目录:
- 1. CrawlSpider的引入:
- (1)首先:观察之前创建spider爬虫文件时
- (2)然后:通过命令scrapy genspider获取帮助:
- (3)最后:使用模板crawl创建一个爬虫文件:
- 2.CrawlSpider的正式讲解
- 2.1 我们通过爬取ZH小说来深入了解它!
- 规划我们的目标:
- 2.2 先获取目标URL第一页的书籍信息!!!
- ①第一步:通过解析start_urls的响应,获取所有书籍URL
- ②第二步:通过解析书籍URL获取到的响应,获取以下数据:
- ③第三步:通过解析书籍URL获取的响应里解析得到的每个小说章节列表页的所有URL,并发送请求获得响应:
- ④第四步:通过解析对应小说的章节列表页获取到的每一章节的URL,发送请求获得响应,得到对应章节的章节内容:
1. CrawlSpider的引入:
(1)首先:观察之前创建spider爬虫文件时
之前使用scrapy框架时,我们创建spider爬虫文件使用的都是默认的basic模板:

观察使用这个命令创建的spider爬虫文件,可知它继承的是scrapy.Spider类:

(2)然后:通过命令scrapy genspider获取帮助:
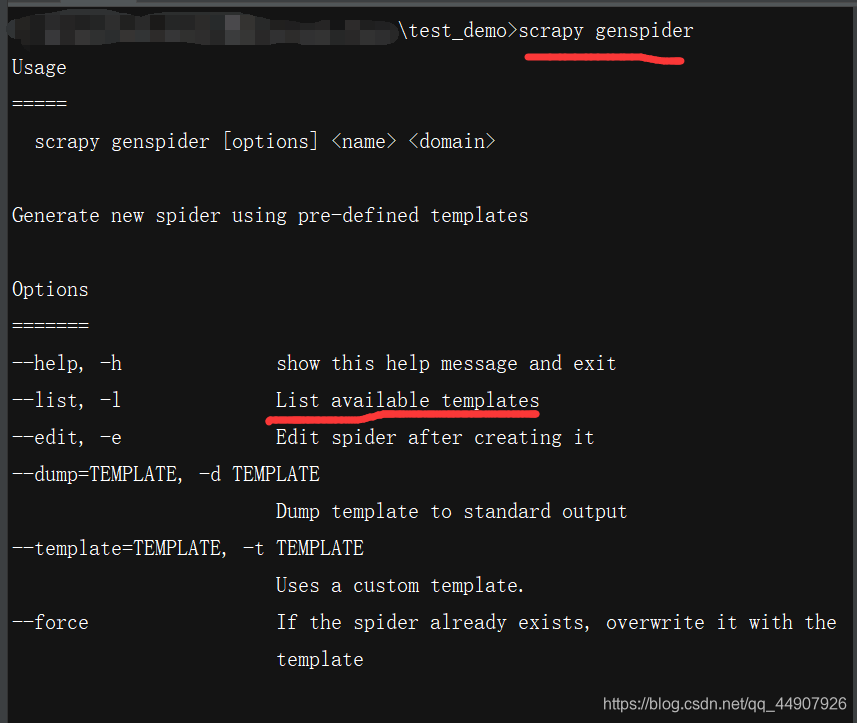
使用帮助里的命令scrapy genspider -l命令可查看可用的爬虫模板:
(3)最后:使用模板crawl创建一个爬虫文件:
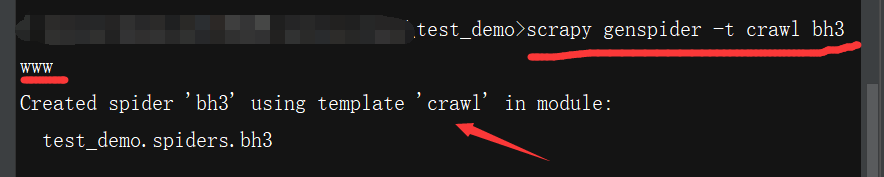
观察创建的爬虫文件,可知,它继承的是CrawlSpider类(注意:CrawlSpider类又继承了Spider类!),这就是本篇文章介绍的玩意:
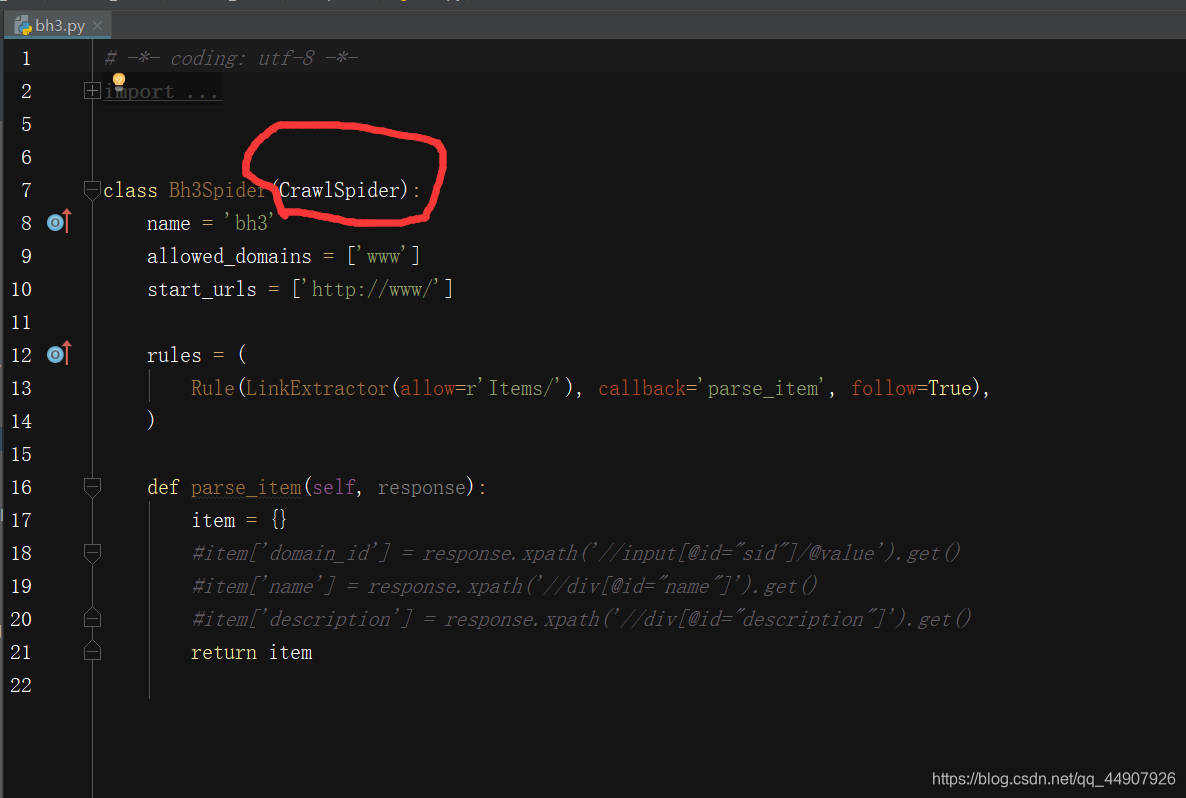
2.CrawlSpider的正式讲解
- 这是个啥玩意?
创建的继承CrawlSpider类的爬虫文件!
2.1 我们通过爬取ZH小说来深入了解它!
规划我们的目标:
目标分四步走:
- 第一步:start_urls—>纵横小说首页中选择完本,免费,总点击!!!:(书籍列表URL)
- 第二步:通过解析start_urls获得的响应,获取到书籍列表URL。并解析书籍列表URL的响应,获取到以下数据:
id,catagory(分类),book_name,author,status,book_nums,description,c_time,book_url,catalog_url - 第三步:通过解析书籍列表URL的响应,获取到每个小说章节列表页的URL,并发送请求获得响应,得到对应小说的章节列表页,获取以下数据:
章节列表(id) , title(章节名称) content(内容),ordernum(序号),c_time,chapter_url(章节url),catalog_url(目录url) - 第四步:通过解析对应小说的章节列表页获取到每一章节的URL,发送请求获得响应,得到对应章节的章节内容:
(章节内容)
第一步:http://book.zongheng.com/store/c0/c0/b0/u1/p1/v0/s1/t0/u0/i1/ALL.html
第二步:http://book.zongheng.com/book/431658.html
第三步:http://book.zongheng.com/showchapter/431658.html
第四步:http://book.zongheng.com/chapter/431658/7255260.html
一步步实现:贪多嚼不烂。按步骤来,一步一个脚印,分阶段获取所需内容,报错易查!!!
2.2 先获取目标URL第一页的书籍信息!!!
项目创建:
# 创建scrapy项目:
scrapy startproject zongheng# 爬虫文件创建:
scrapy genspider -t crawl zh http://book.zongheng.com/
①第一步:通过解析start_urls的响应,获取所有书籍URL
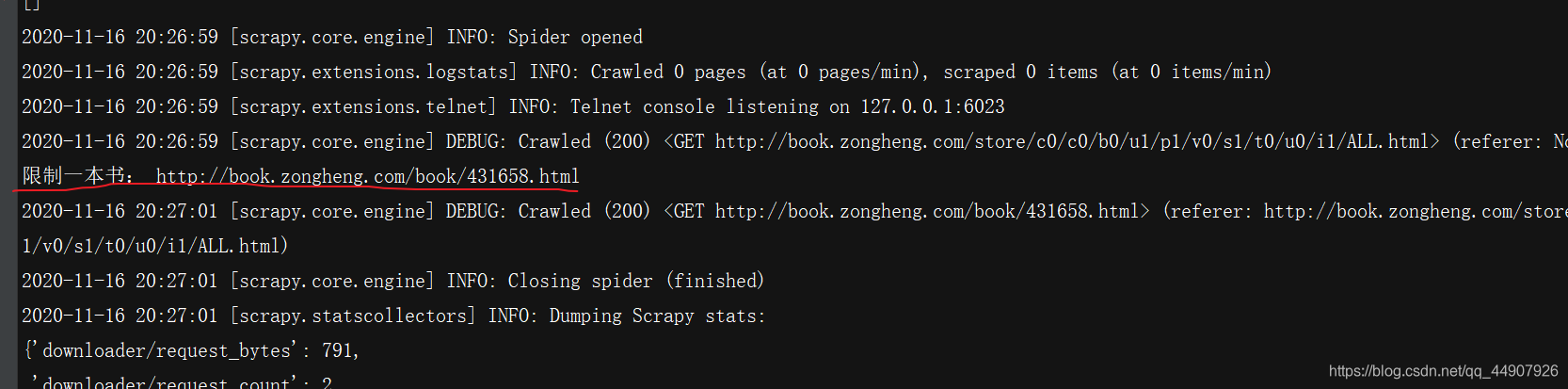
- (为了避免一次爬取数据过多被封,通过特殊处理限定只获取一本小说的URL)
首先,编写爬虫文件:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Ruleclass Bh3Spider(CrawlSpider):name = 'zh'allowed_domains = ['book.zongheng.com']start_urls = ['https://book.zongheng.com/store/c0/c0/b0/u1/p1/v0/s1/t0/u0/i1/ALL.html']rules = (# Rule定义爬取规则: 1.提取url(LinkExtractor对象) 2.形成请求 3.响应的处理规则# 源码:Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True)# 1.LinkExractor是scrapy框架定义的一个类,它定义如何从每个已爬网页面中提取url链接,并将这些url作为新的请求发送给引擎# 引擎经过一系列操作后将response给到callback所指的回调函数。# allow=r'Items/'的意思是提取链接的正则表达式 【相当于findall(r'Items/',response.text)】# 2.callback='parse_item'是指定回调函数。# 3.follow=True的作用:LinkExtractor提取到的url所生成的response在给callback的同时,还要交给rules匹配所有的Rule规则(有几条遵循几条)# 拿到了书籍的url 回调函数 process_links用于处理LinkExtractor匹配到的链接的回调函数# 匹配每个书籍的urlRule(LinkExtractor(allow=r'https://book.zongheng.com/book/\d+.html',restrict_xpaths=("//div[@class='bookname']")), callback='parse_book', follow=True,process_links="process_booklink"),)def process_booklink(self, links):for index, link in enumerate(links):# 限制一本书if index == 0:print("限制一本书:", link.url)yield linkelse:returndef parse_book(self, response):item = {}# item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()# item['name'] = response.xpath('//div[@id="name"]').get()# item['description'] = response.xpath('//div[@id="description"]').get()return item
然后,配置settings.py里的必要配置后运行,即可发现指定页面第一本小说URL获取正常:
②第二步:通过解析书籍URL获取到的响应,获取以下数据:
- id,catagory(分类),book_name,author,status,book_nums,description,c_time,book_url,catalog_url
首先,编写爬虫文件中callback指定的回调函数parse_book:
def parse_book(self, response):print("解析book_url")# 字数:book_nums=response.xpath('//div[@class="nums"]/span/i/text()').extract()[0]# 书名:book_name=response.xpath('//div[@class="book-name"]/text()').extract()[0].strip()category=response.xpath('//div[@class="book-label"]/a/text()').extract()[1]author=response.xpath('//div[@class="au-name"]/a/text()').extract()[0]status=response.xpath('//div[@class="book-label"]/a/text()').extract()[0]description="".join(response.xpath('//div[@class="book-dec Jbook-dec hide"]/p/text()').extract())c_time=datetime.datetime.now()book_url=response.urlcatalog_url=response.css("a").re("http://book.zongheng.com/showchapter/\d+.html")[0]print(book_nums,book_name,category,author,status,description,c_time,book_url,catalog_url)
然后,运行可发现数据获取正常:

③第三步:通过解析书籍URL获取的响应里解析得到的每个小说章节列表页的所有URL,并发送请求获得响应:
- 得到对应小说的章节列表页,获取以下数据:id , title(章节名称) content(内容),ordernum(序号),c_time,chapter_url(章节url),catalog_url(目录url)
首先:编写爬虫文件:(注意:1.这就需要我们再定义一个rules规则,进行书籍章节列表页的URL的获取以及对应响应数据的解析!2.编写相应的回调函数,进行书籍章节列表页信息的获取!)
# -*- coding: utf-8 -*-
import datetimeimport scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Ruleclass Bh3Spider(CrawlSpider):name = 'zh'allowed_domains = ['book.zongheng.com']start_urls = ['https://book.zongheng.com/store/c0/c0/b0/u1/p1/v0/s1/t0/u0/i1/ALL.html']rules = (# Rule定义爬取规则: 1.提取url(LinkExtractor对象) 2.形成请求 3.响应的处理规则# 源码:Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True)# 1.LinkExractor是scrapy框架定义的一个类,它定义如何从每个已爬网页面中提取url链接,并将这些url作为新的请求发送给引擎# 引擎经过一系列操作后将response给到callback所指的回调函数。# allow=r'Items/'的意思是提取链接的正则表达式 【相当于findall(r'Items/',response.text)】# 2.callback='parse_item'是指定回调函数。# 3.follow=True的作用:LinkExtractor提取到的url所生成的response在给callback的同时,还要交给rules匹配所有的Rule规则(有几条遵循几条)# 拿到了书籍的url 回调函数 process_links用于处理LinkExtractor匹配到的链接的回调函数# 匹配每个书籍的urlRule(LinkExtractor(allow=r'https://book.zongheng.com/book/\d+.html',restrict_xpaths=("//div[@class='bookname']")), callback='parse_book', follow=True,process_links="process_booklink"),# 匹配章节目录的urlRule(LinkExtractor(allow=r'https://book.zongheng.com/showchapter/\d+.html',restrict_xpaths=('//div[@class="fr link-group"]')), callback='parse_catalog', follow=True),)def process_booklink(self, links):for index, link in enumerate(links):# 限制一本书if index == 0:print("限制一本书:", link.url)yield linkelse:returndef parse_book(self, response):print("解析book_url")# 字数:book_nums = response.xpath('//div[@class="nums"]/span/i/text()').extract()[0]# 书名:book_name = response.xpath('//div[@class="book-name"]/text()').extract()[0].strip()category = response.xpath('//div[@class="book-label"]/a/text()').extract()[1]author = response.xpath('//div[@class="au-name"]/a/text()').extract()[0]status = response.xpath('//div[@class="book-label"]/a/text()').extract()[0]description = "".join(response.xpath('//div[@class="book-dec Jbook-dec hide"]/p/text()').extract())c_time = datetime.datetime.now()book_url = response.urlcatalog_url = response.css("a").re("https://book.zongheng.com/showchapter/\d+.html")[0]print(book_nums, book_name, category, author, status, description, c_time, book_url, catalog_url)def parse_catalog(self, response):print("解析章节目录", response.url) # response.url就是数据的来源的url# 注意:章节和章节的url要一一对应a_tags = response.xpath('//ul[@class="chapter-list clearfix"]/li/a')chapter_list = []for index, a in enumerate(a_tags):title = a.xpath("./text()").extract()[0]chapter_url = a.xpath("./@href").extract()[0]ordernum = index + 1c_time = datetime.datetime.now()catalog_url = response.urlchapter_list.append([title, ordernum, c_time, chapter_url, catalog_url])print('章节目录:', chapter_list)
然后:运行会发现数据获取正常!

④第四步:通过解析对应小说的章节列表页获取到的每一章节的URL,发送请求获得响应,得到对应章节的章节内容:
- (章节内容)
首先:编写爬虫文件:(注意:1.这就需要我们再定义一个rules规则,进行书籍具体章节内容的URL的获取以及对应响应数据的解析!2.编写相应的回调函数,进行书籍具体章节内容的获取!)
# -*- coding: utf-8 -*-
import datetimeimport scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Ruleclass Bh3Spider(CrawlSpider):name = 'zh'allowed_domains = ['book.zongheng.com']start_urls = ['https://book.zongheng.com/store/c0/c0/b0/u1/p1/v0/s1/t0/u0/i1/ALL.html']rules = (# Rule定义爬取规则: 1.提取url(LinkExtractor对象) 2.形成请求 3.响应的处理规则# 源码:Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True)# 1.LinkExractor是scrapy框架定义的一个类,它定义如何从每个已爬网页面中提取url链接,并将这些url作为新的请求发送给引擎# 引擎经过一系列操作后将response给到callback所指的回调函数。# allow=r'Items/'的意思是提取链接的正则表达式 【相当于findall(r'Items/',response.text)】# 2.callback='parse_item'是指定回调函数。# 3.follow=True的作用:LinkExtractor提取到的url所生成的response在给callback的同时,还要交给rules匹配所有的Rule规则(有几条遵循几条)# 拿到了书籍的url 回调函数 process_links用于处理LinkExtractor匹配到的链接的回调函数# 匹配每个书籍的urlRule(LinkExtractor(allow=r'https://book.zongheng.com/book/\d+.html',restrict_xpaths=("//div[@class='bookname']")), callback='parse_book', follow=True,process_links="process_booklink"),# 匹配章节目录的urlRule(LinkExtractor(allow=r'https://book.zongheng.com/showchapter/\d+.html',restrict_xpaths=('//div[@class="fr link-group"]')), callback='parse_catalog', follow=True),# 章节目录的url生成的response,再来进行具体章节内容的url的匹配 之后此url会形成response,交给callback函数Rule(LinkExtractor(allow=r'https://book.zongheng.com/chapter/\d+/\d+.html',restrict_xpaths=('//ul[@class="chapter-list clearfix"]')), callback='get_content',follow=False, process_links="process_chapterlink"),# restrict_xpaths是LinkExtractor里的一个参数。作用:过滤(对前面allow匹配到的url进行区域限制),只允许此参数匹配的allow允许的url通过此规则!!!)def process_booklink(self, links):for index, link in enumerate(links):# 限制一本书if index == 0:print("限制一本书:", link.url)yield linkelse:returndef process_chapterlink(self, links):for index,link in enumerate(links):#限制21章内容if index<=20:print("限制20章内容:",link.url)yield linkelse:returndef parse_book(self, response):print("解析book_url")# 字数:book_nums = response.xpath('//div[@class="nums"]/span/i/text()').extract()[0]# 书名:book_name = response.xpath('//div[@class="book-name"]/text()').extract()[0].strip()category = response.xpath('//div[@class="book-label"]/a/text()').extract()[1]author = response.xpath('//div[@class="au-name"]/a/text()').extract()[0]status = response.xpath('//div[@class="book-label"]/a/text()').extract()[0]description = "".join(response.xpath('//div[@class="book-dec Jbook-dec hide"]/p/text()').extract())c_time = datetime.datetime.now()book_url = response.urlcatalog_url = response.css("a").re("https://book.zongheng.com/showchapter/\d+.html")[0]print(book_nums, book_name, category, author, status, description, c_time, book_url, catalog_url)def parse_catalog(self, response):print("解析章节目录", response.url) # response.url就是数据的来源的url# 注意:章节和章节的url要一一对应a_tags = response.xpath('//ul[@class="chapter-list clearfix"]/li/a')chapter_list = []for index, a in enumerate(a_tags):title = a.xpath("./text()").extract()[0]chapter_url = a.xpath("./@href").extract()[0]ordernum = index + 1c_time = datetime.datetime.now()catalog_url = response.urlchapter_list.append([title, ordernum, c_time, chapter_url, catalog_url])print('章节目录:', chapter_list)def get_content(self, response):content = "".join(response.xpath('//div[@class="content"]/p/text()').extract())chapter_url = response.urlprint('章节具体内容:',content)
然后:运行会发现数据获取正常!

在上面,我们实现了所有目标数据的获取,不过为了防封,所以限制为只获取第一本小说的信息!!!
需要注意的是:LinkExtractor中的restrict_xpaths参数,它的作用是:过滤(对前面allow匹配到的url进行区域限制),只允许此参数限制区域内的通过allow匹配的url通过!!!可以防止多个Rule规则都匹配到同一个URL,导致数据重复!!!