
本文整理自戴玉超教授在第二届SLAM技术论坛中的报告:《基于深度学习的多视图几何:从监督学习到无监督学习》,共5700余字。
几何视觉利用相机获取的多视角图像重建所观测场景的三维几何结构,在SLAM、无人系统、自动驾驶、机器人、虚拟现实/增强现实和场景分析等方面有重要应用。深度学习特别是深度卷积网络在特征学习与语义信息提取上有巨大优势,如何将数据驱动模型与多视角几何模型相结合成为研究热点。本报告涵盖本领域特别是报告人的一系列最新工作,包括如何在监督学习框架下实现单目深度估计、双目深度估计,如何构建无监督学习框架以实现连续视频帧双目深度估计、具有几何约束的单目光流估计、多目深度估计和双目-激光雷达数据的有效融合等。最后对于本领域的进一步发展进行讨论。
报告首先简单介绍了SLAM的相关技术背景;其次从传统的多视角几何角度介绍了团队在刚性场景、非刚性物体和复杂非刚性场景上所做的工作;继而从监督学习和无监督/自监督学习两个方面介绍了团队在基于深度学习的多视角几何方面开展的工作。在这两个方向上,团队面临的核心问题就是深度估计问题。
针对这个问题,团队围绕不同的传感器设置下开展了不同的研究工作。包括如何通过一张图像去估计场景深度?如何基于两张图像进行自监督双目深度估计?在单目和双目深度估计的基础,如何扩展到多目设置?在这个基础上团队又进一步探讨了面向无人机、无人车上多传感器的融合问题,比如双目和激光雷达的融合;除了研究传感器在空间上的融合问题之外,报告最后也探讨了基于时间维度层面的扩展,比如团队在基于视频连续帧的光流估计上的一些工作。
01 无人系统视觉感知
团队研究的主要背景就是无人系统视觉感知。众所周知,在我们日常生活中,包括无人机、无人车、室内机器人等智能化产品越来越多,它们跟人类发生交互,例如虚拟现实/增强现实,人机交互等应用,都要求无人系统平台自身具有很好的视觉感知能力。从SLAM角度来讲,也就是需要准确的定位与建图。

各种不同类型的无人系统应用在以上背景下团队开展了一系列的工作,团队研究的工具和方法主要有两个:一是从多视角几何理论出发,利用数学理论模型来研究其中的一些关键问题;二是结合机器学习特别是深度学习,这也是团队应用到的主要工具。视觉感知的需求已经深入到生活中的很多方面。在这个背景之下,团队的研究目的是如何基于二维图像,来估计所观测场景的三维结构以及相机姿态。以无人驾驶为例,对于理解三维场景或动态场景,有以下几个因素需要考虑:
1) 所观测场景在每个时刻的三维状态;
2) 整个场景的语义信息,场景中各个物体的语义含义;
3) 在动态感知层面,除了物体每时每刻的三维结构(包括语义结构)之外,物体的运动信息也至关重要。因为只有准确地对物体运动进行建模之后,我们才能进行下一步的运动预测。因此我们需要从三维结构、物体运动、语义这三个层面实现对整个场景的透彻感知,对所有信息进行全面理解。
02 基于传统优化的多视角几何
1、刚性场景的多视角三维重建
刚性场景是指场景无论从什么角度去看,都能够保持一定的不变性。针对刚性场景的多视角三维重建,团队主要在以下两个方面开展工作:
(1)刚性三维重建问题的最优性和求解效率;
(2)如何统一处理不同大视角相机;结合已经进行的一些工作,针对这两个问题,给出相应的解决方法。对于第一个问题,团队的一些早期工作主要是利用凸优化方法,解决方法的创新性在于可以在全局优化框架下同时求解场景三维结构、相机运动和深度,在此基础上进一步提出可以进行大规模优化的交替方法以应对现实应用中的规模性问题;对于第二个问题,团队将具有全局优化意义的重建方法拓展到不同的相机类型,在径向对称相机模型下进行统一表达,此方法可以适用于全景、鱼眼、透射折射等多种不同的相机模型。
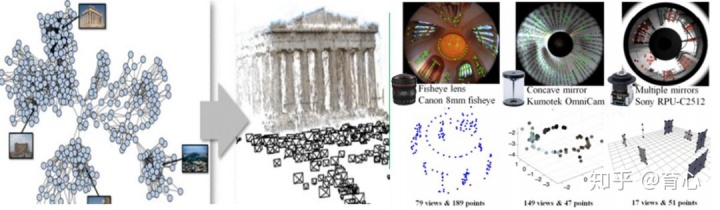
刚性场景的多视角三维重建2、非刚性场景的多视角三维重建刚性场景可以通过多视图几何进行求解(特征点提取及匹配问题解决之后,整个问题就比较容易解决)。但是对于我们所关注的问题,比如我们所处的三维动态世界,它往往是一个非刚性场景(Non-Rigid或Deformable,即动态变化的场景)。这里的主要问题来源于非刚性重建问题本质的欠定性和多解性,即如何获得最佳的重建和如何不受各种不同先验的有偏影响。针对这个问题,团队提出的方法利用问题本质的约束,无需任何先验信息的非刚性重建,主要包含以下两个创新点:
1)无需先验的非刚性三维重建;
2)矩阵秩最优化模型。该方法可以以单目相机从人脸或人体动作上获取相对稀疏的关键点,进一步提升到三维空间。
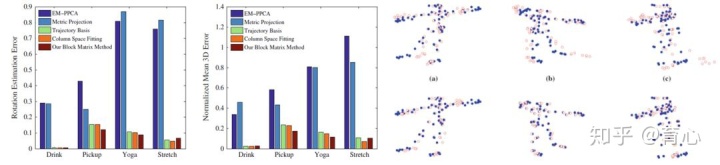
非刚性场景的多视角三维重建但是由于该方法只能用于小规模的数据,团队在之后将该工作进一步拓展到稠密重建上。团队从时间和空间两个维度同时观察和描述我们所观察的非刚性的场景或者物体。从时间上来讲,人们所做的一些动作或者表情,都会有一些重复性。如果把一些高度相似的东西放在一起,就可以用一些简单的模型来表达。这样的话,即使整个序列上的模型是复杂的,但是重组之后就可以通过多个简单模型进行表达。同样空间上也是这样,人们的很多动作或者表达在相邻像素上是高度相关的,因此可以在空间进行表达。这样可以从时间和空间两个维度上施加Grassman 流形约束,最终把时间和空间两个维度加一起。与其它方法相比,团队提出的方法在标准测试数据集上取得了最好的结果。
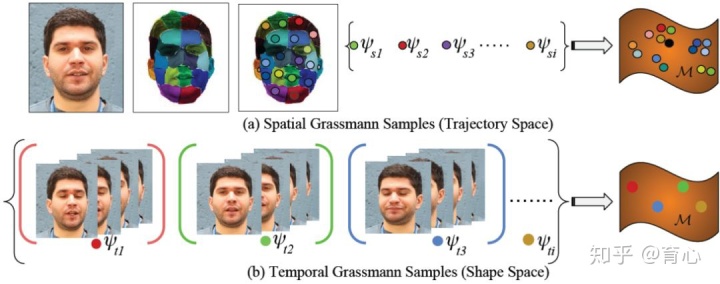

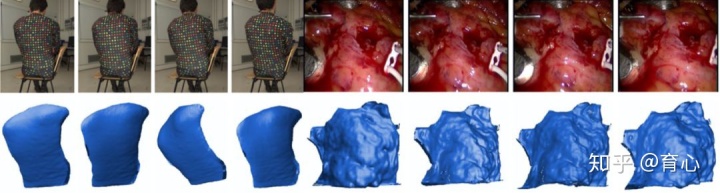
3、动态场景重建:从单个物体到整个场景
以上我们讨论的是围绕单个非刚性物体的三维重建。实际中三维场景更加复杂,可能包含刚性的背景、刚性运动物体以及非刚性物体等。它的结构又是特别复杂的,主要难点集中在以下三个方面:
(1)无处不在的单目相机系统对于单目场景重建提出迫切需求;
(2)现实世界场景更加复杂并且不仅包含刚性物体,也包含非刚性物体;
(3)需要统一的单目三维重建框架以有效应对多种不同的复杂动态场景。
在实际工作中,为了广泛统一地描述这种场景,团队提出在以下假设的基础上统一表达不同动态场景:
(1)两帧之间的变形满足局部逐块刚性,在全局上尽量刚性(As-Rigid-As-Possible)。
(2)待重建的三维场景是逐块平滑的。给定以上假设,团队提出通过求解未知的相对尺度以获得复杂动态场景全局兼容的稠密三维重建方法。

从两帧图像重建复杂非刚性场景从不具有尺度的超像素三维结构到三维曲面的重建的过程表达为求解三维超像素拼图问题。

03 基于深度学习的多视角几何
现在我们讨论SLAM中一个核心问题,即深度估计。深度估计大家很容易理解,即需要从一张图片或者多张图片中估计出每个像素对应的深度,从机器学习的角度来讲这是一个稠密标注问题。例如这里输入一张图片,我们搭建一个网络。现在的方法就可以分为两类:一种是有监督的学习方法,我们有真值监督这个过程;第二种则是无监督或自监督的学习方法,这种设置下没有深度真值作为监督,但是可能有额外的数据。
1、单目深度估计
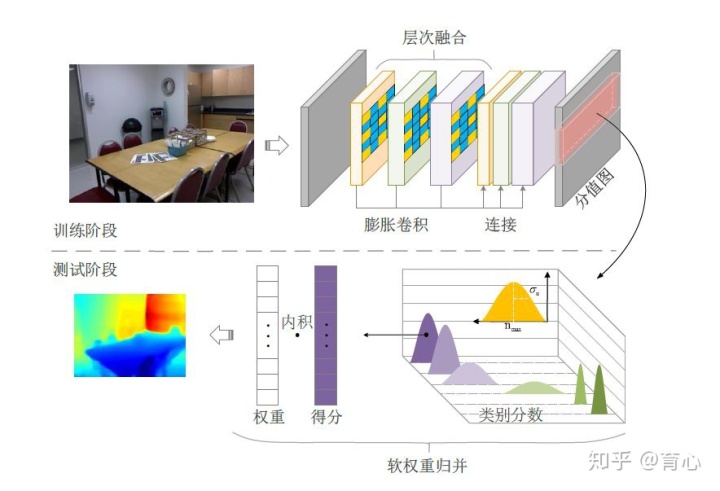
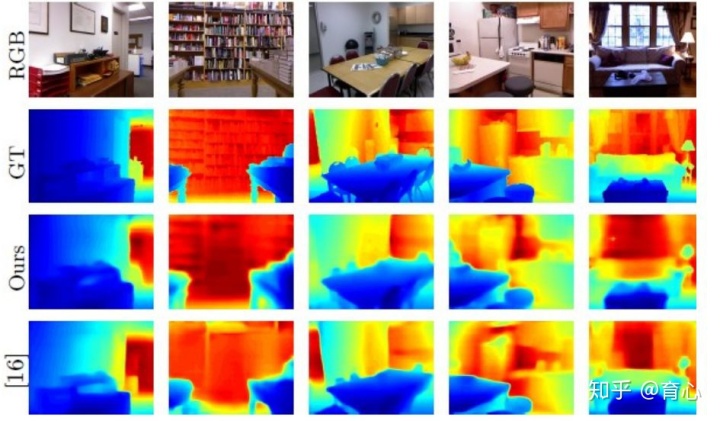
单目深度估计更直接一点。一些比较早期的方法是做监督方法上的结果,当时的特点并不是直接设计端到端的网络,而是把图像分成小块,然后在每个块上面进行回归。这种方法的好处是所依赖的数据集比较少,因为只需要用到图像块和对应深度值之间的回归关系。这种方法在当时取得了很不错的深度估计结果,最近我们在这一问题上进一步扩充,通过全卷积网络把它变成一个分类任务,从而进一步提升深度预测性能。除此之外还能做进一步的工作,比如引用残差网络包括卷积,将结果进一步提升。下图为使用监督学习方法在NYU在室内数据集上的测试结果,其中输入为单张图像,监督信号为深度图,测试时通过给出的RGB图像预测出深度图。
除了有监督的学习方法以外,有一些工作关注无监督或自监督的学习方法。无监督或自监督的学习方法并非不包含任何监督信息,监督信息其实是包含在数据里的。以深度估计为例,我们可以利用更多信息来做自监督学习,比如双目图像信息或者连续视频帧信息。例如我们需要估计一张单目图像对应的深度,但是如果给的是双目图像,当单目估计好的时候,我们可以直接把左右图像进行相互映射。此时不需要另一幅图像的深度,它可以形成自监督,这是同时实现的。当然我们也可以做利用前后帧之间的关系进行时间上的自监督学习。
当前这张图片深度估计的好,相机估计的好,则可以预测下一帧,再根据预测出的下一帧图像去估计再往后的图像,这样就构成了一个循环。这就是自监督可以做的事情。这其中也存在一些其他的挑战,比如现实的场景里除了静态背景,还包含着动态物体,还存在一些严重的遮挡关系。最近的一些方法通过引入额外的数据集来进行处理:比如为了解决动态场景中人体深度估计问题,IEEE CVPR 2019的一篇论文通过构造一个人在做动作,但是多个相机在同时拍摄,这样就能够同时获取human in the motion的数据。另外的一些工作认为,对于单目深度估计,比如像KITTI这种数据仍然不够丰富,他们通过从立体电影中的真实数据集获取数据,来找到数据量更大的更广泛的数据集。
2、双目深度估计
双目深度估计是一个在视觉领域研究非常深入的问题,它是获取深度最直接的方式。有了深度学习之后,基于监督的深度学习方法已经取得了很好的效果并且占据了各种排行榜的前列。然而基于监督学习的双目深度估计仍存在几个问题:
(1)监督学习方法依赖大规模标注数据;
(2)模型推广性问题仍需要解决;
(3)其是否真正学会“立体匹配”。
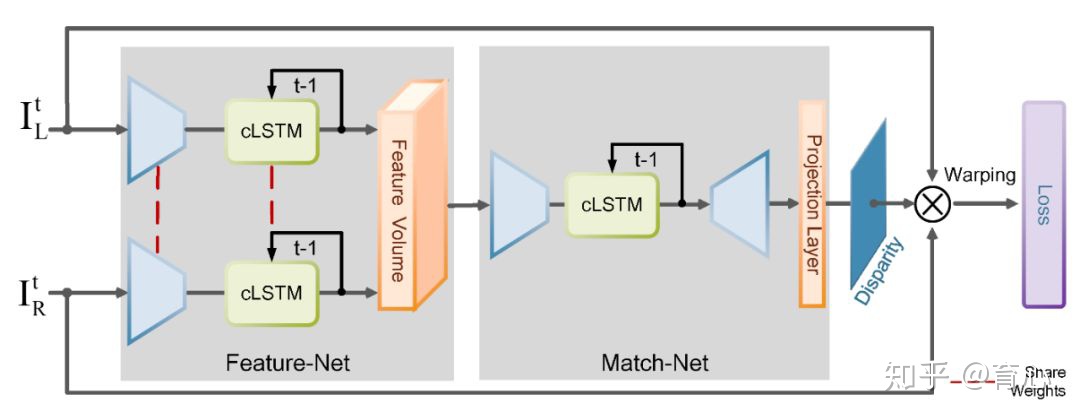
基于递归神经网络的视频双目立体匹配针对这些问题,团队提出了自监督深度双目立体匹配网络结构。此网络包含四个模块:特征提取、特征代价计算、三维特征匹配和图像误差计算。它具有如下三方面的优点:
(1)可以随时间动态演化;
(2)网络具有记忆单元,从而具有基于以往经历调整当前行为的能力;
(3)运行在线后向传播进行模型更新。

3、多目深度估计
团队最近在做的一个工作是进一步把双目深度估计拓展到多目深度估计。我们致力于获取一个非常稠密的深度图,在这方面团队基于自监督的学习方法,利用场景的对称性把双目的结果进一步拓展到多目。提出了第一个无监督多目深度估计的学习框架。其网络由五个模块构成,分别是特征提取、可微单应运算、代价立方体构建、空间传播网络和跨视角一致性损失。为增强多幅深度预测间的一致性,其构建了去中心化的网络,对于每一帧输入的多目图像,均使用网络进行预测。利用深度值与相机位姿,可计算出每对图像间的像素对应关系。利用这些对应关系,在图像空间与深度空间均进行对比,设计跨视角一致损失。促进同一场景下,多个视角观测保持一致。
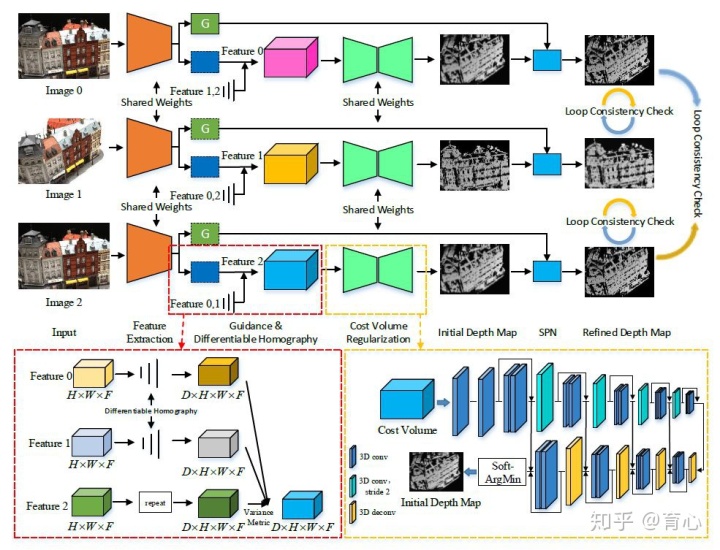
4、双目-LIDAR融合
激光雷达获取的深度图是非常准确的,但是比较稀疏。双目相机可以获得稠密的深度图,但是不确定性比较高,在弱纹理、重复结构和遮挡区域难以获得可靠的深度估计。一个自然的想法就是如何对这两种方法进行融合。对于激光雷达来说,大多数方法都会把它获取的数据当做一个比较好的结果。但是其面临的一个问题是,激光雷达对于动态物体的深度计算是不可靠的。除此之外,对于物体的边缘以及强反射的场景,激光雷达都会存在一些问题。
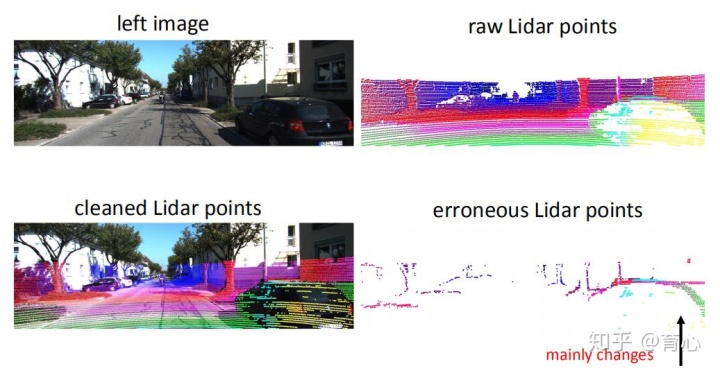
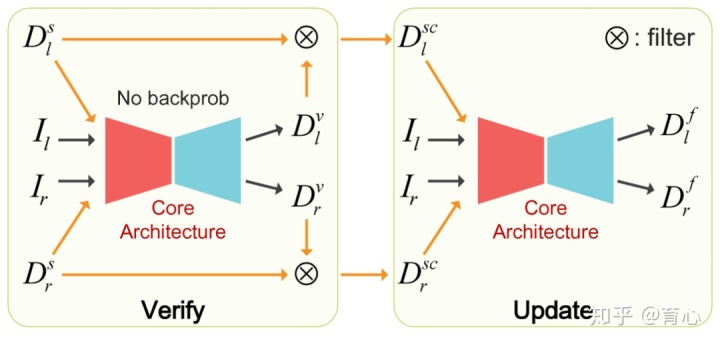
尽管激光雷达不是完美的,但是我们可以选出其中精度高的部分点,来监督双目立体网络如何进行匹配。在这部分所面对的问题是如何选取特征点,然后更新融合模型。团队提出两阶段的方法,第一阶段是做验证,通过比较确定哪些激光雷达点可靠,用它做融合网络,便于后续更新。这样把验证和更新两个阶段交替进行,从而进行有效融合的框架。这是一个无监督的网络,主要是通过两种数据的相互融合来实现的。团队也用了一些场景假设,实验证明我们的方法甚至比监督的方法结果好一些,同时每个像素都是有深度的。

5、光流估计
上面所讲的是从一个时刻通过不同传感器去做,再进一步可以拓展加入时序信息,这就是光流。光流的历史非常悠久,它在物体跟踪方面都有很重要的应用。团队现在研究一个重点是如何去处理其中的一些挑战性的问题,主要是通过在加入几何约束后,尤其是在某一个完全约定的场景,建立前后的约束,比如软约束或者硬约束来做。我们倾向于让它去满足模型。比如说一个几何约束只能解决一个rigid场景。当场景里包含多个运动物体的时候,可以引入low rank或子空间约束。再进一步假设场景里面有多个运动物体,每个运动物体可以通过自己的轨迹进行自表达,这样可以把每一个物体的运动分割出来,再嵌入进去,从而引入一项单独的约束。

极线流(Epipolar Flow)上图是来自KITTI的数据,里面有两个独立的车还有一些其它背景。经过处理我们不仅可以估计出光流,而且可以得到自表达的矩阵,也可以比较清晰的显示出运动分割的情形。
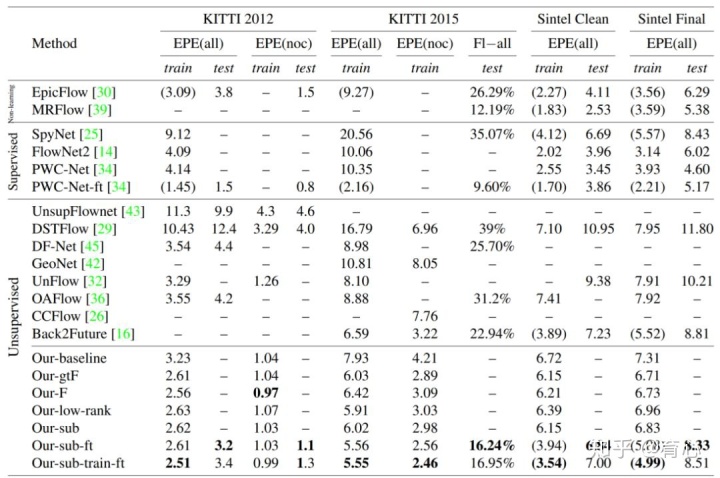


上文讲述了三大类方法,基于传统优化的多视角几何方法、基于监督学习的方法做多视角几何和基于无监督深度学习的方法。这三种方法谁也不能完全替代谁,每一种方法都有自己的优势和劣势。所以针对具体问题需要去选择最适合它的方法,这是一个简单总结。课题组近来围绕无人系统视觉感知中以下三个方面持续开展工作:
1)几何模型驱动方法与数据驱动方法的深度融合;
2)多源多传感器融合的几何视觉;
3)面向终端应用的几何视觉(机器人、无人机、SLAM、集群)。
相关文章[1] Liu Liu, Hongdong Li, Yuchao Dai. Stochastic Attraction and Repulsion Embedding for Image Based Localization. ICCV, 2019.[2] Xuelian Cheng, Yiran Zhong, Yuchao Dai, Hongdong Li. Noise-Aware Unsupervised Deep Lidar-Stereo Fusion. CVPR, 2019.[3] Yiran Zhong, Pan Ji, Jianyuan Wang, Yuchao Dai, Hongdong Li. Unsupervised Deep Epipolar Flow for Stationary or Dynamic Scenes. CVPR, 2019.[4] Yiran Zhong, Yuchao Dai, Hongdong Li. Stereo Computation for a Single Mixture Image. ECCV 2018.[5] Yiran Zhong, Hongdong Li, Yuchao Dai. Open-World Stereo Video Matching with Deep RNN. ECCV 2018.[6] Bo Li, Yuchao Dai, Mingyi He. Monocular Depth Estimation with Hierarchical Fusion of Dilated CNNs and Soft-Weighted-Sum Inference. Pattern Recognition, 2018.[7] Suryansh Kumar, Anoop Cherin, Yuchao Dai, Hongdong Li. Scalable Dense Non-rigid Structure-from-Motion: A Grassmannian Perspective, CVPR 2018.[8] Suryansh Kumar, Yuchao Dai and Hongdong Li. Monocular Dense 3D Reconstruction of a Complex Dynamic Scene from Two Perspective Frames. ICCV 2017.[9] Pan Ji, Hongdong Li, Yuchao Dai and Ian Reid. ``Maximizing Rigidity" Revisited: a Convex Programming Approach for Generic 3D Shape Reconstruction from Multiple Perspective Views. ICCV 2017.[10] Liu Liu, Hongdong Li and Yuchao Dai. Efficient Global 2D-3D Matching for Camera Localization in a Large-Scale 3D Map. ICCV 2017.[11] Bo Li, Chunhua Shen, Yuchao Dai, Anton van den Hengel, Mingyi He; Depth and Surface Normal Estimation from Monocular Images Using Regression on Deep Features and Hierarchical CRFs. CVPR 2015.[12] Jae-Hak Kim*, Yuchao Dai*, Hongdong Li, Xin Du, Jonghyuk Kim: Multi-view 3D Reconstruction from Uncalibrated Radially-Symmetric Cameras. ICCV 2013.[13] Yuchao Dai, Hongdong Li, Mingyi He. A simple prior-free method for non-rigid structure-from-motion factorization. CVPR 2012.
深蓝学院(https://www.shenlanxueyuan.com/)是专注于人工智能的在线教育平台,致力于构建前沿科技课程培养体系的业界标准,涵盖人工智能基础、机器学习、计算机视觉、自然语言处理、智能机器人等领域。



