GPU-CUDA-图形渲染分析
参考文献链接
https://mp.weixin.qq.com/s/dnoqPxEt_XEhVaW_aAfrnQ
https://mp.weixin.qq.com/s/1NumM2PRTqW-HIfQRlUu8A
https://mp.weixin.qq.com/s/d8Dq0YmjHpsoCchy8y4B2g
https://mp.weixin.qq.com/s/5JorA1BJXgeftzrqItJV9g
https://mp.weixin.qq.com/s/bw7GQDJhirVoddiBeErSlA
https://mp.weixin.qq.com/s/-7GxiG_roieUNSMy_G02Vw
https://mp.weixin.qq.com/s/unZFf7gss1p05z_baoJeEA
GPU技术关键参数和应用场景
随着云计算,大数据和人工智能技术发展,边缘计算发挥着越来越重要的作用,补充数据中心算力需求。计算架构要求多样化,需要不同的CPU架构来满足不断增长的算力需求,同时需要GPU,NPU和FPGA等技术加速特定领域的算法和专用计算。以此,不同CPU架构,不同加速技术应用而生。
理解 GPU 和 CPU 之间区别的一种简单方式是比较如何处理任务。CPU 由专为顺序串行处理而优化的几个核心组成,而 GPU 则拥有一个由数以千计的更小、更高效的核心(专为同时处理多重任务而设计)组成的大规模并行计算架构。
CPU是一个有多种功能的优秀领导者。优点在于调度、管理、协调能力强,计算能力则位于其次。而GPU相当于一个接受CPU调度的“拥有大量计算能力”的员工。
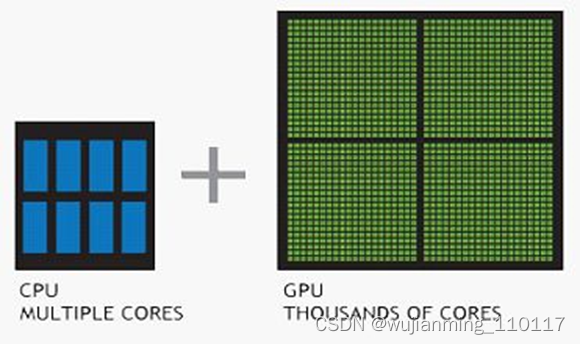
GPU可以利用多个CUDA核心来做并行计算,而CPU只能按照顺序进行串行计算,同样运行3000次的简单运算,CPU需要3000个时钟周期,而配有3000个CUDA核心的GPU运行只需要1个时钟周期。
简而言之,CPU擅长统领全局等复杂操作,GPU擅长对大数据进行简单重复操作。CPU是从事复杂脑力劳动的教援,而GPU是进行大量并行计算的体力劳动者。那么,GPU的重要参数有哪些呢?
• CUDA核心;CUDA核心数量决定了GPU并行处理的能力,在深度学习、机器学习等并行计算类业务下,CUDA核心多意味着性能好一些
• 显存容量:其主要功能就是暂时储存GPU要处理的数据和处理完毕的数据。显存容量大小决定了GPU能够加载的数据量大小。(在显存已经可以满足客户业务的情况下,提升显存不会对业务性能带来大的提升。在深度学习、机器学习的训练场景,显存的大小决定了一次能够加载训练数据的量,在大规模训练时,显存会显得比较重要。
• 显存位宽:显存在一个时钟周期内所能传送数据的位数,位数越大则瞬间所能传输的数据量越大,这是显存的重要参数之一。
• 显存频率:一定程度上反应着该显存的速度,以MHz(兆赫兹)为单位,显存频率随着显存的类型、性能的不同而不同。显存频率和位宽决定显存带宽。
• 显存带宽:指显示芯片与显存之间的数据传输速率,以字节/秒为单位。显存带宽是决定显卡性能和速度最重要的因素之一。
• 其他指标:除了显卡通用指标外,NVIDIA还有一些针对特定场景优化的指标,例如TsnsoCore、RTCoreRT等能力。例如TensenCore专门用于加速深度学习中的张量运算。
评估一个显卡的性能不能单纯看某一个指标的性能,而是结合显卡的个指标及客户业务需求的综合性能。
GPU是协处理器,与CPU端存储是分离的,故GPU运算时必须先将CPU端的代码和数据传输到GPU,GPU才能执行kernel函数。涉及CPU与GPU通信,其中通信接口PCIe的版本和性能会直接影响通信带宽。
GPU的另一个重要参数是浮点计算能力。浮点计数是利用浮动小数点的方式使用不同长度的二进制来表示一个数字,与之对应的是定点数。同样的长度下浮点数能表达的数字范围相比定点数更大,但浮点数并不能精确表达所有实数,而只能采用更加接近的不同精度来表达。
FP32单精度计算
单精度的浮点数中采用4个字节也就是32位二进制来表达一个数字,1位符号,8位指数,23位小数,有效位数为7位。
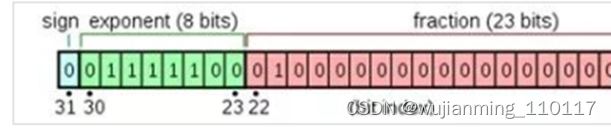
FP64双精度计算
双精度浮点数采用8个字节也就是64位二进制来表达一个数字,1位符号,11位指数,52位小数,有效位数为16位。

FP16半精度计算
半精度浮点数采用2个字节也就是16位二进制来表达一个数字, 1位符号、5位指数、10位小数,有效位数为3位。

因为采用不同位数的浮点数的表达精度不一样,所以造成的计算误差也不一样。
对于需要处理的数字范围大而且需要精确计算的科学计算来说,就要求采用双精度浮点数,例如:计算化学,分子建模,流体动力学。
对于常见的多媒体和图形处理计算、深度学习、人工智能等领域,32位的单精度浮点计算已经足够了。
对于要求精度更低的机器学习等一些应用来说,半精度16位浮点数就可以甚至8位浮点数就已经够用了。
对于浮点计算来说,CPU可以同时支持不同精度的浮点运算,但在GPU里针对单精度和双精度就需要各自独立的计算单元,一般在GPU里支持单精度运算的单精度ALU(算术逻辑单元)称之为FP32 core,而把用作双精度运算的双精度ALU称之为DP unit或者FP64 core,在Nvidia不同架构不同型号的GPU之间,这两者数量的比例差异很大。
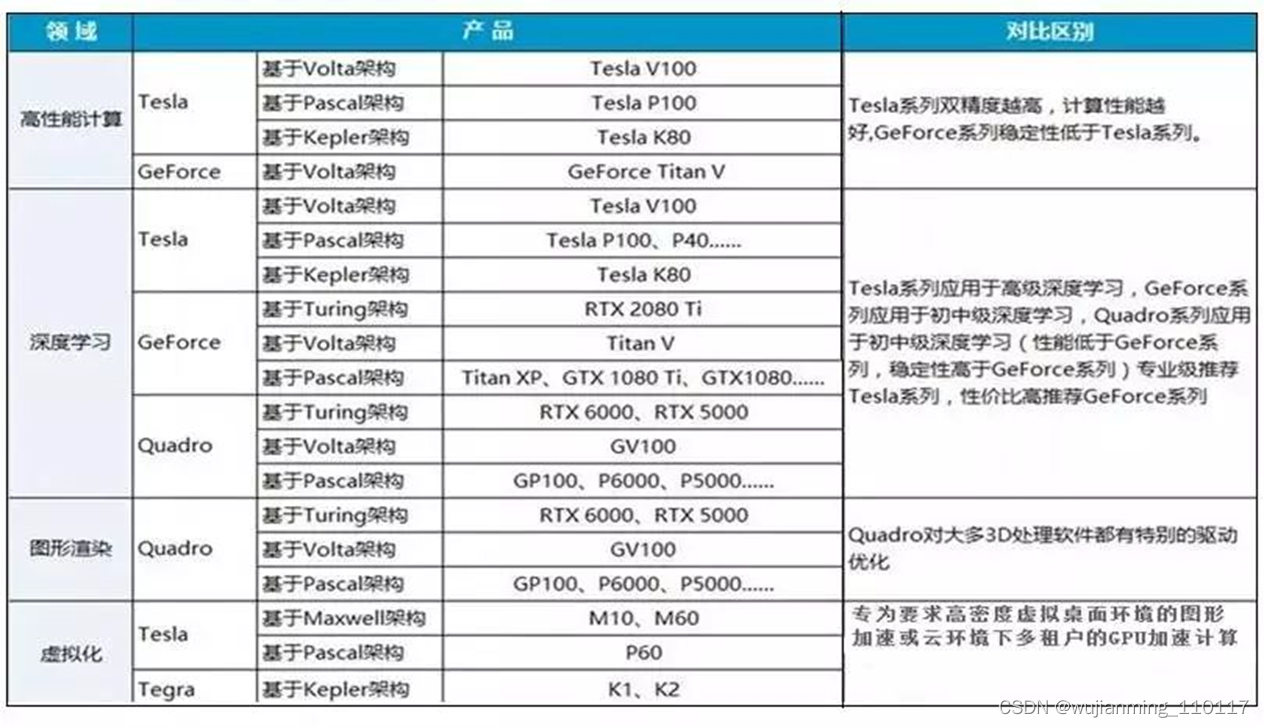
谈到GPU,Nvidia是行业技术的领先者和技术奠基者,其产品主要分以下几个系列,分别面向不同的应用类型和用户群体。
• GeForce系列:主要面向3D游戏应用的GeForce系列,几个高端型号分别是GTX1080TI、Titan XP和GTX1080,分别采用最新的Pascal架构和Maxwell架构;最新的型号RTX 2080TI,Turing架构。因为面向游戏玩家,对双精度计算能力没有需求,出货量也大,单价相比采用相同架构的Tesla系列产品要便宜很多,也经常被用于深度学习、人工智能、计算机视觉等。
• Quadro系列:主要面向专业图形工作站应用,具备强大的数据运算与图形、图像处理能力。因此常常被用在计算机辅助设计及制造CAD/CAM、动画设计、科学研究(城市规划、地理地质勘测、遥感等)、平面图像处理、模拟仿真等。
• GPU加速计算Tesla系列:专用GPU加速计算,Tesla本是第一代产品的架构名称,后来演变成了这个系列产品的名称了,包括V100、P100、K40/K80、M40/M60等几个型号。K系列更适合用作HPC科学计算,M系列则更适合机器学习用途。
Tesla系列高端型号GPU加速器能更快地处理要求超级严格的 HPC 与超大规模数据中心的工作负载。从能源探测到深度学习等应用场合,处理速度比使用传统 CPU 快了一个数量级。
• GPU虚拟化系列:Nvidia专门针对虚拟化环境应用设计GRID GPU产品,该产品采用基于 NVIDIA Kepler 架构的 GPU,首次实现了 GPU 的硬件虚拟化。这意味着,多名用户可以共享单一 GPU。
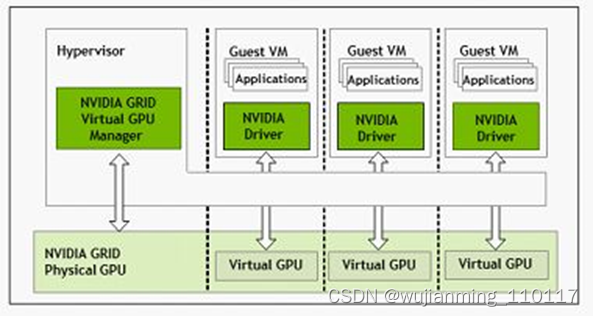
GRID GPU产品主要包含K1和K2两个型号,同样采用Kepler架构,实现了GPU的硬件虚拟化,可以让多个用户共享使用同一张GPU卡,适用于对3D性能有要求的VDI或云环境下多租户的GPU加速计算场景。
GPU散热方式分为散热片和散热片配合风扇的形式,也叫作主动式散热和被动式散热方式。
一般一些工作频率较低的显卡采用的都是被动式散热,这种散热方式就是在显示芯片上安装一个散热片即可,并不需要散热风扇。因为较低工作频率的显卡散热量并不是很大,没有必要使用散热风扇,这样在保障显卡稳定工作的同时,不仅可以降低成本,而且还能减少使用中的噪音。
NVIDIA Tesla Family采用被动散热、QUADRO Family和GeForce Family采用主动散热。
NVIDIA GPU架构的发展类似Intel的CPU,针对不同场景和技术革新,经历了不同架构的演进。
• Turing架构里,一个SM中拥有64个半精度,64个单精度,8个Tensor core,1个RT core。
• Kepler架构里,FP64单元和FP32单元的比例是1:3或者1:24;K80。
• Maxwell架构里,这个比例下降到了只有1:32;型号M10/M40。
• Pascal架构里,这个比例又提高到了1:2(P100)但低端型号里仍然保持为1:32,型号Tesla P40、GTX 1080TI/Titan XP、Quadro GP100/P6000/P5000
• Votal架构里,FP64单元和FP32单元的比例是1:2;型号有Tesla V100、GeForce TiTan V、Quadro GV100专业卡。
深度学习是模拟人脑神经系统而建立的数学网络模型,这个模型的最大特点是,需要大数据来训练。因此,对电脑处理器的要求,就是需要大量的并行的重复计算,GPU正好有这个专长,时势造英雄,因此,GPU就出山担当重任了。
训练:可以把深度学习的训练看成学习过程。人工神经网络是分层的、是在层与层之间互相连接的、网络中数据的传播是有向的。训练神经网络的时候,训练数据被输入到网络的第一层。然后所有的神经元,都会根据任务执行的情况,根据其正确或者错误的程度如何,分配一个权重参数(权值)。
推理:就是深度学习把从训练中学习到的能力应用到工作中去。不难想象,没有训练就没法实现推断。人也是这样,通过学习来获取知识、提高能力。深度神经网络也是一样,训练完成后,并不需要其训练时那样的海量资源。
高性能计算应用程序涵盖了物理、生物科学、分子动力学、化学和天气预报等各个领域。也都是通过GPU实现加速的。
CUDA与GPU
CUDA的产生就是英伟达公司为拥有并行计算需求的从业者能够使用GPU而提供的工具,因此先来讲讲什么是GPU,和CPU之间的有什么异同。首先要明确一点,CPU和GPU都可以作为计算机的大脑,两者的组成部分是一致的,如下图所示:
• 绿色:计算单元
• 橙色:存储单元(硬盘+缓存)
• 黄色:控制单元
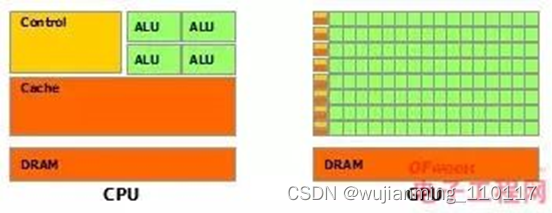
从图中可以发现:
• CPU具有很强的控制器,也有很强大的缓存(Cache)
• GPU有很多控制器,很多的计算单元,每个控制器都配有缓存
从两者的架构来看,发现,这两者的设计逻辑是不一样的,CPU秉承着低延时性,而GPU的思路是高吞吐量。所谓低延时性,直白来说就是一台挖掘机(控制器),用爪子(缓存),一次就能够挖很多的资源(计算)。所谓高吞吐量,直白来说就是一个团的人(控制器),用手(缓存),一次一个个的也能捧很多资源(计算)。所以CPU和GPU用两种不同的思路实现了计算能力最大化。而基于不同的设计思路,两者的应用场景也是大不相同,CPU适合用于逻辑控制,串行的计算场景,而GPU适合用于大规模的并行计算场景。对图像数据的应用就是一种并行计算场景,图像数据由很多像素点组成,各个像素相互独立,并行存在的。,因此GPU最早用于图像渲染等操作。而最近,利用深度学习解决图像问题的场景也很适合用GPU计算。
言归正传,为了让上述的GPU能够发挥作用,CUDA应运而生。CUDA的诞生就是为了让GPU能够有可用的编程环境,使得开发人员可以用程序控制GPU的硬件进行并行计算。所以本质上,CUDA是一个软件体系,如下图所示,该体系结构三部分组成:
• CUDA驱动API
可以通过直接操纵硬件来实现GPU的使用,但编程复杂,编程难度大,类似与汇编语言。(函数前缀为cu)
• CUDA运行时API
对驱动API中的操作进行了一次封装,使用起来相对更友好,因此在编程过程中使用会比驱动API的频率要高。需要注意的是不可以和驱动API混合使用。(函数前缀为cuda)
• CUDA函数库(官方和第三方)
为了实现更高级的功能,官方或者第三方开发者提供的针对于某个领域的高级函数库,使得普通开发人员能够快速上手实现定制化功能。比如安装CUDA时经常会要连带安装的CUDNN,这就是针对于卷积计算的CUDA函数库,使得深度学习开发者能够很容易的调用CUDA实现深度学习算法的构建。
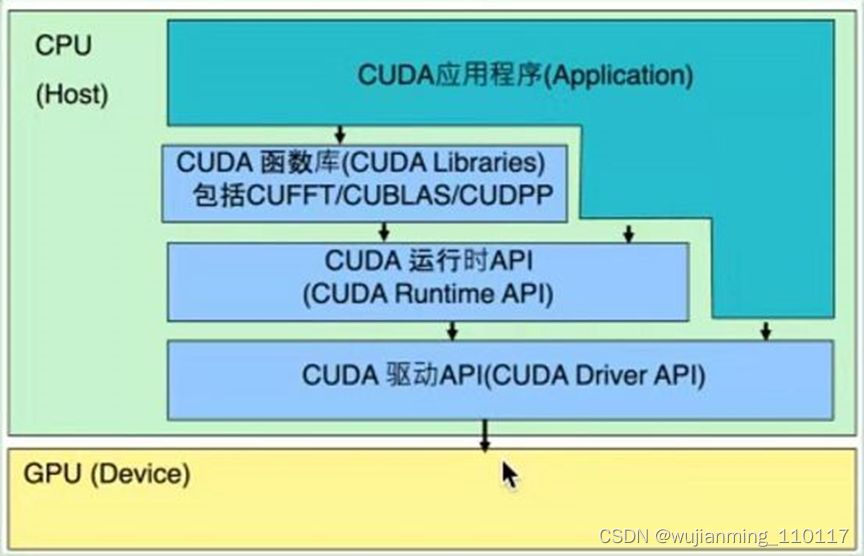
当然如上图所示,当开发人员编写CUDA应用程序时,可以通过直接调用底层的驱动API来调用GPU。也可以通过调用CUDA运行时API间接调用GPU。当然也可以通过直接使用GUDA函数库,进一步简化开发过程。而目前大部分GUDA应用程序开发者使用的都是后两种策略(就先现在很少有人用汇编语言开发功能一样)。CUDA应用程序是直接支持C语言开发的,当然随着CUDA版本的更迭,目前已经支持C++11了。
最后当开发人员利用C语言编写好CUDA应用程序后,还需要用特殊的编译器将程序员能够看懂的C语言,编译成计算,GPU能够识别的机器语言。如上图所示,CUDA的应用程序是以CPU作为宿主,然后达到操纵GPU的目的,所以最终真正运行时整个解决方案中既有运行在CPU上的代码,也会有运行在GPU上的代码。NVCC编译器就是专门针对这种情形开发出来的编译器。
CUDA GPU加速技巧
步调一致的工人
在奇妙的计算机世界有一个叫做GPU的神奇工厂。这个工厂建立在一块海岛上面,与大陆隔海相望。海岛与大陆之间只有一条双向单车道大桥(PCIe),桥上每天有来来往往的卡车运送原材料和工厂加工好的产品(data)。
大桥在海岛的一端连接着一大片空地(vRAM),卡车将运来的原材料存放于此。空地的后面就是工厂的厂房(SM),厂房内忙碌着数万名工人(core)。工人们将原材料搬运至厂房,加工成产品后,搬运回空地,等待卡车将其运回大陆。
这个神奇工厂谓之于神奇,在于他的工人们喜欢步调一致地工作。展开来说,每32个工人结成一组(warp),步调一致地搬材料,步调一致地拧螺丝,步调一致地组装产品……倘若有人想打破这种一致的步调,组内的其他人就要停下来等他,直到大家的步调再次一致。
同样地,工人们也喜欢一起推着一个板车去空地的同一块区域搬运东西(coalesced memory access)。假使其中有人要搬运的东西散落在空地的其他地方,就会推着板车专程再运一次。
当工厂的经理(programmer)发现了工人们的这种特点后,想破脑筋设计工序(kernel),让每组工人们在厂房内尽可能地做同样的事情,也尽可能地让去空地中的同一块区域搬运材料。对于有些产品(e.g.image processing),经理们能轻松地设计出生产工序,让工人们步调一致地工作;而对于有些产品(e.g. SPH),经理们想破脑筋也很难设计出完美的工序,只能不断地优化、设计、优化、设计……直到头秃了,人老了。
需要整理的货物
其实工厂在大陆的一端设有总部(CPU),总部的工厂同样可以生产各式各样的产品。只不过总部工厂的生产设备(instruction)与岛上的工厂不同,工人的素质也不一样。总的来说,大陆的工厂里,工人虽少,但个个精明强干;生产设备更加丰富,配套设施更加完善,这使得工人们的工作效率非常高。与岛上工厂的工人们喜欢一起做同一件事情不同的是,大陆的工厂更善于短时间内完成不同的事情。这样的差异使得两间工厂,对于生产不同种类的产品,各有所长。一直以来,岛上的工厂凭借工人的人数优势,积极承揽大陆工厂很多的生产任务。
大陆的工厂同样设有存放原材料及产品的仓库(RAM)。与岛上存放原材料及产品的那片空地不同的是,货物进出大陆的仓库时,工厂都会派工人对货物进行整理(pageable memory)。这就使得,大陆的工厂每次向岛上进货或出货,工人都会停下手中的活,去货仓整理货物。这会在一定程度上造成资源的浪费。为此,大陆工厂的经理们开始考虑在仓库前面开辟一块空地(pinned memory),这片空地与岛上的一样,无需工人前去整理货物。每当大陆的工厂需要出货时,经理们会派工人将仓库里的货物运到空地,然后工人们可以回到工厂,继续做手头上的事情。当岛上的工厂需要从大陆进货时,会直接派卡车去空地上拿货,无需跟大陆的工厂打招呼(direct memory access)。同样地,当岛上的工厂向大陆运送产品时,可以直接将产品堆放至大陆仓库前的空地。大陆工厂的工人可以在完成自己手中的工作以后,再去空地把产品移至仓库。通过这样的方式,大陆的工厂与岛上的工厂可以在大部分时间里,各自专心致志地从事生产,互不干扰。
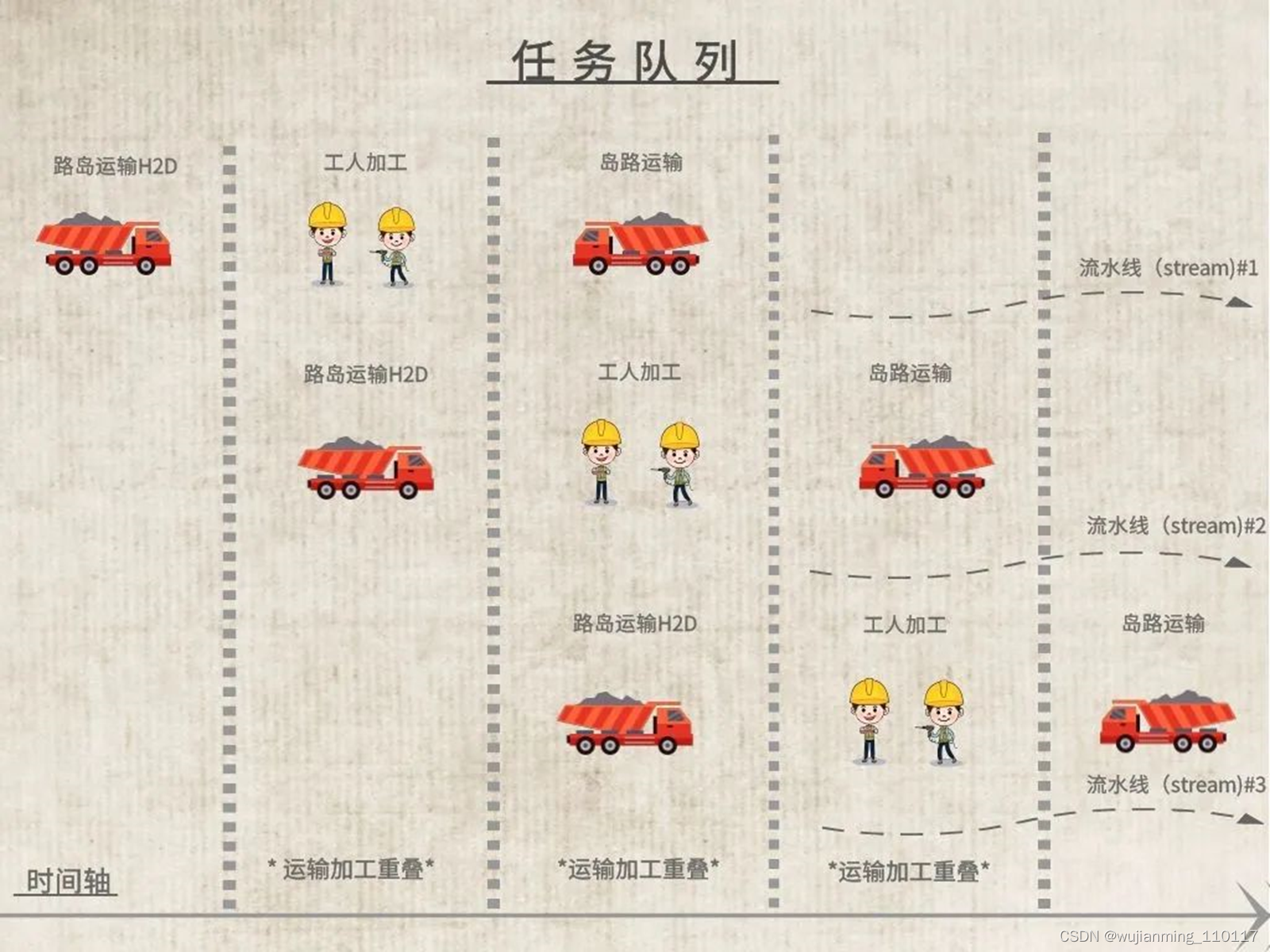
多条流水线
大陆与岛仅通过一条设有双向单行车道的大桥连接。这条大桥比很多人预想的要窄、要长。这就使得货物从桥的一端运输到另一端是非常耗时的。对于有些产品来说,原材料在岛上车间里加工生产的时间可能远远小于材料在路上运输的时间。如果一个产品在岛上的运输和生产的总时间比在大陆工厂里的生产时间要多,那想必很多经理就不会考虑山长水远地在岛上部署该产品的生产了。然而,有些更聪明的经理会设法让产品的运输时间“看起来”没那么长。让一起来看看是怎么做到的。
首先,已经知道一个产品的生产需要经历原料运输->车间加工->产品运输三个前后关联的环节。把这样一条由前后关联的环节组成的生产流程称为流水线(stream)。展开来讲,从哪里运多少原材料,需要工厂多少工人按照什么样的工序去生产,然后把生产出的产品运输到大陆工厂的哪个位置…一旦这些细节确定下来,岛上的工厂就可以拿着这样的方案去执行,全程不需要大陆工厂的参与。那么假如工厂经理制定出多条这样的流水线呢?岛上工厂会执行完一条流水线后再去执行下一条,抑或是同时去执行所有的流水线?
答案是,这取决于岛上工厂的一个调度部门(command uffer)。大致来讲,这个调度部门会把一条流水线上陆岛运输(H2D)、产品加工(kernel execution)、岛陆运输(D2H)三个环节排成任务队列,依次执行;不同流水线的任务队列互相独立。如果大桥上“陆->岛”方向车道上没有卡车在通行,而此时恰巧在任务队列的首端有陆岛运输的任务环节处于待命状态,则调度部门会立即执行这个陆岛运输的任务;该流水线的其余任务环节会等待这个陆岛运输任务的结束。需要注意的是,一旦在“陆->岛”方向的车道上有卡车正在通行,调度部门不会再安排任何的陆岛运输任务。
同样地,如果任务队列首端存在产品加工的任务,且该任务所需要的工人数、设备数(e.g.register,cache)小于岛上工厂里正在休息的工人数、闲置的设备数时,调度部门会立即安排该任务。类似地,当任务队列首端存在岛陆运输的任务,且大桥上岛陆方向的车道上没有卡车通行时,调度部门会立即安排该任务的执行。
从上述描述中,可以看到三个限制条件:1)大桥上每个方向的车道上只能行驶一辆卡车;2)工厂里的工人数和设备数有限,且工人一次只能专注于一个任务;3)每个流水线上的任务环节只能按次序执行。
而调度部门尽力去做的,就是在这三个限制条件约束下,让工人们尽可能有工作可做。与此同时,在工人们工作期间,运输队也不要停歇。运输完一部分原料,马上让工人们加工;工人们加工的同时,再运输一部分原料……运输,加工,加工,运输,通过让运输和加工重叠,消耗在路上的时间就被掩盖掉了,从而运输的时间“看起来”没那么长了。当工人和运输队更忙了,生产周期自然就变快了……真是个充满剥削的社会!聪明的经理们通常会将一个产品的生产科学地分成多条流水线,然后把流水线交给调度部门去调度执行,目的是为了让大桥和工人充分忙碌起来。
让工厂繁忙起来
在卡车的速度不变,工人的手艺没有提升的情况下,若想获得更快的生产效率,经理们唯有不断地增加卡车的班次,减少工人们的休息时间,让整个工厂充分地繁忙起来。通过让工人们步调一致地干活可以达到这个目的;通过减少大陆工厂和岛上工厂的联系可以达到这个目的;通过开辟多条流水线也可以达到这个目的。当然,让工厂繁忙起来的手段远不止这些,等待着聪明的经理们一起去探索。
GPU| CUDA编程
2006年,NVIDIA公司发布了CUDA(http://docs.nvidia.com/cuda/),CUDA是建立在NVIDIA的CPUs上的一个通用并行计算平台和编程模型,基于CUDA编程可以利用GPUs的并行计算引擎来更加高效地解决比较复杂的计算难题。近年来,GPU最成功的一个应用就是深度学习领域,基于GPU的并行计算已经成为训练深度学习模型的标配。目前,最新的CUDA版本为CUDA 9。
GPU并不是一个独立运行的计算平台,而需要与CPU协同工作,可以看成是CPU的协处理器,因此当在说GPU并行计算时,其实是指的基于CPU+GPU的异构计算架构。在异构计算架构中,GPU与CPU通过PCIe总线连接在一起来协同工作,CPU所在位置称为为主机端(host),而GPU所在位置称为设备端(device),如下图所示。
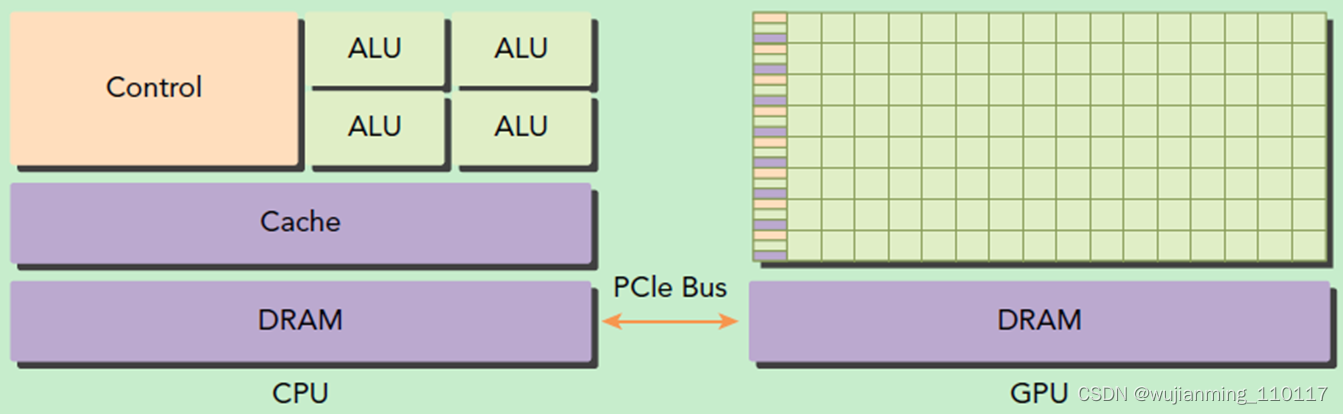
基于CPU+GPU的异构计算. 来源:Preofessional CUDA® C Programming
可以看到GPU包括更多的运算核心,其特别适合数据并行的计算密集型任务,如大型矩阵运算,而CPU的运算核心较少,但是其可以实现复杂的逻辑运算,因此其适合控制密集型任务。另外,CPU上的线程是重量级的,上下文切换开销大,但是GPU由于存在很多核心,其线程是轻量级的。因此,基于CPU+GPU的异构计算平台可以优势互补,CPU负责处理逻辑复杂的串行程序,而GPU重点处理数据密集型的并行计算程序,从而发挥最大功效。
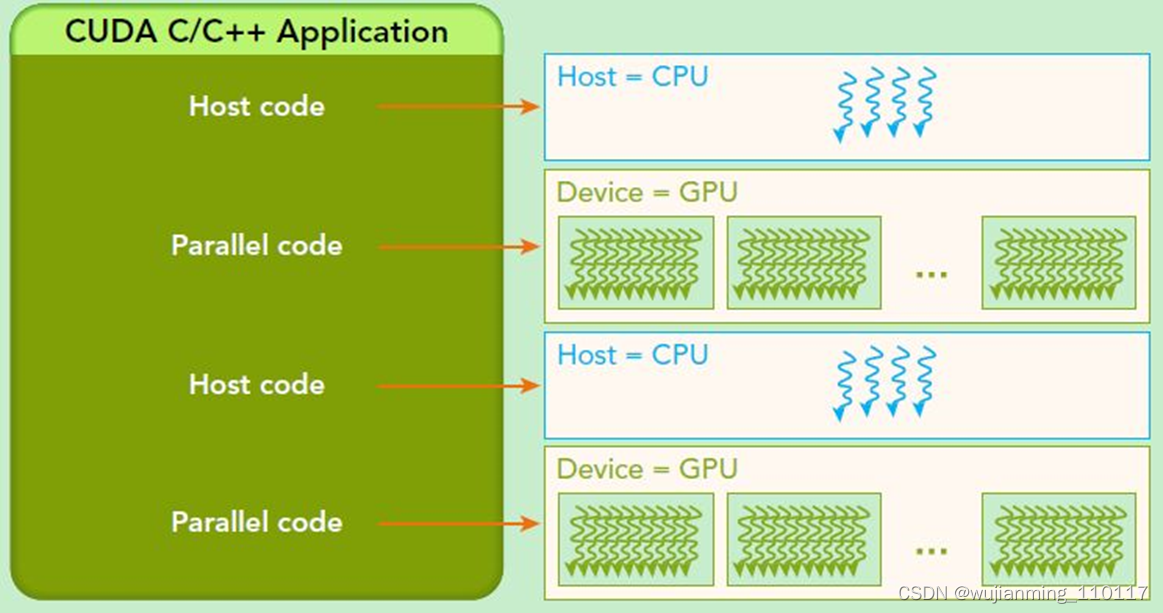
基于CPU+GPU的异构计算应用执行逻辑. 来源:Preofessional CUDA® C Programming
CUDA是NVIDIA公司所开发的GPU编程模型,提供了GPU编程的简易接口,基于CUDA编程可以构建基于GPU计算的应用程序。CUDA提供了对其它编程语言的支持,如C/C++,Python,Fortran等语言,这里选择CUDA C/C++接口对CUDA编程进行讲解。开发平台为Windows 10 + VS 2013,Windows系统下的CUDA安装教程可以参考这里http://docs.nvidia.com/cuda/cuda-installation-guide-microsoft-windows/index.html
1
CUDA编程模型基础
在给出CUDA的编程实例之前,这里先对CUDA编程模型中的一些概念及基础知识做个简单介绍。CUDA编程模型是一个异构模型,需要CPU和GPU协同工作。在CUDA中,host和device是两个重要的概念,用host指代CPU及其内存,而用device指代GPU及其内存。CUDA程序中既包含host程序,又包含device程序,分别在CPU和GPU上运行。同时,host与device之间可以进行通信,这样之间可以进行数据拷贝。典型的CUDA程序的执行流程如下:
- 分配host内存,并进行数据初始化;
- 分配device内存,并从host将数据拷贝到device上;
- 调用CUDA的核函数在device上完成指定的运算;
- 将device上的运算结果拷贝到host上;
- 释放device和host上分配的内存。
上面流程中最重要的一个过程是调用CUDA的核函数来执行并行计算,kernel(http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#kernels)是CUDA中一个重要的概念,kernel是在device上线程中并行执行的函数,核函数用__global__符号声明,在调用时需要用<<<grid, block>>>来指定kernel要执行的线程数量,在CUDA中,每一个线程都要执行核函数,并且每个线程会分配一个唯一的线程号thread ID,这个ID值可以通过核函数的内置变量threadIdx来获得。
由于GPU实际上是异构模型,所以需要区分host和device上的代码,在CUDA中是通过函数类型限定词开区别host和device上的函数,主要的三个函数类型限定词如下:
• global:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数参数,不能成为类成员函数。注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。
• device:在device上执行,仅可以从device中调用,不可以和__global__同时用。
• host:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__,此时函数会在device和host都编译。
要深刻理解kernel,必须要对kernel的线程层次结构有一个清晰的认识。首先GPU上很多并行化的轻量级线程。kernel在device上执行时实际上是启动很多线程,一个kernel所启动的所有线程称为一个网格(grid),同一个网格上的线程共享相同的全局内存空间,grid是线程结构的第一层次,而网格又可以分为很多线程块(block),一个线程块里面包含很多线程,这是第二个层次。线程两层组织结构如下图所示,这是一个gird和block均为2-dim的线程组织。grid和block都是定义为dim3类型的变量,dim3可以看成是包含三个无符号整数(x,y,z)成员的结构体变量,在定义时,缺省值初始化为1。因此grid和block可以灵活地定义为1-dim,2-dim以及3-dim结构,对于图中结构(主要水平方向为x轴),定义的grid和block如下所示,kernel在调用时也必须通过执行配置(http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#execution-configuration)<<<grid, block>>>来指定kernel所使用的线程数及结构。
dim3 grid(3, 2);
dim3 block(4, 3);
kernel_fun<<< grid, block >>>(prams…);
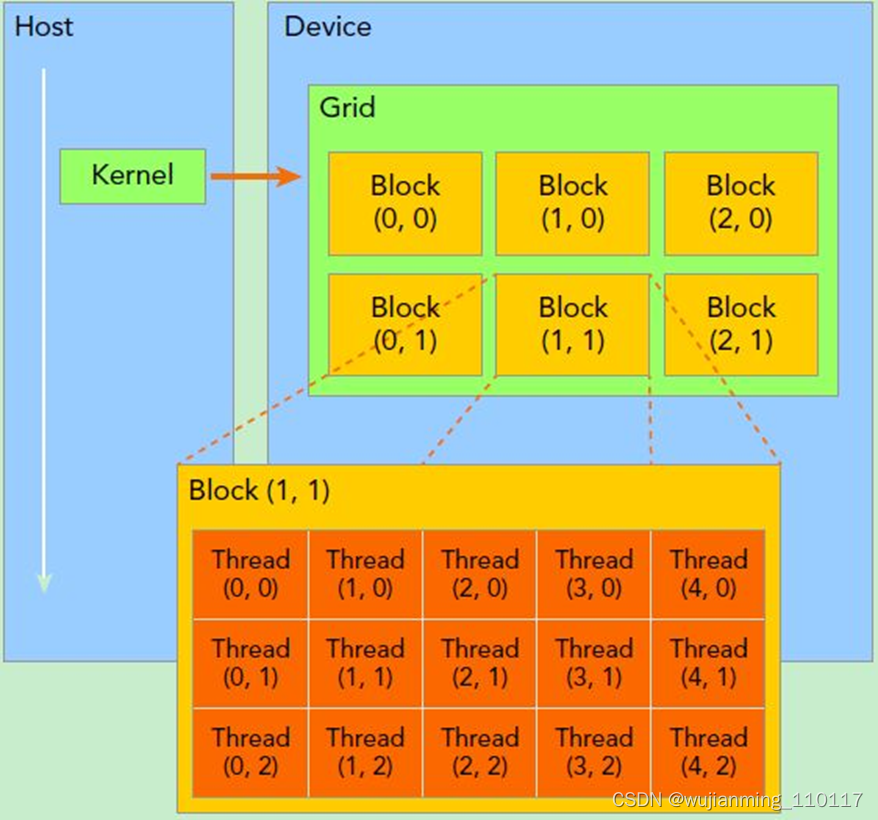
所以,一个线程需要两个内置的坐标变量(blockIdx,threadIdx)来唯一标识,都是dim3类型变量,其中blockIdx指明线程所在grid中的位置,而threaIdx指明线程所在block中的位置,如图中的Thread (1,1)满足:
threadIdx.x = 1
threadIdx.y = 1
blockIdx.x = 1
blockIdx.y = 1
一个线程块上的线程是放在同一个流式多处理器(SM)上的,但是单个SM的资源有限,这导致线程块中的线程数是有限制的,现代GPUs的线程块可支持的线程数可达1024个。有时候,要知道一个线程在blcok中的全局ID,此时就必须还要知道block的组织结构,这是通过线程的内置变量blockDim来获得。获取线程块各个维度的大小。对于一个2-dim的block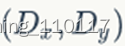
,线程(x,y)的ID值为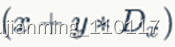 ,如果是3-dim的block
,如果是3-dim的block 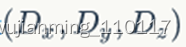
,线程(x,y,z)的ID值为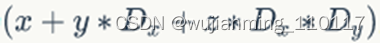
。另外线程还有内置变量gridDim,用于获得网格块各个维度的大小。
kernel的这种线程组织结构天然适合vector,matrix等运算,如将利用上图2-dim结构实现两个矩阵的加法,每个线程负责处理每个位置的两个元素相加,代码如下所示。线程块大小为(16, 16),然后将N*N大小的矩阵均分为不同的线程块来执行加法运算。
// Kernel定义
global void MatAdd(float A[N][N], float B[N][N], float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
…
// Kernel 线程配置
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
// kernel调用
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
…
}
此外这里简单介绍一下CUDA的内存模型,如下图所示。可以看到,每个线程有自己的私有本地内存(Local Memory),而每个线程块有包含共享内存(Shared Memory),可以被线程块中所有线程共享,其生命周期与线程块一致。此外,所有的线程都可以访问全局内存(Global Memory)。还可以访问一些只读内存块:常量内存(Constant Memory)和纹理内存(Texture Memory)。内存结构涉及到程序优化,这里不深入探讨。
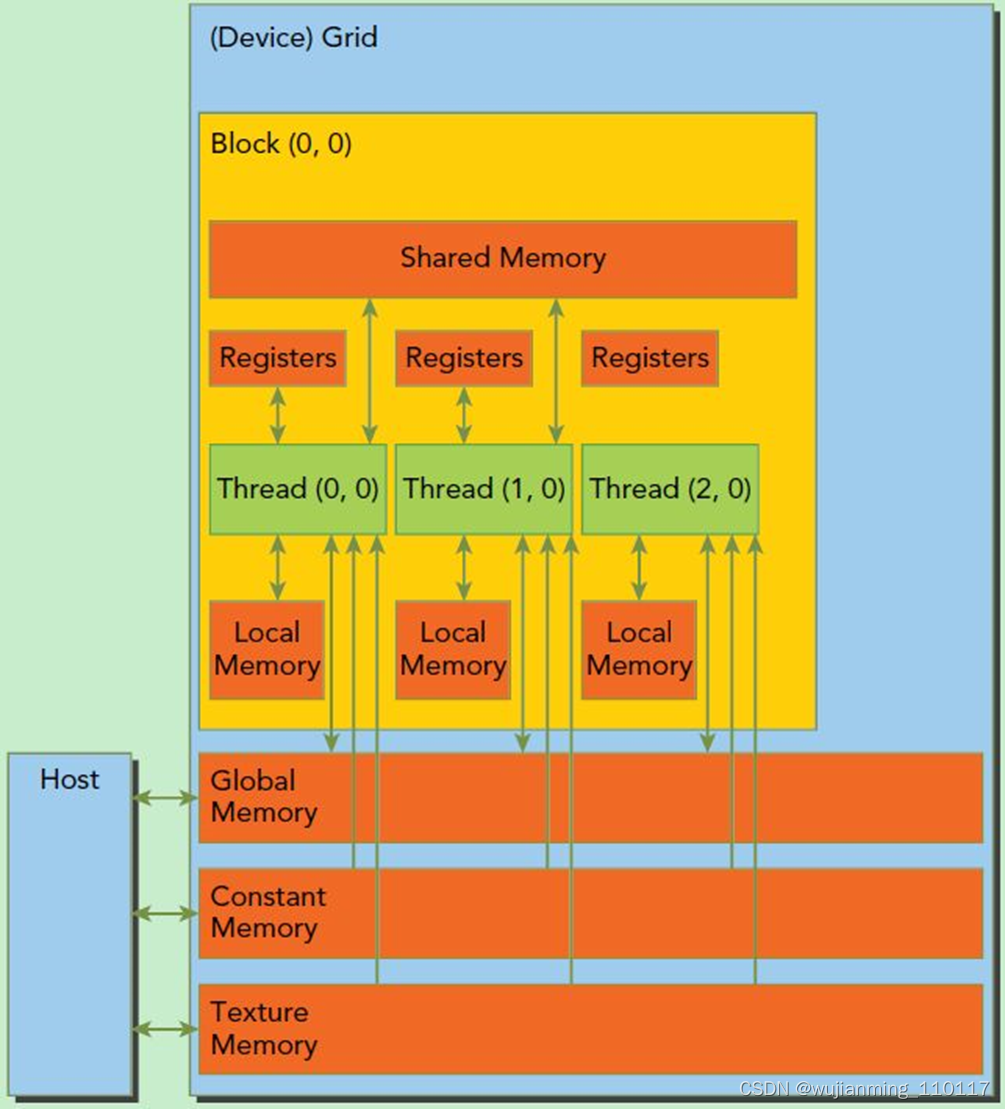
CUDA内存模型
还有重要一点,需要对GPU的硬件实现有一个基本的认识。上面说到了kernel的线程组织层次,那么一个kernel实际上会启动很多线程,这些线程是逻辑上并行的,但是在物理层却并不一定。这其实和CPU的多线程有类似之处,多线程如果没有多核支持,在物理层也是无法实现并行的。但是好在GPU存在很多CUDA核心,充分利用CUDA核心可以充分发挥GPU的并行计算能力。GPU硬件的一个核心组件是SM,前面已经说过,SM是英文名是 Streaming Multiprocessor,翻译过来就是流式多处理器。SM的核心组件包括CUDA核心,共享内存,寄存器等,SM可以并发地执行数百个线程,并发能力就取决于SM所拥有的资源数。当一个kernel被执行时,gird中的线程块被分配到SM上,一个线程块只能在一个SM上被调度。SM一般可以调度多个线程块,这要看SM本身的能力。那么有可能一个kernel的各个线程块被分配多个SM,所以grid只是逻辑层,而SM才是执行的物理层。SM采用的是SIMT(链接:http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#simt-architecture)(Single-Instruction, Multiple-Thread,单指令多线程)架构,基本的执行单元是线程束(wraps),线程束包含32个线程,这些线程同时执行相同的指令,但是每个线程都包含自己的指令地址计数器和寄存器状态,也有自己独立的执行路径。所以尽管线程束中的线程同时从同一程序地址执行,但是可能具有不同的行为,比如遇到了分支结构,一些线程可能进入这个分支,但是另外一些有可能不执行,只能死等,因为GPU规定线程束中所有线程在同一周期执行相同的指令,线程束分化会导致性能下降。当线程块被划分到某个SM上时,将进一步划分为多个线程束,因为这才是SM的基本执行单元,但是一个SM同时并发的线程束数是有限的。这是因为资源限制,SM要为每个线程块分配共享内存,而也要为每个线程束中的线程分配独立的寄存器。所以SM的配置会影响其所支持的线程块和线程束并发数量。总之,就是网格和线程块只是逻辑划分,一个kernel的所有线程其实在物理层是不一定同时并发的。所以kernel的grid和block的配置不同,性能会出现差异,这点是要特别注意的。还有,由于SM的基本执行单元是包含32个线程的线程束,所以block大小一般要设置为32的倍数。

CUDA编程的逻辑层和物理层
在进行CUDA编程前,可以先检查一下自己的GPU的硬件配置,这样才可以有的放矢,可以通过下面的程序获得GPU的配置属性:
int dev = 0;
cudaDeviceProp devProp;
CHECK(cudaGetDeviceProperties(&devProp, dev));
std::cout << "使用GPU device " << dev << “: " << devProp.name << std::endl;
std::cout << “SM的数量:” << devProp.multiProcessorCount << std::endl;
std::cout << “每个线程块的共享内存大小:” << devProp.sharedMemPerBlock / 1024.0 << " KB” << std::endl;
std::cout << “每个线程块的最大线程数:” << devProp.maxThreadsPerBlock << std::endl;
std::cout << “每个EM的最大线程数:” << devProp.maxThreadsPerMultiProcessor << std::endl;
std::cout << “每个EM的最大线程束数:” << devProp.maxThreadsPerMultiProcessor / 32 << std::endl;
// 输出如下
使用GPU device 0: GeForce GT 730
SM的数量:2
每个线程块的共享内存大小:48 KB
每个线程块的最大线程数:1024
每个EM的最大线程数:2048
每个EM的最大线程束数:64
好吧,GT 730显卡确实有点渣,只有2个SM,呜呜…
2
向量加法实例
知道了CUDA编程基础,就来个简单的实战,利用CUDA编程实现两个向量的加法,在实现之前,先简单介绍一下CUDA编程中内存管理API。首先是在device上分配内存的cudaMalloc函数:
cudaError_t cudaMalloc(void** devPtr, size_t size);
这个函数和C语言中的malloc类似,但是在device上申请一定字节大小的显存,其中devPtr是指向所分配内存的指针。同时要释放分配的内存使用cudaFree函数,这和C语言中的free函数对应。另外一个重要的函数是负责host和device之间数据通信的cudaMemcpy函数:
cudaError_t cudaMalloc(void** devPtr, size_t size);
其中src指向数据源,而dst是目标区域,count是复制的字节数,其中kind控制复制的方向:cudaMemcpyHostToHost, cudaMemcpyHostToDevice,
cudaMemcpyDeviceToHost及cudaMemcpyDeviceToDevice,如cudaMemcpyHostToDevice将host上数据拷贝到device上。
现在来实现一个向量加法的实例,这里grid和block都设计为1-dim,首先定义kernel如下:
// 两个向量加法kernel,grid和block均为一维
global void add(float* x, float * y, float* z, int n)
{
// 获取全局索引
int index = threadIdx.x + blockIdx.x * blockDim.x;
// 步长
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
{
z[i] = x[i] + y[i];
}
}
其中stride是整个grid的线程数,有时候向量的元素数很多,这时候可以将在每个线程实现多个元素(元素总数/线程总数)的加法,相当于使用了多个grid来处理,这是一种grid-stride loop(链接:https://devblogs.nvidia.com/cuda-pro-tip-write-flexible-kernels-grid-stride-loops/)方式,不过下面的例子一个线程只处理一个元素,所以kernel里面的循环是不执行的。下面具体实现向量加法:
int main()
{
int N = 1 << 20;
int nBytes = N * sizeof(float);
// 申请host内存
float x, y, z;
x = (float)malloc(nBytes);
y = (float)malloc(nBytes);
z = (float)malloc(nBytes);
// 初始化数据
for (int i = 0; i < N; ++i)
{x[i] = 10.0;y[i] = 20.0;
}// 申请device内存
float *d_x, *d_y, *d_z;
cudaMalloc((void**)&d_x, nBytes);
cudaMalloc((void**)&d_y, nBytes);
cudaMalloc((void**)&d_z, nBytes);// 将host数据拷贝到device
cudaMemcpy((void*)d_x, (void*)x, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy((void*)d_y, (void*)y, nBytes, cudaMemcpyHostToDevice);
// 定义kernel的执行配置
dim3 blockSize(256);
dim3 gridSize((N + blockSize.x - 1) / blockSize.x);
// 执行kernel
add << < gridSize, blockSize >> >(d_x, d_y, d_z, N);// 将device得到的结果拷贝到host
cudaMemcpy((void*)z, (void*)d_z, nBytes, cudaMemcpyHostToDevice);// 检查执行结果
float maxError = 0.0;
for (int i = 0; i < N; i++)maxError = fmax(maxError, fabs(z[i] - 30.0));
std::cout << "最大误差: " << maxError << std::endl;// 释放device内存
cudaFree(d_x);
cudaFree(d_y);
cudaFree(d_z);
// 释放host内存
free(x);
free(y);
free(z);return 0;
}
这里向量大小为1<<20,而block大小为256,那么grid大小是4096,
kernel的线程层级结构如下图所示:
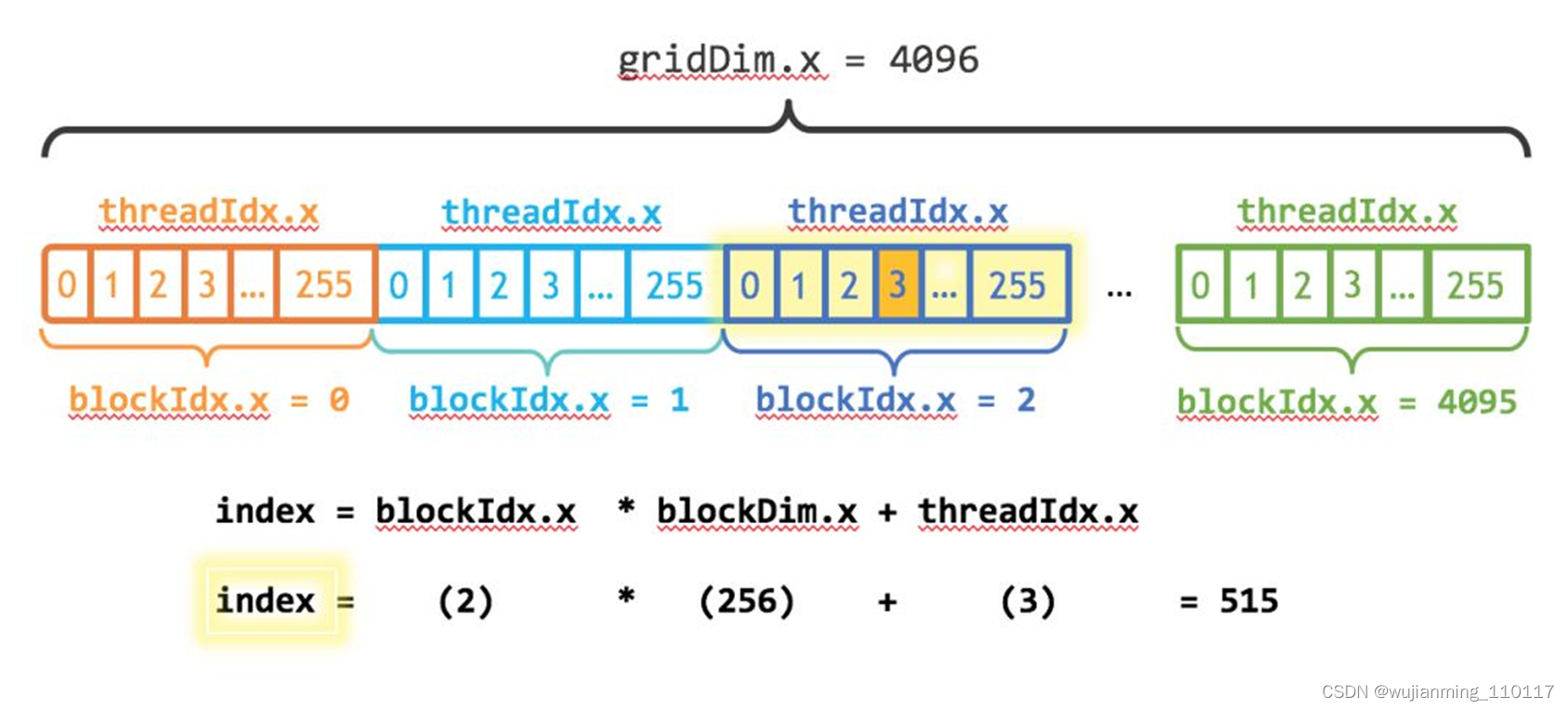
kernel的线程层次结构. 来源:https://devblogs.nvidia.com/even-easier-introduction-cuda/
使用nvprof工具可以分析kernel运行情况,结果如下所示,可以看到kernel函数费时约1.5ms。
nvprof cuda9.exe
7244 NVPROF is profiling process 7244, command: cuda9.exe
最大误差: 4.31602e+008
7244 Profiling application: cuda9.exe
7244 Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 67.57% 3.2256ms 2 1.6128ms 1.6017ms 1.6239ms [CUDA memcpy HtoD]
32.43% 1.5478ms 1 1.5478ms 1.5478ms 1.5478ms add(float*, float*, float*, int)
调整block的大小,对比不同配置下的kernel运行情况,这里测试的是当block为128时,kernel费时约1.6ms,而block为512时kernel费时约1.7ms,当block为64时,kernel费时约2.3ms。看来不是block越大越好,而要适当选择。
在上面的实现中,需要单独在host和device上进行内存分配,并且要进行数据拷贝,这是很容易出错的。好在CUDA 6.0引入统一内存(Unified Memory)(链接:http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#um-unified-memory-programming-hd)来避免这种麻烦,简单来说就是统一内存使用一个托管内存来共同管理host和device中的内存,并且自动在host和device中进行数据传输。CUDA中使用cudaMallocManaged函数分配托管内存:
cudaError_t cudaMallocManaged(void **devPtr, size_t size, unsigned int flag=0);
利用统一内存,可以将上面的程序简化如下:
int main()
{
int N = 1 << 20;
int nBytes = N * sizeof(float);
// 申请托管内存
float *x, *y, *z;
cudaMallocManaged((void**)&x, nBytes);
cudaMallocManaged((void**)&y, nBytes);
cudaMallocManaged((void**)&z, nBytes);// 初始化数据
for (int i = 0; i < N; ++i)
{x[i] = 10.0;y[i] = 20.0;
}// 定义kernel的执行配置
dim3 blockSize(256);
dim3 gridSize((N + blockSize.x - 1) / blockSize.x);
// 执行kernel
add << < gridSize, blockSize >> >(x, y, z, N);// 同步device 保证结果能正确访问
cudaDeviceSynchronize();
// 检查执行结果
float maxError = 0.0;
for (int i = 0; i < N; i++)maxError = fmax(maxError, fabs(z[i] - 30.0));
std::cout << "最大误差: " << maxError << std::endl;// 释放内存
cudaFree(x);
cudaFree(y);
cudaFree(z);return 0;
}
相比之前的代码,使用统一内存更简洁了,值得注意的是kernel执行是与host异步的,由于托管内存自动进行数据传输,这里要用cudaDeviceSynchronize()函数保证device和host同步,这样后面才可以正确访问kernel计算的结果。
3
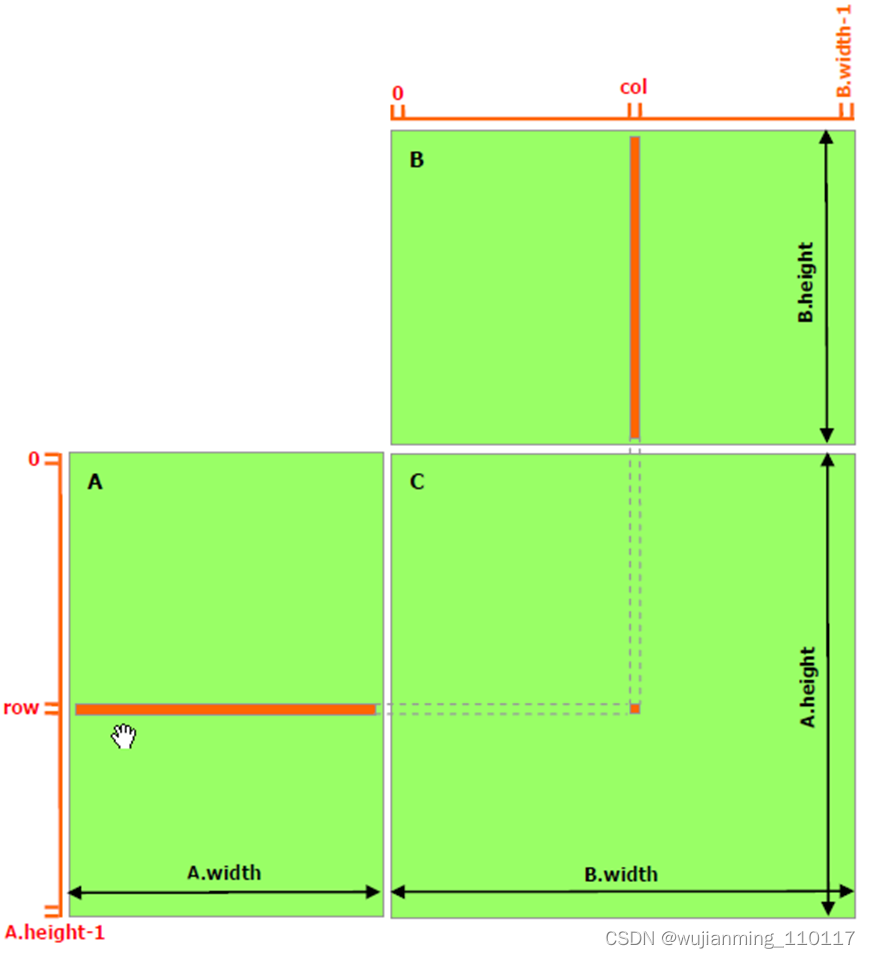
矩阵乘法实例
最后再实现一个稍微复杂一些的例子,就是两个矩阵的乘法,设输入矩阵为A和B,要得到C=A*B。实现思路是每个线程计算C的一个元素值 ,对于矩阵运算,应该选用grid和block为2-D的。首先定义矩阵的结构体:
// 矩阵类型,行优先,M(row, col) = *(M.elements + row * M.width + col)
struct Matrix
{
int width;
int height;
float elements;
Matrix(int w, int h, float e = NULL)
{
width = w;
height = h;
elements = e;
}
};
矩阵乘法实现模式
然后实现矩阵乘法的核函数,这里定义了两个辅助的__device__函数分别用于获取矩阵的元素值和为矩阵元素赋值,具体代码如下:
// 获取矩阵A的(row, col)元素
device float getElement(const Matrix A, int row, int col)
{
return A.elements[row * A.width + col];
}
// 为矩阵A的(row, col)元素赋值
device void setElement(Matrix A, int row, int col, float value)
{
A.elements[row * A.width + col] = value;
}
// 矩阵相乘kernel,2-D,每个线程计算一个元素
global void matMulKernel(const Matrix A, const Matrix B, Matrix C)
{
float Cvalue = 0.0;
int row = threadIdx.y + blockIdx.y * blockDim.y;
int col = threadIdx.x + blockIdx.x * blockDim.x;
for (int i = 0; i < A.width; ++i)
{
Cvalue += getElement(A, row, i) * getElement(B, i, col);
}
setElement(C, row, col, Cvalue);
}
最后采用统一内存编写矩阵相乘的测试实例:
int main()
{
int width = 1 << 10;
int height = 1 << 10;
Matrix A(width, height, NULL);
Matrix B(width, height, NULL);
Matrix C(width, height, NULL);
int nBytes = width * height * sizeof(float);
// 申请托管内存
cudaMallocManaged((void**)&A.elements, nBytes);
cudaMallocManaged((void**)&B.elements, nBytes);
cudaMallocManaged((void**)&C.elements, nBytes);// 初始化数据
for (int i = 0; i < width * height; ++i)
{A.elements[i] = 1.0;B.elements[i] = 2.0;
}// 定义kernel的执行配置
dim3 blockSize(32, 32);
dim3 gridSize((width + blockSize.x - 1) / blockSize.x, (height + blockSize.y - 1) / blockSize.y);
// 执行kernel
matMulKernel << < gridSize, blockSize >> >(A, B, C);// 同步device 保证结果能正确访问
cudaDeviceSynchronize();
// 检查执行结果
float maxError = 0.0;
for (int i = 0; i < width * height; i++)maxError = fmax(maxError, fabs(C.elements[i] - 2 * width));
std::cout << C.elements[0] << std::endl;
std::cout << "最大误差: " << maxError << std::endl;return 0;
}
这里矩阵大小为1024*1024,设计的线程的block大小为(32, 32),那么grid大小为(32, 32),最终测试结果如下:
nvprof cuda9.exe
2456 NVPROF is profiling process 2456, command: cuda9.exe
最大误差: 0
2456 Profiling application: cuda9.exe
2456 Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 100.00% 2.67533s 1 2.67533s 2.67533s 2.67533s matMulKernel(Matrix, Matrix, Matrix)
API calls: 92.22% 2.67547s 1 2.67547s 2.67547s 2.67547s cudaDeviceSynchronize
6.06% 175.92ms 3 58.640ms 2.3933ms 170.97ms cudaMallocManaged
1.65% 47.845ms 1 47.845ms 47.845ms 47.845ms cudaLaunch
0.05% 1.4405ms 94 15.324us 0ns 938.54us cuDeviceGetAttribute
0.01% 371.49us 1 371.49us 371.49us 371.49us cuDeviceGetName
0.00% 13.474us 1 13.474us 13.474us 13.474us cuDeviceTotalMem
0.00% 6.9300us 1 6.9300us 6.9300us 6.9300us cudaConfigureCall
0.00% 3.8500us 3 1.2830us 385ns 1.9250us cuDeviceGetCount
0.00% 3.4650us 3 1.1550us 0ns 2.3100us cudaSetupArgument
0.00% 2.3100us 2 1.1550us 385ns 1.9250us cuDeviceGet
2456 Unified Memory profiling result:
Device “GeForce GT 730 (0)”
Count Avg Size Min Size Max Size Total Size Total Time Name
2048 4.0000KB 4.0000KB 4.0000KB 8.000000MB 22.70431ms Host To Device
266 46.195KB 32.000KB 1.0000MB 12.00000MB 7.213048ms Device To Host
当然,这不是最高效的实现,后面可以继续优化…
小结
最后只有一句话:CUDA入门容易,但是深入难!希望不是从入门到放弃.
OpenGL 图形渲染流程
1、什么是 shader
shader 中文名为着色器,全称为着色器程序,是专门用来渲染图形的一种技术。通过 shader,可以自定义显卡渲染画面的算法,使画面达到想要的效果。小到每一个像素点,大到整个屏幕。通常来说,程序是运行在 CPU 中的,但是着色器程序比较特殊,是运行在 GPU 中的,所以当在编写 shader 程序的时候,实际上也是在编写 GPU 程序。在 OpenGL 中,对应的着色器语言是 GLSL(OpenGL Shading Language)。通过 shader 编程,可以实现很多渲染风格,如马赛克效果、素描风格等。


2、OpenGL 图形渲染流程
当使用 OpenGL 时,都是基于 3D 空间去编程的,但是最终呈现到屏幕或者窗口时却是二维的像素数组,所以简单来说 OpenGL 的渲染流程其实就是将 3D 坐标转换成适配屏幕的 2D 像素,而这个过程实际上是由 OpenGL 的图形渲染管线管理的,大致可以划分成两步:
- 将 3D 坐标转换成 2D 坐标。
- 将 2D 坐标转换成实际有颜色的像素。
如下图所示,图形渲染管线可以被划分为顶点着色器、图元装配、几何着色器、光栅化、片段着色器和测试混合六个阶段,每一个阶段将会把前一个阶段的输出作为输入。所有这些阶段都是高度专门化的(都有一个特定的函数),并且很容易并行执行。正是由于具有并行执行的特性,当今大多数显卡都有成千上万的小处理核心,在 GPU 上为每一个(渲染管线)阶段运行各自的小程序,从而在图形渲染管线中快速处理数据。这些小程序就是 shader。
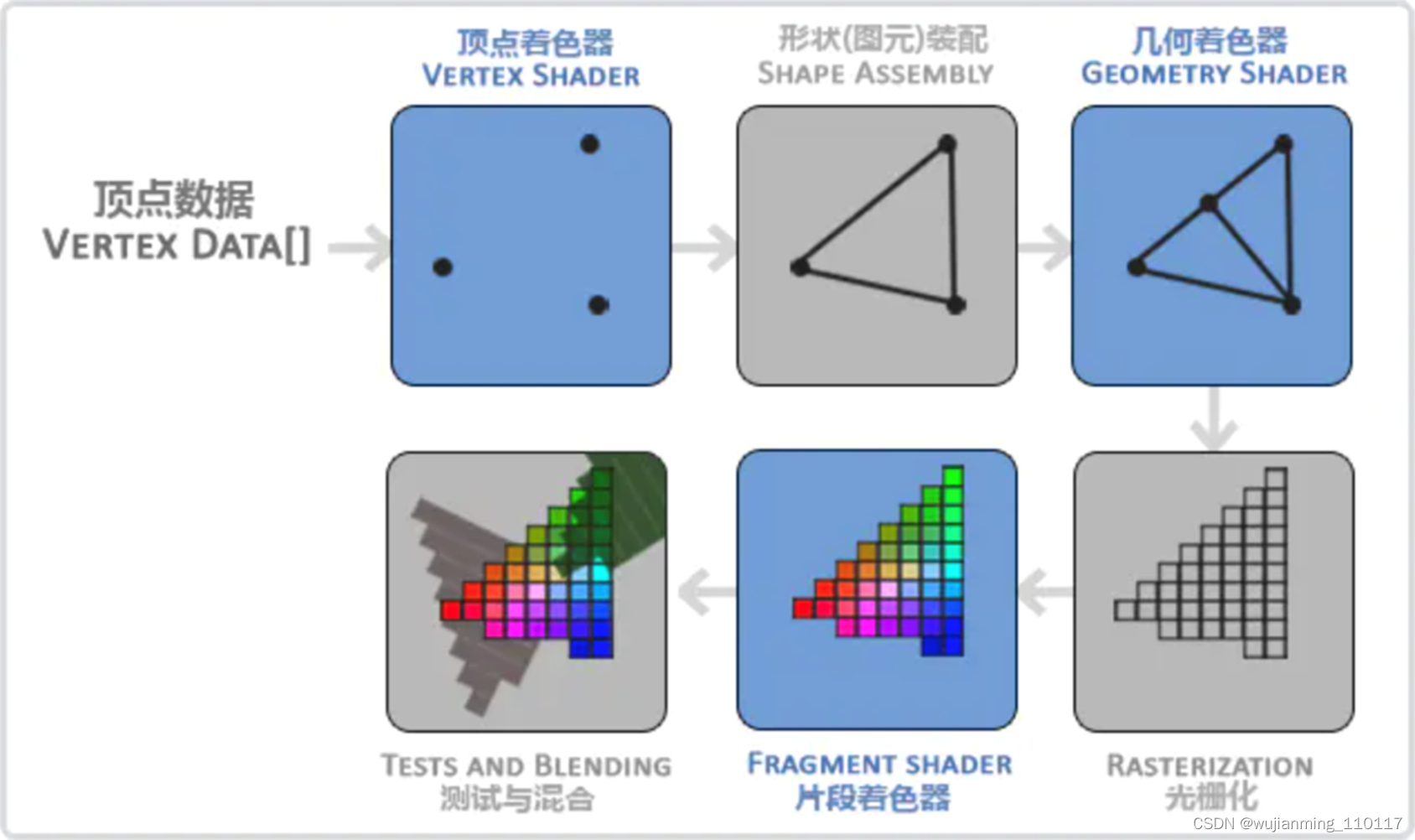
2.1. 顶点着色器
3D 图形都是由一个个三角面片组成的,顶点着色器就是计算每个三角面片上的顶点,并为最终像素渲染做准备。在顶点着色器中,可以访问到顶点的三维位置、颜色、法向量等信息。可以通过修改这些值,或者将其传递到片元着色器中,实现特定的渲染效果。
可以作为顶点着色器的输入有:
• 用 attribute 修饰的属性,可以传递顶点数据、纹理坐标等。
• 用 uniform 修饰的属性,可以传递变换矩阵等。
顶点着色器常见的输出有:
• gl_Position, 将变换后的顶点数据进行输出。
• gl_PointSize, 设置点的大小。
在顶点着色器进行的业务处理有:
• 矩阵变换的计算
• 计算光照公式生成逐顶点颜色
• 生成 / 变换纹理坐标
2.2. 图元装配
图元装配,即将从顶点着色器中输出的顶点根据 primitive (原始的连接关系)还原成网格结构。网格由顶点和索引组成,在这个阶段是根据索引将顶点连接在一起,组成线、面单元。之后就是对超出屏幕外的三角形进行裁剪。
这里的裁剪怎么理解呢?假设有一个三角形,三角形的一个顶点在屏幕外,两个顶点在屏幕内,这个时候就需要将超出屏幕外的三角形裁剪掉,所以能看到的其实是一个四边形,然后再将这个四边形的顶点装配成两个三角形图元的形状。
同时在图元装配这个阶段还需要根据三角形面片的顶点顺序 —— 也就是三角形的法向量朝向来判断是否要进行去除操作。一般顶点按照逆时针排序,根据右手定则来决定三角面片的法向量,如果该法向量朝向视点(法向量与到视点的方向的点积为正),该面是正面。如果该面是反面,则进行背面去除操作。
这里注意:在这个阶段进行的所有裁剪剔除计算都是为了减少需要绘制的顶点个数。
2.3. 几何着色器
几何着色器位于顶点和片段着色器之间,如果没有使用时,则顶点着色器输出到片元着色器,在使用几何着色器后,顶点着色器输出组成一个基础图元的顶点信息到几何着色器,经过几何着色器处理后,再输出到片元着色器。几何着色器能够产生 0 个以上的基础图元 (primitive),能起到一定的裁剪作用、同时也能产生比顶点着色器输入更多的基础图元。
几何着色器在启用后,将获得顶点着色器以组成一个基础图元为一组的顶点输入,通过对输入的顶点进行处理,几何着色器将决定输出的图元类型和个数。当输出的图元减少或者不输出时,实际上起到了裁剪图形的作用,当输出的图元类型改变或者输出更多图元时起到了产生和改变图元的作用。
2.4. 光栅化
光栅化阶段会接收来自几何着色器的图元数据输出。在这个阶段会把图元映射为最终屏幕上相应的像素,生成供片段着色器 (Fragment Shader) 使用的片段 (Fragment)。在片段着色器运行之前会执行裁切 (Clipping)。裁切会丢弃超出视图以外的所有像素,用来提升执行效率。光栅化分为三角形设置与三角形遍历两个阶段:
• 三角形设置:
光栅化的第一个流水线阶段是三角形设置,这个阶段会计算光栅化一个三角网格所需的信息。具体来说,上一个阶段输出的都是三角网格的顶点,即得到的是三角网格每条边的两个端点。但如果要得到整个三角网格对像素的覆盖情况,就必须计算每条边上的像素坐标。为了能够计算边界像素的坐标信息,就需要得到三角形边界的表示方式。这样一个计算三角网格表示数据的过程就叫做三角形设置。输出是为了给下一个阶段做准备。
• 三角形遍历:
三角形遍历阶段将会检查每个像素是否被一个三角网格所覆盖。如果被覆盖的话,就会生成一个片元,而这样一个找到哪些像素被三角网格覆盖的过程就是三角形遍历。三角形遍历阶段会根据上一个阶段的计算结果来判断一个三角网格覆盖了哪些像素,并使用三角网格 3 个顶点的顶点信息对整个覆盖区域的像素进行插值。下图展示了三角形遍历阶段的简化计算过程。
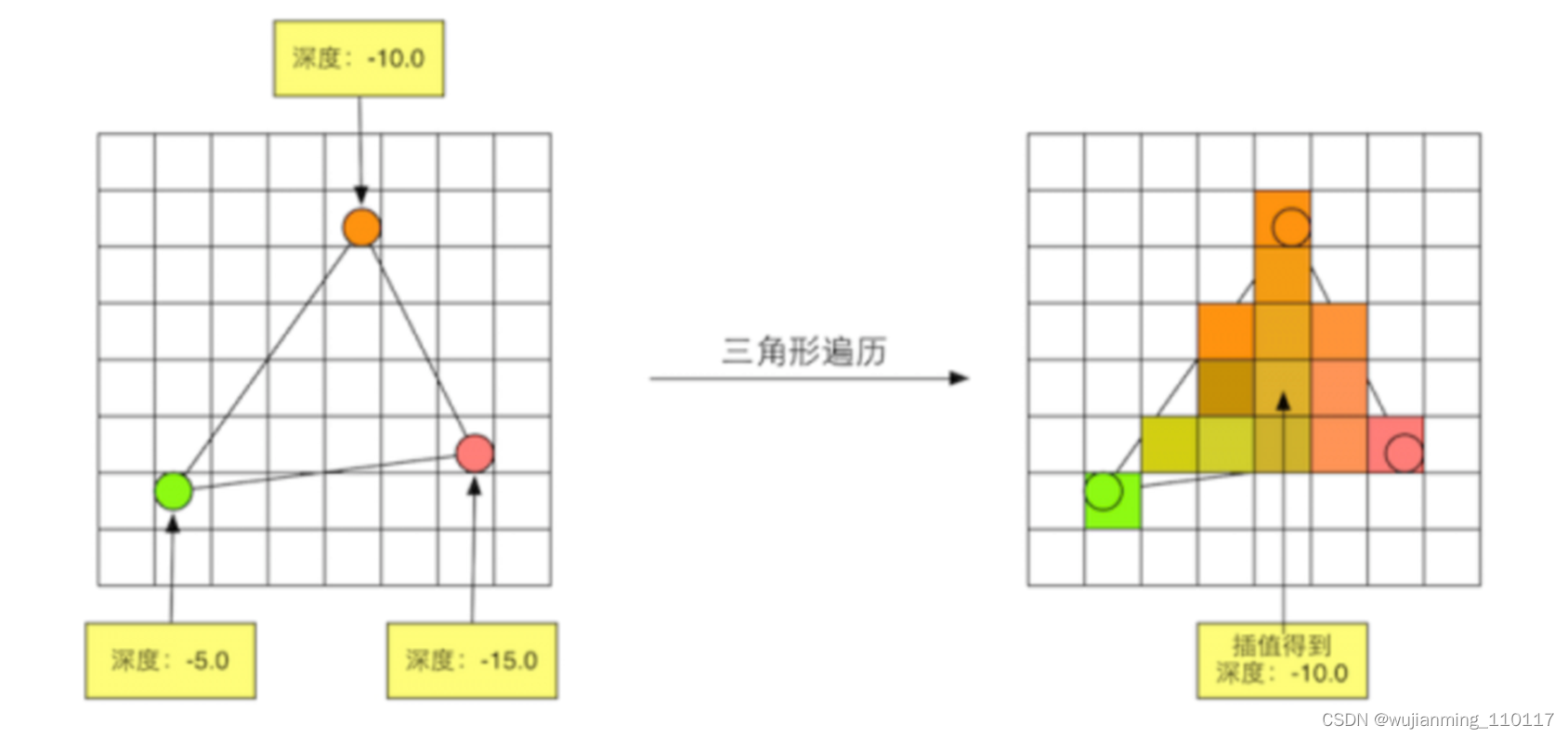
这一步的输出就是得到一个片元序列。需要注意的是,一个片元并不是真正意义上的像素,而是包含了很多状态的集合,这些状态用于计算每个像素的最终颜色。这些状态包括了 (但不限于) 屏幕坐标、深度信息,以及其他从几何阶段输出的顶点信息,例如法线、纹理坐标等。
2.5. 片段着色器
在片段着色器阶段的主要目的是计算一个像素的最终颜色,这也是所有 OpenGL 高级效果产生的地方。通常,片段着色器包含 3D 场景的数据(比如光照、阴影、光的颜色等等),这些数据可以被用来计算最终像素的颜色。
这里注意:光栅化阶段后得到的是一个个 “片元”。片元和像素已经非常接近了,但两者仍是有区别的。用一种通俗的说法来解释的话,就是比如三维空间内有两个从摄像机角度看过去一前一后的三角形,重叠部分的显示区域,每个像素对应两个片元;不重叠的部分,像素和片元一一对应。当然,这个例子是简化过的,真实的对应关系可能更复杂一些。片段着色器也是能够在图形渲染过程中进行编程的一个阶段。
2.6. Alpha 测试和混合
Alpha test 是一种类似 depth test 一般的存在,简单粗暴,通过多个条件来判断当前的片元是否通过测试,只要有一个条件不通过,即被舍弃而不会对后续渲染产生任何影响。当前片元的透明度是其中一个重要的指标,通常设定一个阈值,如果透明度小于这个阈值,那么就会被直接舍弃,相当于这个片元透明到 “看不到”、“消失” 了一般;而高于这个阈值的面片则会被当作不透明的物体来进行处理。这种简单粗暴的方法无法实现真正透明的效果。
Alpha blending 则能够真正实现透明的效果。将当前面片的 alpha 通道值(透明度)作为混合因子,参与该面片本身的颜色与颜色缓冲区中本身颜色的混合。需要注意的是,alpha 混合过程中需要关闭深度写入,但不关闭深度测试。不关闭深度测试意味着,当一个不透明的物体在另一个物体前面的时候,能够通过深度测试正常渲染更近的不透明的物体。
所以,即使在片段着色器中计算出来了一个像素输出的颜色,在渲染多个三角形的时候最后的像素颜色也可能完全不同。
光线追踪-包围盒加速
内容目录:
• 实现效果
• BVH加速
为什么要加速
什么是BVH
BVH的使用
• 代码核心逻辑
• 补充
实现效果
下图中兔子模型是由4968个三角形拼接而成
vscode预览3d模型,默认有个背景,去不掉.

bunny mesh 
bunny render result
注:bunny是儿语化的“兔子”
BVH加速
光线追踪的渲染中,每一个像素,实际上是光线打到物体表面反射到场景中。(实际还有自发光的情况,本章节简化模型,仅考虑漫反射)
为什么要加速
场景中可能存在很多物体,单个像素的光线需要和这些物体挨个求交,最后比较得出最近的交点,其他交点处于被遮挡的情况,忽略不计。
上图中兔子模型有4968个三角形,一帧图像中一个点就需要求交近5千次,1280 * 720的窗口渲染一次需求交 4968 * (1280 * 480)次,这还是比较简单的模型场景。

包围盒示意图
很容易就想到,使用一个立方体,将单个模型包围起来,先对立方体求交,条件成立之后,再考虑与里面的几何模型求交。当然了,可以将模型进一步拆分成n个三角形,包裹在立方体中。

包围盒
包围盒有多种形式,最常用的包围盒长、宽、高分别与x、y、z平行,方便计算。
什么是BVH
BVH:Bounding Volume Hierarchy。包围盒层级。
将场景中的所有模型做拆分,分成一块一块的,最常见的有基于空间和基于物体拆分两种形式。本篇中基于物体做拆分,持续迭代,拆成一个二叉树,中间节点存放包围盒,子节点存放真实的物体。
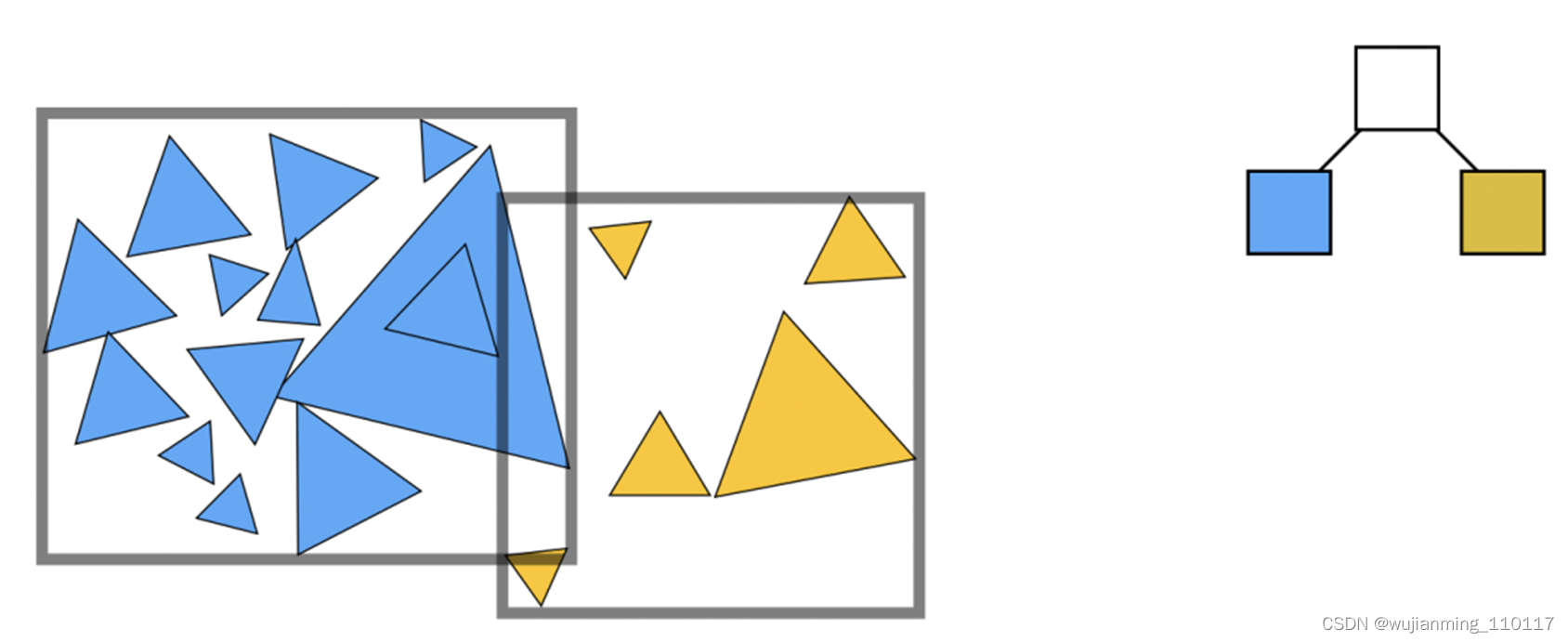
第一次拆分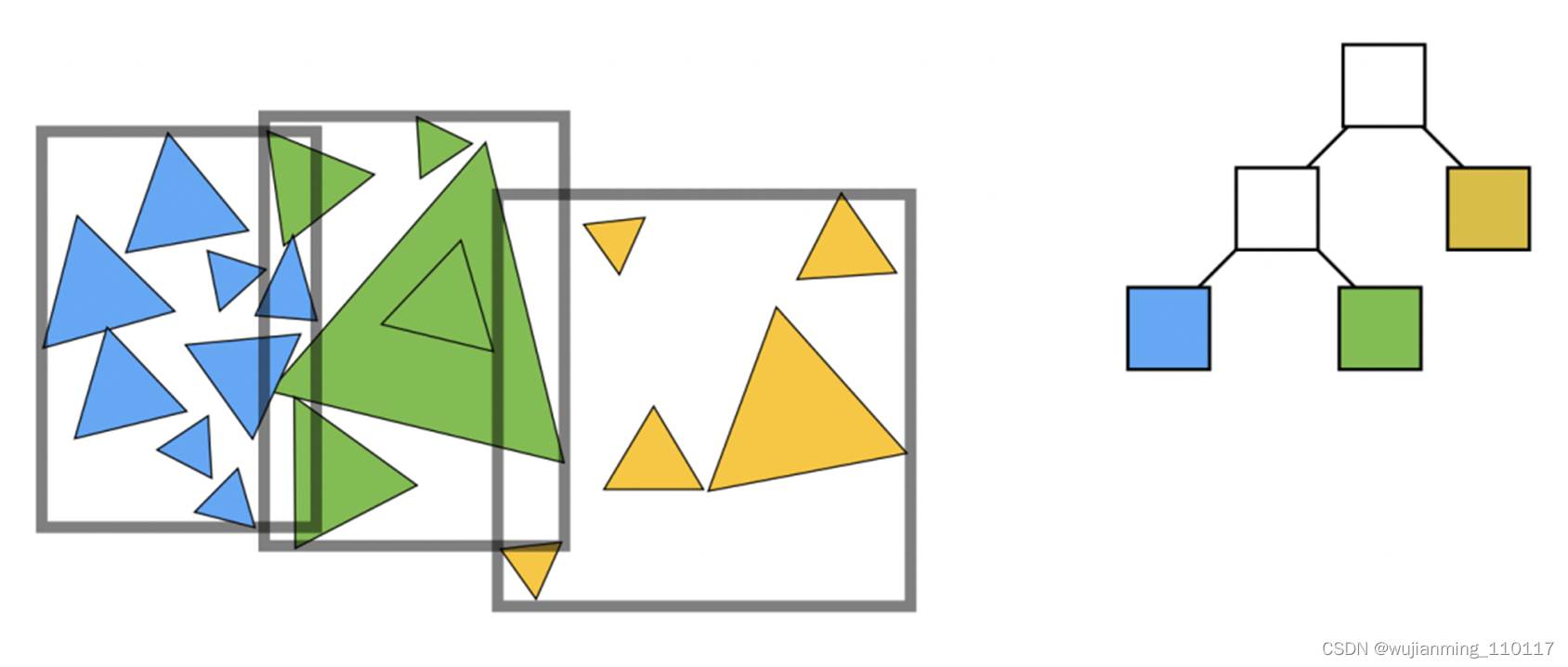
第二次拆分 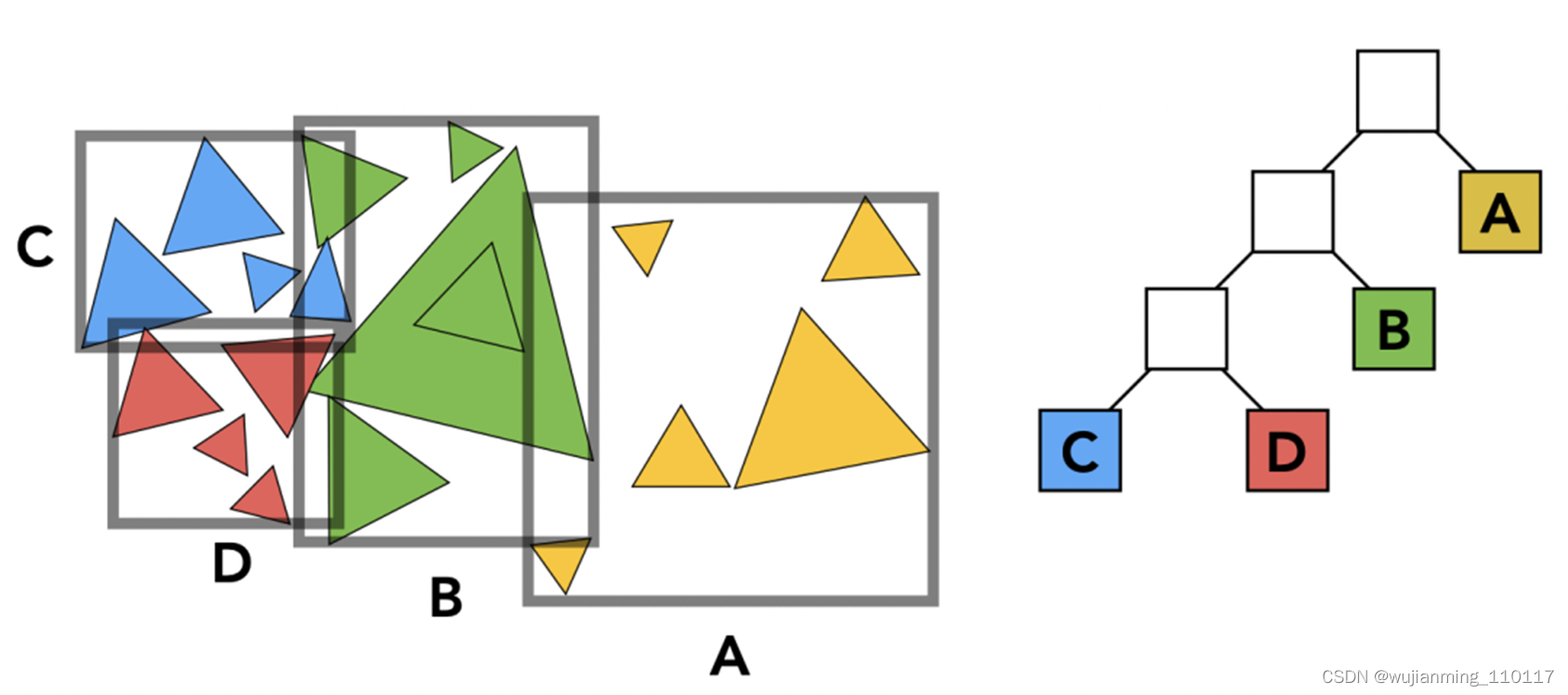
第三次拆分 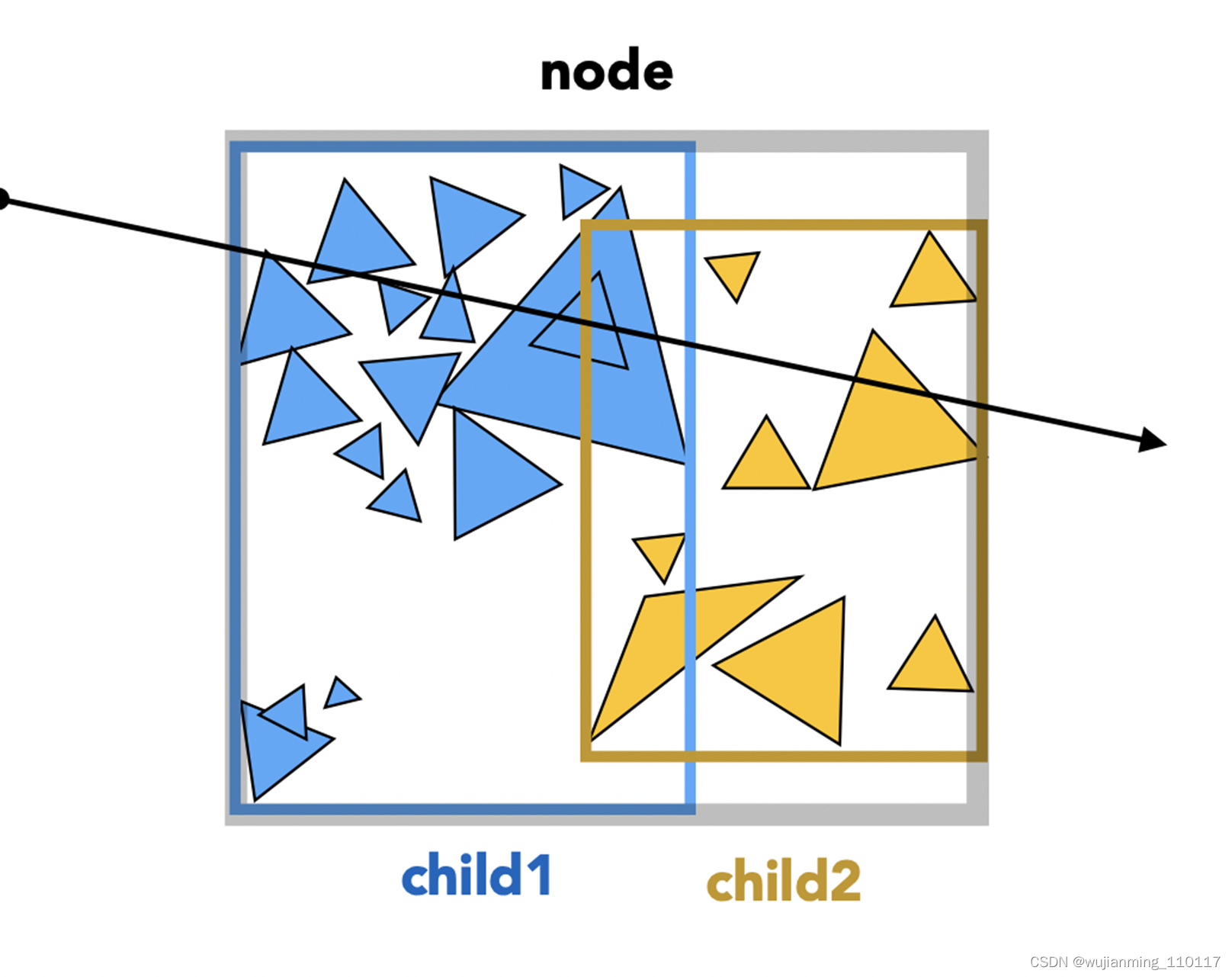
基于包围盒的光线求交
BVH的使用
- 创建包围盒:遍历场景中的物体,按照一定规则拆分包围盒。可以沿着最长的轴方向切割,另外拆分有个限制,就是拆到什么程度不再拆了,可以自己定义,比如一个包围盒少于5个三角形就不再拆分了。
- 光线求交:从上往下,按照树的遍历方式,对每个节点进行遍历,当然了,先判断父节点的包围盒是否和光线相交,满足条件再遍历子节点,如此,很大程度的优化了光线追踪的算法复杂度。
代码核心逻辑
虽然只是个demo,有软渲染器的核心逻辑,有面向对象的封装,有渲染的算法。
• Scene(场景)
• Light(光照)
• Renderer(渲染器)
• Model(几何模型)
• 工具类
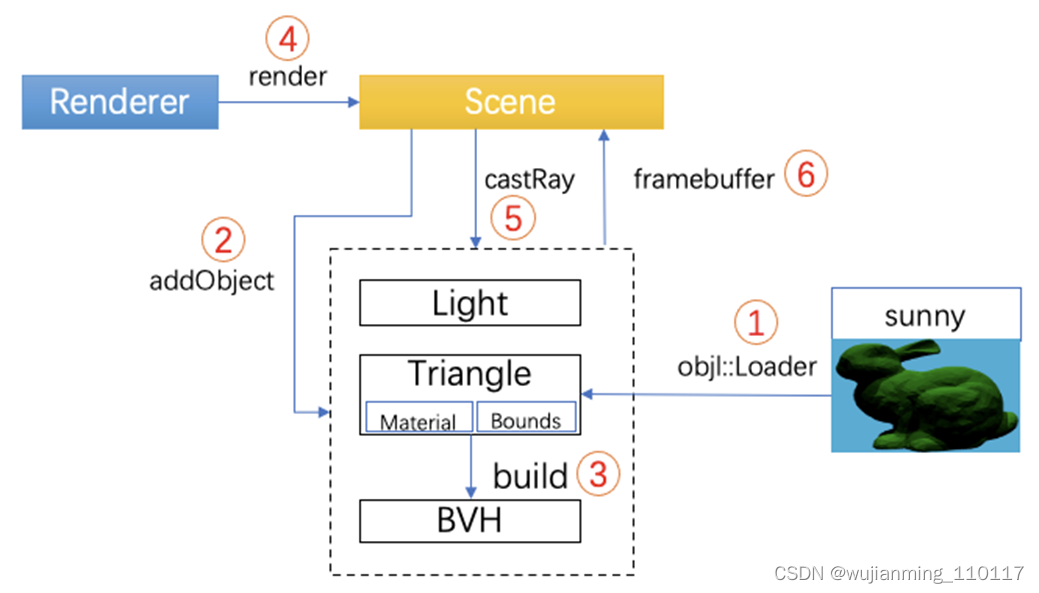
光线追踪渲染流程
完整代码:[1]
https://github.com/summer-go/games101/tree/main/Assignment6
补充
• 判断光线与包围盒相交的算法[2]
• 轻量级的3D加载工具OBJ-Loader[3]
• 模型只有漫反射,用冯氏光照计算颜色,兔子本身没有颜色,写死成(0.0, 0.5, 0.0)绿色
基础渲染
从最初的矩阵开始,到光线、阴影、全局光照等等涵盖几乎所有的图形知识。
第一篇:矩阵

第二篇:着色器基础

第三篇:合并纹理

第四篇:光照
第五篇:多灯光照明

第六篇:凹凸感

第七篇:阴影

第八篇:反射

第九篇:复合材质

第十篇:更复杂的复合材质

第十一篇:透明度

第十二篇:半透明阴影

第十三篇:延迟着色
第十四篇:雾

第十五篇:延迟光照

第十六篇:静态光照

第十七篇:混合光照
第十八篇:实时全局光照、探针体积、LOD组

第十九篇:GPU实例

第二十篇:视差
参考文献链接
https://mp.weixin.qq.com/s/dnoqPxEt_XEhVaW_aAfrnQ
https://mp.weixin.qq.com/s/1NumM2PRTqW-HIfQRlUu8A
https://mp.weixin.qq.com/s/d8Dq0YmjHpsoCchy8y4B2g
https://mp.weixin.qq.com/s/5JorA1BJXgeftzrqItJV9g
https://mp.weixin.qq.com/s/bw7GQDJhirVoddiBeErSlA
https://mp.weixin.qq.com/s/-7GxiG_roieUNSMy_G02Vw
https://mp.weixin.qq.com/s/unZFf7gss1p05z_baoJeEA