😄 无聊学学罢了,非常简单的一个模型吧,算是一个比较经典的模型。ELMO更多的像是一个承上启下的角色,对于我们去了解那些词向量模型的思想也是很有帮助的。但由于同期的BERT等模型过于耀眼,使得大家并不太了解ELMO。
🚀 发表自NAACL-2018,当年的best paper。
🚀 论文链接:https://arxiv.org/pdf/1802.05365.pdf

🚀 导航
| ID | 内容 |
|---|---|
| NO.1 | 1、ELMO解决两个问题 |
| NO.2 | 2、何为前向语言模型? |
| NO.3 | 3、何为后向语言模型? |
| NO.4 | 4、双向语言模型 |
| NO.5 | 5、ELMO模型 |
| NO.6 | 6、如何预训练ELMO? |
| NO.7 | 7、如何冻结 or 微调 ELMO? |
| NO.8 | 8、高频面试题 |
1、ELMO解决两个问题:
1、复杂的语法和语义特征。
2、解决一词多义的问题 (随上下文而动态改变),不像word2vec那样,训练完就不变了,相同的词同样的输出。
ELMO全称为Embeddings from Language Models。即ELMO通过训练语言模型得到,且ELMO是一个双向语言模型 (前向+后向)。
2、何为前向语言模型?

3、何为后向语言模型?

4、双向语言模型

5、ELMO模型
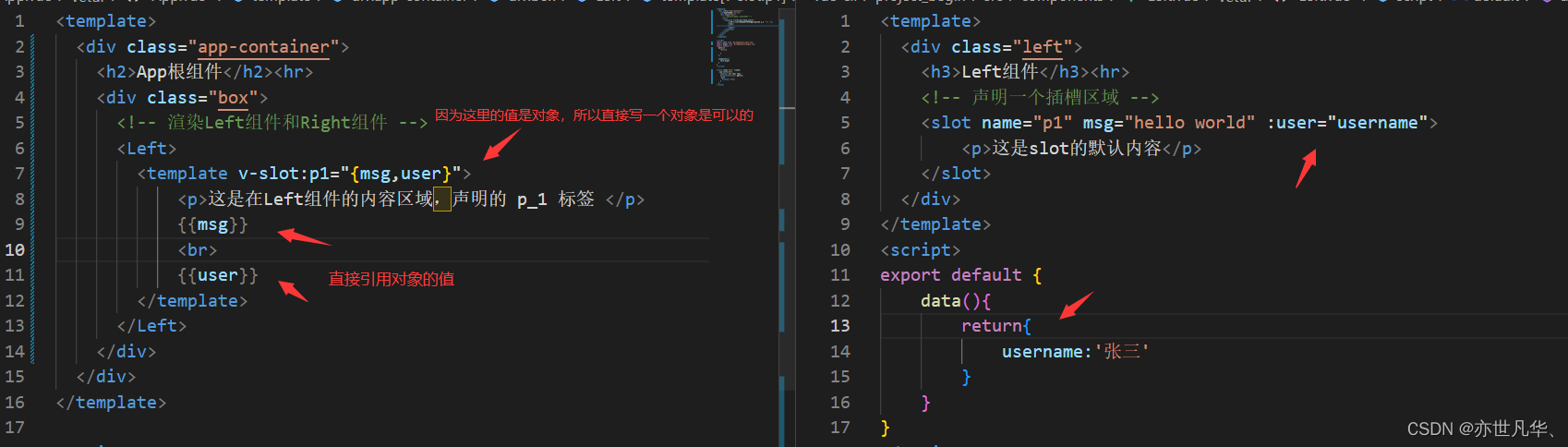
ELMO模型说白了就是两个 两层的LSTM构成。

ELMO模型=前向语言模型+后向语言模型,上图左边是左到右的前向LSTM,右边是右到左的后向LSTM。前向LSTM和后向LSTM由两层LSTM堆叠而成。之前的双向语言模型仅使用最后一层LSTM的输出作为softmax层的输入,而ELMO引入了一个线性组合函数把所有层的输出结果汇总起来,作为softmax层的输入。

6、如何预训练ELMO?
⭐ELMO将输出的向量映射到 vocab_size的长度,经过softmax后,取出概率最大的元素对应的下标,作为对下一个字的预测。相当于做一个分类,类别数量是词表大小,即自回归。
ELMO的输入输出例子:


7、如何冻结 or 微调 ELMO?


8、高频面试题
ELMO使用两层LSTM的意义?
答:
-
ELMo堆叠了两层LSTM,每层提取到的语言特征是不一样的。
-
论文分别用各层的输出做语义消歧和词性标注任务,发现用第二层的输出做语义消歧效果好于用第一层的输出;相反,做词性标注时则用第一层输出比较好。从而验证低层能建模词性等语法特征,高层能进一步建模语义特征。
-
虽然每层提取的特征侧重不同,但是实际应用时,不管什么任务,用的都是所有的特征,只是权重分配不同。
ELMO的优缺点?
答:
优点:
- 1、单词的嵌入取决于上下文,解决了一词多义问题。
- 2、将各层的输出进行线性组合,得到的词表示融合了语法和语义信息。
- 3、输入可以基于词也可以基于字符,可适应不同NLP任务。
- 4、无OOV问题,因为embedding是基于char-level的。
缺点:
- 1、特征提取用的LSTM模型,一方面不能并行,另一方面不好捕捉长距离依赖,所以elmo一般在短文本任务上表现好。
- 2、难以学到更深层次的语义,因为当LSTM的层数超过了3层,层与层之间的梯度消失情况会变得非常明显,网络训练更新迭代缓慢,收敛效果与计算效率急剧下降,甚至进入局部最小的情况。
ELMO的embedding层?
ELMO是通过字符卷积来得到embedding的,即通过卷积(不同卷积核)来获取char之间的类似n-gram的特征。n个卷积核,就有n个输出,n个输出拼接聚合得到单词的embedding。即完成char到word的转变。

为什么ELMO用两个单向的LSTM代替一个双向的LSTM呢?
吐槽一下把,网上大多数博客互相抄来抄去,以为自己解释对了,实则连Bi-LSTM都不懂。
这个提问本来就是错的:为什么ELMO用两个单向的LSTM代替一个双向的LSTM呢?。因为ELMO就是用双向LSTM。
答:平时用的BLSTM是将前向输出和后向输出词向量对应进行拼接,拼接后的词向量纬度扩展为原来的两倍,如果用拼接后的词向量来计算最大似然会出现自己看到自己的情况,因此不拼接词前后向向量,而是将他们的最大对数似然进行相加,联合前向和后向来计算最大似然。