文章目录
- 1. 背景介绍
- 1.1 Meltdown & Spectre 漏洞
- 1.2 KPTI补丁
- 2. KPTI原理
- 2.1 页表隔离
- 2.2 TLB刷新策略
- 3. 代码实现
- 3.1 pgd切换
- 3.2 系统调用
- 3.3 进程切换
- 3.4 pgd的初始化
- 4. 相关知识
- 4.1 ALTERNATIVE()
- 4.2 .pushsection
- 4.3 宏计数器`\@`
- 4.4 pt_regs
- 参考文档:
1. 背景介绍
KPTI(Kernel page-table isolation)内核页表隔离,把进程页表按照成用户态、内核态独立的分割成两份,为了杜绝用户态通过一些旁路漏洞来窃取内核态的数据。这类漏洞最有名的有Meltdown & Spectre,因为是CPU层面的漏洞造成的影响也是非常巨大的。
1.1 Meltdown & Spectre 漏洞
Meltdown 和 Spectre 这两个漏洞厉害的地方就在于,利用现代CPU speculative execution (预测执行)的漏洞,在 rax 被清零之前把信息传递出去。Meltdown 的攻击代码(简化版):
mov rax byte[x] // 非法操作
shl rax 0xC // rax * 4096, page alignment
mov rbx qword [rbx + rax] // [rbx] 为用户空间的一个array,合法操作
攻击原理:
- 1、对于第一行mov代码,操作系统会事先标注好内核的内存地址范围,如果 x 在内核的这个地址范围内,并且 CPU 不是以内核模式运行的话,那么该指令会被 CPU 标注为非法,引起异常,异常处理程序会将 rax 清空为0,并且终结此程序,这样后续指令再来读 rax 的时候就只能读到0了。
- 2、理论上讲,在执行第二条指令之前,rax应该已经被清零了。然而在实际的 CPU 运行中,为了达到更好的性能,第二条和第三条指令在异常处理生效之前都会被部分执行,直到异常处理时 rax 和 rbx 被清零。目前看起来也没什么问题,因为rbx 也会被清零,关于 [x] 的任何信息都没有留下。
- 3、但问题的关键就在第三行指令:如果地址 rbx + rax 不在cache中的话,CPU 会自动将这一地址调入cache中,以便之后访问时获得更好的性能,然而异常处理并不会将这个cache flush掉。而这条 cache 的地址是和 rax 直接相关的,这样就相当于在 CPU 硬件中留下了和rax 相关的信息。
- 4、那么如何还原 rbx + rax 这个被cache的地址呢?这时候需要用到的原理就是利用cache的访问延时,即已经被cache的数据访问时间短,没有被cache的数据访问时间长。由于[rbx]这个array是在用户地址空间内的,可以自由操作,首先我们要确保整个 [rbx]这个array 都是没有被cache的,然后执行上述攻击代码,这时候 rbx + rax 这个地址就已经被cache了,接下来遍历整个[rbx] array,来测量访问时间,访问时间最短的那个 page 就可以确定为 rbx + rax。
最接近的比喻 :
我们把CPU比做学校食堂,把黑客比作两个男生A,B,用户则是女神。这天,男生A,B总要想办法获得女神的一点私密信息——比如,女神今天午饭吃的啥~中午,女神来到食堂打饭,点了一份小笼包。
男生A在女神后面跟食堂大娘说:我也来一份,跟她一样的~
然而这会食堂大娘表示,你等会,你前面还有人哦。
好吧,虽然说是这么说,但是后面的厨房师傅已经听到了对话,已经提前开始准备好了另一份小笼包.....
后来女神点好走了,轮到男生A点,他表示,我要一个跟她一样的...然而这会,
食堂大娘表示,人家是人家,你是你,我们不能透露女神隐私喔,你可以走了,下一个! (这就是目前CPU的内置的安全防线)然而!
当下一个男生B走到食堂大娘面前,直接说:随便,哪道菜最快给我上哪道...
于是乎,既然之前厨房师傅已经提前多准备好了一份小笼包,就干脆直接把小笼包给了男生B....
这下男生知道了,女神中午吃了小笼包......
1.2 KPTI补丁
KPTI补丁基于KAISER,它是一个用于缓解不太重要问题的早期补丁,当时业界还未了解到Meltdown的存在。
如果没有KPTI,每当执行用户空间代码(应用程序)时,Linux会在其分页表中保留整个内核内存的映射,并保护其访问。这样做的优点是当应用程序向内核发送系统调用或收到中断时,内核页表始终存在,可以避免绝大多数上下文切换相关的开销(TLB刷新、页表交换等)。
KPTI通过完全分离用户空间与内核空间页表来解决页表泄露。支持进程上下文标识符(PCID)特性的x86处理器可以用它来避免TLB刷新,但即便如此,它依然有很高的性能成本。据KAISER原作者称,其开销为0.28%[2];一名Linux开发者称大多数工作负载下测得约为5%,但即便有PCID优化,在某些情况下开销高达30%。[1]
使用内核启动选项“pti=off”可以部分禁用内核页表隔离。依规定也可对已修复漏洞的新款处理器禁用内核页表隔离[16]。
2. KPTI原理
2.1 页表隔离

进程页表分割成用户态页表和内核态页表的具体方案是什么样的?
- 1、在运行userapplication 的时候,将kernel mapping 减少到最少,只保留必须的user到kernel的exception entry mapping. 其他的kernel mapping 在运行user application时都去掉,变成无效mapping,这样的话,如果user访问kernel data, 在MMU地址转换的时候就会被挡掉(因为无效mapping).
- 2、设计一个trampoline 的kernel PGD给运行user时用。Trampoline kernel mapping PGD只包含exception entry必需的mapping.
- 3、当user通过系统调用,或是timer或其他异常进入kernel是首先用trampoline的mapping,接下来tramponline的vector处理会将kernel mapping 换成正常的kernel mapping(SWAPPER_PGD_DIR), 并直接跳转到kernel原来的vector entry, 继续正常处理。我们把上述过程称之为map kernel mapping.
- 4、当从kernel返回到user时,正常的kernel_exit会调用trampoline的exit,tramp_exit会重新将kernel mapping 换成是trampoline. 这个过程叫unmap kernel mapping.
2.2 TLB刷新策略
TLB是页表的高速缓存,虚拟地址到物理地址转换都要经过TLB。

TLB刷新策略的发展史是这样的:
-
1、初始状态。操作系统中存在多个进程,每个进程都由自己虚拟地址空间。进程的虚拟地址空间时重叠的,如果存在多-份地址转换将出现混乱。那么在进程切换的时候,会进行TLB刷新,将旧进程的页表缓存无效。

-
2、
Global TLB和non-Global TLB。现代OS都将地址空间分为内核空间和用户空间,进程间的用户空间独立,内核空间一样。
为了性能,可以把内核态空间的页表设置G标志:

这样这类页表被加载进TLB以后会变成Global TLB。这样在进程切换刷新TLB时,只会清理旧进程用户态的non-Global TLB,而不会清理旧进程内核态的Global TLB。这样新的进程会开始一个半新的TLB,效能提高不少:

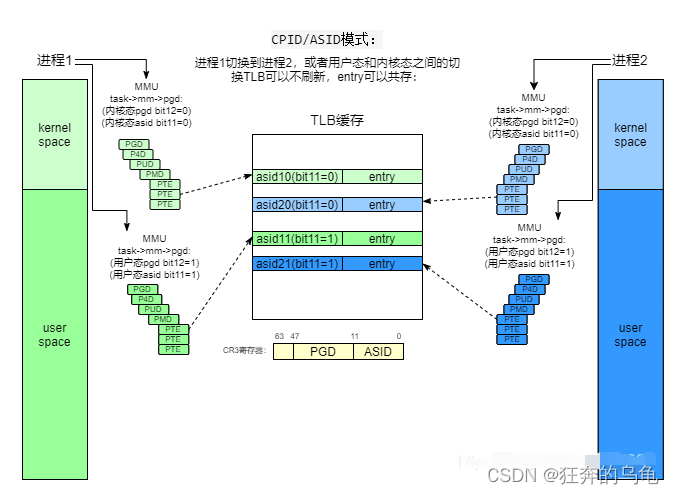
- 3、PCID(Process-Context Identifiers)和ASID(Address-Space Identifier)。
在kpti出现以后对TLB有了两个新的需求:
1、内核空间不能设置成全局,因为这样就没有隔离的效果了。
2、内核态和用户态的切换就会引起页表切换,这种场景下要求TLB不要刷新,因为如果刷新就会带来非常大的性能开销,但是不刷新又怎么做到页表隔离呢?
针对上述的需求,诞生了新的TLB机制PCID/ASID。每一个进程在运行时,都会动态分配一个pcid/asid,如果进程切换到本进程开始运行,把对应的pcid/asid配置到cr3中:

在进程运行过程中,根据本进程的pgd产生的页表转换关系会缓存到TLB中,所有产生的TLB条目会根据当前cr3中的pcid/asid打上标签。TLB条目有了标签以后,页表切换就不需要去刷新旧的条目了,因为当前cpu只会认和当前cr3中asid相同的TLB条目,这样TLB就不用频繁的去刷新,且相互之间也是隔离的。

为了同一进程内的用户态页表和内核态页表隔离,每个进程需要两个asid。用最高位bit11来区分,bit11=0 为内核态asid,bit11=1 为用户态asid。
3. 代码实现
3.1 pgd切换
内核增加了一组宏用来在进程进行用户态、内核态切换时进行页表切换。一个进程的内核态pgd(4K)和用户态pgd(4K)放在一起形成一个8K的pgd。
cr3的bit47-bit11为pgd的物理地址,最低位bit12来进行pgd切换:bit12=0 为内核态pgd,bit12=1 为用户态pgd。
cr3的bit0-bit11为asid,asid也分成内核态和用户态,最高位bit11来进行asid切换:bit11=0 为内核态asid,bit11=1 为用户态asid。

SAVE_AND_SWITCH_TO_KERNEL_CR3()宏用来把cr3中加载成内核态pgd:
linux-source-4.15.0\arch\x86\entry\calling.h:/** PAGE_TABLE_ISOLATION PGDs are 8k. Flip bit 12 to switch between the two* halves:*/
#define PTI_USER_PGTABLE_BIT PAGE_SHIFT
#define PTI_USER_PGTABLE_MASK (1 << PTI_USER_PGTABLE_BIT) // bit12,用来切换内核态/用户态pgd,0=内核态/1=用户态
#define PTI_USER_PCID_BIT X86_CR3_PTI_PCID_USER_BIT
#define PTI_USER_PCID_MASK (1 << PTI_USER_PCID_BIT) // bit11,用来切换内核态/用户态asid,0=内核态/1=用户态
#define PTI_USER_PGTABLE_AND_PCID_MASK (PTI_USER_PCID_MASK | PTI_USER_PGTABLE_MASK).macro SAVE_AND_SWITCH_TO_KERNEL_CR3 scratch_reg:req save_reg:req/* (1) 如果X86_FEATURE_PTI特性没有使能,直接跳转到".Ldone_\@",即本宏为空操作 */ALTERNATIVE "jmp .Ldone_\@", "", X86_FEATURE_PTI /* (2) 备份cr3到scratch_reg和save_reg */movq %cr3, \scratch_regmovq \scratch_reg, \save_reg/** Test the user pagetable bit. If set, then the user page tables* are active. If clear CR3 already has the kernel page table* active.*//* (3) 判断cr3,如果已经是内核态pgd,放弃操作直接返回 */bt $PTI_USER_PGTABLE_BIT, \scratch_regjnc .Ldone_\@/* (4) 进行用户态到内核态的切换 */ADJUST_KERNEL_CR3 \scratch_regmovq \scratch_reg, %cr3.Ldone_\@:
.endm↓.macro SWITCH_TO_KERNEL_CR3 scratch_reg:req/* (4.1) 如果X86_FEATURE_PTI特性没有使能,直接跳转出去,本宏为空操作 */ALTERNATIVE "jmp .Lend_\@", "", X86_FEATURE_PTI/* (4.2) 读出cr3的值到scratch_reg */mov %cr3, \scratch_reg/* (4.3) 计算内核态下,cr3的新值 */ADJUST_KERNEL_CR3 \scratch_reg/* (4.4) 使用新值来配置cr3 */mov \scratch_reg, %cr3
.Lend_\@:
.endm↓.macro ADJUST_KERNEL_CR3 reg:req/* (4.3.1) 如果X86_FEATURE_PTI特性使能,设置noflush标志 */ALTERNATIVE "", "SET_NOFLUSH_BIT \reg", X86_FEATURE_PCID /* Clear PCID and "PAGE_TABLE_ISOLATION bit", point CR3 at kernel pagetables: *//* (4.3.2) 将bit12和bit11清零,把pgd和asid从用户态切换到内核态 */andq $(~PTI_USER_PGTABLE_AND_PCID_MASK), \reg
.endm↓.macro SET_NOFLUSH_BIT reg:req/* (4.3.1.1) noflush标志为cr3的bit63 */bts $X86_CR3_PCID_NOFLUSH_BIT, \reg // bit63,noflush标志
.endm
SAVE_AND_SWITCH_TO_KERNEL_CR3()宏用来把cr3中加载成用户态pgd:
.macro SWITCH_TO_USER_CR3_STACK scratch_reg:req/* (1) 备份rax寄存器 */pushq %rax/* (2) 使用rax充当scratch_reg2,调用内核态到用户态的切换 */SWITCH_TO_USER_CR3_NOSTACK scratch_reg=\scratch_reg scratch_reg2=%rax/* (3) 恢复rax寄存器 */popq %rax
.endm↓#define THIS_CPU_user_pcid_flush_mask \PER_CPU_VAR(cpu_tlbstate) + TLB_STATE_user_pcid_flush_mask.macro SWITCH_TO_USER_CR3_NOSTACK scratch_reg:req scratch_reg2:req/* (2.1) 如果X86_FEATURE_PTI特性没有使能,直接跳转出去,本宏为空操作 */ALTERNATIVE "jmp .Lend_\@", "", X86_FEATURE_PTI/* (2.2) 读出cr3到scratch_reg中 */mov %cr3, \scratch_reg/* (2.3) 如果X86_FEATURE_PCID特性没有使能,直接跳转到切换pgd处 */ALTERNATIVE "jmp .Lwrcr3_\@", "", X86_FEATURE_PCID/** Test if the ASID needs a flush.*//* (2.4.1) 取出cr3中的asid,判断是否需要flush */movq \scratch_reg, \scratch_reg2andq $(0x7FF), \scratch_reg /* mask ASID */bt \scratch_reg, THIS_CPU_user_pcid_flush_maskjnc .Lnoflush_\@/* Flush needed, clear the bit *//* (2.4.2) 如果需要flush,则不设置noflush标志位 */btr \scratch_reg, THIS_CPU_user_pcid_flush_maskmovq \scratch_reg2, \scratch_regjmp .Lwrcr3_pcid_\@.Lnoflush_\@:/* (2.4.3) 如果不需要flush,则设置noflush标志位 */movq \scratch_reg2, \scratch_regSET_NOFLUSH_BIT \scratch_reg.Lwrcr3_pcid_\@:/* Flip the ASID to the user version *//* (2.5) 将bit11置位,把asid从内核态切换到用户态 */orq $(PTI_USER_PCID_MASK), \scratch_reg.Lwrcr3_\@:/* Flip the PGD to the user version *//* (2.6) 将bit12置位,把pgd从内核态切换到用户态 */orq $(PTI_USER_PGTABLE_MASK), \scratch_reg/* (2.7) 使用新值来配置cr3 */mov \scratch_reg, %cr3
.Lend_\@:
.endm
RESTORE_CR3()宏用来恢复备份的cr3:
.macro RESTORE_CR3 scratch_reg:req save_reg:req/* (1) 如果X86_FEATURE_PTI特性没有使能,直接跳转出去,本宏为空操作 */ALTERNATIVE "jmp .Lend_\@", "", X86_FEATURE_PTI/* (2) 如果X86_FEATURE_PCID特性没有使能,直接跳转到切换cr3处 */ALTERNATIVE "jmp .Lwrcr3_\@", "", X86_FEATURE_PCID/** KERNEL pages can always resume with NOFLUSH as we do* explicit flushes.* 内核页面始终可以使用NOFLUSH恢复,因为我们执行显式刷新。*//* (3) 如果save_reg中备份的是内核态pgd,设置noflush标志 */bt $PTI_USER_PGTABLE_BIT, \save_regjnc .Lnoflush_\@/** Check if there's a pending flush for the user ASID we're* about to set.*//* (4) 否则save_reg中备份的是用户态pgd,则根据asid中的标志来判断是否flush */movq \save_reg, \scratch_regandq $(0x7FF), \scratch_regbt \scratch_reg, THIS_CPU_user_pcid_flush_mask/* (4.1) 用户态pgd,不flush,设置noflush标志 */jnc .Lnoflush_\@btr \scratch_reg, THIS_CPU_user_pcid_flush_mask/* (4.2) 用户态pgd,flush,不设置noflush标志 */jmp .Lwrcr3_\@.Lnoflush_\@:/* (5) 设置bit63,noflush标志 */SET_NOFLUSH_BIT \save_reg.Lwrcr3_\@:/** The CR3 write could be avoided when not changing its value,* but would require a CR3 read *and* a scratch register.*//* (6) 使用新值来配置cr3 */movq \save_reg, %cr3
.Lend_\@:
.endm
3.2 系统调用
系统调用过程中内核态和用户态的切换,调用上一节的各种宏来切换页表:
linux-source-4.15.0\arch\x86\entry\entry_64.S:ENTRY(entry_SYSCALL_64_trampoline)/* Note: using %rsp as a scratch reg. *//* (1) 切换到进程的内核态页表 */SWITCH_TO_KERNEL_CR3 scratch_reg=%rspmovq $entry_SYSCALL_64_stage2, %rdiJMP_NOSPEC %rdi
END(entry_SYSCALL_64_trampoline)↓ENTRY(entry_SYSCALL_64_stage2)UNWIND_HINT_EMPTYpopq %rdijmp entry_SYSCALL_64_after_hwframe
END(entry_SYSCALL_64_stage2)↓ENTRY(entry_SYSCALL_64)
GLOBAL(entry_SYSCALL_64_after_hwframe)/* (2) 执行具体的系统调用 */call do_syscall_64 /* returns with IRQs disabled */syscall_return_via_sysret:
/** We are on the trampoline stack. All regs except RDI are live.* We can do future final exit work right here.*//* (3) 切换到进程的用户态页表 */SWITCH_TO_USER_CR3_STACK scratch_reg=%rdi
END(entry_SYSCALL_64)
3.3 进程切换
进程切换的过程也涉及到pgd、asid和cr3的切换:
schedule() → __schedule() → context_switch() → switch_mm_irqs_off():void switch_mm_irqs_off(struct mm_struct *prev, struct mm_struct *next,struct task_struct *tsk)
{/* (1) 分配新进程的asid,并判断tlb是否需要flush */choose_new_asid(next, next_tlb_gen, &new_asid, &need_flush);if (need_flush) {this_cpu_write(cpu_tlbstate.ctxs[new_asid].ctx_id, next->context.ctx_id);this_cpu_write(cpu_tlbstate.ctxs[new_asid].tlb_gen, next_tlb_gen);/* (2.1) 按照新的asid和新的pgd来加载cr3,并且flush旧tlb */load_new_mm_cr3(next->pgd, new_asid, true);/** NB: This gets called via leave_mm() in the idle path* where RCU functions differently. Tracing normally* uses RCU, so we need to use the _rcuidle variant.** (There is no good reason for this. The idle code should* be rearranged to call this before rcu_idle_enter().)*/trace_tlb_flush_rcuidle(TLB_FLUSH_ON_TASK_SWITCH, TLB_FLUSH_ALL);} else {/* The new ASID is already up to date. *//* (2.2) 按照新的asid和新的pgd来加载cr3,不需要flush旧tlb */load_new_mm_cr3(next->pgd, new_asid, false);/* See above wrt _rcuidle. */trace_tlb_flush_rcuidle(TLB_FLUSH_ON_TASK_SWITCH, 0);}
}
3.4 pgd的初始化
- 1、init_top_pgt
KPTI特性开启时,在系统初始化pgd即init_top_pgt中包留了两个page,page 0用于内核态的pgd,page 1用于用户态的pgd:
linux-source-4.15.0\arch\x86\kernel\head_64.S:NEXT_PGD_PAGE(init_top_pgt).quad level3_ident_pgt - __START_KERNEL_map + _KERNPG_TABLE_NOENC.org init_top_pgt + PGD_PAGE_OFFSET*8, 0.quad level3_ident_pgt - __START_KERNEL_map + _KERNPG_TABLE_NOENC.org init_top_pgt + PGD_START_KERNEL*8, 0/* (2^48-(2*1024*1024*1024))/(2^39) = 511 */.quad level3_kernel_pgt - __START_KERNEL_map + _PAGE_TABLE_NOENC.fill PTI_USER_PGD_FILL,8,0 // 预留了一个page给用户态pgd使用#ifdef CONFIG_PAGE_TABLE_ISOLATION
/** Each PGD needs to be 8k long and 8k aligned. We do not* ever go out to userspace with these, so we do not* strictly *need* the second page, but this allows us to* have a single set_pgd() implementation that does not* need to worry about whether it has 4k or 8k to work* with.** This ensures PGDs are 8k long:*/
#define PTI_USER_PGD_FILL 512
#else
#define PTI_USER_PGD_FILL 0
#endif
- 2、pti_init()
pti_init()用来创建init_top_pgt中的page 1(用户态pgd)中的内核映射。
因为工作在用户态时,如果要切换到内核态需要能访问部分内核代码的映射,这些部分和临时的映射在pti_init()创建,在fork()时每个进程来拷贝init_top_pgt中值。
start_kernel() → mm_init() → pti_init():
linux-source-4.15.0\arch\x86\mm\pti.c:void __init pti_init(void)
{/* (1) 创建各个需要临时映射的,在用户态可以访问的内核地址映射 */pti_clone_user_shared();/* Undo all global bits from the init pagetables in head_64.S: */pti_set_kernel_image_nonglobal();/* Replace some of the global bits just for shared entry text: */pti_clone_entry_text();pti_setup_espfix64();pti_setup_vsyscall();
}
- 3、fork()
进程创建时,对KPTI下两个pgd的处理:
_do_fork() → copy_process() → copy_mm() → dup_mm() → mm_init() → mm_alloc_pgd() → pgd_alloc():pgd_t *pgd_alloc(struct mm_struct *mm)
{pgd_t *pgd;pmd_t *u_pmds[PREALLOCATED_USER_PMDS];pmd_t *pmds[PREALLOCATED_PMDS];/* (1) 如果KPTI使能,分配两个page的pgd(page 0用于内核态的pgd,page 1用于用户态的pgd) */pgd = _pgd_alloc();if (pgd == NULL)goto out;mm->pgd = pgd;if (preallocate_pmds(mm, pmds, PREALLOCATED_PMDS) != 0)goto out_free_pgd;if (preallocate_pmds(mm, u_pmds, PREALLOCATED_USER_PMDS) != 0)goto out_free_pmds;if (paravirt_pgd_alloc(mm) != 0)goto out_free_user_pmds;/** Make sure that pre-populating the pmds is atomic with* respect to anything walking the pgd_list, so that they* never see a partially populated pgd.*/spin_lock(&pgd_lock);/* (2) pgd的构造函数,初始化pgd结构 */pgd_ctor(mm, pgd);pgd_prepopulate_pmd(mm, pgd, pmds);pgd_prepopulate_user_pmd(mm, pgd, u_pmds);spin_unlock(&pgd_lock);return pgd;out_free_user_pmds:free_pmds(mm, u_pmds, PREALLOCATED_USER_PMDS);
out_free_pmds:free_pmds(mm, pmds, PREALLOCATED_PMDS);
out_free_pgd:_pgd_free(pgd);
out:return NULL;
}static inline pgd_t *_pgd_alloc(void)
{return (pgd_t *)__get_free_pages(PGALLOC_GFP, PGD_ALLOCATION_ORDER);
}#ifdef CONFIG_PAGE_TABLE_ISOLATION
/** Instead of one PGD, we acquire two PGDs. Being order-1, it is* both 8k in size and 8k-aligned. That lets us just flip bit 12* in a pointer to swap between the two 4k halves.*/
#define PGD_ALLOCATION_ORDER 1
#else
#define PGD_ALLOCATION_ORDER 0
#endif↓static void pgd_ctor(struct mm_struct *mm, pgd_t *pgd)
{/* If the pgd points to a shared pagetable level (either theptes in non-PAE, or shared PMD in PAE), then just copy thereferences from swapper_pg_dir. */if (CONFIG_PGTABLE_LEVELS == 2 ||(CONFIG_PGTABLE_LEVELS == 3 && SHARED_KERNEL_PMD) ||CONFIG_PGTABLE_LEVELS >= 4) {/* (2.1) 使用swapper_pg_dir(init_top_pgt)中pgd来初始化新分配的pgd */clone_pgd_range(pgd + KERNEL_PGD_BOUNDARY,swapper_pg_dir + KERNEL_PGD_BOUNDARY,KERNEL_PGD_PTRS);}/* list required to sync kernel mapping updates */if (!SHARED_KERNEL_PMD) {pgd_set_mm(pgd, mm);pgd_list_add(pgd);}
}↓static inline void clone_pgd_range(pgd_t *dst, pgd_t *src, int count)
{/* (2.1.1) 把init_top_pgt中的page 0(内核态pgd)中的内核映射,拷贝到新分配的pgd的page 0(内核态pgd) */memcpy(dst, src, count * sizeof(pgd_t));
#ifdef CONFIG_PAGE_TABLE_ISOLATIONif (!static_cpu_has(X86_FEATURE_PTI))return;/* Clone the user space pgd as well *//* (2.1.2) 把init_top_pgt中的page 1(用户态pgd)中的内核映射,拷贝到新分配的pgd的page 1(内核态pgd) 注意这个内核映射是部分的临时的,仅供用户态切换内核态时临时使用新进程没有拷贝父进程用户态的映射,而只是简单拷贝了它的vma红黑树*/memcpy(kernel_to_user_pgdp(dst), kernel_to_user_pgdp(src),count * sizeof(pgd_t));
#endif
}
4. 相关知识
4.1 ALTERNATIVE()
内核的开发一直遵循向前兼容的特性,最新版本的内核还可以在最古老的机器上运行。怎么样做到最新的代码能同时兼任新、旧CPU呢?内核实现了一个在运行时根据cpu支持的feature来动态选择的技巧。
内核使用ALTERNATIVE()宏来对一段操作定义两段指令oldinstr和newinstr,默认使用oldinstr,如果feature满足则使用newinstr。
ALTERNATIVE()宏的定义:
#define ALTERNATIVE(oldinstr, newinstr, feature) \ OLDINSTR(oldinstr, 1) \ ".pushsection .altinstructions,\"a\"\n" \ ALTINSTR_ENTRY(feature, 1) \ ".popsection\n" \ ".pushsection .altinstr_replacement, \"ax\"\n" \ ALTINSTR_REPLACEMENT(newinstr, feature, 1) \ ".popsection"
展开以后:
asm volatile("
661:lock; addl $0,0(%%esp) //原始指令
662://如果优化指令长度大于原始指令长度,使用nop在原始指令后面填充,最后原始指令>=优化指令长度.skip -(((6651f-6641f)-(662b-661b)) > 0) * ((6651f-6641f)-(662b-661b)),0x90
663:.pushsection .altinstructions,"a" //创建一个新的section,pushsection和popsection的内容放到该section中.long 661b - . //中间整个是alt_instr对象,管理如何修改指令.long 6641f - ..word __stringify(X86_FEATURE_XMM2) .byte 663b-661b.byte 6651f-6641f.byte 663b-662b.popsection.pushsection .altinstr_replacement, "ax"
6641:mfence //优化指令放在altinstr_replacement section中
6651:.popsection" ::: "memory", "cc");
ALTERNATIVE宏会在链接阶段创建两个特殊的section .altinstructions和.altinstr_replacement,而且arch/x86/kernel/vmlinux.lds.S脚本将两个section顺序放在一起,所以可使用偏移来计算指令地址。
在内核启动的时候会调用apply_alternatives()开始修改指令,遍历.altinstructions节中的内容,判断当前cpu是否支持该特性来决定是否应该使用优化指令来覆盖原始指令。还有两个处理:如果优化指令长度 > 原始指令长度,且不会覆盖,会尝试优化原始指令后面填充的nop指令;如果优化指令有相对跳转,对其跳转地址进行重新计算。
start_kernel() → check_bugs() → alternative_instructions() → apply_alternatives()
4.2 .pushsection
通过内联汇编新增一个 Section:
asm(".pushsection .interp,\"a\"\n"" .string \"/lib/i386-linux-gnu/ld-linux.so.2\"\n"".popsection");
通过上述代码新增了一个 .interp Section,用于指定动态链接器。简单介绍一下这段内联汇编:
- asm 括号内就是汇编代码,这些代码几乎会被“原封不动”地放到汇编语言中间文件中(hello.s)。这里采用 .pushsection, .popsection,而不是 .section 是为了避免之后的代码或者数据被错误地加到这里新增的 Section 中来。
- .pushsection .interp, “a”,这里的 “a” 表示 Alloc,会占用内存,这种才会被加到程序头表中,因为程序头表会用于创建进程映像。
- .string 这行用来指定动态链接器的完整路径。
4.3 宏计数器\@
我们在.macro SAVE_AND_SWITCH_TO_KERNEL_CR3等宏的定义中可以看到一个特殊的符号\@:
\@
as maintains a counter of how many macros it has executed in this pseudo-variable; you can copy that number to your output with ‘\@’, but only within a macro definition.
它的作用是一个计数器,如果宏被多次引用,\@的值就会累加编号。用\@定义的标号.Ldone_\@:就不会重复,而是根据计数分成多个标号。
.macro SAVE_AND_SWITCH_TO_KERNEL_CR3 scratch_reg:req save_reg:reqALTERNATIVE "jmp .Ldone_\@", "", X86_FEATURE_PTImovq %cr3, \scratch_regmovq \scratch_reg, \save_reg/** Test the user pagetable bit. If set, then the user page tables* are active. If clear CR3 already has the kernel page table* active.*/bt $PTI_USER_PGTABLE_BIT, \scratch_regjnc .Ldone_\@ADJUST_KERNEL_CR3 \scratch_regmovq \scratch_reg, %cr3.Ldone_\@:
.endm
4.4 pt_regs
用户态寄存器的保存。
linux程序通过系统调用、中断、异常等手段从用户态切换到内核态时,内核态需要保存用户态的寄存器上下文,通常内核态会在内核态堆栈的最顶端保留一段空间来存储用户态的寄存器上下文,这段空间的存储格式为pt_regs。
// 宏task_pt_regs(),用来获取本进程`内核态堆栈`栈顶保存的`pt_regs`数据
#define task_pt_regs(task) \
({ \unsigned long __ptr = (unsigned long)task_stack_page(task); \__ptr += THREAD_SIZE - TOP_OF_KERNEL_STACK_PADDING; \((struct pt_regs *)__ptr) - 1; \
})
pt_regs的格式定义如下:
struct pt_regs {
// 低地址 ↓
// 区域3结束:unsigned long r15;unsigned long r14;unsigned long r13;unsigned long r12;unsigned long rbp;unsigned long rbx;
// 区域3开始: 保存的是`callee save`和`caller save`类的寄存器
// 区域2结束: // arguments: non interrupts/non tracing syscalls only save up to here //unsigned long r11;unsigned long r10;unsigned long r9;unsigned long r8;unsigned long rax;unsigned long rcx;unsigned long rdx;unsigned long rsi;unsigned long rdi;unsigned long orig_rax;
// 区域2开始:保存的是x86_64的函数参数寄存器 // end of arguments //
// 区域1结束: cpu exception frame or undefined //unsigned long rip;unsigned long cs;unsigned long eflags;unsigned long rsp;unsigned long ss;
// 区域1开始:保存的是一些关键指针 (sp/ip/cs)
// 高地址 ↓ // top of stack page // 栈顶,保存的时候从高地址开始保存
};
pt_regs保存的寄存器信息分为3个区域,x86_64寄存器的详细说明见下图:

参考文档:
1.内核页表隔离
2.KPTI——可以缓解“熔断” (Meltdown) 漏洞的内核新特性
3.解读 Meltdown & Spectre CPU 漏洞
4.Arm64 Linux Kernel KPTI (Meltdown防御)方案解释
5.分页寻址(Paging)机制详解
6.KPTI补丁分析
7.PTI(page table isolation)–代码分析
8..macro
9.通过操作 Section 为 Linux ELF 程序新增数据
10.linux内核的指令替换-alternative
11.TLB、PCID与ASID
12.内核地址空间布局详解