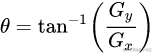主要函数:
1.corpusprocess原始语料处理函数
2.train_word2vec生成word2vec向量
3.generate_id2wec获得索引的w2id,和嵌入权重embedding_weights
4.prepare_data 数据预处理
完整代码下载地址:python本科毕业设计基于神经网络的虚假评论识别系统源码
代码流程:
训练过程:
1.train_word2vec生成word2vec词向量模型,train_word2vec中会调用corpusprocess(对中文文本进行预处理和切词操作)
2.generate_id2wec会根据此向量模型,生成w2id,和嵌入权重embedding_weights
3.prepare_data根据w2id,划分训练集x_train, y_trian和验证集 x_val , y_val
4.w2id和embedding_weights根据定义LSTM模型Senti
5.调用train()方法训练,保存算法模型。
预测过程:
1.加载已经生成word2vec模型
2.generate_id2wec会根据此向量模型,生成w2id,和嵌入权重embedding_weights
3.定义 Sentiment,设置参数
4.加载训练好的LSTM模型
5.调用predict方法预测结果
基于神经网络的虚假评论识别系统
备注:
数据处理时,应该以utf-8编码,不然读出来的数据较乱,修改数据形式,读取Excel文件,以utf-8编码
打乱数据集使得最后的结果更加合理
添加测试集验证模型
测试集:训练集=2:8
在训练集的过程中添加验证集,比例为1:9
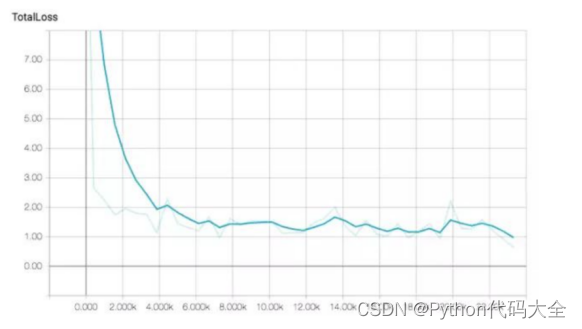
最后的下面如下图所示。
数据比例:

模型结构:
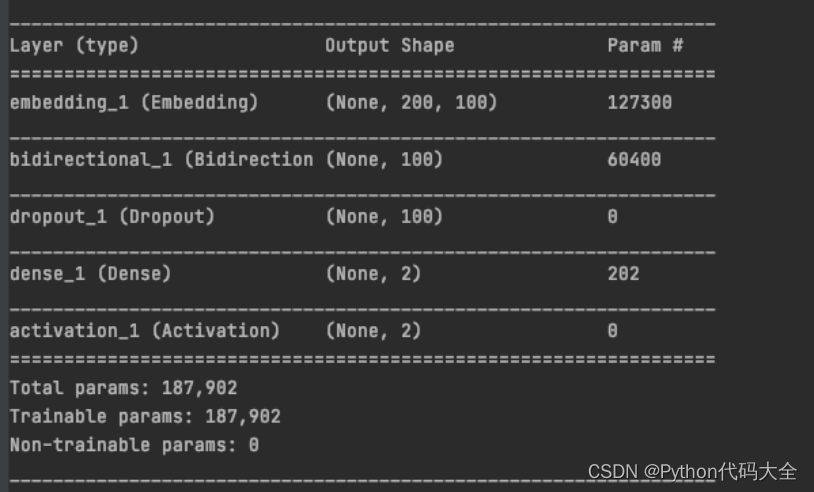
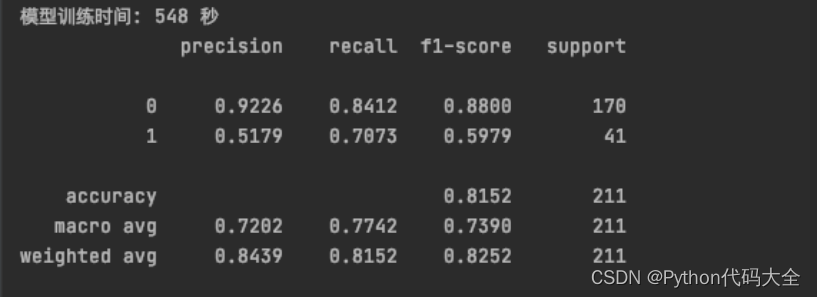
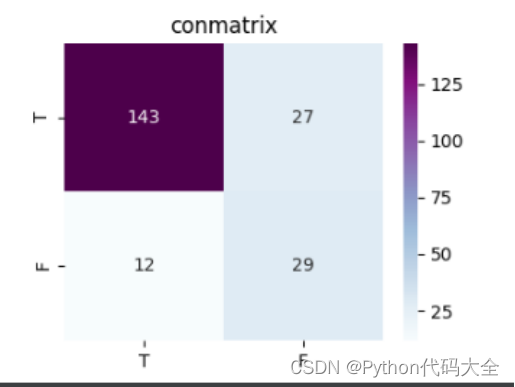
模型指标:
建议:
词向量的维度太大,句子太短,导致句子向量比较稀疏,可以修改句子维度大小;
同时可以修改代码生成训练过程中的acc和loss折线图,类似下面的loss图(80块钱优化上述建议代码)