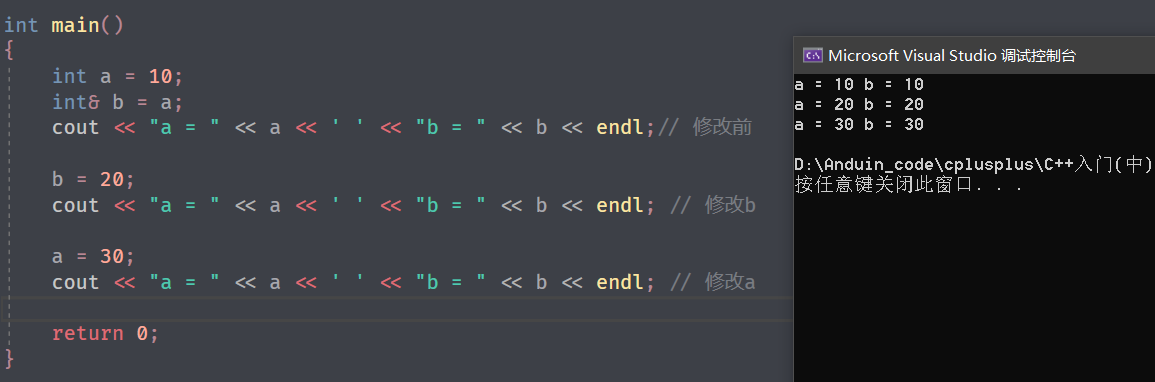
调试查看一下 a 和 b 的关系:

我们发现a和b不仅值相等,连地址也是相同的。而这就说明,b 就是 a ,在语法层面上,这里 b 并不是开辟的新空间,而是对原来的 a 取了一个新名称,叫做 b 。
就好比李逵被叫做黑旋风一样,李逵还是李逵,黑旋风也是它;而 a 就是 a ,但是 b 也是 a 。

而如果这时候对 a 或 b 任意一个修改,那么 a 和 b 都会发生修改。
3、特性
引用有三个注意点。
1) 引用必须在定义时初始化
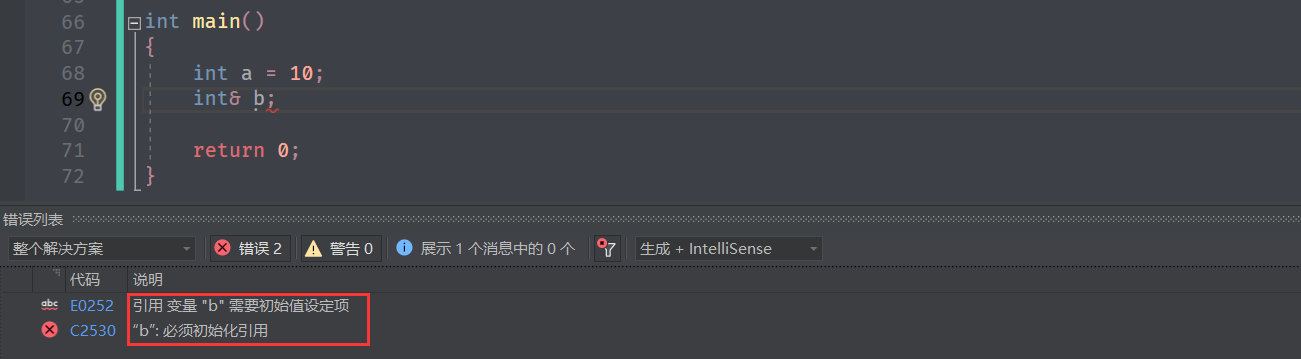
引用是取别名,所以在定义的时候必须明确是谁的别名。
2)一个变量可以有多个引用
就和李逵一样,他可以叫黑旋风也可以叫铁牛,这都是它。
所以一个变量也可以有多个别名。
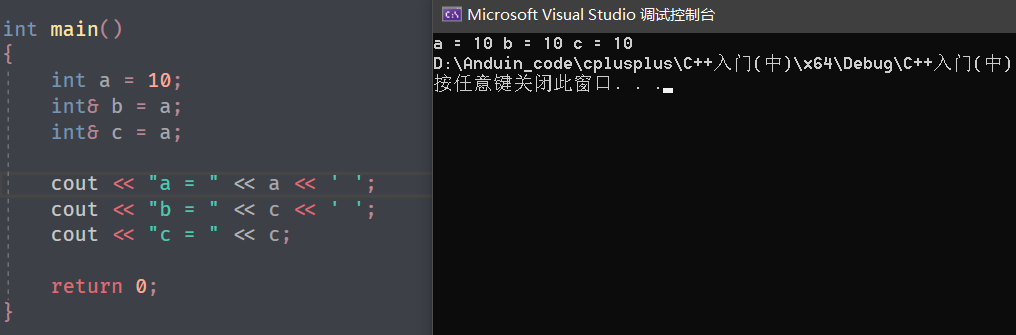
而对于一个起过别名的变量,对它的别名取别名也是可以的。
就好比说有人可能知道李逵也叫铁牛,并不知道他真实姓名,但是他觉得李逵很黑,于是叫他黑旋风,这也没问题,因为这里描述的都是一个人,同理,描述的也是同一个变量。
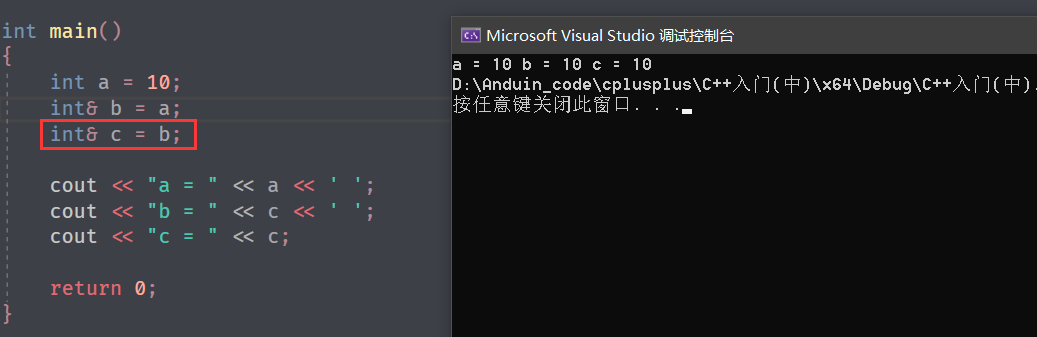
而从根本上看,就可以这么理解:

本质上还是一个变量。
但是别名不能和正式名字冲突,就比如取过别名,就不能定义和别名重命的变量,即使它们的类型不同。
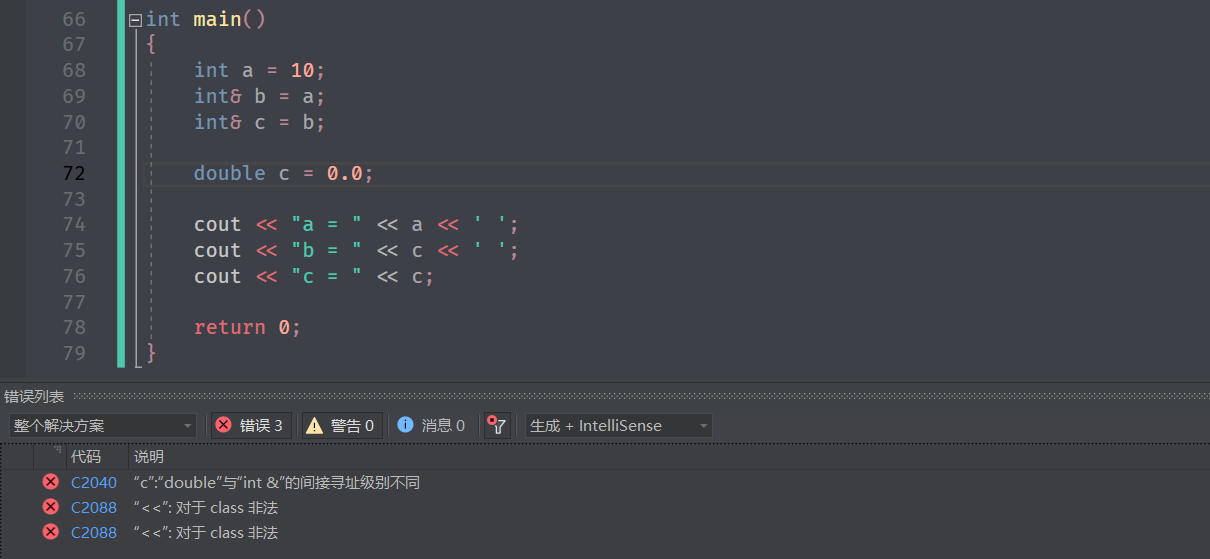
但是这里的报错信息并不准确,实际上为命名冲突。
3)引用一旦引用一个实体,就不能引用其他实体
int main()
{int a = 10;int& b = a;int c = 20;b = c;return 0;
}
对于下一组代码,有什么含义?
- 让 b 变成 c 的别名?
- 还是把 c 赋值给 b ?
这里的代码意思是第二个含义,就是赋值,我们调试看看:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ewhy1pGV-1675308403233)(https://anduin.oss-cn-nanjing.aliyuncs.com/%E5%BC%95%E7%94%A81.gif)]](https://img-blog.csdnimg.cn/e8c83421a4ae426a8b3624b7120a609e.gif)
调试我们也可以看到,我们只是把 c 的值赋值给了 b ,b 的地址还是没变的 ,并且 a 的值也改变了。
这就说明引用一旦引用一个实体,就不能引用其他实体,引用是不会发生改变的。
因为它们是完全独立的两个变量,仅有的关联也只是值相等,改变 b 并不能影响 c ,但是此时 b 是 a 的别名,所以改变 b 会影响 a 。
图:

但是对于指针,则是截然不同的:
int main()
{int a = 10;int c = 20;int* p = &a;p = &c;return 0;
}
对于指针来说,指针可以时刻修改:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9KSddSMf-1675308403233)(https://anduin.oss-cn-nanjing.aliyuncs.com/%E5%BC%95%E7%94%A82.gif)]](https://img-blog.csdnimg.cn/e3f795478b32444896dee258c1593c8e.gif)
p原本指向 a ,现在指向 c .
但是引用也有局限性,因为引用之后的变量是不可修改引用的,比如链表,节点是要不断更替迭代的,所以还需要指针配合,C++才可以写出一个链表。
4、应用
a、做参数
我们知道实参的改变不影响实参,所以这种写法并不能改变值,因为此刻是 传值调用 :
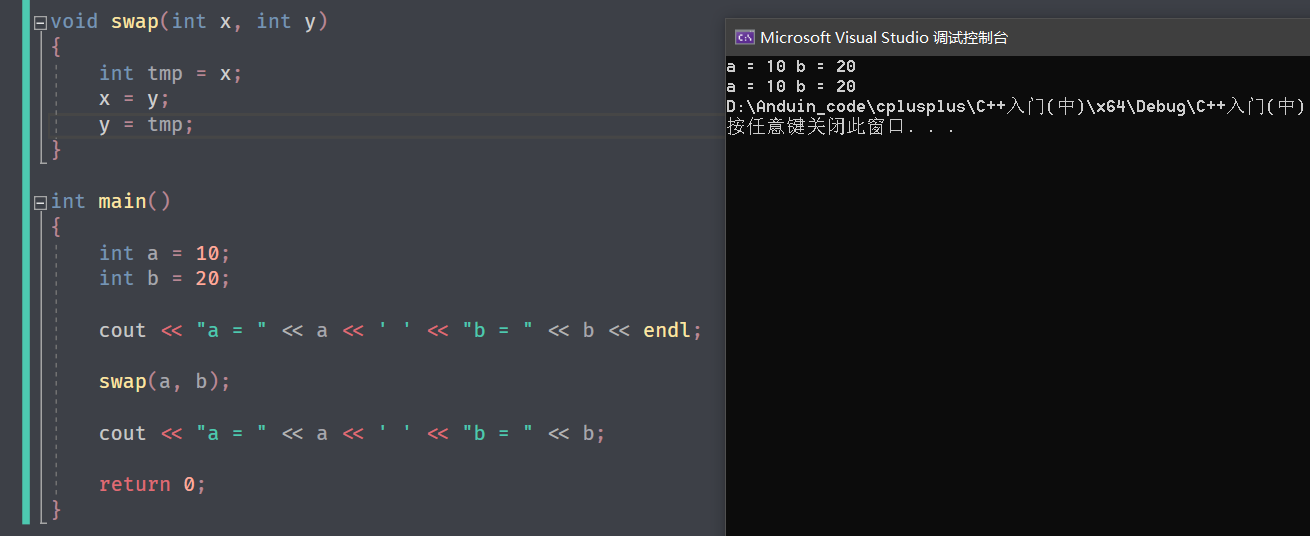
按照之前 c 的写法,我们使用 传址调用 ,用指针修改:
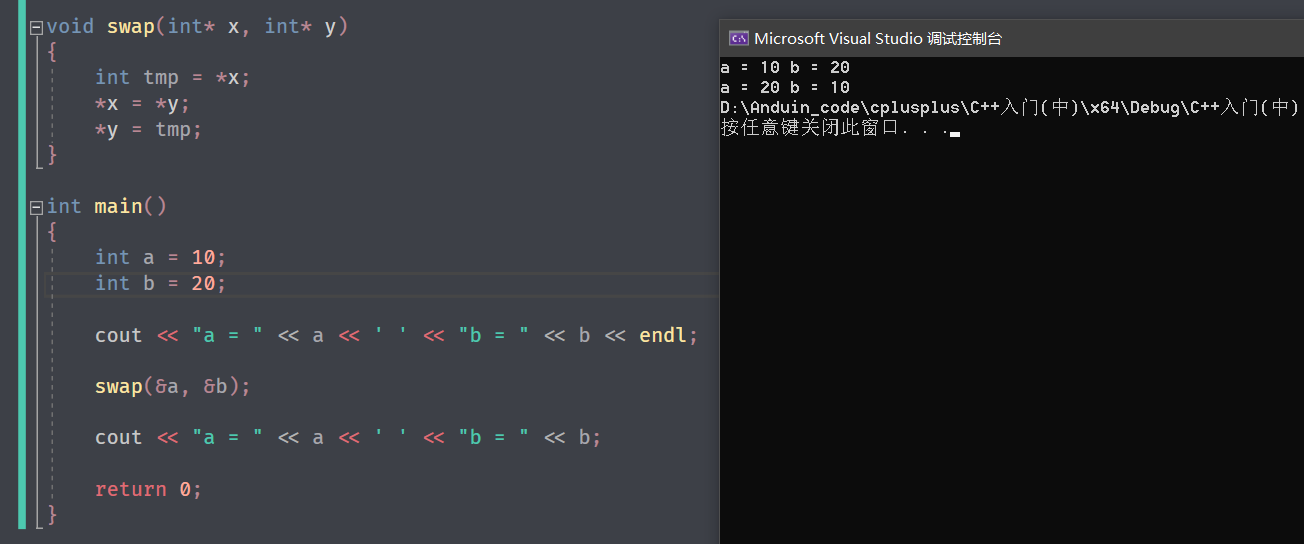
但是学习引用之后,完全可以用引用修改:
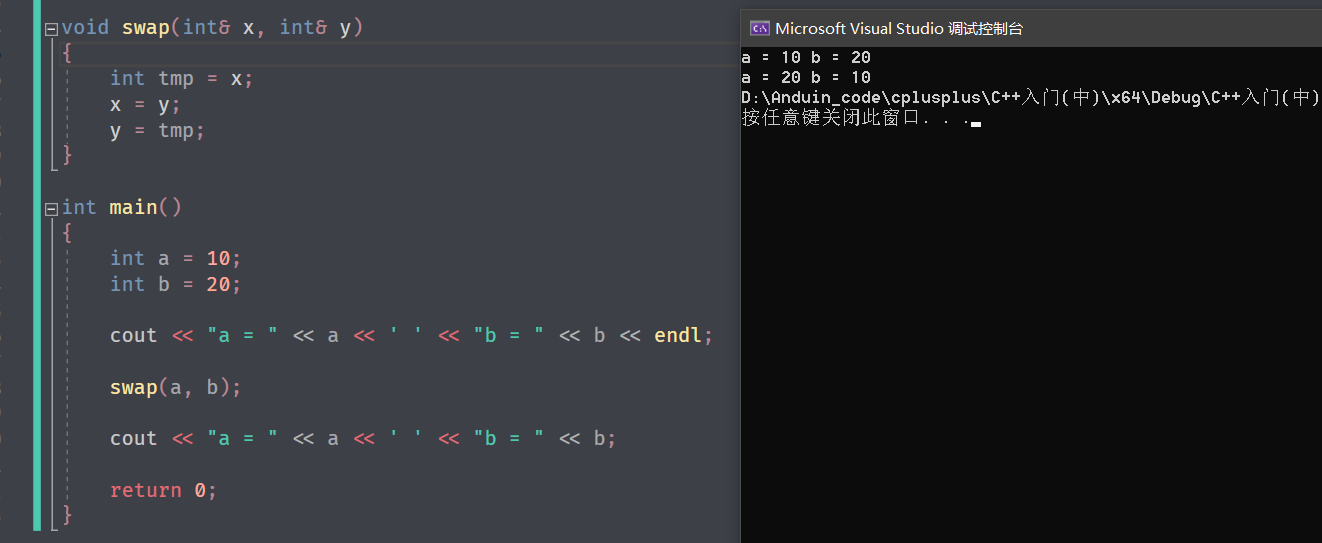
x 和 y 分别是 a 和 b 的引用,对 x 和 y 进行修改,就是对 a 和 b 进行修改,所以值也被修改成功了。
调试看一下:
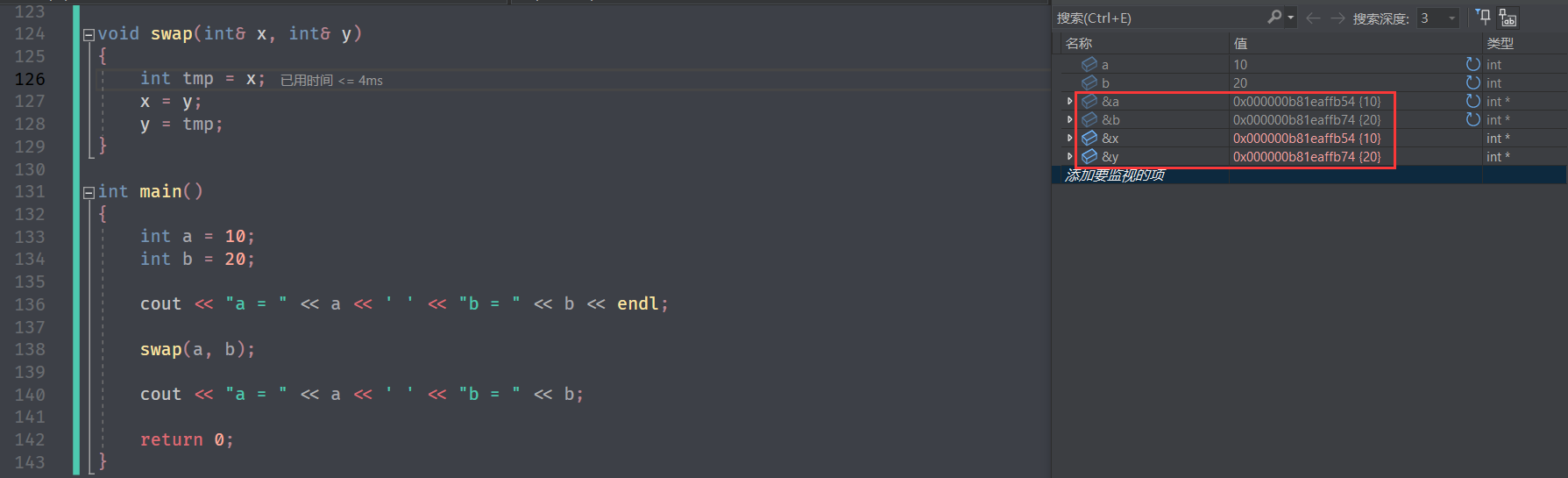
它们的地址是完全相同的。而这里这里既不是传值调用,也不是传址调用,而是 传引用调用 。
思考:上面三个函数是否构成函数重载? 构成,但无法调用。
根据函数名修饰规则,传值和传引用的是不一样的,比如会加上 R 做区分。
但是不能同时调用传值和传引用,因为有歧义,因为 调用不明确 ,编译器并不知道调用哪个:
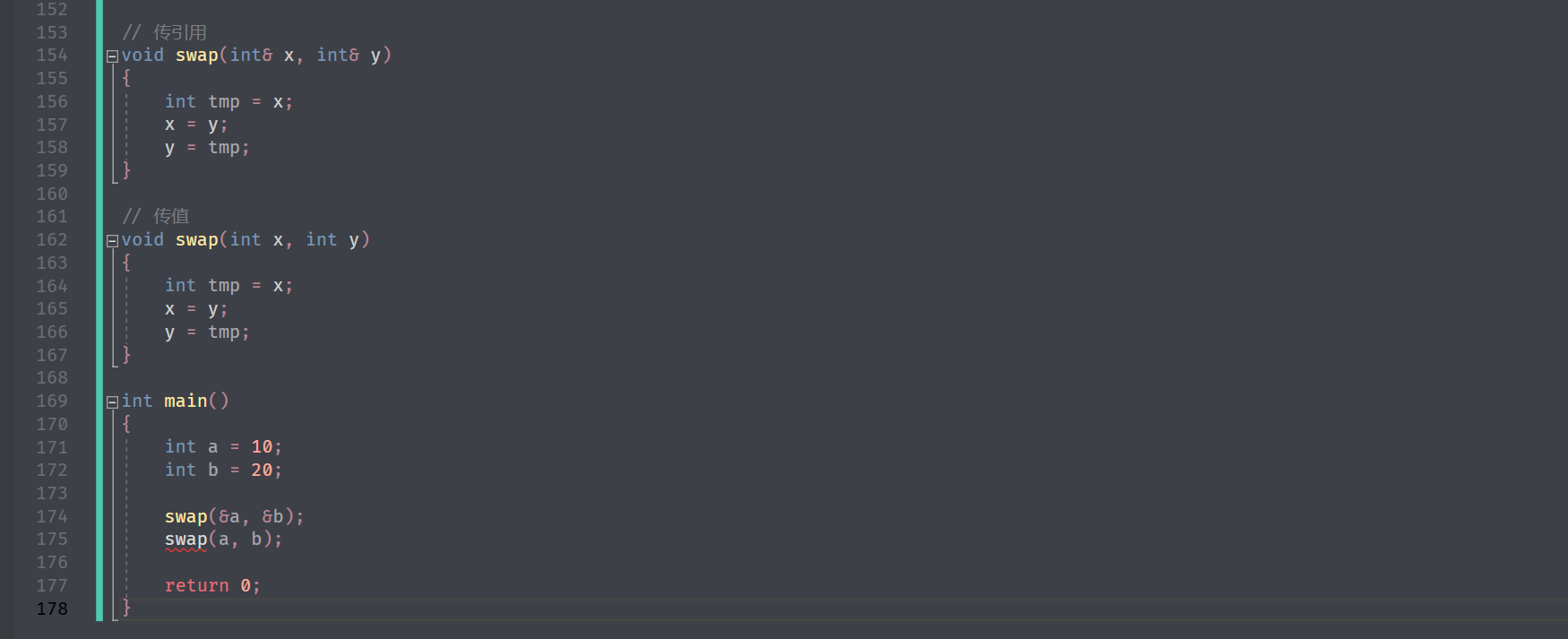
引用解决二级指针生涩难懂的问题 :
讲单链表时,我们写的由于是没有头结点的链表,所以修改时,需要二级指针,对于指针概念不清晰的小伙伴们可能比较难理解。
但是学了引用,就可以解决这个问题:
结构定义:
typedef struct SListNode
{int data;struct SListNode* next;
}SLTNode;
原代码:
void SListPushFront(SLTNode** pphead, SLTDateType x)
{SLTNode* newnode = BuyListNode(x);newnode->next = *pphead; *pphead = newnode;
}// 调用
SLTNode* pilst = NULL;
SListPushFront(&plist);
修改后:
void SListPushFront(SLTNode*& pphead, SLTDateType x) // 改
{SLTNode* newnode = BuyListNode(x);newnode->next = *pphead; *pphead = newnode;
}// 调用
SLTNode* pilst = NULL;
SListPushFront(plist); // 改
修改之后的代码里的二级指针被替换成了引用。
而这里的意思就是给一级指针取了一个别名,传过来的是plist,而plist 是一个一级指针,所以会出现 * ,而这里就相当于 pphead 是 plist 的别名。而这里修改 pphead ,也就可以对 plist 完成修改。
但是有时候也会这么写 :
结构改造:
typedef struct SListNode
{int data;struct SListNode* next;
}SLTNode, *PSLTNode;
这里的意思就是将 struct SListNode* 类型重命名为 PSLTNode 。
代码:
void SListPushFront(PSLTNode& pphead, SLTDateType x) // 改
{PSLTNode newnode = BuyListNode(x);newnode->next = pphead; pphead = newnode;
}// 调用
PSLTNode plist = NULL;
SListPushFront(plist);
在 typedef 之后,PSLTNode 就是结构体指针,所以传参过去,只需要在形参那边用引用接收,随后进行操作,就可以达成目的。
而形参的改变影响实参的参数叫做输出型参数,对于输出型参数,使用引用十分舒适。
如果了解引用,那么这一部分是相当好理解的,一些数据结构教科书上也是这么写的,但是如果不懂引用,甚至会觉得比二级指针还难以理解。
在我们学习了引用之后,之后也可以这么写代码,更加方便。
b、做返回值
要搞清楚这一块,我们先进行一些铺垫。
int add(int a, int b)
{int c = a + b;return c;
}int main()
{int ret = add(1, 2);cout << ret << endl;return 0;
}
这里看似很简单,就是把add函数计算结束的结果返回,但是这里包含了 传值返回 。
若从栈帧角度看,会先创建 main 函数的栈帧,里面就会有 call 指令,开始调用 add 函数。而 add 函数也会形成栈帧,而栈帧中也有两块小空间,用来接受参数,分别为 a 和 b,而里面的 c 则用来计算结果并返回。
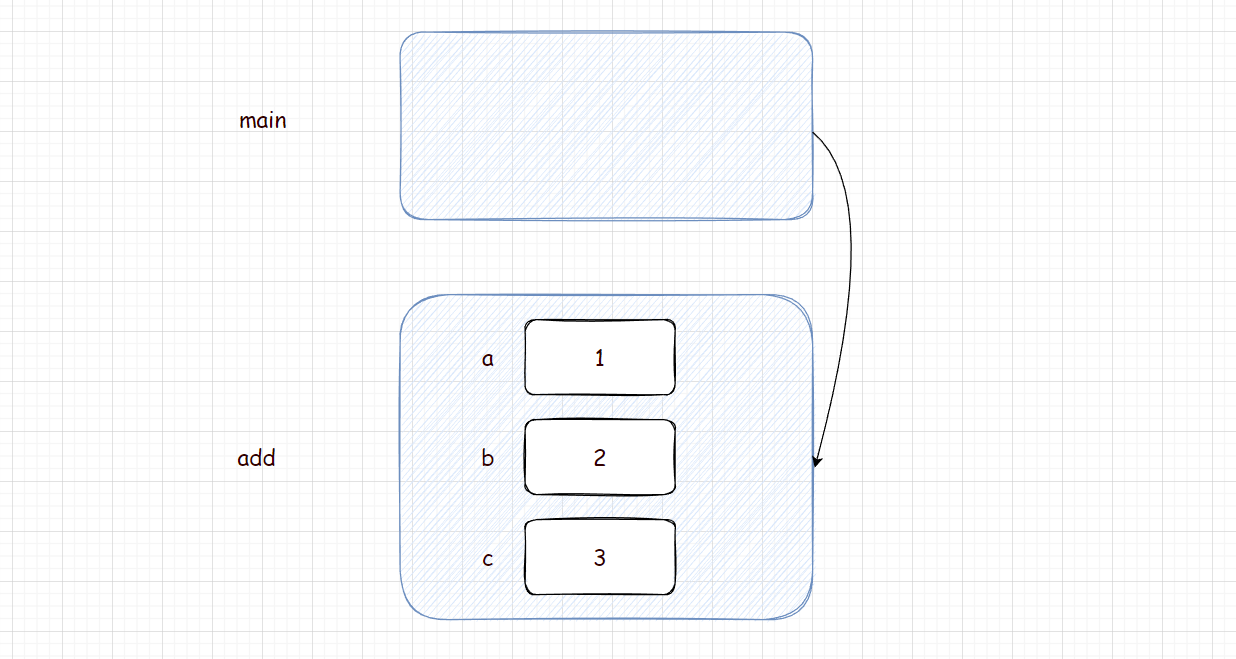
而对于传值返回,返回的并不是 c ,而是返回的是 c 的拷贝。而这其中会有一个临时变量,返回的是临时变量(见函数栈帧)
如果返回的是 c 的话,由于 add 的函数栈帧已经销毁了,就会产生很多奇怪的问题。c 能不能取到都是未知,而这时都是非法访问,因为空间已经被归还给系统了,所以必定是c拷贝后的数据被返回。
但是临时变量在哪?
- 如果 c 比较小(4/8 byte),一般是寄存器充当临时变量,例如eax
- 如果 c 比较大,临时变量放在调用 add 函数的栈帧中,
最后将临时变量中的值赋值给ret
图:
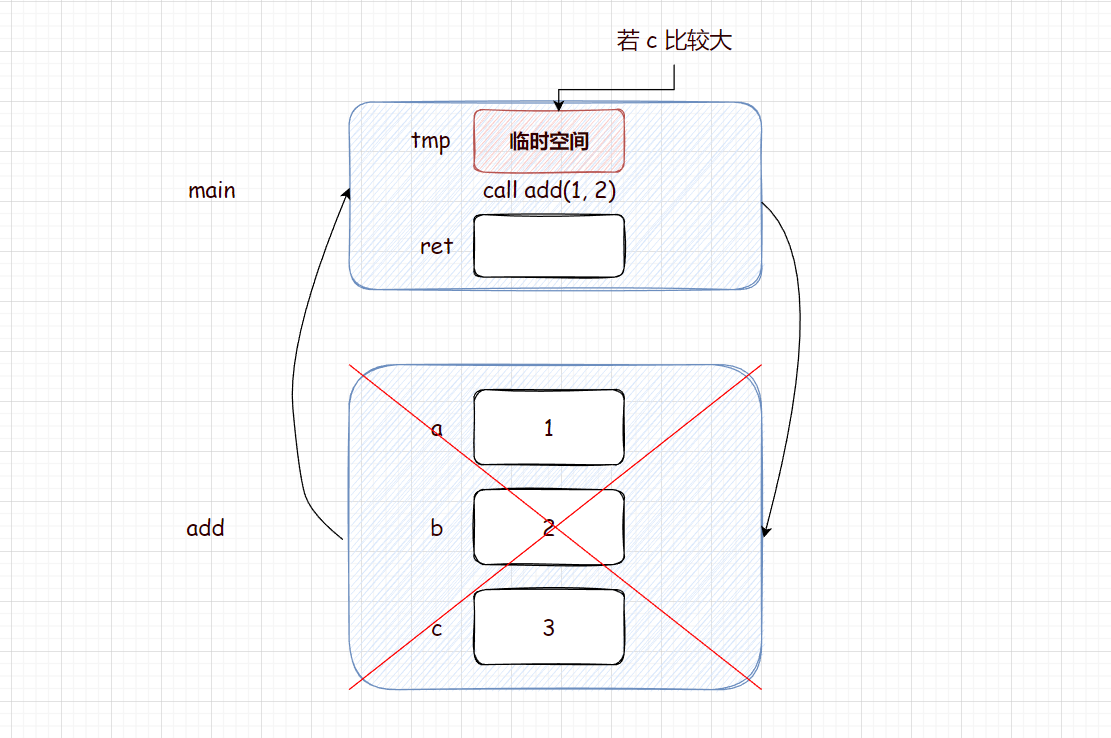
所有的传值返回都会生成一个拷贝
便于理解,看一下汇编:

看第四句话,这里是说,把 eax 中的值,拷贝到 ret 中。
而再函数调用返回时:

这里是将 c 的值放到 eax 中的。
这也就印证了返回时,是以临时拷贝形式返回的,由于返回值是 int ,所以是直接用的 eax 寄存器。
而不论这个函数结束后,返回的那个值会不会被销毁,都会创建临时变量返回,例如这段代码 :
int c()
{static int n = 0;n++;return n;
}int main()
{int ret = c();cout << ret << endl;return 0;
}
对于该函数,编译器仍然是创建临时变量返回;因为编译器不会对其进行特殊处理。
看一下汇编:

仍然是放到 eax 寄存器中返回的。
埋个伏笔:你觉不觉的这个临时变量创建的很冤枉,明明这块空间一直存在,我却依然创建临时变量返回了?能不能帮它洗刷冤屈。
如果我改成引用返回会发生什么情况吗?
int& add(int a, int b)
{int c = a + b;return c;
}int main()
{int ret = add(1, 2);cout << ret << endl;return 0;
}
引用返回就是不生成临时变量,直接返回 c 的引用。而这里产生的问题就是 非法访问 。
造成的问题:
- 存在非法访问,因为 add 的返回值是 c 的引用,所以 add 栈帧销毁后,会访问 c 位置空间,而这是读操作,不一定检查出来,但是本质是错的。
- 如果 add 函数栈帧销毁,空间被清理,那么取 c 值时取到的就是随机值,取决于编译器的决策。
ps:虽然vs销毁栈帧没有清理空间数据,但是会二次覆盖
来看个有意思的:
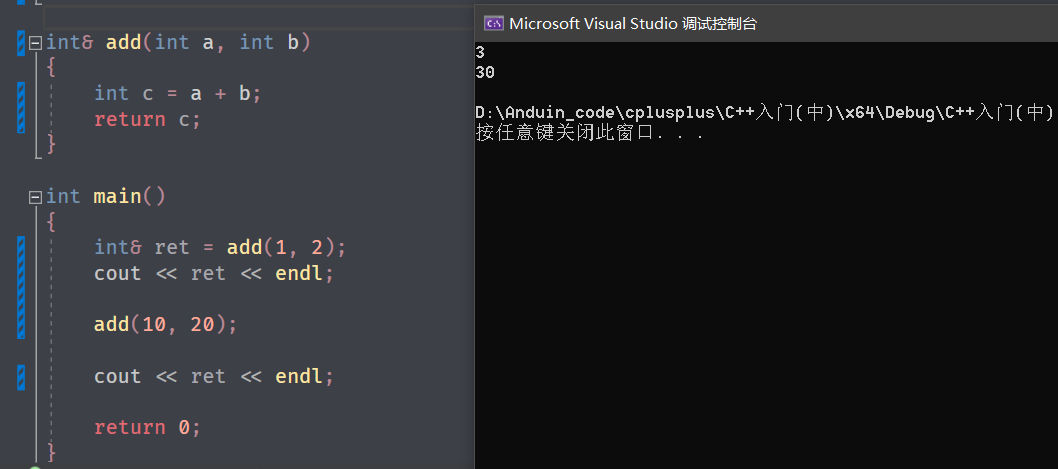
例如这里,当调用 add 函数之后,返回 c 的引用,接收返回值是用的ret相当于是 c 的引用,这时由于没有清理栈帧数据,所以打印3;
但是第二次调用,重新建立栈帧,由于栈帧大小相同,第二次建立栈帧可能还是在原位置,之前空间的数据被覆盖,继续运算,但是此时,ret 那块空间的值就被修改了,而这时没有接收返回值,但是原先的那块 c 的值被修改,所以打印出来 ret 是 30 。
所以使用引用返回时,一旦返回后,返回值的空间被修改,那么都可能会造成错误,使用要小心!
引用返回有一个原则:如果函数返回时,出了函数作用域,如果返回对象还在(还没还给系统),则可以使用引用返回,如果已经还给系统了,则必须使用传值返回。
它俩的区别就是一个生成拷贝,一个不生成拷贝。
而这时 static 修饰的静态变量不委屈了:
int& c()
{static int n = 0;n++;return n;
}
因为 static 修饰的变量在静态区,出了作用域也存在,这时就可以引用返回。
我们可以理解引用返回也有一个返回值,但是这个返回值的类型是 int& ,中间并不产生拷贝,因为返回的是别名。这就相当于返回的就是它本身。
有时引用返回可以发挥出意想不到的结果:
#include <cassert>
#define N 10typedef struct Array
{int a[N];int size;
}AY;int& PostAt(AY& ay, int i)
{assert(i < N);return ay.a[i];
}int main()
{AY ay;PostAt(ay, 1); // 修改返回值for (int i = 0; i < N; i++){PostAt(ay, i) = i * 3;}for (int i = 0; i < N; i++){cout << PostAt(ay, i) << ' ';}return 0;
}
由于PostAt 的形参 ay 为 main 中 局部变量 ay的别名,所以 ay 一直存在;这时可以使用引用返回。
引用返回 减少了值拷贝 ,不比将其拷贝到临时变量中返回;并且由于是引用返回,我们也可以 修改返回对象 。

总结提炼:如果出了作用域,返回变量(静态,全局,上一层栈帧,malloc等)仍然存在,则可以使用引用返回。
5、效率比较
值和引用的作为返回值类型的性能比较:
#include <time.h>
struct A { int a[10000]; };
A a;
// 值返回
A TestFunc1() { return a; } // 拷贝
// 引用返回
A& TestFunc2() { return a; } // 不拷贝
void TestReturnByRefOrValue()
{// 以值作为函数的返回值类型size_t begin1 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc1();size_t end1 = clock();// 以引用作为函数的返回值类型size_t begin2 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc2();size_t end2 = clock();// 计算两个函数运算完成之后的时间cout << "TestFunc1 time:" << end1 - begin1 << endl;cout << "TestFunc2 time:" << end2 - begin2 << endl;
}int main()
{TestReturnByRefOrValue();return 0;
}
由于传值返回要拷贝,所以当拷贝量大,次数多时,比较耗费时间;而传引用返回就不会,因为返回的就是别名。

对于返回函数作用域还在的情况,引用返回优先。
引用传参和传值传参效率比较 :
#include <time.h>
struct A { int a[10000]; };
void TestFunc1(A a) {}
void TestFunc2(A& a) {}
void TestRefAndValue()
{A a;// 以值作为函数参数size_t begin1 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc1(a);size_t end1 = clock();// 以引用作为函数参数size_t begin2 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc2(a);size_t end2 = clock();// 分别计算两个函数运行结束后的时间cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
}int main()
{TestRefAndValue();
}
还是引用快,因为引用减少拷贝次数:

总结:引用的作用主要体现在传参和传返回值
- 引用传参和传返回值,在有些场景下可以提高性能(大对象 and 深拷贝对象 – 之后会讲)。
- 引用传参和传返回值,在对于输出型参数和输出型返回值很舒服。说人话就是形参改变,实参也改变 or 返回对象(返回值改变)。
6、常引用
const 修饰的是常变量,不可修改。

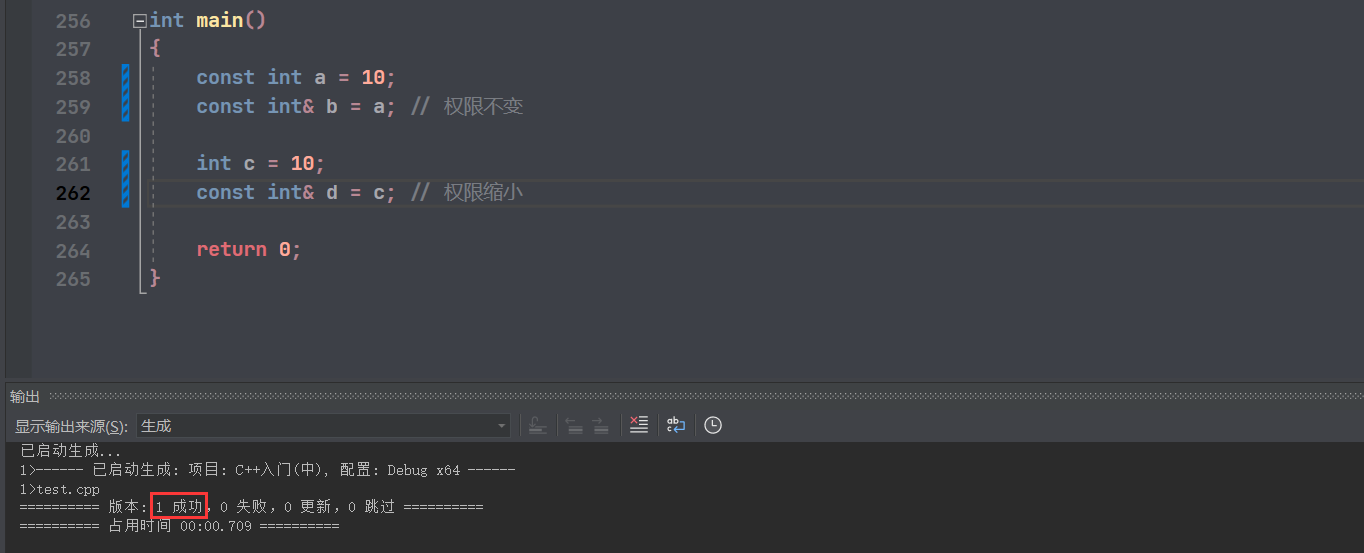
a 本身都不能修改,b 为 a 的引用,那么 b 也不可以修改,这样就没意义了。a 是只读,但是引用 b 具有 可读可写 的权利,该情况为 权限放大 ,所以错误了。
这时,只要加 const 修饰 b ,让 b 的权限也只有只读,使得 权限不变 ,就没问题了:
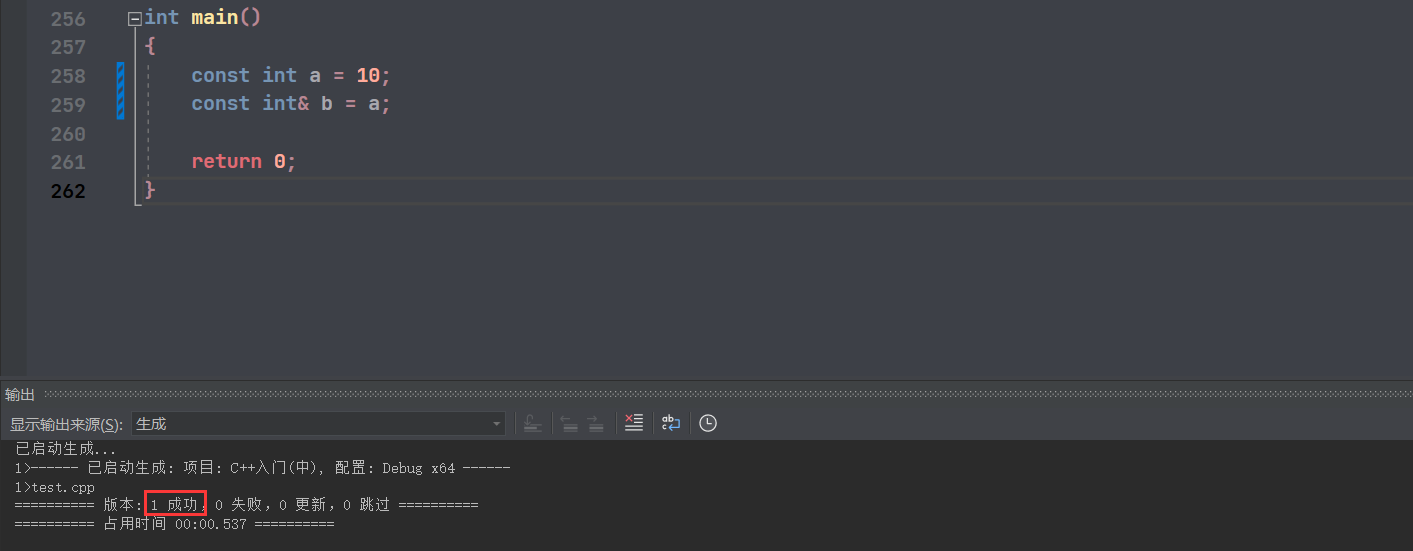
而如果原先变量可读可写,但是别名用 const 修饰,也是可以的,这种情况为 权限缩小 :
对于函数的返回值来说,也不能权限放大,例如:
int c()
{static int n = 0;n++;return n;
}int main()
{int& ret = c(); // errorreturn 0;
}
这样也是不行的,因为返回方式为 传值返回 ,返回的是临时变量,具有 常性 ,是不可改的;而引用放大了权限,所以是错误的;这时加 const 修饰就没问题:const int& ret = c(1, 2)
那么这种情况为什么不可以?

而这样就可以了?

因为类型转换会产生临时变量 :
对于类型转换来说,在转换的过程中会产生一个个临时变量,例如 double d = i,把i转换后的值放到临时变量中,把临时变量给接收的值d
而临时变量具有常性,不可修改,引用就加了写权限,就错了,因为 权限被放大了 。
提炼:对于引用,引用后的变量所具权限可以缩小或不变,但是不能放大(指针也适用这个说法)
作用 :
在一些场景下,假设 x 是一个大对象,或者是深拷贝对象,那一般都会用引用传参,减少拷贝,如果函数中不改变 x ,尽量用 const 引用传参。
这样可以防止 x 被修改 ,而对于 const int& x 也可以接受权限对等或缩小的对象,甚至为常量:
结论 :
- const type& 可以接收各种类型的对象(变量、常量、隐式转换)。对于输出型参数用引用,否则用 const type&,更加安全。
7、指针和引用区别
从语法概念上来说,引用是没有开辟空间的,而指针是开辟了空间的,但是从底层实现上来说,则又不一样:
int main()
{int a = 10;int& ra = a;ra = 20;int* pa = &a;*pa = 20;return 0;
}
汇编:
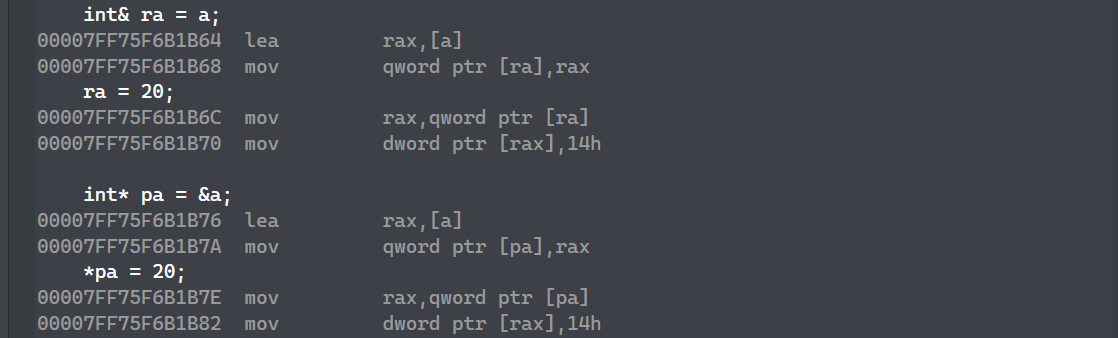
lea 是取地址:我们发现无论引用和指针,都会取地址,且这些过程和指针一样。
其实从汇编上,引用其实是开空间的,并且实现方式和指针一样,引用其实也是用指针实现的。
区别汇总:
- 引用概念上定义一个变量的 别名 ,指针存储一个变量 地址
- 引用 在定义时 必须初始化 ,指针最好初始化 ,但是不初始化也不会报错
- 引用在初始化时引用一个实体后 ,就不能再引用其他实体 ,而指针可以在任何时候指向任何一个同类型
- 没有NULL引用,但有NULL指针
- 在sizeof中含义不同:引用结果为 引用类型的大小,但指针始终是 地址空间所占字节个数 (32位平台下占4个字节)
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
- 有多级指针,但是没有多级引用
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
- 引用比指针使用起来相对更安全
7, 8, 9点说明指针使用起来更复杂一些,更容易出错;而引用则相对简单。
四、结语
到这里,本篇文章就到此结束了。
今天的内容就两块,其实讲讲还是很多的,特别是引用,要点很多,但是用起来那是相当的舒服。所以小伙伴们,赶快用起来吧!
如果觉得 anduinanduinanduin 写的不错的话,可以点赞 + 收藏 + 评论支持一下哦!
那么我们下期见!