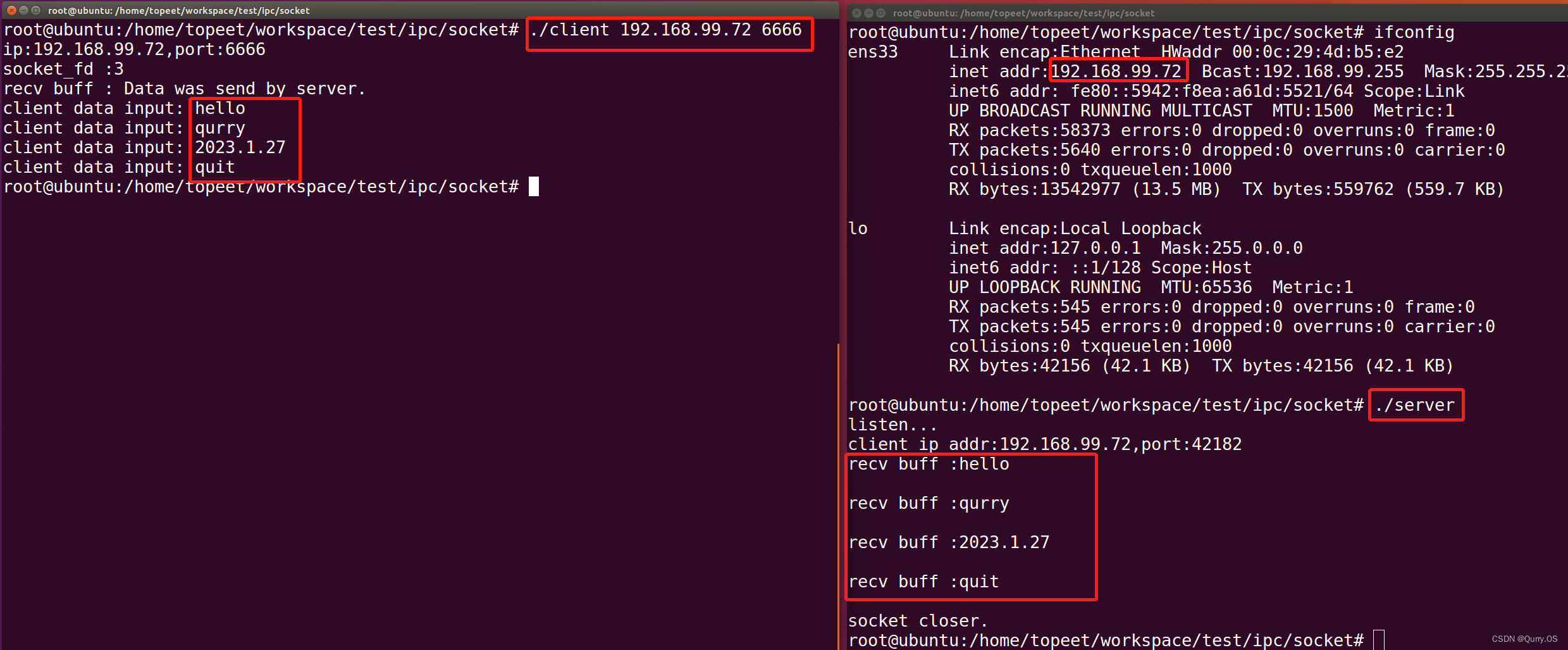
问题描述
小蓝老师教的编程课有 N 名学生, 编号依次是 1…N 。第 i 号学生这学期刷题的数量是 Ai 。
对于每一名学生, 请你计算他至少还要再刷多少道题, 才能使得全班刷题比他多的学生数不超过刷题比他少的学生数。
输入格式
第一行包含一个正整数 N 。
第二行包含 N 个整数:A1,A2,A3,…,AN.
输出格式
输出 N 个整数, 依次表示第 1…N 号学生分别至少还要再刷多少道题。
样例输入
5 12 10 15 20 6样例输出
0 3 0 0 7评测用例规模与约定
对于 30% 的数据,1≤N≤1000,0≤Ai≤1000.
对于 100% 的数据, 1≤N≤100000,0≤Ai≤100000.
题目大意
给出一个序列表示每个人目前的刷题数,计算每个人最少再刷多少题,可使得刷题数比他多的人数不超过刷题数比他少的人数。
解题关键:
给出一个数字,计算出序列中比它大的数字个数和比它小的数字个数
解题思路一:二分 算法复杂度:
- 给定一个数字,可以通过二分查找的方式确定它在一个有序序列中所处的下标,根据下标位置,可以确定大于它的数字数和小于它的数字数,从而完成“多刷题人数”和“少刷题人数”的确定,假设用more和fewer来表示。
- 小的刷题数对应较大的more和较小的fewer,大的刷题数对应较小的more和较大的fewer,因此根据这样的有序性,我们可以对每个同学的刷题数使用二分算法,找出使more<=fewer的最小值。
- check()函数设置为检查more<=fewer,满足返回True,否则返回False。复杂度为O(logn)
参考代码1:通过70%数据测试
import bisect
n = int(input())
a = list(map(int, input().split()))
sa = sorted(a) #获取一份和a相同的,但经过排序的列表# #判断刷题数为cur时,刷题数比他多的人数是否不超过比他小的人数
def check(cur, raw): few = bisect.bisect_left(sa, cur) #使用二分的方式,通过查找元素位置,计算数目 fewer = few if cur == raw else few - 1 #当cur的值相较原本已经增加,这时判断少刷题人数要扣掉自己more = len(sa) - bisect.bisect_right(sa, cur) #计算多刷题的人数if more <= fewer: #判断情况return Trueelse:return Falsemax_num = sa[-1] #获取所有人中刷题最多的题数,作为二分的右边界
res = [] #记录每人为实现目标要多刷的题数
for i in range(n):l, r = a[i] - 1, max_num + 1 #l,r是新的刷题数,标定左右边界while l + 1 != r: #二分算法mid = l + r >> 1if not check(mid, a[i]): #刷题数不达标,说明当前题数还较少,压缩左边界l = midelse:r = mid #否则压缩右边界res.append(r - a[i]) #最终符合要求的结果在r所指范围中,用r减去a[i]即可得到需要多刷的题数
print(*res)优化一:对check()优化:前缀和
使用前缀和,避免重复计算 算法复杂度:O(nlogn)
示例:5个学生,刷题数分别是12,10,8,15,6
1、建一个列表cnt统计每个刷题数对应的学生数
2、计算该列表的前缀和列表scnt,特别赋值scnt[0]=cnt[0],因为本题Ai是从0开始的,但其实前缀和的0一般不用,是从1开始的。
计算前缀和: 或者
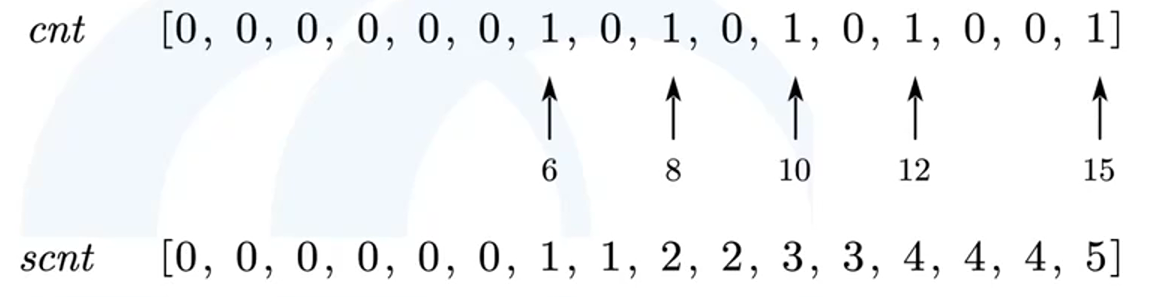
例如:刷题数为10的人,比他多的人more可以用scnt[M] - scnt[cur]=5-3=2,比他少的人fewer可以用前一个前缀和scnt[cur-1] = scnt[cur] - cnt[cur]=3-1=2,如果是通过再刷题达到的刷题数cur,那么fewer需要再-1,减掉一个再刷题前的自己。(因为需要再刷题说明肯定比之前刷题数多)
参考代码2:通过100%数据测试
n = int(input())
a = list(map(int, input().split()))
N = 100010 # 稍微比范围大一点
cnt = [0] * N; scnt = [0] * N # 最后多的0没有影响
for i in range(n):cnt[a[i]] += 1 # 统计刷题数为ai的人数scnt[0] = cnt[0] # 特别赋值
for i in range(1, N):scnt[i] = scnt[i - 1] + cnt[i] # 刷题数i的前缀和def check(x, old):more = scnt[N - 1] - scnt[x] # more:所有人数 - 刷题数x的前缀和fewer = scnt[x] - cnt[x] # fewer:刷题数x的前缀和 - 刷题数x的人数if x != old: # 需要达到刷题数和原来刷题数不一样fewer -= 1 # 减掉一个原来的自己if more <= fewer:return Trueelse:return Falseres = [] # 记录每人为实现目标要多刷的题数
for i in range(n):l, r = a[i] - 1, 100001while l + 1 != r:mid = l + r >> 1 # 右移1等价于//2if check(mid, a[i]):r = midelse:l = midres.append(r - a[i]) # 需要多刷的题数 = 最少需要达到的刷题数r - 原来刷题数a[i]
print(*res) # 加个*,可以打印出列表的每个元素,用空格隔开优化二:前缀和+一次二分找中间数
通过前面的做法,我们发现,对于需要多刷题的人,他们最后都会刷到同一个题目数。例如样例中他们最后都会刷到同一个题目数13.
因此,我们选出一个最小的当前刷题数,用一次二分查找即可确定将要刷到的题数,记为pos
之后遍历a中所有数字,check()不需要再二分查找pos,如果满足check(),就说明新刷题数是0,否则新刷题数是pos - a[i]
算法复杂度:O(n)
参考代码3:通过100%数据测试
n = int(input())
a = list(map(int, input().split()))
t = min(a) # 选出刷题数最少的,后面进行一次二分查找
N = 100010
cnt = [0] * N; scnt = [0] * N
for i in range(n):cnt[a[i]] += 1scnt[0] = cnt[0]
for i in range(1, N):scnt[i] = scnt[i - 1] + cnt[i]def check(x, old):more = scnt[N - 1] - scnt[x]fewer = scnt[x] - cnt[x]if x != old:fewer -= 1if more <= fewer:return Trueelse:return False# 没有for循环,只需要做一次二分
l, r = t - 1, 100001
while l + 1 != r:mid = l + r >> 1if check(mid, t):r = midelse:l = mid
pos = r # 最少需要达到的刷题数pos
res = []
for i in range(n): if check(a[i], a[i]): # 已经满足more <= fewerres.append(0) # 不需要刷题else: # 不满足more <= fewerres.append(pos - a[i]) # 需要多刷的题数 = 最少需要达到的刷题数 - 原来刷题数
print(*res)